MySQL调优之分区表
一、分区表的应用场景
1、为什么是用分区表?
表非常大以至于无法全部都放在内存中,或者只在表的最后部分有热点数据,其他均是历史数据,分区表是指根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分。从逻辑上看,只有一张表,但是底层却是由多个物理分区组成。
2、使用分区表的好处
(1)数据更容易维护
批量删除大量数据可以使用清除整个分区的方式
对一个独立分区进行优化、检查、修复等操作
(2)高效利用设备
数据可以分布在不同的物理设备上,高效地利用多个硬件设备,和单个磁盘或者文件系统相比,可以存储更多数据
(3)可以使用分区表来避免某些特殊的瓶颈
innodb的单个索引的互斥访问(之后补充)
ext3文件系统的inode锁竞争(之后补充)
(4)优化查询
在where语句中包含分区条件时,可以只扫描一个或多个分区表来提高查询效率;涉及sum和count语句时,也可以在多个分区上并行处理,最后汇总结果。
(5)分区表更容易维护。
例如:想批量删除大量数据可以清除整个分区,可以备份和恢复独立的分区
二、分区表的限制
1、分区数目有限
一个表最多只能有1024个分区,在5.7版本的时候可以支持8196个分区。
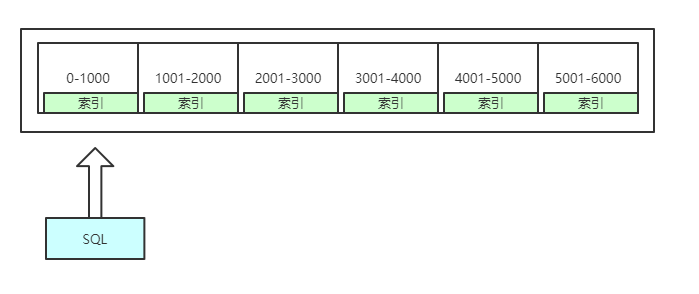
2、分别表表达式的限制
MySQL5.1中,分区表达式必须是整数,或者返回整数的表达式。在MySQL5.5中提供了非整数表达式分区的支持。
3、分区表对索引的限制
如果分区字段中有主键或者唯一索引的列,那么多有主键列和唯一索引列都必须包含进来。即:分区字段要么不包含主键或者索引列,要么包含全部主键和索引列。
4、分区表中无法使用外键约束
5、数据与索引同在
MySQL的分区适用于一个表的所有数据和索引,不能只对表数据分区而不对索引分区,也不能只对索引分区而不对表分区,也不能只对表的一部分数据分区。
三、分区表的原理
分区表由多个相关的底层表实现,这个底层表也是由句柄对象标识,我们可以直接访问各个分区。存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引知识在各个底层表上各自加上一个完全相同的索引。从存储引擎的角度来看,底层表和普通表没有任何不同,存储引擎也无须知道这是一个普通表还是一个分区表的一部分。
分区表的操作按照以下的操作逻辑进行:
1、select查询
当查询一个分区表的时候,分区层先打开并锁住所有的底层表,优化器先判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据
2、insert操作
当写入一条记录的时候,分区层先打开并锁住所有的底层表,然后确定哪个分区接受这条记录,再将记录写入对应底层表
3、delete操作
当删除一条记录时,分区层先打开并锁住所有的底层表,然后确定数据对应的分区,最后对相应底层表进行删除操作
4、update操作
当更新一条记录时,分区层先打开并锁住所有的底层表,mysql先确定需要更新的记录再哪个分区,然后取出数据并更新,再判断更新后的数据应该再哪个分区,最后对底层表进行写入操作,并对源数据所在的底层表进行删除操作
5、注意
有些操作时支持过滤的,例如,当删除一条记录时,MySQL需要先找到这条记录,如果where条件恰好和分区表达式匹配,就可以将所有不包含这条记录的分区都过滤掉,这对update同样有效。如果是insert操作,则本身就是只命中一个分区,其他分区都会被过滤掉。mysql先确定这条记录属于哪个分区,再将记录写入对应得曾分区表,无须对任何其他分区进行操作。
虽然每个操作都会“先打开并锁住所有的底层表”,但这并不是说分区表在处理过程中是锁住全表的,如果存储引擎能够自己实现行级锁,例如innodb,则会在分区层释放对应表锁。
四、分区表的类型
1、范围分区
根据列值在给定范围内将行分配给分区。
范围分区表的分区方式是:每个分区都包含行数据且分区的表达式在给定的范围内,分区的范围应该是连续的且不能重叠,可以使用values less than运算符来定义。
(1)、创建普通的表
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
);
(2)、按照store_id来进行分区
创建带分区的表,下面建表的语句是按照store_id来进行分区的,指定了4个分区
CREATE TABLE employees2 (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);
(3)、less than maxvalue的使用
在当前的建表语句中可以看到,store_id的值在1-5的在p0分区,6-10的在p1分区,11-15的在p3分区,16-20的在p4分区,但是如果插入超过20的值就会报错,因为mysql不知道将数据放在哪个分区,可以使用less than maxvalue来避免此种情况。
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
--maxvalue表示始终大于等于最大可能整数值的整数值
(4)、根据职务代码分区
可以使用相同的方式根据员工的职务代码对表进行分区
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (job_code) (
PARTITION p0 VALUES LESS THAN (100),
PARTITION p1 VALUES LESS THAN (1000),
PARTITION p2 VALUES LESS THAN (10000)
);
(5)、用date类型进行分区
可以使用date类型进行分区:如虚妄根据每个员工离开公司的年份进行划分,如year(separated)
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY RANGE ( YEAR(separated) ) (
PARTITION p0 VALUES LESS THAN (1991),
PARTITION p1 VALUES LESS THAN (1996),
PARTITION p2 VALUES LESS THAN (2001),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
(6)、用函数来对表进行分区
可以使用函数根据range的值来对表进行分区,如timestampunix_timestamp()
CREATE TABLE quarterly_report_status (
