个人项目wc(C语言)
github地址:https://github.com/nilonger/mycangku
一、项目要求
1、wc.exe 是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程序设计语言源文件的字符数、单词数和行数。
2、实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。
程序处理用户需求的模式为:wc.exe [parameter] [file_name]
3、基本功能:
wc.exe -c file.c //返回文件 file.c 的字符数
wc.exe -w file.c //返回文件 file.c 的词的数目
wc.exe -l file.c //返回文件 file.c 的行数
4、扩展功能:
-s 递归处理目录下符合条件的文件。
-a 返回更复杂的数据(代码行 / 空行 / 注释行)。
空行:本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
代码行:本行包括多于一个字符的代码。
注释行:本行不是代码行,并且本行包括注释。一个有趣的例子是有些程序员会在单字符后面加注释:
} //注释
在这种情况下,这一行属于注释行。
特殊情况,如 return; } //注释,既算是代码行也算是注释行。
[file_name]: 文件或目录名,可以处理一般通配符
5、高级功能:
-x 参数。这个参数单独使用。如果命令行有这个参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、行数等全部统计信息。
二、PSP
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|---|---|---|---|
Planning |
计划 |
50 |
80 |
· Estimate |
· 估计这个任务需要多少时间 |
500 |
600 |
Development |
开发 |
500 |
600 |
· Analysis |
· 需求分析 (包括学习新技术) |
100 |
200 |
· Design Spec |
· 生成设计文档 |
20 |
25 |
· Design Review |
· 设计复审 (和同事审核设计文档) |
20 |
20 |
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 |
20 |
· Design |
· 具体设计 |
80 |
100 |
· Coding |
· 具体编码 |
150 |
350 |
· Code Review |
· 代码复审 |
30 |
60 |
· Test |
· 测试(自我测试,修改代码,提交修改) |
30 |
60 |
Reporting |
报告 |
20 |
30 |
· Test Report |
· 测试报告 |
20 |
30 |
· Size Measurement |
· 计算工作量 |
10 |
10 |
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
10 |
20 |
合计 |
1560 |
2205 |
三、解题思路
1、刚开始拿到题目的时候,一脸懵逼,不知道从哪里开始着手,只知道要统计字符数,单词数,总行数。不知道怎么下手,就百度了一下wc,看到了一些用java,Python,C什么的例子,发现其实还而已,然后就开始着手计划打码
2、字符数:只要是在 ‘!’和‘~’ 之间的字符,都算入统计范围内
词数:要求在由英文字母组成 ‘A’~‘Z’ 和 ‘a’~‘z’,然后设置一个变量 flag,帮助判断行数是否要 +1
行数:行数最简单,只要判断换行符 ‘\n’ 就好了
返回更复杂数据 A :空行,注释行(包括多行注释),代码行,这个几个数据的统计没得参考,只能通过上面那几个数据的统计过程自己 写相应的算法
递归目录:没有。觉得C语言实现有点难,别的语言又不会。所以放弃。
四、设计实现过程
第一种(也是现在代码的运行顺序):

第二种(之前为了调试单独一个函数的功能):
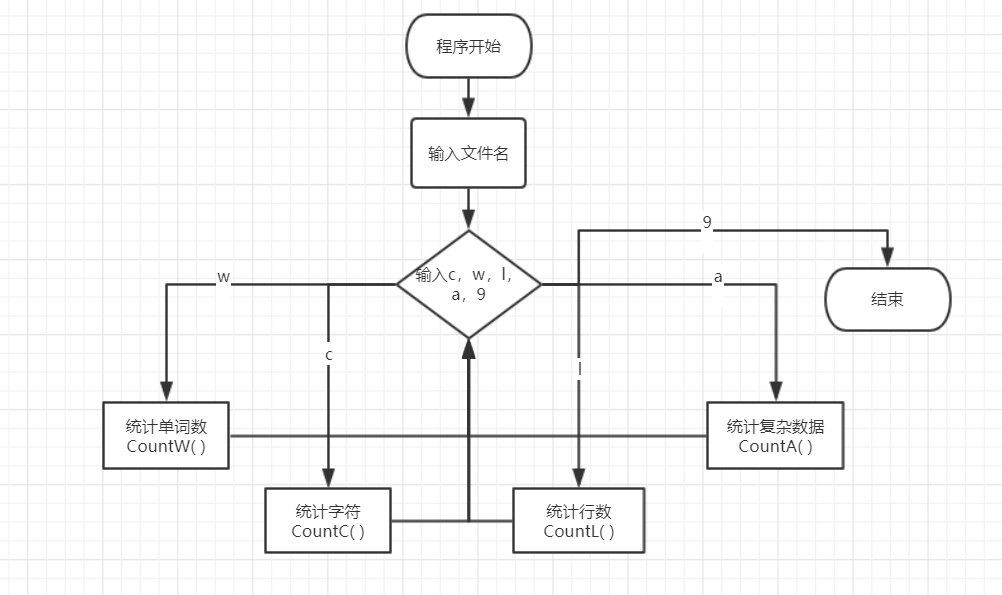
五、代码说明
统计字符数函数CountC():
#include <stdio.h>
#include<stdlib.h>
#include <string.h> int x,y,z,k,konghang;//x字符数 ; y词数 ;z行数 ; k 注释行数 int m; //不是空文件时 m=1 //字符数
void CountC(char fname[]){
FILE* fp=NULL;
