R语言学习笔记-Corrplot相关性分析
首先安装需要的包
install.packages("Corrplot") #安装Corrplot
install.packages("RColorBrewer ") #安装RColorBrewer
install.packages("showtext")#安装showtext
install.packages("sysfonts")#安装sysfonts
install.packages("showtextdb")#安装showtextdb
install.packages("showtext")#安装RColorBrewer
加载需要的包
lapply(c("corrplot","showtex","RColorBrewer","showtextdb","sysfonts"))
如果需要更换字体,就加载系统内字体
font.families() #查看添加的字体
showtext.begin() #加载字体
**showtext.end() #停止加载字体
导入数据[示例]
mydataframe<-read.csv(file,header=logical_value,sep="delimiter",row.names="name")
mydataframe:自定义数据名称,此处将集合名称定义为mydataframe
table:指读取文件格式为表格
file: csv文件的名称或路径夹名称
header:其后面逻辑值,可填写TRUE或FALSE,表示文件是否读取横列标题
sep:指文件分隔符,如csv用英文逗号分隔 ","
row.names:指定表示行标识符的变量(作为行名的表头)
本次利用自带的mtcars作为示例data(mtcars)#加载数据集
mydata <- mtcars[, c(1:7)]#使用前7行数据
查看数据
head(mydata)#查看数据
绘制图像
pic01<-cor(mydata)
corrplot(pic01)
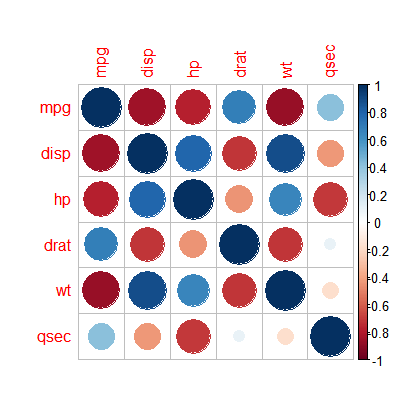
corrplot(mydata)
可以在括号内加入如下定义,改变图像。
method = c("circle"/"square"/"ellipse"/"number"/ "shade"/"color"/"pie"),
method:指定可视化的方法,可以是圆形、方形、椭圆形、数值、阴影、颜色或饼图形
type = c("full"/"lower"/"upper"),
type:指定展示的方式,可以是完全的图形、上三角或下三角(不填时默认为“full”)
col:指定图像的几种颜色,默认以均匀的颜色展示,以col = c("purple", "green","white")),为例,即指图标在(-1,1)区间以紫色、绿色、白色三种颜色的改变表示。
****可以通过colorRampPalette定义
COLOR01<- colorRampPalette(c("#5081ff","#638dff","#b1c6ff","#c3d5ff" ,"#ffffff", "#f7cccc","#f1aeac","#eb8b8a","#e66a68"))(10)
corrplot(pic01,col = COLOR01)
bg = c("white"/"black"/"pink"/……),
bg:指定图的背景色
title = "HokkaidoM",
mar=c(0, 0, 1, 0)
title:为图形添加标题
mar=c(0, 0, 1, 0) :设置图距离(下,左,上,右)四个边缘的距离
*****若使用标题title必须加mar=c(0, 0, 1, 0),不然标题显示不全
is.corr = TRUE,
is.corr:是否为相关系数绘图,默认为TRUE,同样也可以实现非相关系数的可视化,只需使该参数设为FALSE即可
diag = TRUE,
diag:是否展示对角线上的结果,默认为TRUE
outline = FALSE,
outline:是否绘制圆形、方形或椭圆形的轮廓,默认为FALSE
addgrid.col = NULL,
addgrid.col:当选择的方法为颜色或阴影时,默认的网格线颜色为白色,否则为灰色
addCoef.col = NULL,
addCoef.col:为相关系数添加颜色,默认不添加相关系数,只有方法为number时,该参数才起作用
addCoefasPercent = FALSE,
addCoefasPercent:为节省绘图空间,是否将相关系数转换为百分比格式,默认为FALSE
