保证看完就会!大数据YRAN核心知识点来袭!
01 我们一起学大数据
大家好,今天分享的是大数据YRAN的核心知识点,老刘尽量用通俗易懂的话来讲述YARN知识点,争取做到大家看完后能够用口语化的形式将它们表达出来,做到真正的看完就会!(如果觉得老刘写的不错,给老刘点个赞)
02 YARN核心知识点
第1点:什么是YARN?
YARN是Hadoop架构中的资源调度引擎模块,从这个模块名字就可以看出来,YARN是用来为应用提供资源管理和调度的。
类似于HDFS,YARN也是经典的主从架构。架构的内容放在第2点讲,如果面试介绍YARN的话,老刘建议第一点和第二点一起讲。
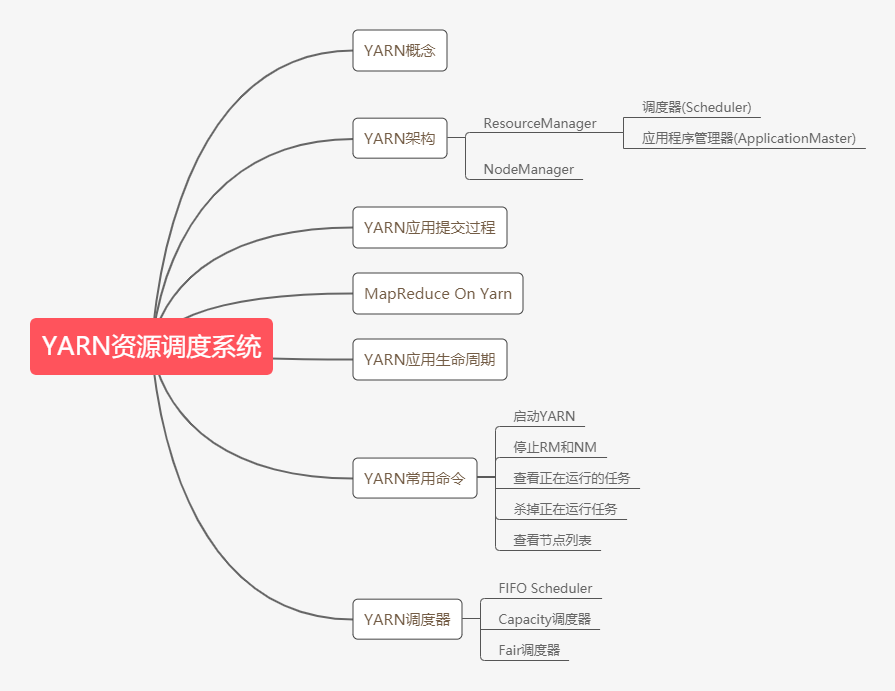
第2点:YRAN架构
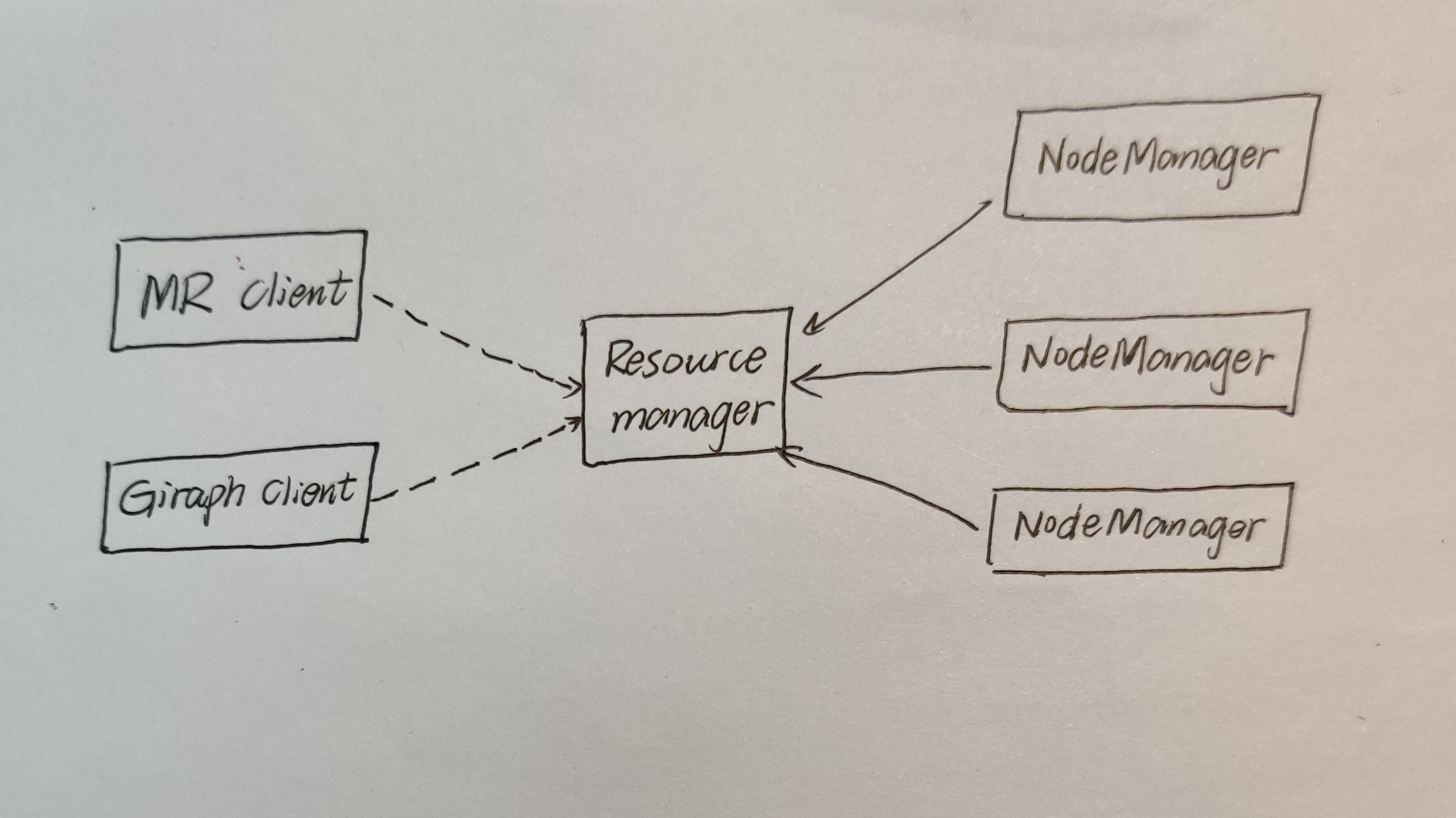
先看这张架构图,就可以知道YARN是非常典型的主从架构。YARN由一个ResourceManager(RM)和多个NodeManager(NM)构成,RM是主节点,NM是从节点。
什么是ResourceManager?
RM是一个全局的资源管理器,集群只有一个,它主要负责整个系统的资源管理和分配,启动监控ApplicationMaster,监控NodeManager以及资源的分配和调度。
RM主要由两个组件构成:调度器和应用程序管理器。
什么是调度器(Scheduler)?
调度器就是根据容量 、队列一些限制条件,将系统中的资源分配给各个正在运行的应用程序,这里有一句话想说,调度器是一个纯调度器,就是它只管资源分配,不参与具体应用程序相关的工作。
什么是应用程序管理器(ApplicationMaster)?
应用程序管理器它主要负责监控管理整个系统的所有应用程序,同时负责向RM申请资源、返还资源等。
什么是NodeManager?
NodeManager是一个从服务,整个集群有多个。它负责接收RM的资源分配请求,分配具体的Container给应用,它也负责监控并报告Container的使用信息给RM。
什么是Contaienr?
