PRML读书笔记——3 Linear Models for Regression
Linear Basis Function Models
线性模型的一个关键属性是它是参数的一个线性函数,形式如下:

w是参数,x可以是原始的数据,也可以是关于原始数据的一个函数值,这个函数就叫basis function,记作φ(x),于是线性模型可以表示成:
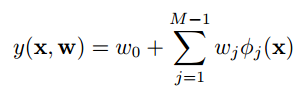
w0看着难受,定义一个函数φ0(x) = 1, 模型的形式再一次简化成:
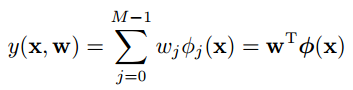
以上就是线性模型的一般形式。basis function有很多选择,例如Gaussian、sigmoid、tanh (tanh(x) = 2 * sigmoid(a) − 1)。
Maximum likelihood and least squares
训练线性模型的时候,假设cost function为sum-of-squares error function,那么minimize cost function 和 maximize likelihood function是等价的。
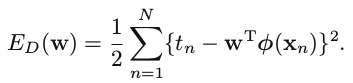
另外一个发现就是,w0最终解出来为target values的均值 和 各个特征的basis function values均值的加权和 的差,如下:
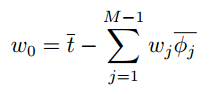
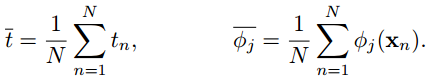
Regularized least squares
一般的正则化形式如下:
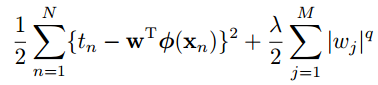
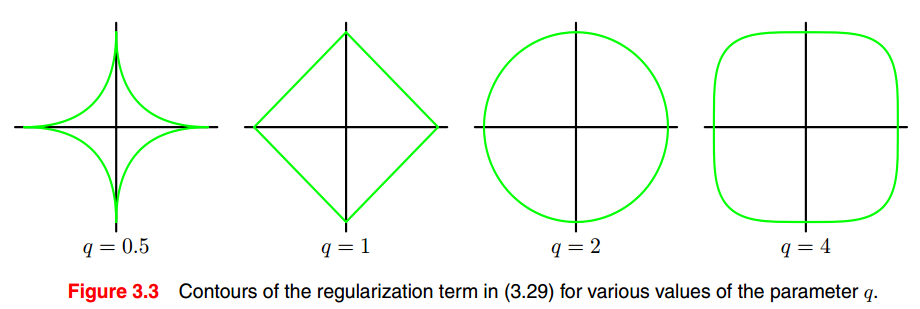
q = 1, 为lasso(least absolute shrinkage and selection operator) 正则化,其特点是,当λ足够大的时候,某些参数会趋向0,看下图。
q = 2, 二次正则化,使得一些参数足够小。
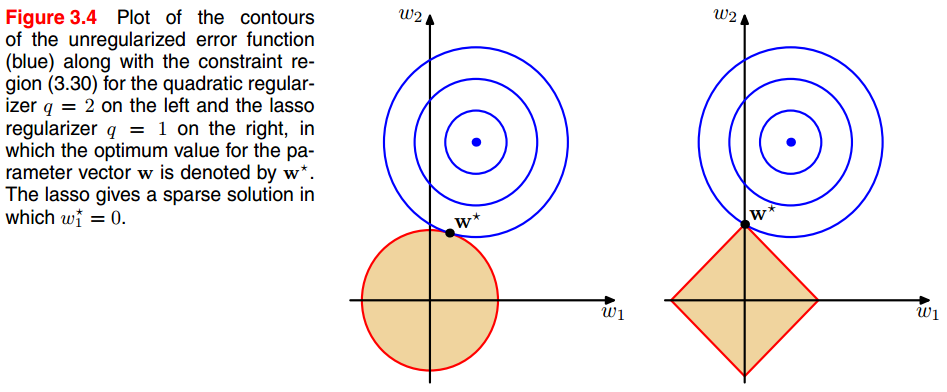
Bias-Variance trade-off
假设y(x, D)代表基于数据集D训练出来的regression function, h(x)代表数据集D中,给定x条件下target value的期望
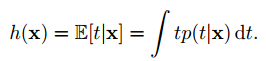
squared loss function可以写成:
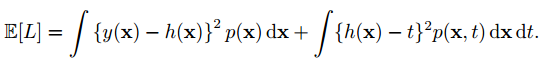
后一项与y(x)无关,考虑前一项积分里面的部分:
{y(x; D) − h(x)}2 = {y(x; D) − ED[y(x; D)] + ED[y(x; D)] − h(x)}2
= {y(x; D) − ED[y(x; D)]}2 + {ED[y(x; D)] − h(x)}2
+2{y(x; D) − ED[y(x; D)]}{ED[y(x; D)] − h(x)}
这样积分取期望后为:
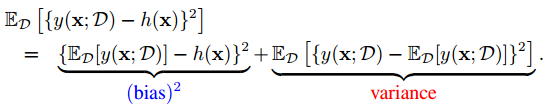
前一项为bias,后一项为variance。
于是loss function的总体希望就为,(bias)2 + variance + noise
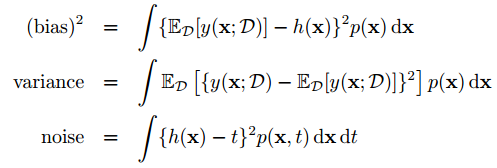
于是就产生了bias-variance trade-off问题, flexible models低bias,高variance;rigid models 高bias,低variance。
在实际应用中,为了观察bias和variance,计算如下:
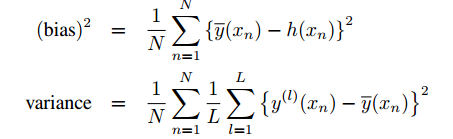
其中:
