初创电商公司Drop的数据湖实践
欢迎关注微信公众号:ApacheHudi
1. 引入
Drop是一个智能的奖励平台,旨在通过奖励会员在他们喜爱的品牌购物时获得的Drop积分来提升会员的生活,同时帮助他们发现与他们生活方式产生共鸣的新品牌。实现这一体验的核心是Drop致力于在整个公司内推广以数据为基础的文化,Drop的数据用于多种形式,包括但不限于商业智能、测量实验和构建机器学习模型。
为了确保有效地利用数据,工程团队一直在寻找可以改善基础架构以适应当前和未来的需求的方法,与许多其他高成长型初创公司的经验类似,我们对数据的需求规模超过了基础架构的能力,因此需要将以商业智能为中心的数据基础架构演变为可以释放大数据需求和能力的基础架构。
2. 动机
Drop在成立之初就着力构建数据基础架构,以便利用自动报告和仪表板来观察关键业务的指标。我们的第一代数据基础架构使用以AWS Redshift数据仓库为中心的架构,使用Apache Airflow调度自定义批处理ETL作业,使用Looker构建自动化仪表板和报告。

该架构实现了我们的早期目标,但是利用数据的需求已经超出了商业智能的范围。为向会员提供更个性化的体验,我们需要一个支持高级功能的数据平台,例如更深入的分析、全面的实验测量以及机器学习模型的开发,我们也意识到原来架构的技术限制可能会阻止我们解锁那些所需的功能,一些最突出的限制包括:
- 随着数据规模的扩大,关键的ETL作业的运行时间猛增,一些作业无法在24小时内运行。
- AWS Redshift将计算与存储混合在一起,限制了提取数据到仓库的扩展能力,在Redshift中提供的数据选择非常有限,从而偏离了其作为“中心”的位置。
- 在Redshift集群之上构建机器学习架构效果并不理想,因为Redshift仅能处理结构化数据,并且用于填充仓库的批处理ETL作业延迟较高。
为解决这些不足并考虑到后续的扩展性,我们需要继续构建数据基础架构。数据湖是一个集中式存储库,能够存储任何规模的非结构化和结构化数据,构建数据湖将使我们能够解决第一代数据基础架构的局限性,同时允许我们保留原始架构的关键组件,这些组件仍然满足后续的长期数据基础架构计划。
3. 构建数据湖
当开始构建Drop的数据湖时,我们遵循以下指导原则:
- 技术堆栈保持简单:作为Drop Engineering的核心理念之一,我们旨在利用现有的和经过验证的AWS技术来简化我们的技术栈,已有AWS经验能够让我们快速制作新功能原型以及利用AWS生态系统中其他服务的集成优势,因此继续使用AWS技术意义重大。我们在整个数据团队中继续保留Python和SQL,因此无需学习用于数据提取或处理的新语言,而是使用PySpark来构建所有Apache Spark作业。
- 避免重复造轮子:在开源和技术社区中寻找成功的数据湖实施案例和经验,并向Uber和Airbnb寻求有关顶层设计的思路和灵感,有关更多特定技术的知识,我们依赖于已发布的AWS re:Invent的演讲,通过参加2018年的AWS re:Invent并听取Robinhood关于他们如何实现数据湖的故事,一切都得以实现,Robinhood的故事与我们技术栈非常相似,对要解决的问题以及解决问题的理念产生了深深的共鸣,所有这些故事和资源组成了我们数据湖的最初蓝图。
