大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识。
在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备。
Hdfs 架构
首先来个Hdfs的架构图,图中中包含了Hdfs 的组成与一些操作。
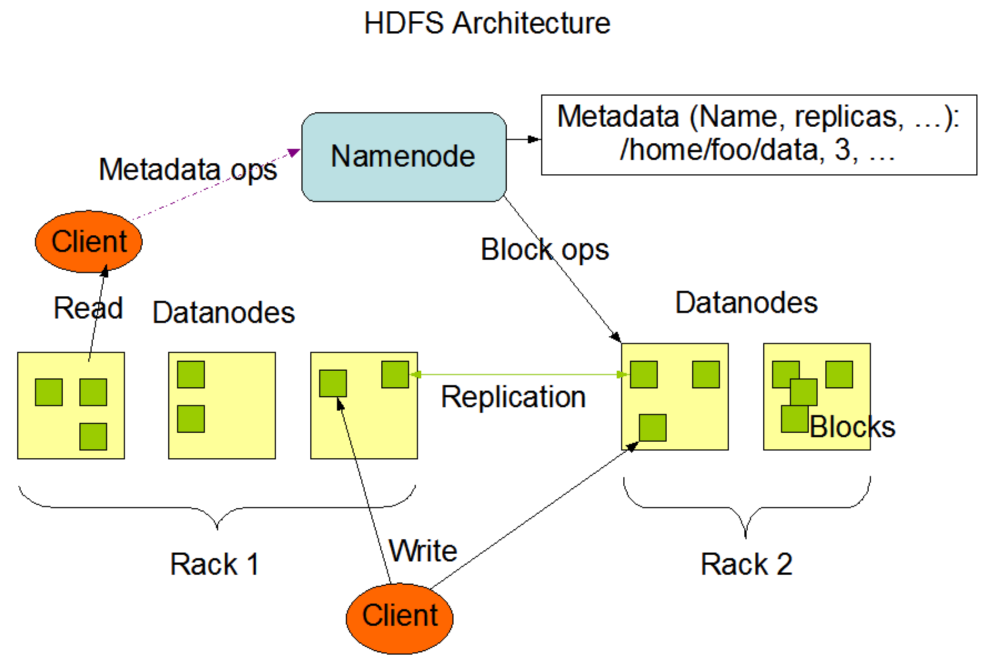
对于一个客户端而言,对于Hdfs的操作不外乎也就读写两个操作,接下来就去看看整个流程是怎么走的。
下面我们由浅及深,氛围简单流程,详细流程分别介绍读写过程
简单流程
读请求流程
客户端需要读取数据的时候,流程大致如下:
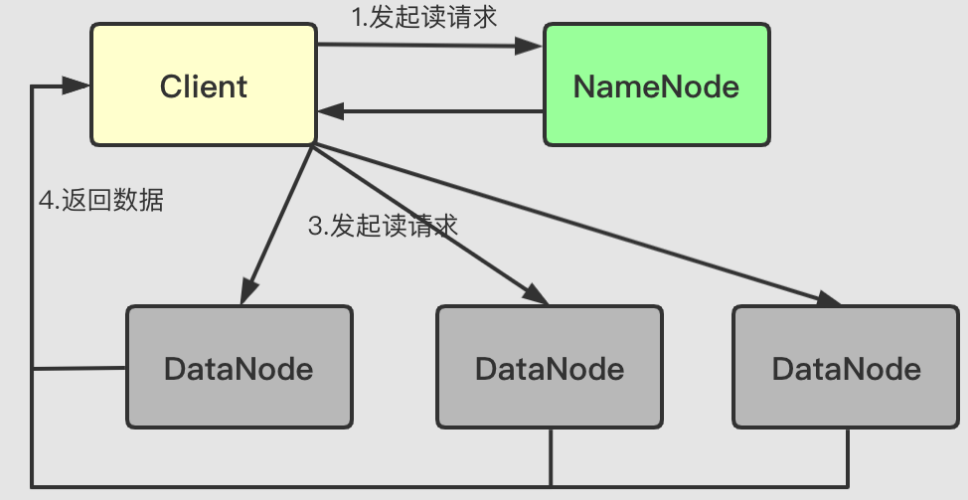
Client向NameNode发起读请求NameNode收到读请求后,会返回元数据,包括请求文件的数据块在DataNode的具体位置。Client根据返回的元数据信息,找到对应的DataNode发起读请求DataNode收到读请求后,会返回对应的Block数据给Client。
写请求流程
客户端需要写入数据的时候,流程大致如下:
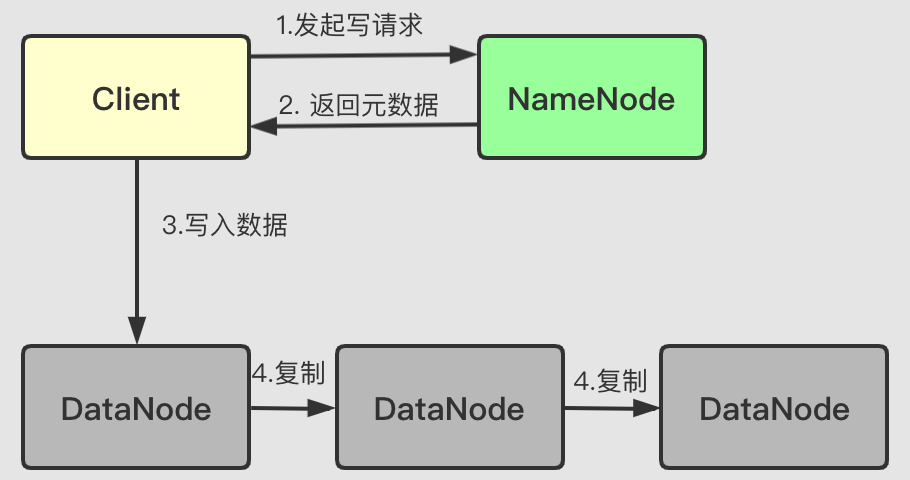
Client向NameNode发起写请求,其中包含写入的文件名,大小等。NameNode接收到信息,NameNode会将文件的信息存储到本地,同时判断客户端的权限、以及文件是否存在等信息,验证通过后NameNode返回数据块可以存储的DataNode信息。- 客户端会切割文件为多个
Block,将每个Block写入DataNode,在DataNode之间通过管道,对Block做数据备份。
详细流程
读请求流程
客户端需要读取数据的时候,流程大致如下:
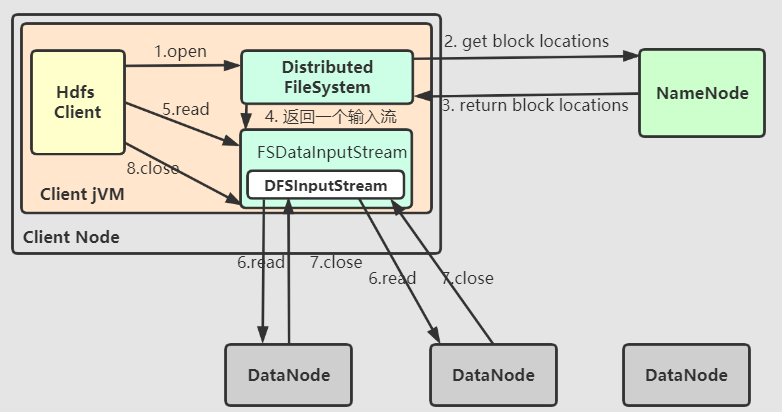
- 客户端通过调用
FileSystem的open()方法来读取文件。、 - 这个对象是
DistributedFileSystem的一个实例,通过远程调用(RPC)与NameNode沟通,会向NameNode请求需要读写文件文件的Block位置信息。 