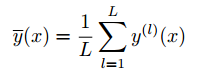
y(l)(x)是prediction function。
Bayesian Linear Regression(该段摘自Jian Xiao(iamxiaojian@gmail.com)的笔记Notes on Pattern Recognition and Machine Learning (Bishop))
Bayesian 方法能够避免 over-fitting 的原因是: Marginalizing over the model parameters instead of making point estimates of their values.
假设有多个 model;观察到的 data set 是 D。 Bayesian 的 model comparison 方法是,比较各个模型的后验概率,即:
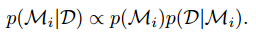
先验概率 p(Mi) allows us to express a preference for different model。可以假设每个模型的先验概率相等,那么剩下要比较的关键是: p(D|Mi) ——model evidence 或 marginal likelihood。
Model averaging V.S. model selection
Model averaging:把多个模型,用各自模型的后验概率加权平均,得到 predictive distribution为
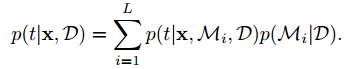
Model selection: 只选择一个模型,即其中后验概率最大的模型。这是一种 approximation to model averaging。以上分析可以看出,各个 model 的后验概率是关键,而计算后验概率的关键又是 model evidence。
从 sampling 的角度看, Mi 相当于 hyper-parameter,而 w 则是 parameter。 一个 model 不同于另一个 model,是因为 hyper-parameter。
The Evidence Approximation
full Bayesian需要marginalize with respect to hyper-parameters as well as parameters,例如hyperparameter是alpha和beta,w是parameter,那么predictive distribution为:
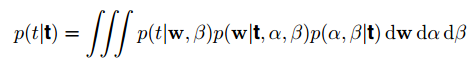
就比较难,这里就考虑一种approximation,给hyperparameters设置一个特定的数值,这个数值由maximizing the marginal likelihood function 来确定。这个方法叫empirical Bayes、 type 2 maximum likelihood、generalized maximum likelihood、evidence approximation(in machine learning)
Previous Chapter | Next Chapter
PRML读书笔记——3 Linear Models for Regression的更多相关文章
- PRML读书笔记——Introduction
1.1. Example: Polynomial Curve Fitting 1. Movitate a number of concepts: (1) linear models: Function ...
- Andrew Ng机器学习公开课笔记 -- Generalized Linear Models
网易公开课,第4课 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 前面介绍一个线性回归问题,符合高斯分布 一个分类问题,logstic回 ...