order = c("original", "AOE", "FPC", "hclust", "alphabet"),
hclust.method = c("complete", "ward", "single", "average", "mcquitty", "median", "centroid"),
order:指定相关系数排序的方法,可以是原始顺序(original)、特征向量角序(AOE)、第一主成分顺序(FPC)、层次聚类顺序(hclust)和字母顺序,一般”AOE”排序结果都比”FPC”要好
hclust.method:当order为hclust时,该参数可以是层次聚类中ward法、最大距离法等7种之一
addrect = NULL,
rect.col = "black",
rect.lwd = 2,
addrect:当order为hclust时,可以为添加相关系数图添加矩形框,默认不添加框,如果想添加框时,只需为该参数指定一个整数即可
rect.col:指定矩形框的颜色
rect.lwd:指定矩形框的线宽
tl.pos = NULL,
tl.pos:指定文本标签(变量名称)的位置,当type=full时,默认标签位置在左边和顶部(lt),当type=lower时,默认标签在左边和对角线(ld),当type=upper时,默认标签在顶部和对角线,l、r代表左右,d表示对角线,n表示不添加文本标签
tl.cex = 1,
tl.cex:指定文本标签的大小
tl.col = "red",
tl.col:指定文本标签的颜色
tl.offset = 0.4,
tl.offset:设置文本标签偏移量,即文本标签和图像的距离
tl.srt = 90,
tl.srt:文本标签角度
cl.pos = "b"/"r"/"n"
cl.pos:图例(颜色)位置,r图例在右表,b图例在底部,不需要图例时,只需指定该参数为n
cl.lim = (x1,x2),
颜色区间限制
cl.length = 数字
颜色区间刻度间隔的数量
cl.cex = 0.8,
颜色刻度标签数字大小
cl.ratio = 0.15,
颜色刻度粗细
cl.align.text = "l","c","r",
刻度标签数字显示在每个刻度的靠左处/中央/靠右处
cl.offset = 0.5,
刻度标签与颜色刻度条的距离
addshade = c("negative", "positive", "all"),
addshade:只有当method=shade时,该参数才有用,参数值可以是negtive/positive和all,分表表示对负相关系数、正相关系数和所有相关系数添加阴影。注意:正相关系数的阴影是45度,负相关系数的阴影是135度
shade.lwd = 1,
shade.lwd:指定阴影的线宽
shade.col = "white",
shade.col:指定阴影线的颜色
addCoef.col=”颜色”
addCoef.col:增加p值
add = TRUE
add = :是否与另一图片拼接,默认为false
p.mat 分析/显著性分析
cor.mtest <- function(mat, ...) {
mat <- as.matrix(mat)
n <- ncol(mat)
p.mat<- matrix(NA, n, n)
diag(p.mat) <- 0
for (i in 1:(n - 1)) {
for (j in (i + 1):n) {
tmp <- cor.test(mat[, i], mat[, j], ...)
p.mat[i, j] <- p.mat[j, i] <- tmp$p.value
}
}
colnames(p.mat) <- rownames(p.mat) <- colnames(mat)
p.mat
}
#构建cor.mtest函数
mydatap<- cor.mtest(mydata) #计算原始数据的p.mat并定义此数据集合
sig.level = 0.05,
筛选的标准以0.05为界 sig.level = c(0.001,0.01,0.05)
设置筛选的各个区间值 insig = c("pch","p-value","blank", "n"),
被筛选的不显著值为叉叉、p值数字、不显示任何东西、n insig = "label_sig"
设置被筛选出的为显著值 pch = 4, pch.col = "black", pch.cex = 3,
plotCI = c("n","square", "circle", "rect"),
lowCI.mat = NULL,
uppCI.mat = NULL, ...)