NameNode会进行合法性校验,然后返回Block位置信息,每一个Block都回返回存有该副本的DataNode地址,并且会根据DtaNode与Client的距离进行排序(这里的距离是指集群网络拓扑的距离,也是尽可能满足数据本地性的要求)DistributedFileSystem会返回一个支持文件定位的输入流FSDataInputStream给客户端,其中封装着DFSInputStream对象,该对象管理者DataNode和NameNode之间的I/OClient对这个输入流调用read()方法DFSInputStream存储了文件中前几个块的DataNode地址,然后在文件第一个Block所在的DataNode中连接最近的一个DtaNode。通过对数据流反复调用read(),可以将数据传输到客户端。- 当到到
Block的终点的时候,DFSInputStream会关闭与DataNode的链接。然后搜寻下一个Block的DataNode重复6、7步骤。在Client看来,整个过程就是一个连续读取过程。 - 当完成所有
Block的读取后,Client会对FSDataInputStream调用close()
Client读取数据流的时候,Block是按照DFSInputStream与DataNode打开新的连接的顺序读取的。
并且在有需要的时候,还会请求NameNode返回下一个批次Blocks的DataNode信息
在DFSInputStream与DataNode交互的时候出现错误,它会尝试选择这个Block另一个最近的DataNode,并且标记之前的DataNode避免后续的Block继续在该DataNode上面出错。
DFSInputStream也会对来自DataNode数据进行校验,一旦发现校验错误,也会从其他DataNode读取该Bclock的副本,并且向NamaNode上报Block错误信息。
整个流程下来,我们可以发现Client直接连接到DataNode检索数据并且通过NameNode知道每个Block的最佳DataNode。
这样设计有一个好处就是:
因为数据流量分布在集群中的所有DataNode上,所以允许Hdfs扩展到大量并发Client.
与此同时,NamaNode只需要响应Block的位置请求(这些请求存储在内存中,非常高效),
而不需要提供数据。
否则随着客户端数量的快速增加,NameNode会成为成为性能的瓶颈。
读请求流程
客户端需要写入数据的时候,流程大致如下:
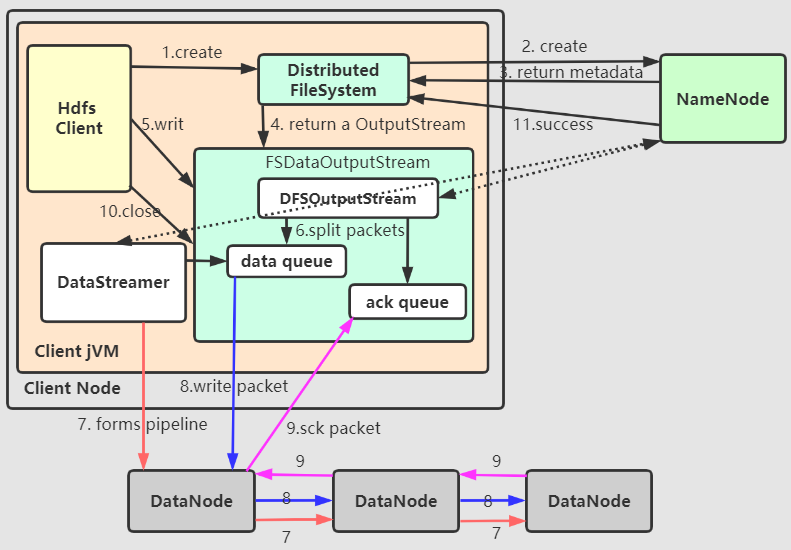