- 确保可扩展性:随着我们的组织从早期的初创企业过渡到高速增长的企业,数据的规模以及利用数据的复杂性迅速增长,这意味着需要在指数增长方案中有效执行的技术,同时最小化相关技术的复杂性开销。
4. 总体架构
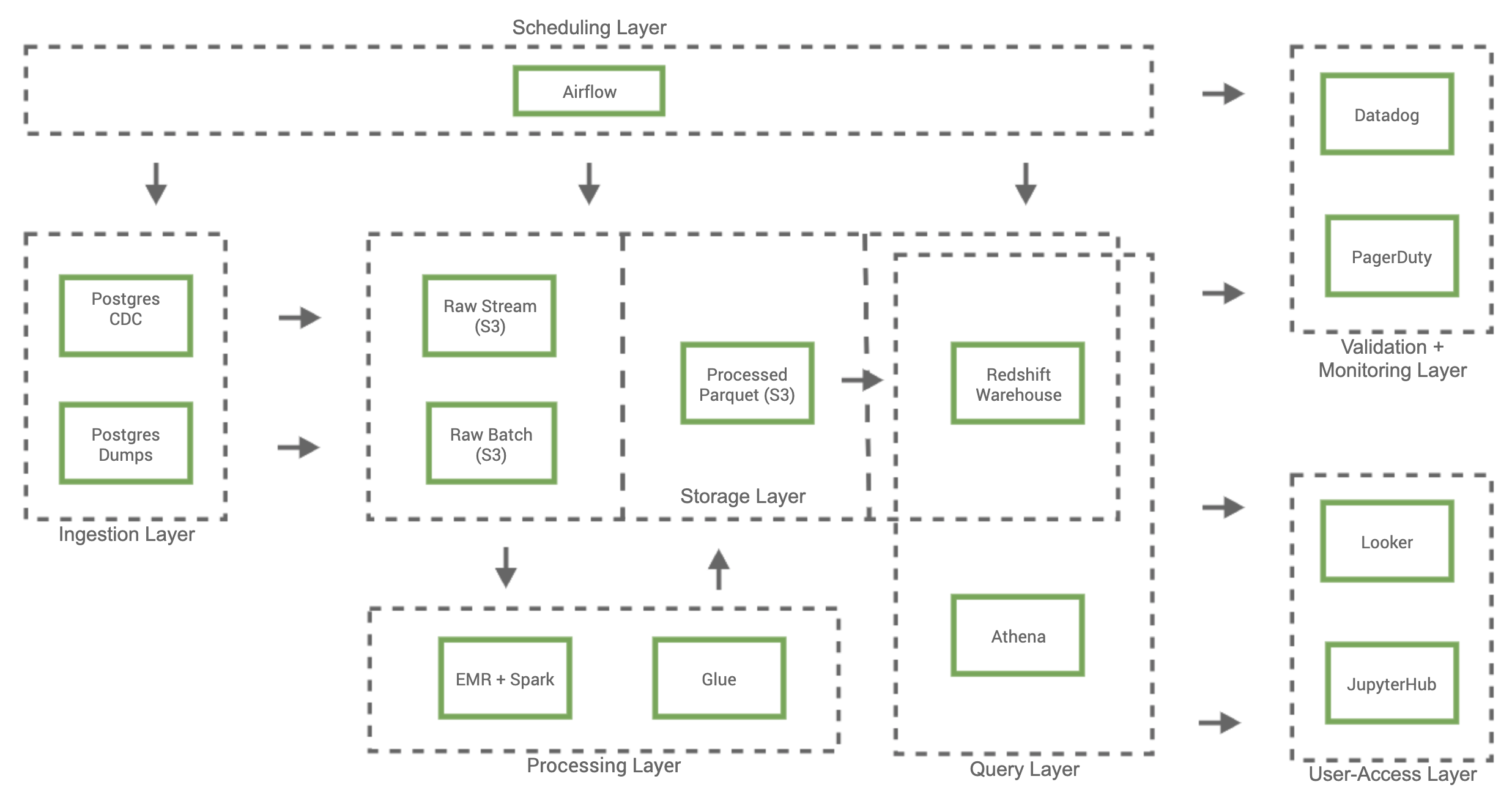
5. 数据湖
5.1 调度层
调度层负责管理和执行数据湖中所有工作流程,调度程序会协调数据湖中所有数据的大部分移动,利用Airflow使我们能够通过Airflow有向无环图(DAG)构建所有工作流和基础架构,这也简化了我们的工程开发和部署流程,同时为我们的数据基础架构提供了版本控制,Apache Airflow项目还包含大量支持AWS的集成库和示例DAG,使我们能够快速集成和评估新技术。
5.2 摄入层
当从多个不同的数据源(例如服务器日志,增长营销平台和业务运营服务)拉取数据时,数据主要是从RDS Postgres数据库,以批处理和流处理两种形式提取到数据湖。我们选择AWS Database Migration Services(DMS)来摄取这些表单,因为它与RDS Postgres进行了原生集成,并且能够以批和流形式将数据提取到S3中,DMS复制Postgres“预写日志(WAL)”的数据,以“变更数据捕获(CDC)”任务进入数据湖,并在S3上生成一分钟分区的Apache Parquet文件,此为流处理方式。批处理使用DMS的“全量迁移”任务以将Postgres库表的快照导入S3数据湖,批处理管道由调度层通过Airflow以自定义DAG的形式进行管理,这允许我们控制批快照到S3的调度,并在批运行结束时关闭未使用的DMS资源以降低服务成本。

5.3 处理层
处理层负责将数据从存储层的“原始(Raw)”部分转换为数据湖的“列式(Columnarized)”部分中的标准化列式和分区结构。我们使用Lambda架构来协调给定数据源的批和流数据,这种数据处理模型使我们能够将高质量的批量快照与一分钟延迟流文件相结合来生成给定数据集的最新列式版本。我们将AWS Glue及其Data Catalog(数据目录)用作数据湖的中央metastore管理服务,metastore包含每个数据集的元数据,例如在S3中的位置、结构定义和整体大小,也可以使用AWS Glue Crawlers捕获和更新该元数据,整个流程如下:
- 调度层启动处理特定数据集Lambda架构的DAG。
- DAG将PySpark应用程序加载到S3,启动AWS EMR集群,并在EMR中运行PySpark应用程序。
- 来自存储层“原始”部分的批和流数据均作为EMR Spark应用程序的输入,最终输出是存储层“列式”部分中使用Lambda架构进行协调的Parquet数据集。
- 完成EMR步骤后终止EMR集群以便降低EMR成本。
- 运行AWS Glue Crawler程序以更新AWS Glue目录中表的元数据,该目录元数据充当整个数据湖的中央metastore。