Container是yarn中分配资源的一个单位,包括内存、CPU等资源,YARN以Container为单位分配资源。
第3点:YARN应用提交过程
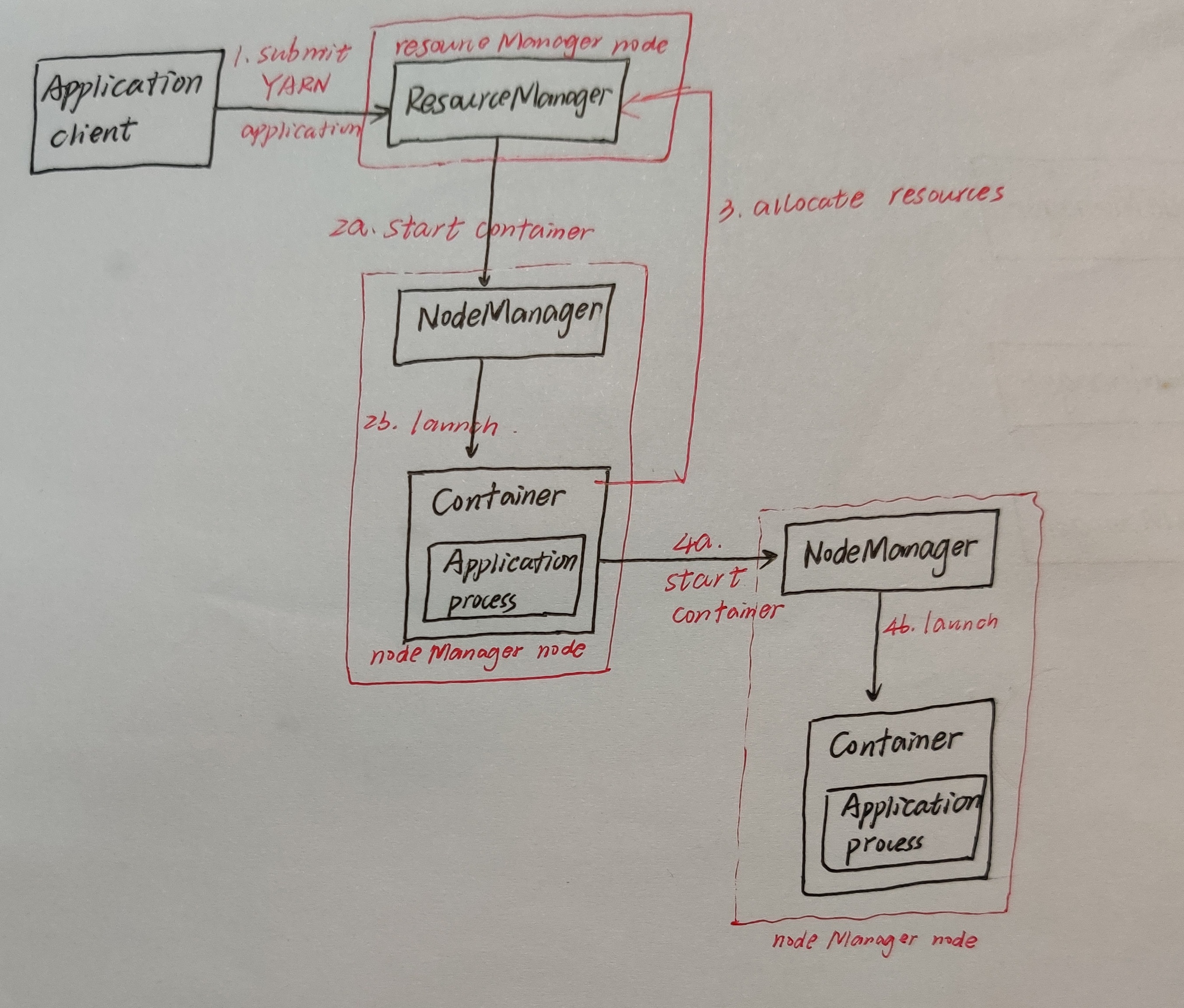
老刘这里简单讲讲YARN的应用提交过程,主要想讲的是MapReduce On Yarn这个内容。
根据上面的图,就可以看出来YARN的应用提交过程。
第一步是用户将应用程序提交到 ResourceManager 上;
第二步是ResourceManager为应用程序 ApplicationMaster 申请资源,并与某个 NodeManager 通信启动第一个 Container,以启动ApplicationMaster;
第三步是ApplicationMaster 与 ResourceManager 注册进行通信,为内部要执行的任务申请资源,一旦得到资源后,就会和 NodeManager 通信,从而启动对应的 Task;
第四步是所有任务运行完成后,ApplicationMaster会向 ResourceManager 进行注销,整个应用程序就运行结束了。
下面就是重点内容,详细讲讲MapReduce On Yarn。
第4点:MapReduce On Yarn
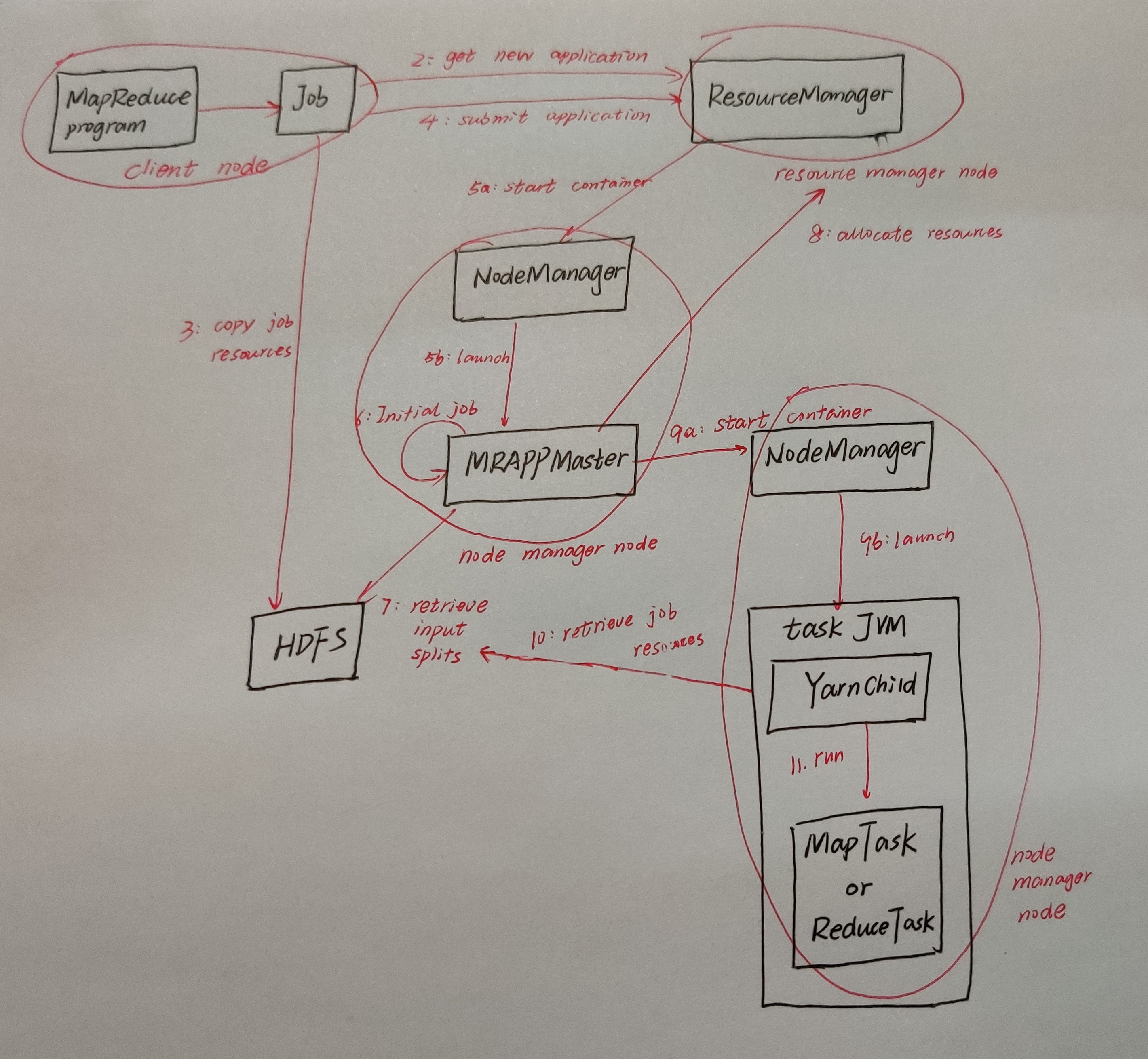
这一点,很重要,第3点就是说说了皮毛,第4点是详细的描述整个过程,老刘尽量讲的通俗易懂点,MapReduce On Yarn运行过程如下:
1、先把程序打成Jar包,接着客户端运行hadoop jar命令,就会把job提交到集群中运行。在这个过程中,程序里的job.waitForCompletion()会调用Job里的submit()方法。
2、接着会远程调用ResourceManager的getId,就会得到一个MR作业的id。同时也会检查输出目录是否存在,如果没有指定输出目录或者目录已经存在,就会报错;也会计算作业分片,若无法计算分片,也会报错。
3、接下里,会把Job相关的配置文件,jar包,分片信息,上传到HDFS。
4、客户端将应用程序提交给RM,任务开始真正运行。
5、当RM收到任务提交的通知后,它会与指定的NodeManager通信,通知NodeManager启动容器,NodeManager会创建占据特定资源的Container,并且在这个Container中运行MRAppMaster进程。
6、MRAppMaster进程会初始化job,创建多个簿记对象,记录各map任务,reduce任务的进度信息,状态信息。