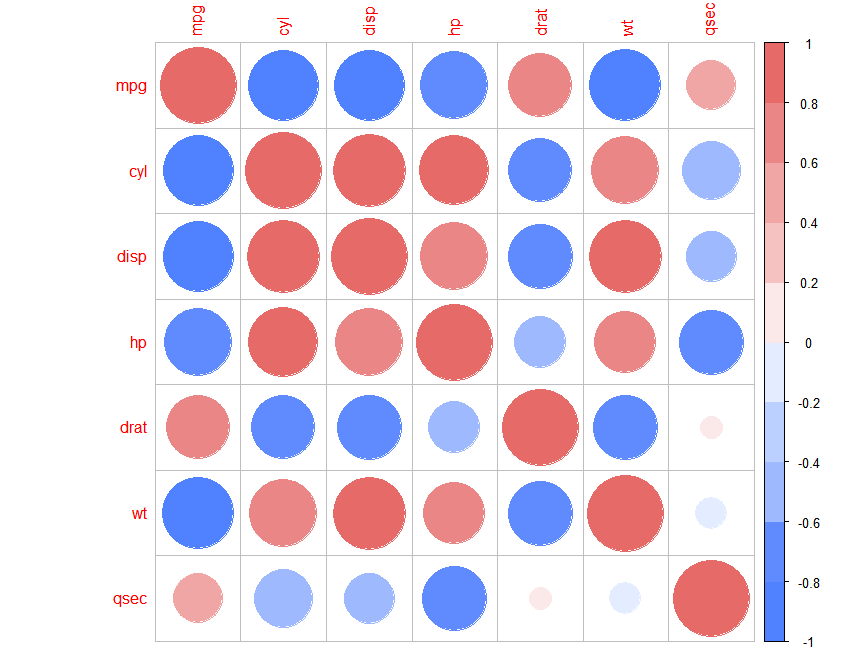
corrplot(pic01, type = "upper", order = "hclust", p.mat=mydatap, sig.level = 0.05, insig = "label_sig")#绘图,标记显著值
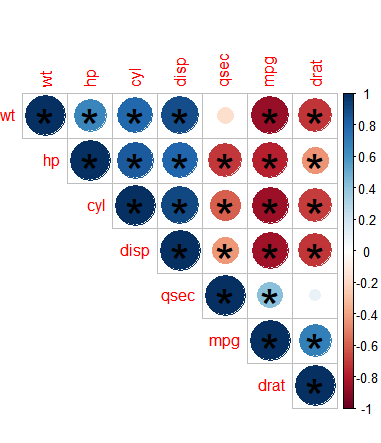
corrplot(pic01, type="upper", order="hclust", p.mat = mydatap, sig.level = 0.05)#绘图,把不显著的叉掉

corrplot(pic01, type = "upper", order = "hclust", p.mat=mydatap, sig.level = 0.05, insig="blank")
#绘图,把不显著的空掉