report_id INT NOT NULL,
report_status VARCHAR(20) NOT NULL,
report_updated TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)
PARTITION BY RANGE ( UNIX_TIMESTAMP(report_updated) ) (
PARTITION p0 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-01-01 00:00:00') ),
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-04-01 00:00:00') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-07-01 00:00:00') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-10-01 00:00:00') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-01-01 00:00:00') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-04-01 00:00:00') ),
PARTITION p6 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-07-01 00:00:00') ),
PARTITION p7 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-10-01 00:00:00') ),
PARTITION p8 VALUES LESS THAN ( UNIX_TIMESTAMP('2010-01-01 00:00:00') ),
PARTITION p9 VALUES LESS THAN (MAXVALUE)
);
--timestamp不允许使用任何其他涉及值的表达式
2、基于时间间隔分区
基于时间间隔的分区方案,在mysql5.7中,可以基于范围或事件间隔实现分区方案,有两种选择
1、基于范围的分区,对于分区表达式,可以使用操作函数基于date、time、或者datatime列来返回一个整数值
CREATE TABLE members (
firstname VARCHAR(25) NOT NULL,
lastname VARCHAR(25) NOT NULL,
username VARCHAR(16) NOT NULL,
email VARCHAR(35),
joined DATE NOT NULL
)
PARTITION BY RANGE( YEAR(joined) ) (
PARTITION p0 VALUES LESS THAN (1960),
PARTITION p1 VALUES LESS THAN (1970),
PARTITION p2 VALUES LESS THAN (1980),
PARTITION p3 VALUES LESS THAN (1990),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
CREATE TABLE quarterly_report_status (
report_id INT NOT NULL,
report_status VARCHAR(20) NOT NULL,
report_updated TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)
PARTITION BY RANGE ( UNIX_TIMESTAMP(report_updated) ) (
PARTITION p0 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-01-01 00:00:00') ),
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-04-01 00:00:00') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-07-01 00:00:00') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-10-01 00:00:00') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-01-01 00:00:00') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-04-01 00:00:00') ),
PARTITION p6 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-07-01 00:00:00') ),
PARTITION p7 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-10-01 00:00:00') ),
PARTITION p8 VALUES LESS THAN ( UNIX_TIMESTAMP('2010-01-01 00:00:00') ),
PARTITION p9 VALUES LESS THAN (MAXVALUE)
);
2、基于范围列的分区,使用date或者datatime列作为分区列
CREATE TABLE members (
firstname VARCHAR(25) NOT NULL,
lastname VARCHAR(25) NOT NULL,
username VARCHAR(16) NOT NULL,
email VARCHAR(35),
joined DATE NOT NULL
)
PARTITION BY RANGE COLUMNS(joined) (
PARTITION p0 VALUES LESS THAN ('1960-01-01'),
PARTITION p1 VALUES LESS THAN ('1970-01-01'),
PARTITION p2 VALUES LESS THAN ('1980-01-01'),
PARTITION p3 VALUES LESS THAN ('1990-01-01'),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