5.4 存储层
S3作为存储平台的原因有以下三个:易用性、高可靠性和相对低成本。数据存储在存储层中的“原始”和“列式”两部分都基于S3,而“数仓(Warehouse)”中的数据位于Redshift集群中。数据湖中的所有数据首先通过摄入层以各种格式进入“Raw”部分,为了使数据保存到“列式”部分中,数据会通过处理层转换为“列式”部分,并遵守分区标准。我们选择Apache Parquet作为标准列式文件格式,因为Apache Parquet广泛用于数据处理服务中,并且具有性能和存储优势。存储层的“数仓”部分由Redshift数据仓库组成,其数据来自“原始”和“列式”部分。还可以通过数据“热度”对存储层的各部分进行分类,类比于数据的访问频率,“原始”数据数据最冷,“列式”数据比“原始”数据更热,而“数仓”数据是最热的数据,因为它经常会被自动化仪表板和报告访问。S3的另一个优势是我们能够根据数据规模控制成本,对于较冷的数据,我们可以更变S3存储类型或者将数据迁移到AWS Glacier以降低成本。
5.5 从数据湖访问数据
技术团队和非技术团队都会使用数据湖,以便更好地为决策提供依据并增强整体产品体验,非技术团队通常通过商业智能平台Looker来访问数据,以自动化仪表板和报告的形式监控各项指标。
技术团队应用范围更广,从探索性分析中的即席查询到开发机器学习模型和管道。可以通过AWS Athena托管的Presto服务或通过Redshift数据仓库直接查询数据湖中的数据。AWS Athena还与AWS Glue的数据目录集成,这使Athena可以完全访问我们的中央metastore,这种原生集成使得Athena可以充当S3中存储数据的主要查询服务。我们还能够利用Redshift Spectrum查询S3数据,这在即席查询场景下特别有用,我们也希望使用S3的数据来丰富Redshift集群的数据。为了对机器学习模型进行更正式的探索性分析和开发,需要结合使用Spark和Glue目录来查询或直接与S3中的对象进行交互。
5.6 检查与监控
确保数据湖的消费者完全信任数据的准确性至关重要,我们建立了一套全面的检查和监控程序以提醒我们任何意外情况。我们通过Airflow DAG构建的绝大多数数据湖流程,并且能够使用Datadog监视Airflow作业失败,并通过PagerDuty将关键问题转发给工程师。为了建立数据质量检查,我们还构建了一系列Airflow DAG,以生成特定数据集的自定义数据验证指标,我们在给定数据集上运行的一组标准的验证检查和指标包括但不限于空检查、行计数检查和数据延迟指标,这些指标都会被推送到Datadog,这样便可以在其中监视异常并在必要时向参与者发出告警。

6. 当前情况
Drop的数据湖现在每天从Postgres数据库中提取十亿条记录,并处理TB级的作业,该数据湖已被众多团队采用,并为增强了数据分析能力以及开发和交付机器学习模型的能力。总体而言,该架构效果不错,并且我们相信数据基础架构的发展将使我们处于更好的位置,以适应当前和未来的需求。