Client通过create()方法调用DistributedFileSystem的create()DistributedFileSystem通过RPC向NameNode请求建立在文件系统的明明空间中新建一个文件,此时只是建立了一个空的文件加,并没有Block。NameNode接收到crete请求后,会进行合法性校验,比如是否已存在想通文件,Client是否有相关权限。如果校验通过,NameNode会为新文件创建一个记录,并返回一些可用的DataNode。否则客户端抛出一个IOExceptionDistributedFileSystem会返回一个FSDataOutputStream个Client,与读取数据类似,FSDataOutputStream封装了一个DFSOutputStream,负责NameNode与DataNode之间交互。Client调用write()DFSOutputStream会将数据切分为一个一个packets,并且将之放入一个内部队列(data queue),这个队列会被DataStreamer消费,DataStreamer通过选择一组合合适DataNodes来写入副本,并请求NameNode分配新的数据块。与此同时,DFSOutputStream还维护一个等待DataNode确认的内部包队列(ack queue)- 这些
DataNodes会被组成一个管道(假设备份数量为3) - 一旦
pipeline建立,DataStreamer将data queue中存储的packet流式传入管道的第一个DataNode,第一个DataNode存储Packet并将之转发到管道中的第二个DataNode,同理,从第二个DataNode转发到管道中的第三个DataNode。 - 当所一个
packet已经被管道中所有的DataNode确认后,该packet会从ack queue移除。 - 当
Client完成数据写入,调用close(),此操作将所有剩余的数据包刷新到DataNode管道,等待NameNode返回文件写入完成的确认信息。 NameNode已经知道文件是由哪个块组成的(因为是DataStreamer请求NameNode分配Block的),因此,它只需要等待Block被最小限度地复制,最后返回成功。
如果在写入的过程中国发生了错误,会采取以下的操作:
- 关闭管道,并将所有在
ack queue中的packets加到data queue的前面,避免故障节点下游的DataNode发生数据丢失。 - 给该
Block正常DataNode一个新的标记,将之告知NameNode,以便后续故障节点在恢复后能删除已写入的部分数据。 - 将故障节点从管道中移除,剩下的两个正常
