少标签数据学习:宾夕法尼亚大学Learning with Few Labeled Data

原文链接 小样本学习与智能前沿 。 在这个公众号后台回复“200527”,即可获得课件电子资源。

Few-shot image classification
Three regimes of image classification

Problem formulation
Training set consists of labeled samples from lots of “tasks”, e.g., classifying cars, cats, dogs, planes . . .
Data from the new task, e.g., classifying strawberries has:

Few-shot setting considers the case when s is small.
A flavor of current few-shot algorithms
Meta-learning forms the basis for almost all current algorithms. Here’s one successful instantiation.
Prototypical Networks [Snell et al., 2017]
- Collect a meta-training set, this consists of a large number of related tasks
- Train one model on all these tasks to ensure that the clustering of features of this model correctly classifies the task
- If the test task comes from the same distribution as the meta-training tasks, we can use the clustering on the new task to classify new classes
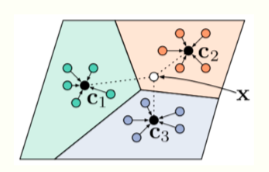
How well does few-shot learning work today?

The key idea
A classifier trained on a dataset \(D_s\) is a function F that classifies data x using
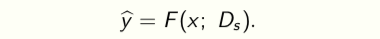
The parameters \(θ^∗ = θ(D_s )\) of the classifier are a statistic of the dataset Ds obtained after training. Maintaining this statistic avoids having to search over functions F at inference time.
We cannot learn a good (sufficient) statistic using few samples. So we will search over functions at test-time more explicitly
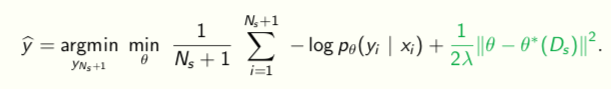
Transductive Learning
 ## A very simple baseline
## A very simple baseline
- Train a large deep network on the meta-training dataset with the standard classification loss
- Initialize a new “classifier head” on top of the logits to handle new classes
- Fine-tune with the few labeled data from the new task
- Perform transductive learning using the unlabeled test data
with a few practical tricks like cosine annealing of step-sizes,
mixup regularization, 16-bit training, very heavy data augmentation, and label smoothing cross-entrop
An example

Results on benchmark datasets

The ImageNet-21k dataset

1-shot, 5-way accuracies are as high as 89%, 1-shot 20-way accuracies are about 70%.
A proposal for systematic evaluation

A thermodynamical view of representation learning
表征学习的热力学观点
Transfer learning
Let’s take an example from computer vision
(.Zamir, A. R., Sax, A., Shen, W., Guibas, L. J., Malik, J., & Savarese, S. Taskonomy: Disentangling task transfer learning. CVPR 2018)

Information Bottleneck Principle
信息瓶颈原则
A generalization of rate-distortion theory for learning relevant representations of data [Tishby et al., 2000]
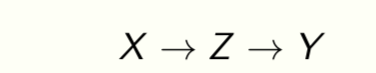
Z is a representation of the data X. We want
- Z to be sufficient to predict the target Y , and
- Z to be small in size, e.g., few number of bits.
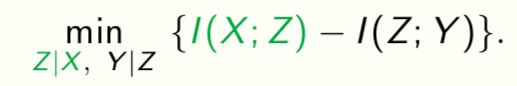
Doing well on one task requires throwing away nuisance information [Achille & Soatto, 2017].
The key idea
The IB Lagrangian simply minimizes \(I(X;Z)\), it does not let us measure what was thrown away.
Choose a canonical task to measure discarded information. Setting
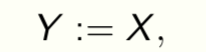
i.e., reconstruction of data, gives a special task. It is the superset of all tasks and forces the model to learn lossless representations.
The architecture we will focus on is

An auto-encoder
Shanon entropy measures the complexity of data
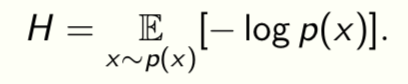
Distortion D measures the quality of reconstruction
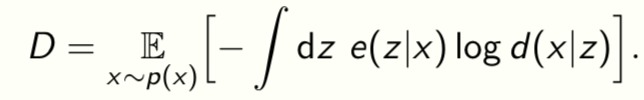
Rate R measures the average excess bits used to encode the representation
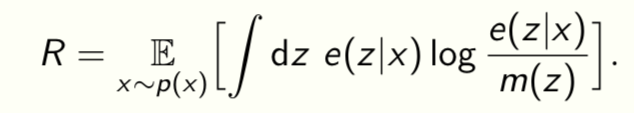
Rate-Distortion curve
We know that [Alemi et al., 2017]
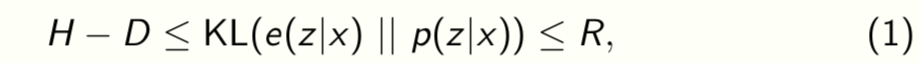
this is the well-known ELBO (evidence lower-bound). Let
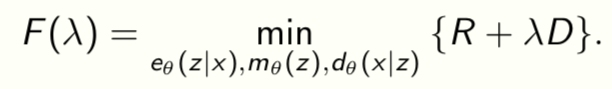
This is a Lagrange relaxation of the fact that given a variational family and data there is an optimal value R = func(D) that best sandwiches (1).