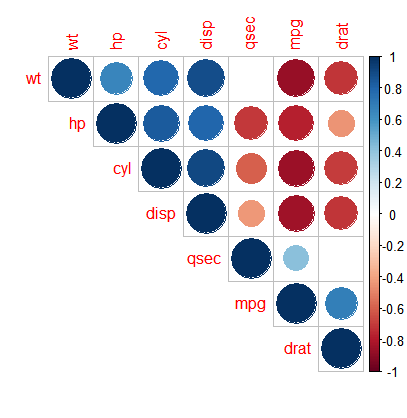
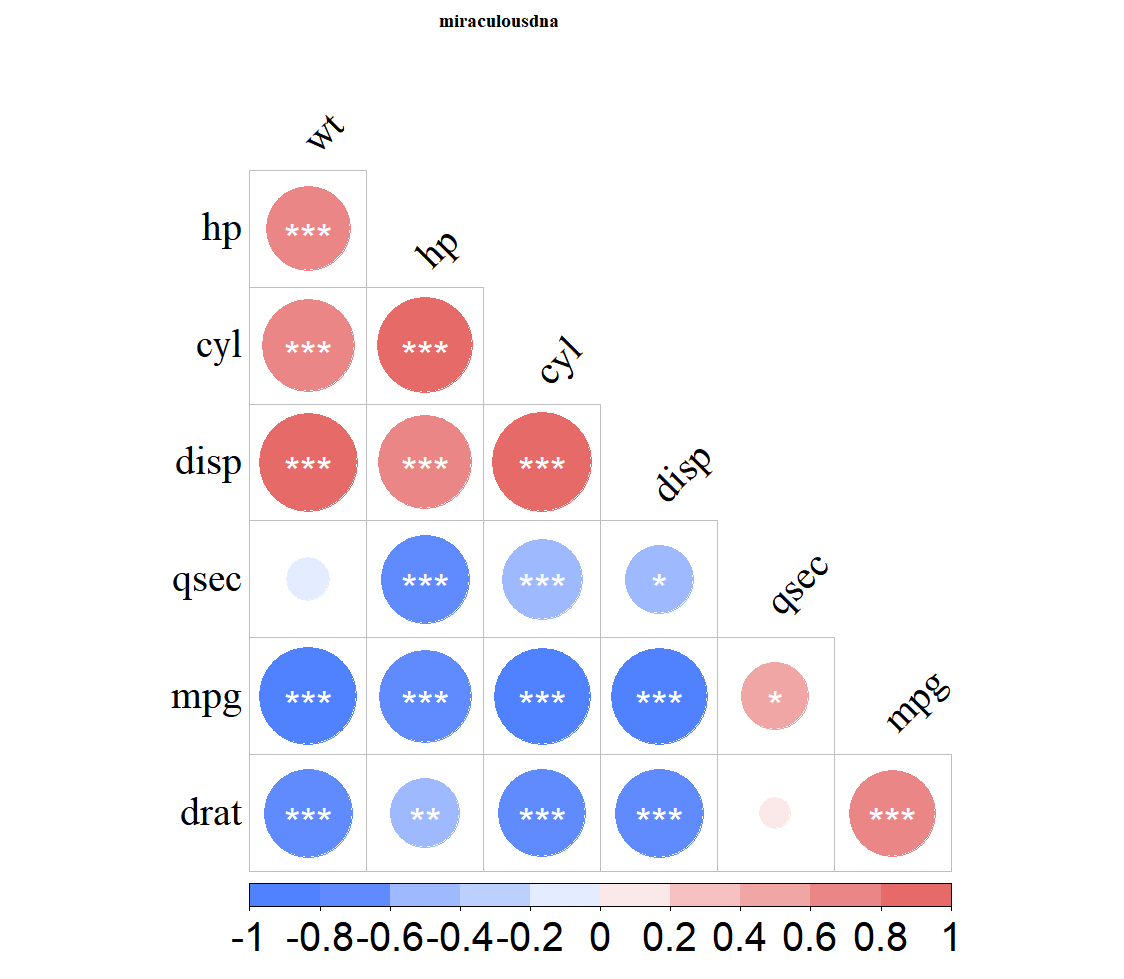
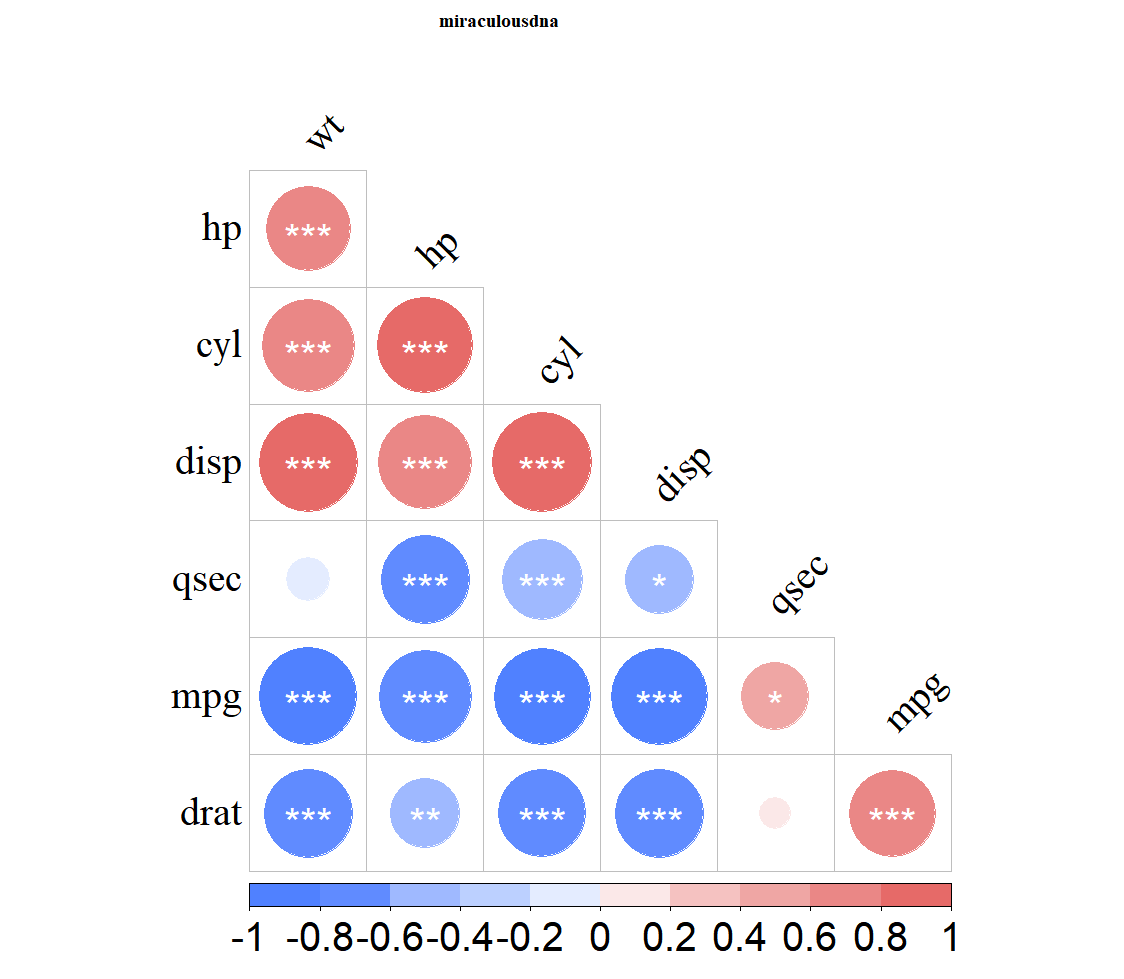
corrplot(pic01,
type="lower",
order="hclust",
p.mat=mydatap,
insig = "label_sig",
sig.level = c(0.001,0.01,0.05),
pch.cex = 2.5,pch.col="white",
diag = FALSE,tl.srt =45,tl.col = "black",
family="serif",col = COLOR01,
tl.cex = 2.5,title = "miraculousdna",
mar=c(0, 0, 1, 0),cl.cex = 2.5
)
R语言学习笔记-Corrplot相关性分析的更多相关文章
- R语言学习笔记:分析学生的考试成绩
孩子上初中时拿到过全年级一次考试所有科目的考试成绩表,正好可以用于R语言的统计分析学习.为了不泄漏孩子的姓名,就用学号代替了,感兴趣可以下载测试数据进行练习. num class chn math e ...
- R语言学习笔记:基础知识
1.数据分析金字塔 2.[文件]-[改变工作目录] 3.[程序包]-[设定CRAN镜像] [程序包]-[安装程序包] 4.向量 c() 例:x=c(2,5,8,3,5,9) 例:x=c(1:100) ...
- R语言学习笔记之: 论如何正确把EXCEL文件喂给R处理
博客总目录:http://www.cnblogs.com/weibaar/p/4507801.html ---- 前言: 应用背景兼吐槽 继续延续之前每个月至少一次更新博客,归纳总结学习心得好习惯. ...
