第1章 RDD概念 弹性分布式数据集
第1章 RDD概念 弹性分布式数据集
1.1 RDD为什么会产生
RDD是Spark的基石,是实现Spark数据处理的核心抽象。那么RDD为什么会产生呢?
Hadoop的MapReduce是一种基于数据集的工作模式,面向数据,这种工作模式一般是从存储上加载数据集,然后操作数据集,最后写入物理存储设备。数据更多面临的是一次性处理。
MR的这种方式对数据领域两种常见的操作不是很高效。第一种是迭代式的算法。比如机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR这种模式不太合适,即使多MR串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR显然不擅长。
MR中的迭代:
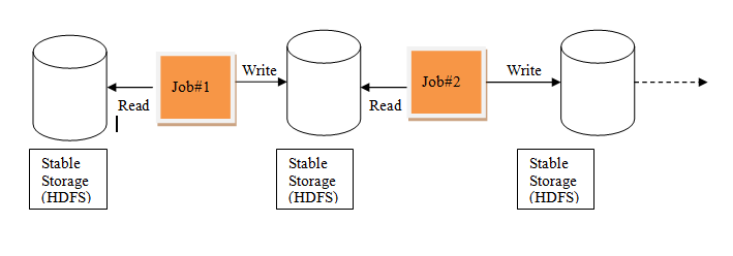
Spark中的迭代:
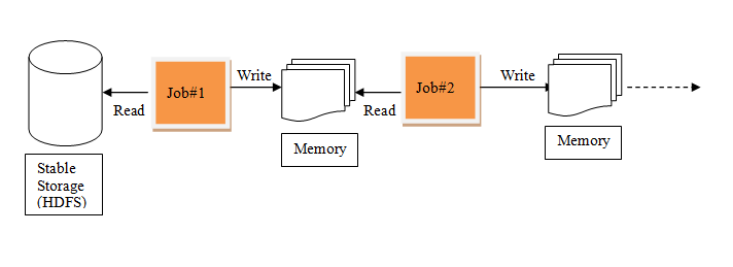
我们需要一个效率非常快,且能够支持迭代计算和有效数据共享的模型,Spark应运而生。RDD是基于工作集的工作模式,更多的是面向工作流。
但是无论是MR还是RDD都应该具有类似位置感知、容错和负载均衡等特性。
1.2 RDD概述
1.2.1 什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有RDD 以及调用 RDD 操作进行求值。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含 Python、Java、Scala 中任意类型的对象, 甚至可以包含用户自定义的对象。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD支持两种操作:转化操作和行动操作。RDD 的转化操作是返回一个新的 RDD的操作,比如 map()和 filter(),而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作。比如 count() 和 first()。
Spark采用惰性计算模式(懒执行),RDD只有第一次在一个行动操作中用到时,才会真正计算。Spark可以优化整个计算过程。默认情况下,Spark 的 RDD 会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个 RDD,可以使用 RDD.persist() 让 Spark 把这个 RDD 缓存下来。
1.2.2 RDD的属性

1) 一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
2) 一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
3) RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
4) 一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
5) 一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
RDD是一个应用层面的逻辑概念。一个RDD多个分片。RDD就是一个元数据记录集,记录了RDD内存所有的关系数据。
1.3 RDD的弹性
1) 自动进行内存和磁盘数据存储的切换
Spark优先把数据放到内存中,如果内存放不下,就会放到磁盘里面,程序进行自动的存储切换
2) 基于血统的高效容错机制
在RDD进行转换和动作的时候,会形成RDD的Lineage依赖链,当某一个RDD失效的时候,可以通过重新计算上游的RDD来重新生成丢失的RDD数据。
3) Task如果失败会自动进行特定次数的重试
RDD的计算任务如果运行失败,会自动进行任务的重新计算,默认次数是4次。
4) Stage如果失败会自动进行特定次数的重试
如果Job的某个Stage阶段计算失败,框架也会自动进行任务的重新计算,默认次数也是4次。
5) Checkpoint和Persist可主动或被动触发
RDD可以通过Persist持久化将RDD缓存到内存或者磁盘,当再次用到该RDD时直接读取就行。也可以将RDD进行检查点CheckPoint,检查点会将数据存储在HDFS中,该RDD的所有父RDD依赖都会被移除。
6) 数据调度弹性
Spark把这个JOB执行模型抽象为通用的有向无环图DAG,可以将多Stage的任务串联或并行执行,调度引擎自动处理Stage的失败以及Task的失败。
7) 数据分片的高度弹性
