HBase的基本架构及其原理介绍
1、概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解。在这里,我觉得可以用HDFS的架构作为借鉴。(其实像Hadoop生态系统中的大部分组建的架构原理是类似,不信你往下看)
2、介绍架构
(1)HDFS例子
在这里我以我比较熟悉的HDFS分布式文件系统作为一个例子来简单说明一下。首先我对HDFS的架构做一个简单的说明:
HDFS分布式文件系统主要三个组建:NameNode和DataNode以及SecondaryNameNode。Namenode主要负责维护文件系统的元数据信息,DataNode则是负责实际存储对应数据分片的节点。
它的主要工作原理是客户端(client)通过发送一个请求(读写请求)时,首先会从NameNode中获取对应的元数据信息,这个元数据信息包含了对应 请求的数据所在的位置、大小等信息。获取到这些元数据信息后,client直接从对应的DataNode上执行对应的请求。这就是整个请求的响应过程。这 简单吧。当然这里并没有讲到SecondaryNameNode,它的作用主要是用来合并fsimage和edits文件来减少NameNode重启的时 间,还可以用来作为数据的一个冷备份。
好了,HDFS分布式文件系统的架构和原理简单的理解就是上面的内容了。下面来看看HBase的架构和原理吧。
(2)HBase(正题)
有了HDFS的基本原理对比之后,我们用同样的思维看HBase:与HDFS一样,HBase有Master和RegionServer(当然,这里还 需要用到Zookeeper)。在这里其实Zookeeper充当了类似NameNode的角色,Master的角色实际上是维护整个列式存储集群的运行 (如分配或切分Region,检查失效的RegionServer),RegionServer的角色当然跟Datanode的角色类似啦。
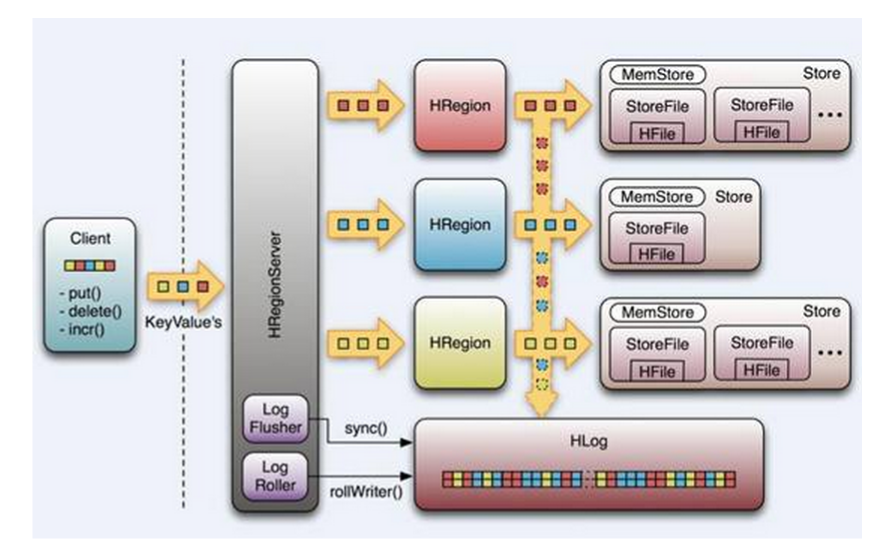
HBase的主要原理:客户端(Client)发送对应的请求(增、删、改、查),首先客户端会从Zookeeper中获取一个-ROOT-的表的元信 息(即-ROOT-的位置);第二步,客户端就去读取对应的-ROOT-表的信息,-ROOT-表中存储了对应的Meta的元数据信息;第三步,客户端知 道了Meta表元数据信息后就去读取对应Meta表的信息,Meta表存储了对应存放数据的RegionServer的位置信息等;第四步,就去获取对应 RegionServer上的数据。
HBase中比较重要的RegionServer,它上面包含的内容有:WAL(HLog)、BlockCache、Region、MemStore、StoreFile(HFile新版本的改进),下面主要讲一下这些个名词的原理和含义:
a) WAL:Write Ahead Log即提前写日志(Log),根据字面意思就知道,在写操作的时候,就是先要写入到该日志文件中。所有写操作都会先保证将数据写入这个Log文件后,才 会真正更新MemStore,最后写入HFile中。这样可以在RegionServer挂掉后,通过WAL来恢复数据,从而避免数据的丢失。一般一个 RegionServer只有一个WAL实例,也就是说一个RegionServer的所有WAL写都是串行的,你可能会觉得这会有性能问题,因而在 HBase 1.0之后,通过HBASE-5699实现了多个WAL并行写(MultiWAL),该实现采用HDFS的多个管道写,以单个HRegion为单位。
b) BlockCache:它是一个读缓存,即“引用局部性”原理。
c) Region:它是一个Table在一个RegionServer中的存储单元,也是分布式存 储的最小单元。一个Table可以有一个或多个Region,他们可以在一个相同的RegionServer上,也可以分布在不同的 RegionServer上,一个RegionServer可以有多个Region,他们分别属于不同的Table。Region由多个Store构成, 每个Store对应了一个Table在这个Region中的一个Column Family,即每个Column Family就是一个集中的存储单元,因而最好将具有相近IO特性的Column存储在一个Column Family,以实现高效读取(数据局部性原理,可以提高缓存的命中率)。Store是HBase中存储的核心,它实现了读写HDFS功能,一个 Store由一个MemStore 和0个或多个StoreFile组成。
d) MemStore是一个写缓存(In Memory Sorted Buffer),所有数据的写在完成WAL日志写后,再写入MemStore中,由MemStore根据一定的算法将数据Flush到地层HDFS文件中 (HFile),通常每个HRegion中的每个 Column Family有一个自己的MemStore。
e) HFile(StoreFile) 用于存储HBase的数据(Cell/KeyValue)。在HFile中的数据是按RowKey、Column Family、Column排序,对相同的Cell(即这三个值都一样),则按timestamp倒序排列。
HBase的基本架构及其原理介绍的更多相关文章
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- Hbase架构与原理(转)
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”.就像Bigtable利 ...
