Mysql快速入门(看完这篇能够满足80%的日常开发)
这是一篇mysql的学习笔记,整理结合了网上搜索的教程以及自己看的视频教程,看完这篇能够满足80%的日常开发了。
菜鸟教程:https://www.runoob.com/mysql/mysql-tutorial.html
MySQL参考手册中文版:https://tool.oschina.net/apidocs/apidoc?api=mysql-5.1-zh
1 前言
1.1 什么是关系型数据库
MySQL 为关系型数据库。
关系数据库管理系统RDBMS(Relational Database Management System)的特点:
- 数据以表格的形式出现
- 每行为各种记录
- 每列为记录所对应的数据域
- 许多的行和列组成一张表单
- 若干的表单组成database
在(数据)表中有行、列之分。在多数数据库系统中,数据表中的列称为字段,有的也称为域,数据表中的行称为记录。一个(数据)表由行(记录)和列(字段)构成,组成一个二维关系表。而一个真正的数据库由若干张表、视图及相关的文件等组成一个统一的相关联的系统。
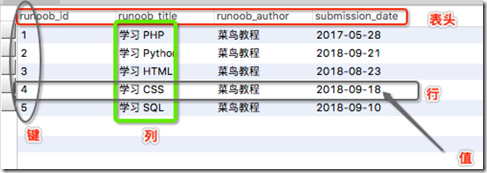
1.2 RDBMS 术语
在我们开始学习MySQL 数据库前,让我们先了解下RDBMS的一些术语:
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体,是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
- 表头(header): 每一列的名称;
- 行(row): 每一行用来描述某条记录的具体信息;
- 值(value): 行的具体信息, 每个值必须与该列的数据类型相同;
- 键(key): 键的值在当前列中具有唯一性。
1.3 与非关系型数据对比
1)关系型数据库
最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织
优点:
- 易于维护:都是使用表结构,格式一致;
- 使用方便:SQL语言通用,可用于复杂查询;
- 复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。
缺点:
- 读写性能比较差,尤其是海量数据的高效率读写;
- 固定的表结构,灵活度稍欠;
- 高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
2)非关系型数据库
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
优点:
- 格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
- 速度快:nosql可以使用硬盘或内存作为载体,而关系型数据库只能使用硬盘;
- 高扩展性;
- 成本低:nosql数据库部署简单,基本都是开源软件。
缺点:
- 不提供sql支持,学习和使用成本较高。
- 数据结构相对复杂,复杂查询方面稍欠。
2 环境搭建
方法一: 使用phpstudy快速搭建(如果是学习建议用此方法)。
方法二:自己下载源码搭建,这里以windows下搭建为例。
mysql下载地址:https://dev.mysql.com/downloads/mysql/
1)将下好的压缩包解压
这里压缩在:C:\Program Files\mysql-8.0.15-winx64
2)在安装目录下,新建my.ini文件,
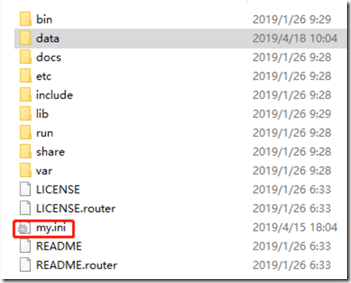
文件内容如下,其中basedir\datadir根据实际情况修改:
注意这里保存时编码为ansi,用记事本编辑就好了
[mysqld]
# 设置3306端口
port=3306
# 设置mysql的安装目录
basedir=C:\Program Files\mysql-8.0.15-winx64
# 设置mysql数据库的数据的存放目录
datadir=C:\Program Files\mysql-8.0.15-winx64\data
# 允许最大连接数
max_connections=200
# 允许连接失败的次数。
max_connect_errors=10
# 服务端使用的字符集默认为UTF8
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 默认使用“mysql_native_password”插件认证
#mysql_native_password
default_authentication_plugin=mysql_native_password
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[client]
# 设置mysql客户端连接服务端时默认使用的端口
port=3306
default-character-set=utf8
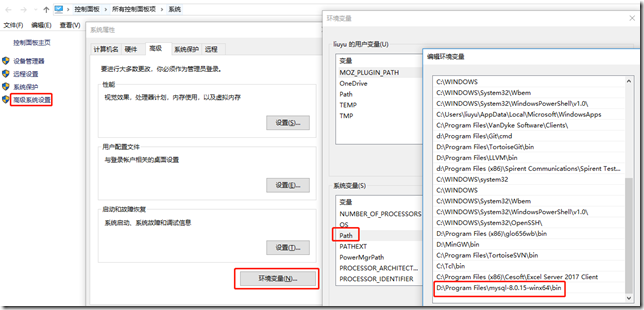
3)配置环境变量:
我的电脑右键-->属性-->高级系统设置-->环境变量-->修改PATH,将mysql路径添加进去,
例如:C:\Program Files\mysql-8.0.15-winx64\bin
4)安装
用管理员身份运行CMD:
mysqld --initialize --console
在MySQL的安装目录下执行命令,记录下生成的临时密码,例如:
lu?T,<0uKlz+

开始安装:
mysqld --install
服务名默认为mysql,如果需要修改名,可以执行 mysqld --install [服务名](建议别改了)
若提示The service already exists!