Rate-Distortion-Classification (RDC) surface
Let us extend the Lagrangian to

where the classification loss is
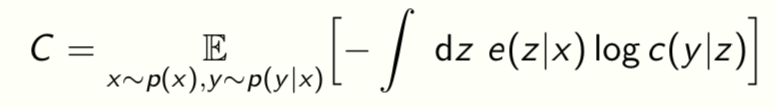
Can also include other quantities like the entropy S of the model parameters
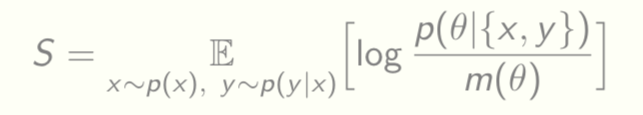

The existence of a convex surface func(R,D,C,S) = 0 tying together these functionals allows a formal connection to thermodynamics [Alemi and Fischer 2018]
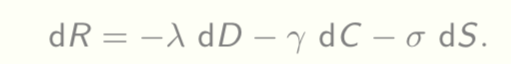
Just like energy is conserved in physical processes, information is conserved in the model, either it is in the encoder-classifier pair or it is in the decoder.
Equilibrium surface of optimal free-energy
The RDC surface determines all possible representations that can be learnt from given data. Can solve the variational problem for F(λ,γ) to get
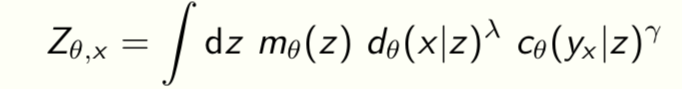
and
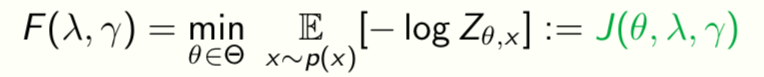
This is called the “equilibrium surface” because training converges to some point on this surface. We now construct ways to travel on the surface
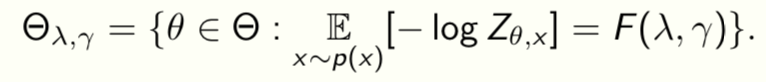 The surface depends on data p(x,y).
The surface depends on data p(x,y).
An iso-classification loss process
A quasi-static process happens slowly enough for the system to remain in equilibrium with its surroundings, e.g., reversible expansion of an ideal gas.
We will create a quasi-static process to travel on the RDC surface. This constraint is
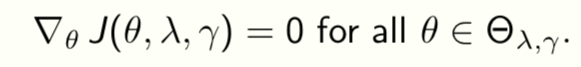
e.g., if we want classification loss to be constant in time, we need

……
更多精彩,请下载 资源文件 了解。
关注公众号“小样本学习与智能前沿”,回台回复“200527” ,即可获取资源文件“Learning with Few Labeled Data.pdf”