7. 重点总结
我们的实施过程踩过不少坑,总结如下:
- 提取列式的数据的好处:尽管存储层的“原始”部分与文件格式无关,但是以列式提取数据对下游更有利,当从Postgres表中摄取数据时,这些表包含冗长和复杂文本Blob的列(例如jsonb列),下游解析数据就成了噩梦,进一步依赖serDe文件来协助解析数据只会增加整体复杂性,由于Parquet的固有特性,将DMS配置为以Parquet格式输出文件可保持列的架构完整性,并且我们的下游处理层作业也可提升速度和数据质量性能,这种折衷是以增加DMS生成parquet文件所需的内存资源为代价的。
- 技术栈使用Spark:我们的工程团队以前在内部Hadoop方面的经验非常有限,因此采用Spark带来了很多麻烦。尽管有大量可用的Spark资源,但我们最大的痛点还是资源管理和错误排除,我们选择EMR而不是AWS Gule构建ETL作业,这会提交已利用资源的控制级别,提升了性能和节约成本节约,但代价是复杂性的提升。为每个Spark作业配置最佳EMR资源非常复杂,我们很快了解到这些优化工作需要浪费高昂的时间。当EMR作业失败时,我们也很难解决根源问题,在很多情况下,EMR群集生成的错误日志不够细致,并且有时也掩盖了重要细节。通过改进日志记录过程并直接引用Spark执行程序日志,我们能够发现更详细的信息,从而更快发现根本原因。
- 关闭空闲资源:我们可以将节省的大部分费用归功于我们在处理临时工作负载方面的经验,通过将几乎所有的数据湖操作都构造为Airflow DAG,我们可以自动化何时删除未使用的资源,我们只有在需要通过Airflow进行批量提取作业时才启动DMS复制实例的能力,这使我们节省了始终保持实例可用的等效成本的90%以上。类似地,当我们的Airflow调度处理层作业时,我们仅使用竞价型实例启动EMR集群,并在完成时终止集群,这与我们始终拥有可用节点相比,平均节省了70%以上。
8. 下一步计划
我们也在寻找改善数据基础架构的方法,并且已经开始制定下一步计划,包括:
- 通过诸如Apache Hudi或Delta Lake之类的技术改善数据可用性以及存储层中的版本控制管理。
- 通过Apache Kafka和Debezium进行事件驱动开发来调整我们的摄入层功能。
- 使用AWS Lake Formation等工具改善数据访问治理,这样可以对团队访问哪些数据进行严格控制。
初创电商公司Drop的数据湖实践的更多相关文章
- 谈B2B电商平台与大数据
数据为王,服务为本——谈B2B电商平台与大数据 2013-06-27 11:10:41 作者:B2B行业资讯 标签: 大数据 ...
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
- 电商网站垮IDC数据备份,MySql主从同步,图片及其它数据文件的同步
原文网址:http://www.bzfshop.net/article/180.html 对一个电子商务网站而言,最宝贵的资源就是数据.服务器是很廉价的东西,即使烧了好几个也问题不大,但是用户数据如果 ...