执行命令sc delete mysql,先删除该mysql
5)启动服务
服务安装成功之后通过命令启动MySQL的服务
net start mysql
若不成功,到mysql安装目录下
mysqld --remove
mysqld --install
net start mysql
注意事项:
1)如果前面安装时指定了别的服务吗,这里mysql也要替换成对应的值
2)重启后默认不会启动mysql,可以手动以管理员权限执行net start mysql启动,也可以修改服务启动,我平时不用,所以选择每次重启后手动执行命令启动。
6)修改密码
mysql -u root -p 使用临时密码登陆
接着这里修改密码为123456
ALTER user 'root'@'localhost' IDENTIFIED BY '123456';
7)查看版本,数据库路径
SELECT @@version,@@datadir
3 数据类型
3.1 数值类型
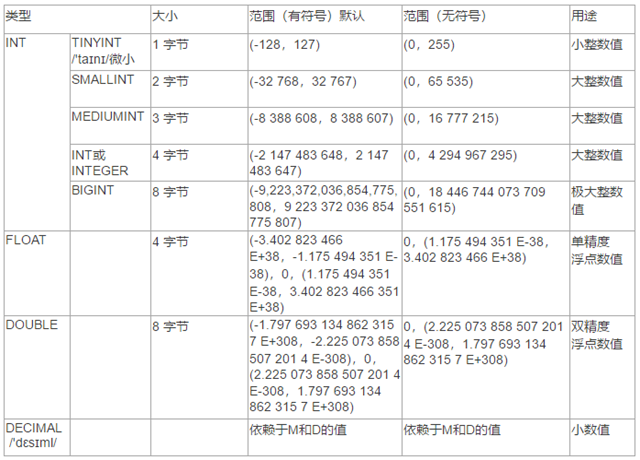
DECIMAL说明:
1)M 表示数据的最大总长度(不包括小数点,范围为1~65);D 表示:固定小数位(范围0~30,但不得超过M);
例:decimal(5,2)
可以存储123.45 ,存入数据的时候,按四舍五入计算。
2)在计算总长度时要优先考虑小数位,也就是D的约束
例:DECIMAL(5,3)
1.2345 --- 小数点后最多3位,自动四舍五入数据截断后保存,1.235
1.2 --- 小数未满部分补0。按照1.200保存。
123.45 --- 因为小数部分未满3位,要补0.所以保存应该123.450。所以整个位数超出了5,有问题。
3)D不能超过M值,若D等于M,如DECIMAL(5,5)
最大存储值为0.99999
4)适用场景
适合保存货币值,比如话费就可以用decimal来装的
int(xx)说明:
int(11)不是限制int的长度为11位,而是字符的显示宽度,例如插入数据1,显示为00000000001。
在字段类型为int时,无论你显示宽度设置为多少,int类型能存储的最大值和最小值永远都是固定的。
3.2 日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
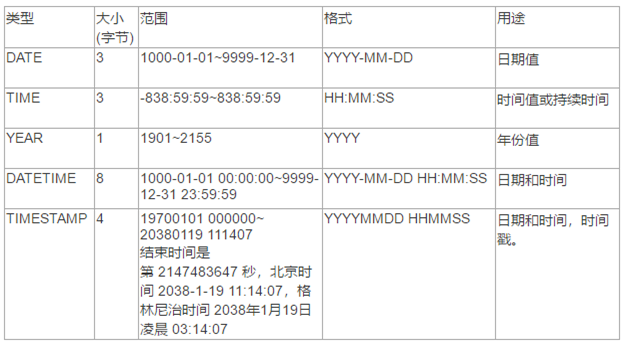
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
TIMESTAMP类型有专有的自动更新特性。
3.3 字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
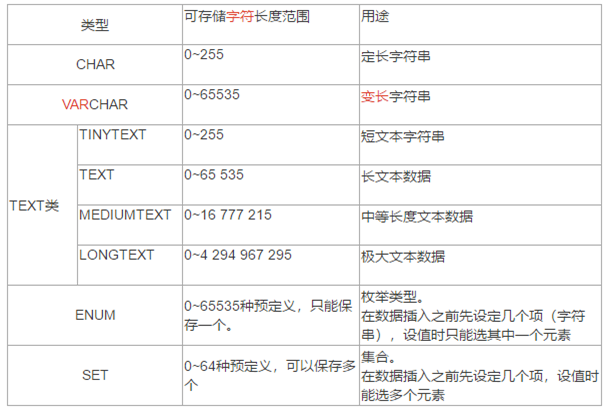
3.3.1 CHAR和VARCHAR比较
都需要指定长度,他们的区别在于:
1)存储方式不同:
- char 对英文(ASCII)字符占用1个字节,对一个汉字占用2个字节,varchar 对每个英文(ASCII)字符都占用2个字节,对一个汉字也只占用两个字节。但对于utf8,一个字符都会占用3个字节。
