ZooKeeper的应用场景(转)
应用场景1 :统一命名服务
分布式应用中,通常需要一套完备的命令机制,既能产生唯一的标识,又方便人识别和记忆。 我们知道,每个ZNode都可以由其路径唯一标识,路径本身也比较简洁直观,另外ZNode上还可以存储少量数据,这些都是实现统一的NameService的基础。下面以在HDFS中实现NameService为例,来说明实现NameService的基本布骤:
- 目标:通过简单的名字来访问指定的HDFS机群
- 定义命名规则:这里要做到简洁易记忆。下面是一种可选的方案: [serviceScheme://][zkCluster]-[clusterName],比如hdfs://lgprc-example/表示基于lgprc ZooKeeper集群的用来做example的HDFS集群
- 配置DNS映射: 将zkCluster的标识lgprc通过DNS解析到对应的ZooKeeper集群的地址
- 创建ZNode: 在对应的ZooKeeper上创建/NameService/hdfs/lgprc-example结点,将HDFS的配置文件存储于该结点下
- 用户程序要访问hdfs://lgprc-example/的HDFS集群,首先通过DNS找到lgprc的ZooKeeper机群的地址,然后在ZooKeeper的/NameService/hdfs/lgprc-example结点中读取到HDFS的配置,进而根据得到的配置,得到HDFS的实际访问入口
应用场景2:配置管理
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台PC Server运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的PC Server,这样非常麻烦而且容易出错。
将配置信息保存在ZooKeeper的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到ZooKeeper的通知,然后从ZooKeeper获取新的配置信息应用到系统中。
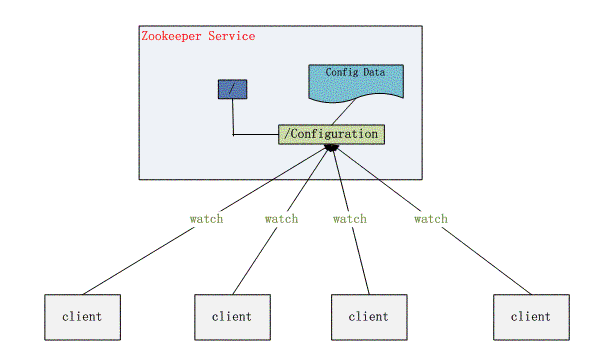
下面的基本的步骤:
- 将公共的配置内容放到ZooKeeper中某个ZNode上,比如/service/common-conf
- 所有的实例在启动时都会传入ZooKeeper集群的入口地址,并且在运行过程中Watch /service/common-conf这个ZNode
- 如果集群管理员修改了了common-conf,所有的实例都会被通知到,根据收到的通知更新自己的配置,并继续Watch /service/common-conf
应用场景 3:集群管理
ZooKeeper能够很容易的实现集群管理的功能,如有多台Server组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力时,就会增加一台或多台Server,同样也必须让“总管”知道。
ZooKeeper不仅能够维护当前的集群中机器的服务状态,而且能够选出一个“总管”,让这个总管来管理集群,这就是ZooKeeper的另一个功能LeaderElection。

规定编号最小的为Master,所以当我们对SERVERS节点做监控的时候,得到服务器列表,只要所有集群机器逻辑认为最小编号节点为Master,那么Master就被选出,而这个Master宕机的时候,相应的ZNode会消失,然后新的服务器列表就被推送到客户端,然后每个节点逻辑认为最小编号节点为Master,这样就做到动态Master选举。
四、 组员管理(Group Membership)
在典型的Master-Slave结构的分布式系统中,Master需要作为“总管”来管理所有的Slave, 当有Slave加入,或者有Slave宕机,Master都需要感知到这个事情,然后作出对应的调整,以便不影响整个集群对外提供服务。以HBase为例,HMaster管理了所有的RegionServer,当有新的RegionServer加入的时候,HMaster需要分配一些Region到该RegionServer上去,让其提供服务;当有RegionServer宕机时,HMaster需要将该RegionServer之前服务的Region都重新分配到当前正在提供服务的其它RegionServer上,以便不影响客户端的正常访问。下面是这种场景下使用ZooKeeper的基本步骤:
- Master在ZooKeeper上创建/service/slaves结点,并设置对该结点的Watcher
- 每个Slave在启动成功后,创建唯一标识自己的临时性(Ephemeral)结点/service/slaves/${slave_id},并将自己地址(ip/port)等相关信息写入该结点