DataNodes重新组成管道,剩余的数据写入正常的DataNodes。 - 当
NameNode发现备份不够的时候,它会在另一个DataNode上创建一个副本补全,随后该Blcok将被视为正常
针对多个DataNode出现故障的情况,我们只要设置 dfs.NameNode.replication.min的副本数(默认为1),Block将跨集群异步复制,直到达到其目标复制因子( dfs.replication,默认为3)为止.
通俗易懂的理解
上面的读写过程可以做一个类比,
NameNode 可以看做是一个仓库管理员;
DataNode 可以看作是仓库;
管理员负责管理商品,记录每个商品所在的仓库;
仓库负责存储商品,同时定期想管理员上报自己仓库中存储的商品;
此处的商品可以粗略的理解为我们的数据。
管理员只能有一个,而仓库可以有多个。
当我们需要出库的时候,得先去找管理员,在管理员处取得商品所在仓库的信息;
我们拿着这个信息到对应仓库提取我们需要的货物。
当我们需要入库的时候,也需要找管理员,核对权限后告诉我们那些仓库可以存储;
我们根据管理员提供的仓库信息,将商品入库到对应的仓库。
存在的问题
上面是关于Hdfs读写流程介绍,虽然我分了简单和详细,但是实际的读写比这个过程复杂得多。
比如如何切块?
为何小于块大小的文件按照实际大小存储?
备份是如何实现的?
Block的结构等等。
这些内容会在后续的源码部分详细解答。
此外,有人也许发现了,前文大数据系列1:一文初识Hdfs中Hdfs架构的介绍和本文读写的流程的介绍中,存在一个问题。
就是NameNode的单点故障问题。虽然之前有SecondaryNameNode 辅助NameNode合并fsiamge和edits,但是这个还是无法解决NameNode单点故障的问题。
很多人听过HA(High Availability) 即高可用,误以为高可用就是SecondaryNameNode,其实并不是。
在下一篇文章中会介绍Hdfs高可用的实现方式。
想了解更多内容观影关注:【兔八哥杂谈】
大数据系列2:Hdfs的读写操作的更多相关文章
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- 【大数据系列】Hadoop DataNode读写流程
DataNode的写操作流程 DataNode的写操作流程可以分为两部分,第一部分是写操作之前的准备工作,包括与NameNode的通信等:第二部分是真正的写操作. 一.准备工作 1.首先,HDFS c ...