if((fp=fopen(fname,"r"))==NULL) //不要 放在主函数里面
{
printf("打不开文件\n");
exit();
} char ch;
ch=fgetc(fp);
while(ch!=EOF)
{
if(ch>='!'&&ch<='~') //ASCII 从33到126
x++;
ch=fgetc(fp); }
if(x==)m=; //m=0 则为 空文件
fclose(fp);
}
统计单词数函数CountW():
//词数
void CountW(char fname[]){
FILE* fp=NULL;
if((fp=fopen(fname,"r"))==NULL)
{
printf("打不开文件\n");
exit();
} char ch;
int flag=; //用于判断是否要 +1 ,flag要先置为0
ch=fgetc(fp);
while(ch!=EOF)
{
if(!(ch>='A'&&ch<='Z'||ch>='a'&&ch<='z')){ //如果是非字母字符,让flag为0 ||ch=='.'||ch=='_'
flag = ;
}
else if((flag ==)&&(ch>='A'&&ch<='Z'||ch>='a'&&ch<='z')) //如果是字母字符且flag原值为0,flag置1,单词数加一
{
flag = ;
y++;
}
ch=fgetc(fp);
}
// y--; //单独测试 的时候要加上 ,不知道为什么要 -1
if(m==) y=;
fclose(fp);
}
统计行数CountL():
//行数
int CountL(char fname[]){
FILE* fp=NULL;
if((fp=fopen(fname,"r"))==NULL)
{
printf("打不开文件\n");
exit();
} char ch;
ch=fgetc(fp);
z++; // 单独测试 的时候要去掉
while(ch!=EOF)
{
if(ch=='\n')
z++;
ch=fgetc(fp);
}
if(m==) z=; //不能z-- 空文件运行会出错
fclose(fp);
return(z);
}
统计复杂类型数据函数CountA():
这里没有分开三个函数,而是合在一起。
缺点:见后面总结。
void CountA(char fname[]){
FILE* fp=NULL;
if((fp=fopen(fname,"r"))==NULL)
{
printf("打不开文件\n");
exit();
}
//注释行
char ch;
ch=fgetc(fp);
while(ch!=EOF)
{
if(ch=='/')
{
ch=fgetc(fp);
if(ch=='/')
{
k++; //注释行 +1
ch=fgetc(fp); //获得新的字符,并重新开始循环
continue;
}
else if(ch=='*')
{
ch=fgetc(fp);
while(ch!=EOF)
{
if(ch=='\n') k++; //多行注释的 每个回车都要 +1
if(ch=='*')
ch=fgetc(fp);
if(ch=='/')
{
k++; //多行注释完整,行数+1,并跳出第二层循环
break;
}
ch=fgetc(fp);
}
}
}
ch=fgetc(fp);
}
printf("注释行:%d\n",k);
rewind(fp); //指回文件开头
//空行
int flag=;
int num=; //两个换行符之间的字符数
konghang=;
ch=fgetc(fp);
while(ch!=EOF){
if(ch=='\n'&&num==) //第一个换行符
{
flag=;
konghang++;
}
else if(ch!='\n'&&flag==)
num++;
else if(ch!='\n'&&flag==&&num==) //第一行 是代码行 的情况
{
num++;
flag=;
}
else if(ch=='\n'&&flag==&&num>=){ //代码行到最后,把累加的字符数 归0
num=;
flag=;
}
ch=fgetc(fp);
}
printf("空行数:%d\n",konghang);
rewind(fp);
//代码行
int num1=,daimahang=,flag1=;;
ch=fgetc(fp);
while(ch!=EOF){
if((ch!=' '&&ch!='\n'&&ch!='\t'&&ch!='/'))
{
num1++;
}
else if(ch=='\n'&&num1>=&&flag1==)
{
daimahang++;
num1=;
}
else if(ch=='/')