- char(n),如果实际使用字符不足n,会在后面用空格补全存入数据库中。varchar(n)则不会。
- 因为varchar要记录数据长度(系统根据数据长度自动分配空间),所以每个varchar数据产生后,系统都会在数据后面增加1-2个字节的额外开销:是用来保存数据所占用的空间长度,如果数据本身小于127个字符:额外开销一个字节;如果大于127个,就开销两个字节。例如对于utf8:

2)char效率高于varchar
因此当在长度固定的场景,例如:身份证号,手机号,电话等用char效率高,空间也不浪费
3.3.2 关于TEXT类的数据
1)text不设置长度, 当不知道属性的最大长度时,适合用text。
2)按照查询速度: char > varchar > text
3)需要额外的字节来存储长度:
Tinytext:系统使用一个字节来保存,实际能够存储的数据为:2 ^ 8 + 1
Text:使用两个字节保存,实际存储为:2 ^ 16 + 2
Mediumtext:使用三个字节保存,实际存储为:2 ^ 24 + 3
Longtext:使用四个字节保存,实际存储为:2 ^ 32 + 4
3.3.3 null与空字符串的不同
在MySQL里,null与空字符串 ' '是完全不同的:NULL是指没有值,而' '则表示值是存在的,只不过是个空值。判断NULL用is null 或者 is not null。
判断空字符串‘’,要用 ='' 或者 <>''。sql语句里可以用if(col,col,0)处理,即:当col为true时(非null,及非'')显示,否则打印0
3.4 二进制类型
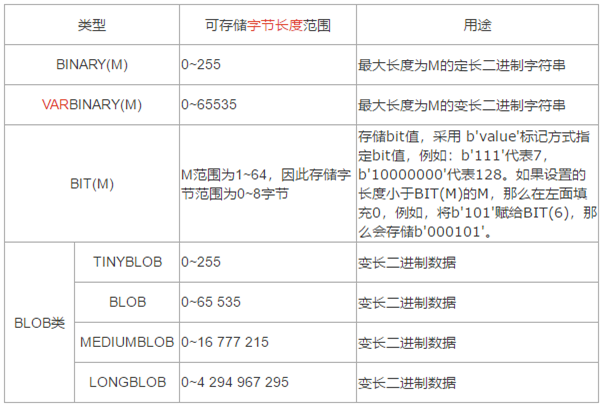
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们没有字符集,并且排序和比较基于列值字节的数值。
BLOB是可变数据类型,但是一般开发中,除非文件时机密型的,否正不存数据库。一般做法是把文件存储的路径存到数据库中,当要取文件时,去数据库中指定的路径中去找。
4 数据库的基本操作
注意sql语句不区分大小写,而且所有命令都需要以 ; 结尾
4.1 显示所有数据库
show databases;
4.2 创建数据库
create database 数据库命;
4.3 选择数据库
use 数据库命;
4.4 查看当前数据库
方法一:
select database()语句
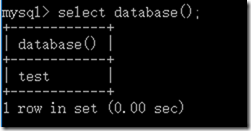
方法二:
show tables; #首行显示数据库名
方法三:
status;
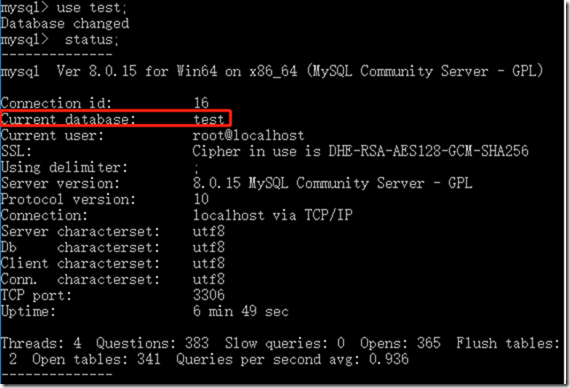
4.5 删除数据库
drop database 数据库名;
5 数据库表基本操作
注,本章及之后的章节里,[ ]表示为可选参数。
5.1 创建表
表是数据库存储数据的基本单位。一个表包含若干字段或记录;
创建表语法:
CREATE TABLE [if not exists] 表名(
属性名 数据类型 [完整性约束条件],
. .