这里面的簿记对象要说一下,很多地方都没解释它是什么,就一笔忽略,在老刘看来这就有点不太好。
老刘搜了一下后,是这样介绍的:MapReduce 作业的 application master 是一个 Java 应用,它的主类是 MRAppMaster。它通过创建一定数量的簿记对象(bookkeeping object)跟踪作业进度来初始化作业,该簿记对象接受任务报告的进度和完成情况。
7、AppMaster接下里要启动Task任务了,但它不知道启动多少个map task以及在哪个节点上启动等信息,所以这个时候AppMaster就需要从HDFS获取分片信息之类的。
8、获取完信息,就要开始分配任务了,AppMaster会为了每个任务向RM请求资源分配Container。RM收到消息后,会进行资源的计算,计算什么资源呢?一般是为map任务、reduce任务分配多大内存啊,几个虚拟内核之类的啊。
这一步老刘想说的是在看资料中,大家可以尝试反问下自己,比如就这个它会计算资源,你可以问问自己,它计算什么资源,这对自身进步有很大帮助。
9、AppMaster收到这些计算资源信息的返回结果后,就会与NodeManager通信,NodeManager就会启动一个JVM(容器)。
10、但是在容器中运行任务(YarnChild)之前,会将运行任务需要的资源拉取到本地(jar包,配置文件,分布式缓存文件)。
11、任务运行。
老刘尽量用口语化的形式表达出来了,希望大家能够记住它。
第5点:YARN应用生命周期
1、Client向RM提交应用,包括AM程序及启动AM的命令。
2、RM为AM分配第一个容器,并与对应的NM通信,令其在容器上启动应用的AM。
3、AM启动时向RM注册,允许Client向RM获取AM信息然后直接和AM通信。
4、AM通过资源请求协议,为应用协商容器资源。
5、如容器分配成功,AM要求NM在容器中启动应用,应用启动后可以和AM独立通信。
6、应用程序在容器中执行,并向AM汇报。
7、在应用执行期间,Client和AM通信获取应用状态。
8、应用执行完成,AM向RM注销并关闭,释放资源。
第6点:YARN常用命令
启动YARN
start-yarn.sh 停止RM和NM
stop-yarn.sh 查看正在运行的任务
yarn application -list 杀掉正在运行任务
yarn application -kill 任务id 查看节点列表
yarn node -list
第7点:YARN调度器
大家先想想为什么需要调度器?在现实生活中,绝对会遇到同时提交任务的场景,那这个时候到底如何分配资源满足这些任务呢?谁先执行呢?都是有讲究的!