- Master收到有新子结点加入的通知后,做相应的处理
- 如果有Slave宕机,由于它所对应的结点是临时性结点,在它的Session超时后,ZooKeeper会自动删除该结点
- Master收到有子结点消失的通知,做相应的处理
五、 简单互斥锁(Simple Lock)
在传统的应用程序中,线程、进程的同步,都可以通过操作系统提供的机制来完成。但是在分布式系统中,多个进程之间的同步,操作系统层面就无能为力了。这时候就需要像ZooKeeper这样的分布式的协调(Coordination)服务来协助完成同步,下面是用ZooKeeper实现简单的互斥锁的步骤,这个可以和线程间同步的mutex做类比来理解:
- 多个进程尝试去在指定的目录下去创建一个临时性(Ephemeral)结点 /locks/my_lock
- ZooKeeper能保证,只会有一个进程成功创建该结点,创建结点成功的进程就是抢到锁的进程,假设该进程为A
- 其它进程都对/locks/my_lock进行Watch
- 当A进程不再需要锁,可以显式删除/locks/my_lock释放锁;或者是A进程宕机后Session超时,ZooKeeper系统自动删除/locks/my_lock结点释放锁。此时,其它进程就会收到ZooKeeper的通知,并尝试去创建/locks/my_lock抢锁,如此循环反复
六、互斥锁(Simple Lock without Herd Effect)
有一个问题,每次抢锁都会有大量的进程去竞争,会造成羊群效应(Herd Effect),为了解决这个问题,我们可以通过下面的步骤来改进上述过程:
- 每个进程都在ZooKeeper上创建一个临时的顺序结点(Ephemeral Sequential) /locks/lock_${seq}
- ${seq}最小的为当前的持锁者(${seq}是ZooKeeper生成的Sequenctial Number)
- 其它进程都对只watch比它次小的进程对应的结点,比如2 watch 1, 3 watch 2, 以此类推
- 当前持锁者释放锁后,比它次大的进程就会收到ZooKeeper的通知,它成为新的持锁者,如此循环反复
这里需要补充一点,通常在分布式系统中用ZooKeeper来做Leader Election(选主)就是通过上面的机制来实现的,这里的持锁者就是当前的“主”。
七、读写锁(Read/Write Lock)
读写锁跟互斥锁相比不同的地方是,它分成了读和写两种模式,多个读可以并发执行,但写和读、写都互斥,不能同时执行行。利用ZooKeeper,在上面的基础上,稍做修改也可以实现传统的读写锁的语义,下面是基本的步骤:
- 每个进程都在ZooKeeper上创建一个临时的顺序结点(Ephemeral Sequential) /locks/lock_${seq}
- ${seq}最小的一个或多个结点为当前的持锁者,多个是因为多个读可以并发
- 需要写锁的进程,Watch比它次小的进程对应的结点
- 需要读锁的进程,Watch比它小的最后一个写进程对应的结点
- 当前结点释放锁后,所有Watch该结点的进程都会被通知到,他们成为新的持锁者,如此循环反复
八、屏障(Barrier)
在分布式系统中,屏障是这样一种语义: 客户端需要等待多个进程完成各自的任务,然后才能继续往前进行下一步。下用是用ZooKeeper来实现屏障的基本步骤:
- Client在ZooKeeper上创建屏障结点/barrier/my_barrier,并启动执行各个任务的进程
- Client通过exist()来Watch /barrier/my_barrier结点
- 每个任务进程在完成任务后,去检查是否达到指定的条件,如果没达到就啥也不做,如果达到了就把/barrier/my_barrier结点删除
- Client收到/barrier/my_barrier被删除的通知,屏障消失,继续下一步任务
九、双屏障(Double Barrier)
双屏障是这样一种语义: 它可以用来同步一个任务的开始和结束,当有足够多的进程进入屏障后,才开始执行任务;当所有的进程都执行完各自的任务后,屏障才撤销。下面是用ZooKeeper来实现双屏障的基本步骤:
进入屏障:
- Client Watch /barrier/ready结点, 通过判断该结点是否存在来决定是否启动任务
- 每个任务进程进入屏障时创建一个临时结点/barrier/process/${process_id},然后检查进入屏障的结点数是否达到指定的值,如果达到了指定的值,就创建一个/barrier/ready结点,否则继续等待
- Client收到/barrier/ready创建的通知,就启动任务执行过程
离开屏障:
- Client Watch /barrier/process,如果其没有子结点,就可以认为任务执行结束,可以离开屏障