{
ch=fgetc(fp);
if(ch=='/')
{
ch=fgetc(fp);
while(ch!=EOF){
if(ch=='\n') break;
ch=fgetc(fp);
}
}
else if(ch=='*')
{
ch=fgetc(fp);
while(ch!=EOF){
if(ch>='A'&&ch<='Z'||ch>='a'&&ch<='z')num1++;
if(ch=='\n')num1=;
if(ch=='*')
{
ch=fgetc(fp);
if(ch=='/') break;
}
ch=fgetc(fp);
}
}
}
ch=fgetc(fp);
}
daimahang++; //最后一行没有'\n',自动 +1
if(m==) daimahang=;
printf("代码行数:%d\n",daimahang);
fclose(fp);
}
主函数:
注释里面的就是 原本用来单独调试单个函数用的第二个流程。(选择 流程1 或 流程2 在运行过程中,同一个文件各数据统计的结果会有所出入,解决方法已经在各个函数里面备注了。)
int main(){
char fu[];
char fname[];
while(){
m=; //不是空文件是 m=1
x=y=z=k=konghang=;
printf("输入文件名:");
scanf("%s",fname);
CountC(fname) ;
printf("字符数为:%d\n",x);
CountW(fname);
printf("单词数为:%d\n",y);
CountL(fname);
printf("行数:%d\n",z);
CountA(fname);
}
/* printf("-c:统计字符数\n -w:统计单词数\n -l:统计行数\n -a复杂数据\n -9:退出\n");
while(1)
{ x=0;y=1;z=1;k=0; //行数先设置为 1
printf("请输入你的操作c/w/l/a/9:");
scanf("%s",fu);
if(fu[0]=='c')
{
CountC(fname) ;
printf("字符数为:%d\n",x);
}
if(fu[0]=='w')
{
CountW(fname);
printf("单词数为:%d\n",y);
}
if(fu[0]=='l')
{
CountL(fname);
printf("行数:%d\n",z);
}
if(fu[0]=='a')
{
CountA(fname);
}
if(fu[0]=='9')
break;
}
*/
return ;
}
六、测试运行
1、空文件

2、一个字符的文件

3、只有一个词的文件

4、只有一行的文件

5、一个典型的源文件

6、自己乱打的文件:
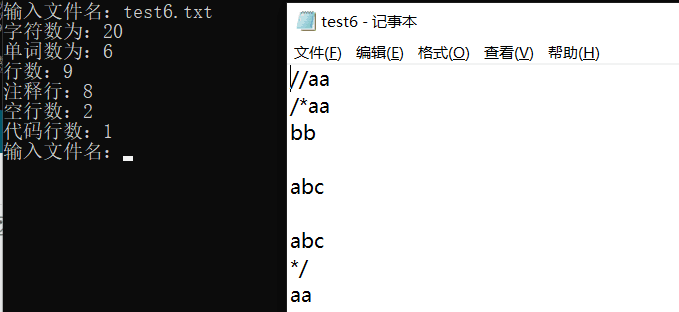
七、项目小结
1、这次任务从无到有的,从不知如何开始到自己写算法统计复杂数据,过程虽然很无聊,改不好也容易烦躁,但是最后还是基本改完了,很是高兴
2、设置几个固定的文件来做 回归测试 还是远远不够的,这样你代码只会偏向于说:只要满足那几个文件就好了,但是要是文件一改动,代码运行结果马上出现统计问题。所以我在测试的时候,偏向于改变文件里的内容来做测试,改动的次数多了,就可以发现还有那些问题所在,上面的第6个图就是自己乱打的代码,其中通过这个方法就发现并解决的多行注释里可以包含空行的现象,因为注释行可以包含空行,所以 : 代码行!=总行 - 注释行 -空行,因为这样子会多减去一部分,导致代码行比实际少!
3、缺点:1)统计复杂数据的时候,最后一行不能是空行,空行统计会出错
2)统计复杂数据的时候,最后一行如果有注释,比如(printf();//我是注释,或者最后一行是 ' */ ' ),注释行将不能最后一行统计在内,也就是那一行仍然是属于代码行
3)我的算法是:只要有注释,该行就归为 注释行
4)也就发现最后一行这个问题,其他地方没有发现什么问题
优点:各种数据随便互相嵌套,统计结果基本都不会出现问题(除了上面说的),还有就是,实现了注释行里的可以空行可以计算进去和多行注释里面的代码不包含进代码行等等。
4、局限于现在只会c语言,其他语言比如java,学过一点,但是由于不熟练,就放弃了用java来写,还有就是递归目录没有实现。
5、这个项目所花的时间有点长(还好早一点写),大部分时间用在了分析复杂数据的算法,还有写完算法、优化算法的过程上。
个人项目wc(C语言)的更多相关文章
- 个人项目-wc
个人项目-WC (C语言) 一.Github地址:https://github.com/Lin-J-F/WC 二.PSP表格 PSP2.1 Personal Software Process St ...