所以在Yarn框架中,调度器是一块很重要的内容。有了合适的调度规则,就可以保证多个应用可以在同一时间有条不紊的工作。
YARN中最原始的调度规则是FIFO,就是谁先提交任务谁先执行。但是这样很可能会导致两种情况:① 一个大任务独占资源,其他的资源需要不断的等待大任务完成;② 一堆小任务占用资源,大任务一直无法得到适当的资源。所以FIFO虽然很简单,但是并不能满足我们的需求。
所以在YARN中现在有三种调度器可以选择:FIFO Scheduler ,Capacity Scheduler,FairS cheduler。
FIFO Scheduler是把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中第一个应用进行分配资源,等到第一个的应用需求满足后再给第二个分配。
FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它的缺点刚刚也说了。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。所以如果在共享的集群中,更适合采用Capacity Scheduler或Fair Scheduler。
对于Capacity调度器,它会有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。
但是在Fair调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。当第一个大job提交时,这时只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。小任务执行完成之后就会释放自己占用的资源,大任务又获得了全部的资源,这样就保证了Fair调度器既得到了高的资源利用率又能保证小任务的及时完成。
03 总结
好啦,YARN知识点就讲的差不多了,老刘尽量用通俗易懂的口语化形式将这些知识点表达出来了,希望能够对大数据感兴趣的同学有帮助,也希望能够得到大佬们的批评和指点。
觉得老刘写的不错的,给老刘点个赞吧!
最后,有事,联系公众号:努力的老刘;没事,就和老刘一起学大数据。
保证看完就会!大数据YRAN核心知识点来袭!的更多相关文章
- 大白话详解大数据HBase核心知识点,老刘真的很用心(3)
老刘目前为明年校招而努力,写文章主要是想用大白话把自己复习的大数据知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的理解! 01 HBase知识点(3) 第13点:HBase表的热点问题 什么是热 ...