- 每个任务进程执行任务结束后,都需要删除自己对应的结点/barrier/process/${process_id}
十、共享锁(Locks)
共享锁在同一个进程中很容易实现,但是在跨进程或者在不同 Server 之间就不好实现了。Zookeeper 却很容易实现这个功能,实现方式也是需要获得锁的 Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了。
当分布式系统操作数据,例如:读取数据、分析数据、最后修改数据。在分布式系统里这些操作可能会分散到集群里不同的节点上,那么这时候就存在数据操作过程中一致性的问题,如果不一致,我们将会得到一个错误的运算结果,在单一进程的程序里,一致性的问题很好解决,但是到了分布式系统就比较困难,因为分布式系统里不同服务器的运算都是在独立的进程里,运算的中间结果和过程还要通过网络进行传递,那么想做到数据操作一致性要困难的多。Zookeeper提供了一个锁服务解决了这样的问题,能让我们在做分布式数据运算时候,保证数据操作的一致性。
十一、队列管理
ZooKeeper可以处理两种类型的队列:
1、同步队列:当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
同步队列用ZooKeeper 实现的实现思路如下:
- 创建一个父目录/synchronizing,每个成员都监控标志(Set Watch)位目录/synchronizing/start是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建/synchronizing/member_i的临时目录节点,然后每个成员获取/synchronizing目录的所有目录节点,也就是member_i。判断i的值是否已经是成员的个数,如果小于成员个数等待/synchronizing/start的出现,如果已经相等就创建/synchronizing/start。
2、FIFO队列:先进先出队列,例如实现生产者和消费者模型。
FIFO队列用ZooKeeper实现思路如下:
- 实现的思路也非常简单,就是在特定的目录下创建SEQUENTIAL类型的子目录/queue_i,这样就能保证所有成员加入队列时都是有编号的,出队列时通过getChildren()方法可以返回当前所有的队列中的元素,然后消费其中最小的一个,这样就能保证FIFO。
总结
ZooKeeper作为Hadoop项目中的一个子项目,是Hadoop集群管理的一个必不可少的模块,它主要用来控制集群中的数据,如它管理Hadoop集群中的NameNode,还有Hbase 中Master Election、Server之间状态同步等。
ZoopKeeper提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管理模型。
参考:
http://www.cnblogs.com/raphael5200/p/5289768.html(以上小部分内容转自此篇文章)
http://www.wuzesheng.com/?p=2609(以上大部分内容转自此篇文章)
http://blog.chinaunix.net/uid-26748613-id-4536290.html(以上小部分内容转自此篇文章)
ZooKeeper的应用场景(转)的更多相关文章
- ZooKeeper典型应用场景
ZooKeeper典型应用场景一览 数据发布与订阅(配置中心) 发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据发布到ZK节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新.例 ...
- ZooKeeper典型应用场景一览
原文地址:http://jm-blog.aliapp.com/?p=1232 ZooKeeper典型应用场景一览 数据发布与订阅(配置中心) 发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据 ...
- ZooKeeper典型应用场景(转)
ZooKeeper是一个高可用的分布式数据管理与系统协调框架.基于对Paxos算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基于这样的特性,使得ZooKeeper解决很多分布式问题.网上 ...
- ZOOKEEPER典型应用场景解析
zookeeper实现了主动通知节点变化,原子创建节点,临时节点,按序创建节点等功能.通过以上功能的组合,zookeeper能够在分布式系统中组合出很多上层功能.下面就看几个常用到的场景,及使用方式和 ...