- R语言学习笔记(二)
今天主要学习了两个统计学的基本概念:峰度和偏度,并且用R语言来描述. > vars<-c("mpg","hp","wt") &g ...
- R语言学习笔记
向量化的函数 向量化的函数 ifelse/which/where/any/all/cumsum/cumprod/对于矩阵而言,可以使用rowSums/colSums.对于“穷举所有组合问题" ...
- R语言学习笔记:小试R环境
买了三本R语言的书,同时使用来学习R语言,粗略翻下来感觉第一本最好: <R语言编程艺术>The Art of R Programming <R语言初学者使用>A Beginne ...
- R语言学习笔记—K近邻算法
K近邻算法(KNN)是指一个样本如果在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.即每个样本都可以用它最接近的k个邻居来代表.KNN算法适 ...
- R语言学习笔记:使用reshape2包实现整合与重构
R语言中提供了许多用来整合和重塑数据的强大方法. 整合 aggregate 重塑 reshape 在整合数据时,往往将多组观测值替换为根据这些观测计算的描述统计量. 在重塑数据时,则会通过修改数据的结 ...
- R语言学习笔记—朴素贝叶斯分类
朴素贝叶斯分类(naive bayesian,nb)源于贝叶斯理论,其基本思想:假设样本属性之间相互独立,对于给定的待分类项,求解在此项出现的情况下其他各个类别出现的概率,哪个最大,就认为待分类项属于 ...
随机推荐
- javascript是面向对象的,怎么体现javascript的继承关系?
一个简单的例子: var A =function(){ } A.prototype = { v : 5, tmp : 76, echo : function(){console.log(this.tm ...
- 【JVM】类加载器与双亲委派
类加载器,顾名思义,即是实现类加载的功能模块,负责将Class的字节码形式加载成内存形式的Class对象.字节码文件可来源于磁盘或者jar包中的Class文件,也可以来自网络字节流. 类加载器 在JV ...
- if-then-else、loop控制语句在SIMD指令下的后端指令生成实现--笔记
作者:Yaong 出处:https://www.cnblogs.com/yaongtime/p/14111134.html 版权:本文版权归作者和博客园共有 转载:欢迎转载,但未经作者同意,必须保留此 ...
- Tensorflow学习笔记No.11
图像定位 图像定位是指在图像中将我们需要识别的部分使用定位框进行定位标记,本次主要讲述如何使用tensorflow2.0实现简单的图像定位任务. 我所使用的定位方法是训练神经网络使它输出定位框的四个顶 ...
- css处理文字不换行、换行截断、溢出省略号
1.使文字不换行 white-space: nowrap; 值 描述 normal 默认.空白会被浏览器忽略. pre 空白会被浏览器保留.其行为方式类似 HTML 中的 <pre> 标签 ...
- NSMutableArray 的实现原理
一.普通C语言的数组实现: 是开辟一段连续的内存空间,缺点:在插入下标为0的元素,会移动其他所有元素.添加,插入,删除同理. 当数组非常大时,这样很快会成为问题. 二.OC ...
- .NET Core +Angular 项目 部署到CentOS
前言: 最近公司需要开发项目能在Linux系统上运行,示例开发项目采用.Net Core + Angular开发:理论上完全支持跨平台. 但是实践才是检验真理的唯一标准:那么还是动手来验证实现下:过程 ...
- 牛客挑战赛46 B
题目链接: 最小的指数 乍一看还以为是Pollard_rho算法,其实大可不必. 发现\(1<= n <= 1e18\),我们可以将n分为两部分(分块思想降低时间复杂度). 剔除小于等于\ ...
- ssh 免密码登陆设置不成功
记一次centos6设置免密码登陆设置不成功的解决.自己挖的坑自己填. ssh 免密码登陆设置( 正常情况下是这样的,设置成功后登陆主机是不需要密码的) [root@master .ssh]# ssh ...
- metinfo小于v6.2.0版本SQL盲注利用脚本
#coding=utf-8 import requests import re import sys import time #获取config_safe.php中的 key def getKey(u ...