- 大白话详解大数据HBase核心知识点,老刘真的很用心(2)
前言:老刘目前为明年校招而努力,写文章主要是想用大白话把自己复习的大数据知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的理解! 01 HBase知识点 第6点:HRegionServer架构 为 ...
- 一篇文章看懂TPCx-BB(大数据基准测试工具)源码
TPCx-BB是大数据基准测试工具,它通过模拟零售商的30个应用场景,执行30个查询来衡量基于Hadoop的大数据系统的包括硬件和软件的性能.其中一些场景还用到了机器学习算法(聚类.线性回归等).为了 ...
- 我要进大厂之大数据Hadoop HDFS知识点(2)
01 我们一起学大数据 老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点! ...
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
- 大数据BI框架知识点备注
将这段时间的一些基于大数据方案的BI知识点暂时做些规整,可能还存在较多问题,后续逐步完善修改. 数据模型: 1.星型模型和雪花模型,同样是将业务表拆分成事实表和纬度表:例如一个员工数据表,可以拆分为员 ...
- ping命令的七种用法,看完瞬间成大神
一.ping基本使用详解 在网络中ping是一个十分强大的TCP/IP工具.它的作用主要为: 1.用来检测网络的连通情况和分析网络速度 2.根据域名得到服务器IP 3.根据ping返回的TTL值来判断 ...
- 入门大数据---Flink核心概念综述
一.Flink 简介 Apache Flink 诞生于柏林工业大学的一个研究性项目,原名 StratoSphere .2014 年,由 StratoSphere 项目孵化出 Flink,并于同年捐赠 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
随机推荐
- C# 面试前的准备_基础知识点的回顾_04
1.Session和Cookie的使用区别 很容易回答的就是Session在服务器端,存储的数据可以较大容量,比如我们存一个Table,上千条数据. Cookie保存在客户端,安全系数低,不能放重要的 ...
- javaSE、javaEE、Android知识点总结
曾今上学时候的一些学习总结,如有错误请大家指出,共同学习. 1. 什么是WebView? WebView是一个使用WebKit引擎的浏览器组件,用来加载网页. 2. WebView中加载网页的两种方式 ...
- POI样式设置详细解析
````````由于看到网上对poi做报告合成的内容不是很全面, ````````自己最近又有新的需求, 作为勉励, 会慢慢补充详细的样式设置, 希望也能帮到各位 设置段落方向 (默认是纵向, 这里可 ...
- 使用WxPusher给自己的个人微信发送提醒消息(WxPusher微信推送服务)
1.背景 我们很多时候,我们在服务器上运行软件,发生一些业务异常,需要给我们发送一个及时的提醒,或者是使用一些耗时软件,比如抢车票,抢课,刷优惠券当任务运行成功以后,也需要及时的发送消息给自己 ,告诉 ...
- SpringBoot第二集:注解与配置(2020最新最易懂)
2020最新SpringBoot第二集:基础注解/基础配置(2020最新最易懂) 一.Eclipse安装SpringBoot插件 Eclipse实现SpringBoot开发,为便于项目的快速构建,需要 ...
- 谈谈Android项目框架的前世今生
嗨,大家好,今天出了大太阳,真是美好的开始. 这篇文章和大家说说Android届流行的三大框架,了解下架构的前世今生,以及我对于这些框架的一些认识和看法. 三大框架区别 MVC 架构介绍 Model: ...
- java开发-前后端分离
众所周知,做java开发是后端的开发,我们时常与前端打交道,但更加注重后端代码的实现,前台的页面都是由前端开发人员做的,那么,是怎么做到前后端分离的呢? 首先,是后端的开发, 在mapper层:Stu ...
- eclipse之SSH配置hibernate【三】
配置hibernate,没有和spring整合,可以看成独立的部分. 在src下创建hibernate配置文件,hibernate.cfg.xml.主要是sql连接相关配置. <?xml ver ...
- Luogu P4546 [THUWC2017]在美妙的数学王国中畅游
题意 题意奇奇怪怪,这里就不写了. \(\texttt{Data Range:}1\leq n\leq 10^5,1\leq m\leq 2\times 10^5\) 题解 为什么你们都是卡在数学方面 ...
- Redis的介绍及使用
redis 简介 简单来说 redis 就是一个数据库,不过与传统数据库不同的是 redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向.另外,redis 也经常 ...