3、列表分区
类似于按range分区,区别在于list分区是基于列值匹配一个离散值集合中的某个值来进行选择
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
4、列分区
mysql从5.5开始支持column分区,可以认为i是range和list的升级版,在5.5之后,可以使用column分区替代range和list,但是column分区只接受普通列不接受表达式
CREATE TABLE `list_c` (
`c1` int(11) DEFAULT NULL,
`c2` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
/*!50500 PARTITION BY RANGE COLUMNS(c1)
(PARTITION p0 VALUES LESS THAN (5) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (10) ENGINE = InnoDB) */
CREATE TABLE `list_c` (
`c1` int(11) DEFAULT NULL,
`c2` int(11) DEFAULT NULL,
`c3` char(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
/*!50500 PARTITION BY RANGE COLUMNS(c1,c3)
(PARTITION p0 VALUES LESS THAN (5,'aaa') ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (10,'bbb') ENGINE = InnoDB) */
CREATE TABLE `list_c` (
`c1` int(11) DEFAULT NULL,
`c2` int(11) DEFAULT NULL,
`c3` char(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
/*!50500 PARTITION BY LIST COLUMNS(c3)
(PARTITION p0 VALUES IN ('aaa') ENGINE = InnoDB,
PARTITION p1 VALUES IN ('bbb') ENGINE = InnoDB) */
5、hash分区
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含myql中有效的、产生非负整数值的任何表达式
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH(store_id)
PARTITIONS 4;
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LINEAR HASH(YEAR(hired))
PARTITIONS 4;
6、key分区
类似于hash分区,区别在于key分区只支持一列或多列,且mysql服务器提供其自身的哈希函数,必须有一列或多列包含整数值
CREATE TABLE tk (
col1 INT NOT NULL,
col2 CHAR(5),
col3 DATE
)
PARTITION BY LINEAR KEY (col1)
PARTITIONS 3;
7、子分区
在分区的基础之上,再进行分区后存储
CREATE TABLE `t_partition_by_subpart`
(
`id` INT AUTO_INCREMENT,
`sName` VARCHAR(10) NOT NULL,
`sAge` INT(2) UNSIGNED ZEROFILL NOT NULL,
`sAddr` VARCHAR(20) DEFAULT NULL,
`sGrade` INT(2) NOT NULL,
`sStuId` INT(8) DEFAULT NULL,
`sSex` INT(1) UNSIGNED DEFAULT NULL,
PRIMARY KEY (`id`, `sGrade`)
) ENGINE = INNODB
PARTITION BY RANGE(id)
SUBPARTITION BY HASH(sGrade) SUBPARTITIONS 2
(
PARTITION p0 VALUES LESS THAN(5),
PARTITION p1 VALUES LESS THAN(10),
PARTITION p2 VALUES LESS THAN(15)
);
五、如何使用分区表
如果需要从非常大的表中查询出某一段时间的记录,而这张表中包含很多年的历史数据,数据是按照时间排序的,此时应该如何查询数据呢?
因为数据量巨大,肯定不能在每次查询的时候都扫描全表。考虑到索引在空间和维护上的消耗,也不希望使用索引,即使使用索引,会发现会产生大量的碎片,还会产生大量的随机IO,但是当数据量超大的时候,索引也就无法起作用了,此时可以考虑使用分区来进行解决
1、全量扫描数据,不要任何索引
使用简单的分区方式存放表,不要任何索引,根据分区规则大致定位需要的数据为止,通过使用where条件将需要的数据限制在少数分区中,这种策略适用于以正常的方式访问大量数据
2、索引数据,并分离热点
如果数据有明显的热点,而且除了这部分数据,其他数据很少被访问到,那么可以将这部分热点数据单独放在一个分区中,让这个分区的数据能够有机会都缓存在内存中,这样查询就可以只访问一个很小的分区表,能够使用索引,也能够有效的使用缓存
六、使用分区表需要注意的问题
1、null值会使分区过滤无效
2、分区列和索引列不匹配,会导致查询无法进行分区过滤
3、选择分区的成本可能很高
4、打开并锁住所有底层表的成本可能很高
5、维护分区的成本可能很高
MySQL调优之分区表的更多相关文章
- MySQL 调优/优化的 100 个建议
MySQL 调优/优化的 100 个建议 MySQL是一个强大的开源数据库.随着MySQL上的应用越来越多,MySQL逐渐遇到了瓶颈.这里提供 101 条优化 MySQL 的建议.有些技巧适合特定 ...
- MySQL 调优基础(一) CPU与进程
一般而言,MySQL 的调优可以分为两个层面,一个是在MySQL层面上进行的调优,比如SQL改写,索引的添加,MySQL各种参数的配置:另一个层面是从操作系统的层面和硬件的层面来进行调优.操作系统的层 ...