- 转:从开源项目学习 C 语言基本的编码规则
从开源项目学习 C 语言基本的编码规则 每个项目都有自己的风格指南:一组有关怎样为那个项目编码约定.一些经理选择基本的编码规则,另一些经理则更偏好非常高级的规则,对许多项目而言则没有特定的编码规则,项 ...
- 实践简单的项目WC
#include<iostream> #include<fstream> #include<string> #include<Windows.h> us ...
- 个人项目-WC(C/C++ 兼容Linux和Windows)
一.Github地址 https://github.com/S-TRAVELER/WC 实现的功能: 支持 -c 支持 -w 支持 -l 支持 -s 支持 -a 图形界面 多参数(文件名或通配符表达式 ...
- 个人项目-WC (java实现)
一.Github地址:https://github.com/734635746/WC 二.PSP表格 PSP2.1 Personal Software Process Stages 预估耗时(分钟) ...
- 个人项目-WC(Java实现)
一.Github项目地址: https://github.com/kestrelcjx/-WC-Java- 二.PSP表格 PSP2.1 Personal Software Process Stage ...
- 个人项目—WC
一,Github地址:https://github.com/mushan520/WC.git 二.PSP表格: PSP2.1 Personal Software Process Stages 预估耗 ...
- 个人项目 wc.exe
GitHub地址:https://github.com/oAiuo/wordCount 一.题目描述 Word Count1. 实现一个简单而完整的软件工具(源程序特征统计程序).2. 进行单元测试. ...
- 个人项目WC.exe Node.js+electron实现
前言 实现语言:Javascript 编译工具:webstorm GitHub:https://github.com/NPjuan/WC.git 项目要求 wc.exe 是一个常见的工具,它能统计文本 ...
随机推荐
- sql数据管理语句
一.数据管理 1.增加数据 INSERT INTO student VALUES(1,'张三','男',20); -- 插入所有字段.一定依次按顺序插入 -- 注意不能少或多字段值 如只需要插入部分字 ...
- bubble排序
故事的起因:好久没有用bubble了,,,居然忘记了基本格式........ 经过:,,,,这可算是我学的第一个比较有用的"算法"啊...这怎么行! 结果: void bubbleSort (elem ...
- 00_02_使用Parallels Desktop创建Windos7虚拟机
准备工作 如果要看图片的准备过程请参考该链接 需要注意的是给CPU配置为一个核,内存分配1024M 硬盘空间划分为60G 操作系统安装设置 注:windows系统设置一般都是"下一步&quo ...
- 1-Numpy的通用函数(ufunc)
一.numpy“通用函数”(ufunc)包括以下几种: 元素级函数(一元函数):对数组中的每个元素进行运算 数组级函数:统计函数,像聚合函数(例如:求和.求平均) 矩阵运算 随机生成函数 常用一元通用 ...
- Python time localtime()方法
描述 Python time localtime() 函数类似gmtime(),作用是格式化时间戳为本地的时间.高佣联盟 www.cgewang.com 如果sec参数未输入,则以当前时间为转换标准. ...
- PDOStatement::closeCursor
PDOStatement::closeCursor — 关闭游标,使语句能再次被执行.(PHP 5 >= 5.1.0, PECL pdo >= 0.9.0) 说明 语法 bool PDOS ...
- ERROR 1054 (42S22): Unknown column 'password' in 'field list'
解决: update MySQL.user set authentication_string=password('123456') where user='root'; FLUSH PRIVILEG ...
- 关于 ORA-01033: ORACLE initialization or shutdown in progress
第一步: 这个错误首先查看服务进程是否正常启动: 第二步: 一般情况下第一步都没问题,问题出在可能误删了日志文件: 当然可能不是你删除的,可能被某些清理软件删除的: 或者是其他情况导致日志出错 ...
- 一文说通C#中的异步编程补遗
前文写了关于C#中的异步编程.后台有无数人在讨论,很多人把异步和多线程混了. 文章在这儿:一文说通C#中的异步编程 所以,本文从体系的角度,再写一下这个异步编程. 一.C#中的异步编程演变 1. ...
- 【JVM】JVM优化过程全记录
请大神移步:https://segmentfault.com/a/1190000010510968?utm_source=tuicool&utm_medium=referral 今天看JVM群 ...