- Kylin系列之二:原理介绍
Kylin系列之二:原理介绍 2018年4月15日 15:52 因何而生 Kylin和hive的区别 1. hive主要是离线分析平台,适用于已经有成熟的报表体系,每天只要定时运行即可. 2. Kyl ...
- 资源管理与调度系统-YARN的基本架构与原理
资源管理与调度系统-YARN的基本架构与原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 为了能够对集群中的资源进行统一管理和调度,Hadoop2.0引入了数据操作系统YARN. ...
- 03 Yarn 原理介绍
Yarn 原理介绍 大纲: Hadoop 架构介绍 YARN 产生的背景 YARN 基础架构及原理 Hadoop的1.X架构的介绍 在1.x中的NameNodes只可能有一个,虽然可以通过Se ...
- HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Googl ...
- [转]MySQL主从复制原理介绍
MySQL主从复制原理介绍 一.复制的原理 MySQL 复制基于主服务器在二进制日志中跟踪所有对数据库的更改(更新.删除等等).每个从服务器从主服务器接收主服务器已经记录到其二进制日志的保存的更新,以 ...
- 分布式文件系统FastDFS原理介绍
在生产中我们一般希望文件系统能帮我们解决以下问题,如:1.超大数据存储:2.数据高可用(冗余备份):3.读/写高性能:4.海量数据计算.最好还得支持多平台多语言,支持高并发. 由于单台服务器无法满足以 ...
- HBase 事务和并发控制机制原理
作为一款优秀的非内存数据库,HBase和传统数据库一样提供了事务的概念,只是HBase的事务是行级事务,可以保证行级数据的原子性.一致性.隔离性以及持久性,即通常所说的ACID特性.为了实现事务特性, ...
随机推荐
- java.nio.file.Path
public interface Path extends Comparable<Path>, Iterable<Path>, Watchable 1. A Path repr ...
- iOS 动画组
其实早在一个多月以前就已经实现了动作组播放的功能,不过当时感觉好像没有什么难度并没有放在心上,今天突然要用到动画组,发现已经忘记了,所以又将原来的代码翻出来看了下.最后决定还是写下来,以备不时之需.动 ...
- OpenGL利用模板测试实现不规则裁剪
本文是原创文章,如需转载,请注明文章出处 在游戏开发中,经常会有这样的需求:给定一张64x64的卡牌素材,要求只显示以图片中心为圆点.直径为64的圆形区域,这就要用到模板测试来进行不规则裁剪. 实现不 ...
- include包含头文件的语句中,双引号和尖括号的区别是什么?
include包含头文件的语句中,双引号和尖括号的区别是什么? #include <> 格式:引用标准库头文件,编译器从标准库目录开始搜索 尖括号表示只在系统默认目录或者括号内的路径查找 ...
- C#如果把A.new()编译成new A()
缘由 对于初次接触某个第三方库的C#开发者,假如要调用里面一个方法,发现需要一个A类型的实例作为参数,怎么获得这个实例呢? 我想大多数人会先尝试new A吧: 如果没有,可能会尝试输入A.看看有没可能 ...
- SSL/TLS协议运行机制的概述
互联网的通信安全,建立在SSL/TLS协议之上. 本文简要介绍SSL/TLS协议的运行机制.文章的重点是设计思想和运行过程,不涉及具体的实现细节.如果想了解这方面的内容,请参阅RFC文档. 一.作用 ...
- Java 根据当前时间获取明天、当前周的周五、当前月的最后一天
private Date getDateByType(Date date, Integer type) { Calendar calendar = Calendar.getInstance(); ca ...
- jfinal基本应用 --报主键重复
在使用jfinal 的Model过程中有一个很怪异的问题,发布到服务器上,只要是往表中添加字段,就报主键重复. 1.我添加表的时候调用了 public void create(Map map){ St ...
- android .9图的作用
参考:http://www.cnblogs.com/lianghui66/archive/2013/01/08/2850581.html .9图的介绍 1.这种格式的图片是Android平台上一种被拉 ...
- Orchard入门:如何创建一个完整Module
这是一个Orchard-Modules的入门教程.在这个教程里,我们将开发两个功能页面分别用于数据录入与数据展示. 完成上述简单功能开发,我们一共需要6个步骤.分别为: 创建Module 创建Mode ...