- 印度最大在线食品杂货公司Grofers的数据湖建设之路
1. 起源 作为印度最大的在线杂货公司的数据工程师,我们面临的主要挑战之一是让数据在整个组织中的更易用.但当评估这一目标时,我们意识到数据管道频繁出现错误已经导致业务团队对数据失去信心,结果导致他们永 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- 基于 DataLakeAnalytics 的数据湖实践
随着软硬件各方面条件的成熟,数据湖(Data Lake)已经越来越受到各大企业的青睐, 与传统的数仓实践不一样的是,数据湖不需要专门的“入仓”的过程,数据在哪里,我们就从哪里读取数据进行分析.这样的好 ...
- 09-Flutter移动电商实战-移动商城数据请求实战
1.URL接口管理文件建立 第一步需要在建立一个URL的管理文件,因为课程的接口会一直进行变化,所以单独拿出来会非常方便变化接口.当然工作中的URL管理也是需要这样配置的,以为我们会不断的切换好几个服 ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 杯具,万达电商又换CEO
万达电商CEO再离职.而这距他入职还差一个月才满一年. 昨晚.万达电商CEO董策告诉新浪科技6月3日已正式从万达电商离职.将去往澳洲照应家人.而谈到离职原因和万达电商时,董策以开会为由收了电话. 从2 ...
随机推荐
- Web服务器的配置与管理
Web服务器的配置与管理(2) 虚拟主机技术 在上篇博文中,我们已经利用IIS搭建好了一台Web服务器,并可以成功访问IIS中自带的默认站点,那么我们是否可以在这台服务器中再创建另外一个Web站点?也 ...
- SSM 生成mapper中xml文件:未能解析映射资源:“文件嵌套异常
错误日记我就网上随便找个贴着: 错误一: org.springframework.beans.factory.BeanCreationException: Error creating bean wi ...
- id0-rsa WP合集
忙里偷闲做做题wwwwwwwwwwwww Intro to Hashing Intro to PGP Hello PGP Hello OpenSSL Intro to RSA Caesar Hello ...
- keepalive笔记之三:keepalived通知脚本进阶示例
下面的脚本可以接受选项,其中: -s, --service SERVICE,...:指定服务脚本名称,当状态切换时可自动启动.重启或关闭此服务: -a, --address VIP: 指定相关虚拟路由 ...
- dTree动态生成树(后台处理,简化前台操作)
dTree是个很方便在页面生成树的 js 控件,如果你下载了,我猜里在几分钟之内便能在页面上显示出一颗树来. 它本身给的例子是通过一些静态数据构造树,下面我说一种通过查询的数据动态构造树的方法. 例子 ...
- Unique Snowflakes(窗口滑动)
题目: Emily the entrepreneur has a cool business idea: packaging and selling snowflakes. She has devis ...
- oracle中group by 和order by同时存在时
关键点:order by 的栏位必须在group by 中有:例如:select name from TABLE group by name ,id order by id asc
- 安卓权威编程指南 挑战练习 25章 深度优化 PhotoGallery 应用
你可能已经注意到了,提交搜索时, RecyclerView 要等好一会才能刷新显示搜索结果.请接受挑战,让搜索过程更流畅一些.用户一提交搜索,就隐藏软键盘,收起 SearchView 视图(回到只显示 ...
- 安卓权威编程指南 挑战练习 13.8 用于RecyclerView的空视图
当前,CriminalIntent应用启动后,会显示一个空白列表.从用户体验上来讲,即使crime列表 是空的,也应展示提示或解释类信息. 请设置空视图展示类似“没有crime记录可以显示”的信息.再 ...
- 理解 Java 内存模型的因果性约束
目录 理解 Java 内存模型的因果性约束 欢迎讨论 规范理解 例子练习 例子1 例子2 总结 理解 Java 内存模型的因果性约束 欢迎讨论 欢迎加入技术交流群186233599讨论交流,也欢迎关注 ...