- [Scikit-learn] 1.1 Generalized Linear Models - Logistic regression & Softmax
二分类:Logistic regression 多分类:Softmax分类函数 对于损失函数,我们求其最小值, 对于似然函数,我们求其最大值. Logistic是loss function,即: 在逻 ...
- PRML读书会第三章 Linear Models for Regression(线性基函数模型、正则化方法、贝叶斯线性回归等)
主讲人 planktonli planktonli(1027753147) 18:58:12 大家好,我负责给大家讲讲 PRML的第3讲 linear regression的内容,请大家多多指教,群 ...
- PRML读书笔记——机器学习导论
什么是模式识别(Pattern Recognition)? 按照Bishop的定义,模式识别就是用机器学习的算法从数据中挖掘出有用的pattern. 人们很早就开始学习如何从大量的数据中发现隐藏在背后 ...
- PRML-Chapter3 Linear Models for Regression
Example: Polynomial Curve Fitting The goal of regression is to predict the value of one or more cont ...
- Coursera台大机器学习课程笔记10 -- Linear Models for Classification
这一节讲线性模型,先将几种线性模型进行了对比,通过转换误差函数来将linear regression 和logistic regression 用于分类. 比较重要的是这种图,它解释了为何可以用Lin ...
- [Scikit-learn] 1.1 Generalized Linear Models - Lasso Regression
Ref: http://blog.csdn.net/daunxx/article/details/51596877 Ref: https://www.youtube.com/watch?v=ipb2M ...
- PRML读书笔记——线性回归模型(上)
本章开始学习第一个有监督学习模型--线性回归模型."线性"在这里的含义仅限定了模型必须是参数的线性函数.而正如我们接下来要看到的,线性回归模型可以是输入变量\(x\)的非线性函数. ...
随机推荐
- 常见开发需求之前端利器webstorm中的git和快捷键
需求 前端开发中我们最常用的一般是webstorm.hbuilder和sublime,因为以前使用过一段时间eclipse所以我对webstorm的感觉比较良好,再加上以前使用hbuilder维护 ...
- linux下 html转pdf
其实很简单的, 在当前文件夹中打开终端, 只需要一个命令就好 wkhtmltopdf test.html test.pdf 这样一个test.html的文件就转为test.pdf 的pdf文件啦!
- Java中的void
转:关于void 学过java的人都知道void的意思是空,是java中的关键字.最初在知道void的时候是public static void main(String[]args){},我记得当初接 ...
- HDU-1203(01背包)
I NEED A OFFER! Problem Description Speakless 很早就想出国,现在他已经考完了所有需要的考试,准备了所有要准备的材料,于是,便需要去申请学校了.要申请国外的 ...
- SOAPUI使用教程-WSDL项目---检查器
SoapUI Pro添加了许多可用的WSDL消息上下文的检查器. XSD / XML Schema检查器 XML Schema检查器显示当前节点对应的XML模式定义. 下面的屏幕截图显示了在Bing搜 ...
- Sass和compass 安装 和配合grunt实时显示 [Sass和compass学习笔记]
demo 下载http://vdisk.weibo.com/s/DOlfkrAWjkF/1401192855 为什么要学习Sass和compass ?提高站独立和代码产品化的绝密武器,尤其是程序化cs ...
- CSS中伪类及伪元素用法详解
CSS中伪类及伪元素用法详解 伪类的分类及作用: 注:该表引自W3School教程 伪元素的分类及作用: 接下来让博主通过一些生动的实例(之前的作业或小作品)来说明几种常用伪类的用法和效果,其他的 ...
- About_php_封装函数
<?php //编写数据库操作的魔术函数 function mysql_bind(){ //首先我们不知道外面会传入多少个参数 //可以用func_get_args()方法来获取全部传入参数,这 ...
- Python获取当前日期及时间
import time def GetNowTime(): return time.strftime("%Y%m%d%H%M%S",time.localtime(time.time ...
- stl文件格式
http://wenku.baidu.com/view/a3ab7a26ee06eff9aef8077b.html [每个三角形面片的定义包括三角形各个定点的三维坐标及三角形面片的法矢量[三角形的法线 ...