- 【大数据系列】HDFS初识
一.HDFS介绍 HDFS为了做到可靠性(reliability)创建了多分数据块(data blocks)的复制(replicas),并将它们放置在服务集群的计算节点中(compute nodes) ...
- 大数据学习之HDFS基本API操作(上)06
package it.dawn.HDFSPra; import java.io.FileNotFoundException; import java.io.IOException; import ja ...
- 【大数据系列】HDFS安全模式
一.什么是安全模式 安全模式时HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除.修改等变更请求.在NameNode主节点启动时,HDFS首先进入安全模式,DataNod ...
- 【大数据系列】HDFS文件权限和安全模式、安装
HDFS文件权限 1.与linux文件权限类型 r:read w:write x:execute权限x对于文件忽略,对于文件夹表示是否允许访问其内容 2.如果linux系统用户sanglp使用hado ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列4:Yarn以及MapReduce 2
系列文章: 大数据系列:一文初识Hdfs 大数据系列2:Hdfs的读写操作 大数据谢列3:Hdfs的HA实现 通过前文,我们对Hdfs的已经有了一定的了解,本文将继续之前的内容,介绍Yarn与Yarn ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
随机推荐
- .NET Core AWS S3云存储
前言 最近有需要用到AWS S3云存储上传附件,这里对利用.NET或.NET Core在调用SDK APi需要注意的一点小问题做个记录,或许能对后续有用到的童鞋提供一点帮助 AWS S3云存储 官方已 ...
- Angular实战之使用NG-ZORRO创建一个企业级中后台框架(进阶篇)
前言: 上一篇文章我们讲了如何在创建的Angular项目中快速引入ng-zorro-antd企业中台组件库,并且快速构建后台管理页面框架模板.这一章主要介绍的是如何在创建好的后台管理页面框架的快速生成 ...
- Eureka Server启动过程分析
1.首先,SpringCloud充分利用了SpringBoot的自动装配特点 eureka-server的jar包,发现在META-INF下面的配置文件spring.factories,里面记录了Sp ...
- 鸿蒙HarmonyOS应用开发落地实践,Harmony Go 技术沙龙落地北京
12月26日,华为消费者BG软件部开源中心与51CTO Harmony OS技术社区携手,共同主办了主题为"Harmony OS 应用开发落地实践"的 Harmony Go 技术沙 ...
- hive之Json解析(普通Json和Json数组)
一.数据准备 现准备原始json数据(test.json)如下: {"movie":"1193","rate":"5", ...
- Hbase之过滤器的使用
一.过滤器概念 基础API中的查询操作在面对大量数据的时候是非常物无力的,这里Hbase提供了高级的查询方法:Filter(过滤器).过滤器可以根据簇.列.版本等更多的条件来对数据进行过滤,基于Hba ...
- CountDownLatch/CyclicBarrier/Semaphore 使用过吗
CountDownLatch 让一些线程堵塞直到另一个线程完成一系列操作后才被唤醒.CountDownLatch 主要有两个方法,当一个或多个线程调用 await 方法时,调用线程会被堵塞,其他线程调 ...
- TCP三次握手(通俗易懂)
一--导读 前不久中国和外国RPEC协议的签订,标志着东亚自贸区的建立成功.现在韩国和日本要做贸易.日本一直监听着韩国总统的一举一动,但他又不会主动.(服务器的监听状态)只是被动的等着韩国总统先开口. ...
- Liunx运维(十一)-系统管理命令
文档目录: 一.lsof:查看进程打开的文件 二.uptime:显示系统的运行时间及负载 三.free:查看系统内存信息 四.iftop:动态显示网络接口流量信息 五.vmstat:虚拟内存统计 六. ...
- 实现Vue的多页签组件
在之前的博客中 关于vue的多页面标签功能,对于嵌套router-view缓存的最终无奈解决方法 有写过vue的多页签功能的解决方案 可以看到我当时那个多页签的组件还是比较简单 的,只有打开跟关闭 ...