可以根据业务的特征,动态调整数据分片的个数,提升整体的应用执行效率。
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持丰富的转换操作(如map, join, filter, groupBy等),通过这种转换操作,新的RDD则包含了如何从其他RDDs衍生所必需的信息,所以说RDDs之间是有依赖关系的。基于RDDs之间的依赖,RDDs会形成一个有向无环图DAG,该DAG描述了整个流式计算的流程,实际执行的时候,RDD是通过血缘关系(Lineage)一气呵成的,即使出现数据分区丢失,也可以通过血缘关系重建分区,总结起来,基于RDD的流式计算任务可描述为:从稳定的物理存储(如分布式文件系统)中加载记录,记录被传入由一组确定性操作构成的DAG,然后写回稳定存储。另外RDD还可以将数据集缓存到内存中,使得在多个操作之间可以重用数据集,基于这个特点可以很方便地构建迭代型应用(图计算、机器学习等)或者交互式数据分析应用。可以说Spark最初也就是实现RDD的一个分布式系统,后面通过不断发展壮大成为现在较为完善的大数据生态系统,简单来讲,Spark-RDD的关系类似于Hadoop-MapReduce关系。
1.4 RDD特点
RDD表示只读的分区的数据集,对RDD进行改动,只能通过RDD的转换操作,由一个RDD得到一个新的RDD,新的RDD包含了从其他RDD衍生所必需的信息。RDDs之间存在依赖,RDD的执行是按照血缘关系延时计算的。如果血缘关系较长,可以通过持久化RDD来切断血缘关系。
1.4.1 分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。

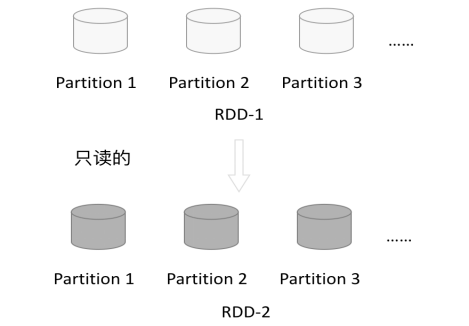
1.4.2 只读
如下图所示,RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
由一个RDD转换到另一个RDD,可以通过丰富的操作算子实现,不再像MapReduce那样只能写map和reduce了,如下图所示。
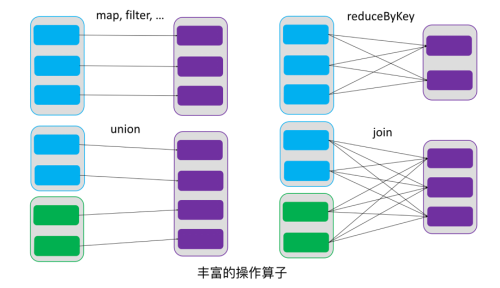
RDD的操作算子包括两类,一类叫做transformations,它是用来将RDD进行转化,构建RDD的血缘关系;另一类叫做actions,它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。下图是RDD所支持的操作算子列表。

1.4.3 依赖
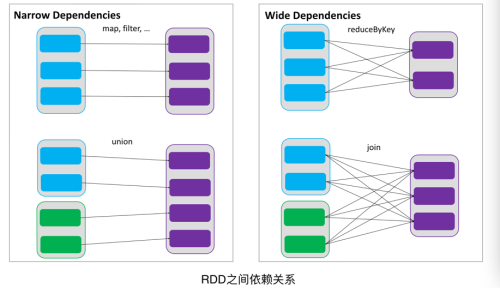
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系,也称之为依赖。如下图所示,依赖包括两种,一种是窄依赖,RDDs之间分区是一一对应的,另一种是宽依赖,下游RDD的每个分区与上游RDD(也称之为父RDD)的每个分区都有关,是多对多的关系。
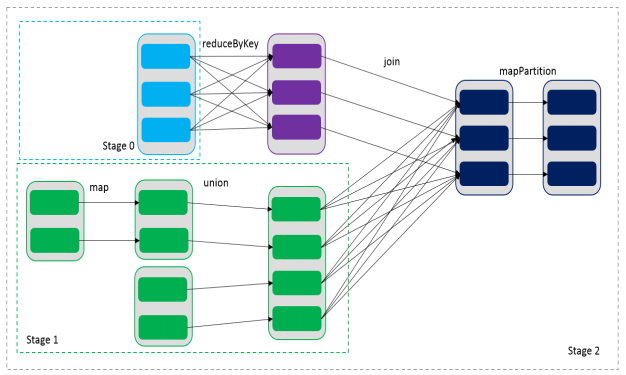
通过RDDs之间的这种依赖关系,一个任务流可以描述为DAG(有向无环图),如下图所示,在实际执行过程中宽依赖对应于Shuffle(图中的reduceByKey和join),窄依赖中的所有转换操作可以通过类似于管道的方式一气呵成执行(图中map和union可以一起执行)。
1.4.4 缓存
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。如下图所示,RDD-1经过一系列的转换后得到RDD-n并保存到hdfs,RDD-1在这一过程中会有个中间结果,如果将其缓存到内存,那么在随后的RDD-1转换到RDD-m这一过程中,就不会计算其之前的RDD-0了。

1.4.5 CheckPoint
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处拿到数据。
给定一个RDD我们至少可以知道如下几点信息:1、分区数以及分区方式;2、由父RDDs衍生而来的相关依赖信息;3、计算每个分区的数据,计算步骤为:1)如果被缓存,则从缓存中取的分区的数据;2)如果被checkpoint,则从checkpoint处恢复数据;3)根据血缘关系计算分区的数据。
第1章 RDD概念 弹性分布式数据集的更多相关文章
- Spark - RDD(弹性分布式数据集)
org.apache.spark.rddRDDabstract class RDD[T] extends Serializable with Logging A Resilient Distribut ...