- MySQL调优系列基础篇
前言 有一段时间没有写博客了,整天都在忙,上班,录制课程,恰巧最近一段时间比较清闲,打算弄弄MYSQL数据库. 关于MySQL数据库,这里就不做过多的介绍,开源.免费等特性深受各个互联网行业喜爱,尤其 ...
- mysql调优 基础
MySQL调优可以从几个方面来做: 1. 架构层:做从库,实现读写分离: 2.系统层次:增加内存:给磁盘做raid0或者raid5以增加磁盘的读写速度:可以重新挂载磁盘,并加上noatime参数,这样 ...
- mysql调优最大连接数
一.mysql调优 1.1 报错: Mysql: error 1040: Too many connections 1.2 原因: 1.访问量过高,MySQL服务器抗不住,这个时候就要考虑增加从服务器 ...
- MySQL调优 —— Using temporary
DBA发来一个线上慢查询问题. SQL例如以下(为突出重点省略部分内容): select distinct article0_.id, 等字段 from article_table article ...
- 数据库MySQL调优实战经验总结<转>
数据库MySQL调优实战经验总结 MySQL 数据库的使用是非常的广泛,稳定性和安全性也非常好,经历了无数大小公司的验证.仅能够安装使用是远远不够的,MySQL 在使用中需要进行不断的调整参数或优化设 ...
- MySQL调优 优化需要考虑哪些方面
MySQL调优 优化需要考虑哪些方面 优化目标与方向定位 总体目标:使得响应时间更快,吞吐量更大. (throughout --- 吞吐量:单位时间内处理事务的数量) 如何找到需要优化的地方 使用 ...
- Mysql 调优和水平扩展思路
系统调优参数 一些比较重要的参数: back_log:back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中.如果MySql的连接数据达到max_connecti ...
随机推荐
- 蚂蚁开源的 SOFABoot,和 Spring Boot 有啥关系?
一.SOFABoot 是什么鬼? 说到 SOFABoot,不得不先说下 SOFARPC 框架,SOFARPC 也是大名远扬,最早起源于阿里淘宝 HSF 框架,现在是蚂蚁金服开源的一款高性能.高可扩展性 ...
- 如何将离线计算业务的成本降低65%——弹性容器服务EKS「竞价实例」上线
在容器化的应用场景中,大数据计算是其中很大并且业务应用在逐渐增加的一个热门领域,包括越来越多的人工智能企业,都在使用容器技术来支持业务中的大量计算任务.降低成本.提升资源利用率也是当前这部分用户非常期 ...
- 基于websocket的netty demo
前面2文 基于http的netty demo 基于socket的netty demo 讲了netty在http和socket的使用,下面讲讲netty如何使用websocket websocket是h ...
- java类的主动使用/被动使用
对类的使用方式分为:主动使用.被动使用 所有的java虚拟机实现必须在每个类或接口被java程序"首次主动使用"时才初始化他们 ps:被动使用不会初始化类,但是有可能会加载类(JV ...
- CentOs 7 安装mysql5.7.18(二进制版本)
1.下载二进制版本安装包.搜狐开源镜像站:http://mirrors.sohu.com/mysql/MySQL-5.7/ , 找 mysql-5.7.18-linux-glibc2.5-x86_ ...
- PHPer 面试
A:怎么保证促销商品不会超卖? 答:这个问题是我们当时开发时遇到的一个难点,超卖的原因主要是下的订单的数目和我们要促销的商品的数目不一致导致的,每次总是订单的数比我们的促销商品的数目要多,当时我们的小 ...
- Flink SQL 核心概念剖析与编程案例实战
本次,我们从 0 开始逐步剖析 Flink SQL 的来龙去脉以及核心概念,并附带完整的示例程序,希望对大家有帮助! 本文大纲 一.快速体验 Flink SQL 为了快速搭建环境体验 Flink SQ ...
- Lesson_strange_words4
mount on 安装 arc 弧 actuator 马达,致动器:调节器 roughly 大致,大约 radially 径向,放射状 stepper 步进机 motor 电机,发动机 sequent ...
- 【基础】1001_Hello,World!
题目相关 [题目描述] 编写一个能够输出"Hello,World!"的程序,这个程序常常作为一个初学者接触一门新的编程语言所写的第一个程序,也经常用来测试开发.编译环境是否能够正常 ...
- Linux下安装Oracle11g服务器【转】
安装环境 Linux服务器:oracle linux 6.6 64位 Oracle服务器:Oracle11gR2 64位 系统要求 Linux安装Oracle系统要求 系统要求 说明 内存 必须高于1 ...