Summary
Simple methods such as transductive fine-tuning work extremely well for few-shot learning. This is really because of powerful function approximators such as neural networks.
The RDC surface is a fundamental quantity and enables principled methods for transfer learning. Also unlocks new paths to understanding regularization and properties of neural architecture for classical supervised learning.
We did well in the era of big data without understanding much about data; this is unlikely to work in the age of little data.
Email questions to pratikac@seas.upenn.edu Read more at
- Dhillon, G., Chaudhari, P., Ravichandran, A., and Soatto, S. (2019). A baseline for few-shot image classification. arXiv:1909.02729. ICLR 2020.
- Li, H., Chaudhari, P., Yang, H., Lam, M., Ravichandran, A., Bhotika, R., & Soatto, S. (2020). Rethinking the Hyperparameters for Fine-tuning. arXiv:2002.11770. ICLR 2020.
- Fakoor, R., Chaudhari, P., Soatto, S., & Smola, A. J. (2019). Meta-Q-Learning. arXiv:1910.00125. ICLR 2020.
- Gao, Y., and Chaudhari, P. (2020). A free-energy principle for representation learning. arXiv:2002.12406.
少标签数据学习:宾夕法尼亚大学Learning with Few Labeled Data的更多相关文章
- 【转载】 迁移学习(Transfer learning),多任务学习(Multitask learning)和端到端学习(End-to-end deep learning)
--------------------- 作者:bestrivern 来源:CSDN 原文:https://blog.csdn.net/bestrivern/article/details/8700 ...
- PU Learning简介:对无标签数据进行半监督分类
当只有几个正样本,你如何分类无标签数据 假设您有一个交易业务数据集.有些交易被标记为欺诈,其余交易被标记为真实交易,因此您需要设计一个模型来区分欺诈交易和真实交易. 假设您有足够的数据和良好的特征,这 ...
- 联邦学习(Federated Learning)
联邦学习简介 联邦学习(Federated Learning)是一种新兴的人工智能基础技术,在 2016 年由谷歌最先提出,原本用于解决安卓手机终端用户在本地更新模型的问题,其设计目标是 ...
- 零次学习(Zero-Shot Learning)入门(转)
很久没有更文章了,主要是没有找到zero-shot learning(ZSL)方面我特别想要分享的文章,且中间有一段时间在考虑要不要继续做这个题目,再加上我懒 (¬_¬),所以一直拖到了现在. 最近科 ...
- 小样本学习(few-shot learning)在文本分类中的应用
1,概述 目前有效的文本分类方法都是建立在具有大量的标签数据下的有监督学习,例如常见的textcnn,textrnn等,但是在很多场景下的文本分类是无法提供这么多训练数据的,比如对话场景下的意图识别, ...
- 【47】迁移学习(Transfer Learning)
迁移学习(Transfer Learning) 如果你要做一个计算机视觉的应用,相比于从头训练权重,或者说从随机初始化权重开始,如果你下载别人已经训练好网络结构的权重,你通常能够进展的相当快,用这个作 ...
- 多视图学习(multiview learning)
多视图学习(multi-view learning) 前期吹牛:今天这一章我们就是来吹牛的,刚开始老板在和我说什么叫多视图学习的时候,我的脑海中是这么理解的:我们在欣赏妹子福利照片的时候,不能只看45 ...
- 深度学习(Deep Learning)资料大全(不断更新)
Deep Learning(深度学习)学习笔记(不断更新): Deep Learning(深度学习)学习笔记之系列(一) 深度学习(Deep Learning)资料(不断更新):新增数据集,微信公众号 ...
- 读李宏毅《一天看懂深度学习》——Deep Learning Tutorial
大牛推荐的入门用深度学习导论,刚拿到有点懵,第一次接触PPT类型的学习资料,但是耐心看下来收获还是很大的,适合我这种小白入门哈哈. 原PPT链接:http://www.slideshare.net/t ...
随机推荐
- Docker 基础 B站 学习 最强 教程
狂神说!! https://www.bilibili.com/video/BV1og4y1q7M4
- Linux系统中使用confluence构建企业wiki
搭建confluence服务需要的步骤有:一,安装java环境即安装jdk8.二,安装需要使用的数据库(建议使用mysql5.6).三,破解的confluence6服务. 一,所需软件下载 1,下载j ...
- C\C++语言重点——指针篇 | 为什么指针被誉为 C 语言灵魂?(一文让你完全搞懂指针)
本篇文章来自小北学长的公众号,仅做学习使用,部分内容做了适当理解性修改和添加了博主的个人经历. 注:这篇文章好好看完一定会让你掌握好指针的本质! 看到标题有没有想到什么? 是的,这一篇的文章主题是「指 ...
- Tensorflow学习---argmax中axis问题
一:argmax中axis问题 https://blog.csdn.net/qq575379110/article/details/70538051/ 总之:axis=0/1不是行/列关系 test ...
- 【笔记】nrf52832广播使用--厂商自定义数据应用
需求: 1)使用蓝牙不停发送ble广播,发送自定义的数据,并每一秒更新自定义数据. 2)设置不同的发射功率.广播间隔.广播名称 1.初始化 使用nordic官方sdk17版本,打开一个ble串口用例. ...
- 仿select下拉框
默认状态下,灰色面板出现.当点击页面按钮以及灰色面板外区域时,面板消失;点击按钮,灰色面板出现;点击灰色面板区域,面板不能消失. 主要考察:事件冒泡与取消事件冒泡. 代码: <!DOCTYPE ...
- 华为+京东数科(原京东金融)面经--Java后台开发
华为: 1.笔试中遇到的问题,如何解决的?(Scanner 如何结束循环读取数据,笔者在面试中因没有理解到Scanner类的hasNext()与hasNextLine()是阻塞方法,导致没有正确退出循 ...
- linux命令查看日志
首先介绍几个日志查看种常用的简单命令: 1.tail tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件. tail -f filename 会把 filenam ...
- 手写一个Web服务器,极简版Tomcat
网络传输是通过遵守HTTP协议的数据格式来传输的. HTTP协议是由标准化组织W3C(World Wide Web Consortium,万维网联盟)和IETF(Internet Engineerin ...
- mysql之索引组织表
1.二叉树/平衡树.B-tree.B+tree.B*tree 树:最上一层是根节点.最底下一层是叶子节点.(一般左边节点小于右边节点) 二叉树:每个节点最多只能有两个分支,一般只用于教材.二叉树的深度 ...