- [Berkeley]弹性分布式数据集RDD的介绍(RDD: A Fault-Tolerant Abstraction for In-Memory Cluster Computing 论文翻译)
摘要: 本文提出了分布式内存抽象的概念--弹性分布式数据集(RDD,Resilient Distributed Datasets).它同意开发者在大型集群上运行基于内存的计算.RDD适用于两种 ...
- Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD
http://blog.csdn.net/pipisorry/article/details/53257188 弹性分布式数据集RDD(Resilient Distributed Dataset) 术 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- RDD内存迭代原理(Resilient Distributed Datasets)---弹性分布式数据集
Spark的核心RDD Resilient Distributed Datasets(弹性分布式数据集) Spark运行原理与RDD理论 Spark与MapReduce对比,MapReduce的计 ...
- 弹性分布式数据集RDD概述
[Spark]弹性分布式数据集RDD概述 弹性分布数据集RDD RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作 ...
- 弹性分布式数据集(RDD)
spark围绕弹性分布式数据集(RDD)的概念展开的,RDD是一个可以并行操作的容错集合. 创建RDD的方法: 1.并行化集合(并行化驱动程序中现有的集合) 调用SparkContext的parall ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- RDD弹性分布式数据集的基本操作
RDD的中文解释是弹性分布式数据集.构造的数据集的时候用的是List(链表)或者Array数组类型/* 使用makeRDD创建RDD */ /* List */ val rdd01 = sc.make ...
随机推荐
- Java Web(5)-Servlet详解(上)
一.Servlet 1. 什么是Servlet Servlet 是 JavaEE 规范之一,规范就是接口 Servlet 就 JavaWeb 三大组件之一,三大组件分别是:Servlet 程序.Fil ...
- 在CentOS 7 上为docker配置端口转发以兼容firewall
在CentOS 7上当我们以类似下列命令将主机端口与容器端口映射时可能遇到无法访问容器服务的问题 docker run --name web_a -p 192.168.1.250:803:80 -d ...
- Python2.7 PicklingError: Can't pickle <type 'instancemethod'>: attribute lookup __builtin__.instancemethod failed 问题解决
# 报错信息 PicklingError: Can't pickle <type 'instancemethod'>: attribute lookup __builtin__.insta ...
- 使用MacOS自带的SVN客户端
原文链接:https://jingyan.baidu.com/article/5552ef479c1554518ffbc92f.html 摘要:mac环境下有自带的SVN服务端和客户端,SVN是许多公 ...
- python绝技:运用python成为顶级黑客|中文pdf完整版[42MB|网盘地址附提取码自行提取|
Python 是一门常用的编程语言,它不仅上手容易,而且还拥有丰富的支持库.对经常需要针对自己所 处的特定场景编写专用工具的黑客.计算机犯罪调查人员.渗透测试师和安全工程师来说,Python 的这些 ...
- 自学java,学多久可以自己找到工作?
先以肯定的语气说明一下自学Java,多久可以找到工作: 按照目前Java的体系来说,Java的几个重点在于Javase.数据库.Spring全家桶系列的框架.而其他的在Java体系之内,会基础的操 ...
- Python os.lchmod() 方法
概述 os.lchmod() 方法用于修改连接文件权限.高佣联盟 www.cgewang.com 只支持在 Unix 下使用. 语法 lchmod()方法语法格式如下: os.lchmod(path, ...
- Python File isatty() 方法
概述 isatty() 方法检测文件是否连接到一个终端设备,如果是返回 True,否则返回 False.高佣联盟 www.cgewang.com 语法 isatty() 方法语法如下: fileObj ...
- 7.29 NOI模拟赛 题答 npc问题 三染色 随机 贪心
LINK:03colors 这道题虽然绝大多数的人都获得了满分 可是我却没有. 老师讲题的时候讲到了做题答的几个技巧 这里总结一下. 数据强度大概为n=5000,m=60000的随机数据. 老师说:一 ...
- RabbitMQ好文章推荐
文章来源:掘金 作者:申城异乡人 RabbitMQ使用教程(一)RabbitMQ环境安装配置及Hello World示例 https://juejin.im/post/5ce644b9f ...