- ZooKeeper典型应用场景概览
ZooKeeper是一个高可用的分布式数据管理与系统协调框架.基于对Paxos算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基于这样的特性,使得ZooKeeper解决很多分布式问题.网上 ...
- 搞懂分布式技术6:Zookeeper典型应用场景及实践
搞懂分布式技术6:Zookeeper典型应用场景及实践 一.ZooKeeper典型应用场景实践 ZooKeeper是一个高可用的分布式数据管理与系统协调框架.基于对Paxos算法的实现,使该框架保证了 ...
- ZooKeeper 典型应用场景-数据发布与订阅
ZooKeeper 是一个高可用的分布式数据管理与系统协调框架.基于对 Paxos 算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基于这样的特性,使得 ZooKeeper 可以解决很多分 ...
- 面试题:4个zookeeper的应用场景,你知道几个?
前言 现在聊的 topic 是分布式系统,面试官跟你聊完了 dubbo 相关的一些问题之后,已经确认你对分布式服务框架/RPC框架基本都有一些认知了.那么他可能开始要跟你聊分布式相关的其它问题了. 分 ...
- zookeeper系列(四)zookeeper的使用场景
作者:leesf 掌控之中,才会成功:掌控之外,注定失败. 出处:http://www.cnblogs.com/leesf456/p/6036548.html感谢原著公开这么好的博文供大家学习 ...
- zookeeper典型应用场景之一:master选举
对于zookeeper这种东西,仅仅知道怎么安装是远远不够的,至少要对其几个典型的应用场景进行了解,才能比较全面的知道zk究竟能干啥,怎么玩儿,以后的日子里才能知道这货如何能为我所用.于是,有了如下的 ...
随机推荐
- 安科 OJ 1054 排队买票 (递归,排列组合)
时间限制:1 s 空间限制:128 M 题目描述 有M个小孩到公园玩,门票是1元.其中N个小孩带的钱为1元,K个小孩带的钱为2元.售票员没有零钱,问这些小孩共有多少种排队方法,使得售票员总能找得开零钱 ...
- sql 全站搜索
SQL全站搜索 create proc Full_Search(@string varchar(50)) as begin declare @tbname varchar(50) declare tb ...
- TypeScript `infer` 关键字
考察如下类型: type PromiseType<T> = (args: any[]) => Promise<T>; 那么对于符合上面类型的一个方法,如何得知其 Prom ...
- JavaScript--编程挑战
小伙伴们,请编写"改变颜色"."改变宽高"."隐藏内容"."显示内容"."取消设置"的函数,点击相应 ...
- hihocode 编程练习赛17
1. f1 score 首先了解f1 score的计算方法, 我记得是学信息检索知道的, 然后简单处理就行. 由于我写的比较麻烦, 中间处理过程引入了一些除数为0的情况,导致错了很多次.其实是很简单的 ...
- java学习笔记_BeatBox(GUI部分)
import java.awt.*; import javax.swing.*; public class BeatBox { JFrame theFrame; JPanel mainPanel; S ...
- 3--Java NIO基础1
一.NIO概述 1. BIO带来的挑战 BIO即堵塞式I/O,数据在写入或读取时都有可能堵塞,一旦有堵塞,线程将失去CPU的使用权,性能较差. 2. NIO工作机制 Java NIO由Channel. ...
- 清瘦的记录者: 一个比dbutils更小巧、好用的的持久化工具
https://gitee.com/bitprince/memory 1. 概述 1.1 连接.语句和结果集 从JDBC的规范上看,其对数据访问层有相当简洁的抽象:1.连接(connection) 2 ...
- Java_Web三大框架之Hibernate 入门(一)
一.Hibernate简介: Hibernate作者——Gavin King Hibernate创始人 < Hibernate in action >作者 EJB 3.0的Entity b ...
- Java编译器、JVM、解释器
Java虚拟机(JVM)是可运行Java代码的假想计算机.只要根据JVM规格描述将解释器移植到特定的计算机上,就能保证经过编译的任何Java代码能够在该系统上运行.本文首先简要介绍从Java文件的编译 ...