属性名 数据类型 [完整性约束条件]
)[ENGINE=引擎名 AUTO_INCREMENT=自动累加起始值 CHARSET=编码格式;];
若表名已存在则会报错。若不想报错,可以使用 CREATE TABLE IF NOT EXISTS 表名 这种方式。这样会返回成功,但是有一个warning。若表名有特殊字符,例如带有空格,可以将使用 `表名 1` 这种方式。
根据已有表创建新表,包括数据和结构:
CREATE TABLE 新表名 as select * from 已有表名;
实例:
CREATE TABLE t_bookType(
id int primary key auto_increment,
bookTypeName varchar(20),
bookTypeDesc varchar(200)
); CREATE TABLE t_book(
id int primary key auto_increment,
bookName varchar(20),
author varchar(10),
price decimal(6,2),
bookTypeId int,
constraint `fk` foreign key (`bookTypeId`) references `t_bookType`(`id`)
); CREATE TABLE t_bookType5(
id1 INT AUTO_INCREMENT,
id2 INT,
val1 INT,
val2 INT,
PRIMARY KEY (id1,id2),
UNIQUE (val1,val2)
);
decimal /ˈdesɪml/ n. 小数
constraint /kənˈstreɪnt/ n. 限定;约束
5.1.1完整性约束条件
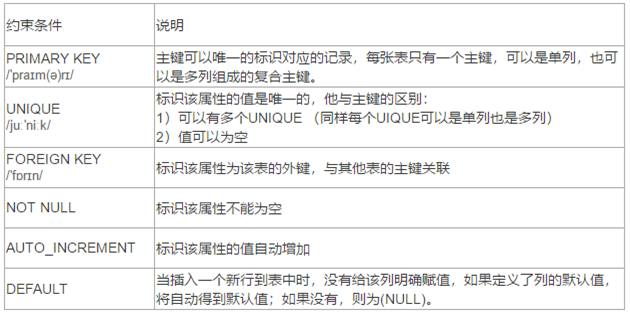
5.1.2 数据表的复合主键
所谓的复合主键 就是指表的主键含有一个以上的字段组成
比如
create table test (
name varchar(19),
id number,
value varchar(10),
primary key (name,id)
);
上面的name和id字段组合起来就是你test表的复合主键
它的出现是因为你的name字段可能会出现重名,所以要加上ID字段这样就可以保证你记录的唯一性
一般情况下,主键的字段长度和字段数目要越少越好
5.1.3 主键(PRIMARY KEY)与UNIQUE 对比
1)UNIQUE 约束唯一标识数据库表中的每条记录。它 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。
2)PRIMARY KEY 拥有自动定义的 UNIQUE 约束。
3)每张表可以有多个 UNIQUE,但是每个表只能有一个PRIMARY KEY。
4)UNIQUE 可为空,而PRIMARY KEY不能
5.1.4 主键与外键
1)主键是唯一标识一条记录,不能有重复的,不允许为空
2)外键可以有重复的, 可以是空值,用来和其他表建立联系用的。
用到外键一定是至少涉及到两张表。例如有两张表,部门表(主表,主键ID)、员工表(从表,外键Dept_id),因为员工表中的员工需要知道自己属于哪个部门,就可以通过外键Dept_id找到对应的部门,然后才能找到部门表里的各种字段信息,从而让二者相关联。外键一定是在“从表”中创建,并由“从表”负责维护二者之间的关系。
5.1.5 外键的使用条件
1)两个表必须是InnoDB表,MyISAM表暂时不支持外键
2) 外键列必须建立了索引,MySQL 4.1.2以后的版本在建立外键时会自动创建索引,但如果在较早的版本则需要显式建立;
3)外键关系的两个表的列必须是数据类相似,也就是可以相互转换类型的列,比如int和tinyint可以,而int和char则不可以
为什么说外键能保持数据的一致性、完整性?
在不设置外键的情况下(两表独立建立dept_id),员工表的dept_id字段和部门表的dept_id字段是没有关联的。只是你自己认为他们有关系而已,数据库并不认为它俩有关系。也就是说,你在员工表的dept_id字段插了一个值(比如1234),但是这个值在部门表中并没有,这个时候,数据库还是允许你插入的,它并不会对插入的数据做关系检查。然而在设置外键的情况下,你插入员工表的dept_id字段的值必须要求在部门表的dept_id字段能找到。 同时,如果你要删除部门表的某个dept_id字段,必须保证员工表中没有引用该字段值,否则就没法删除。这就是所谓的保持数据的一致性和完整性。
外键语法
[CONSTRAINT symbol] FOREIGN KEY [id] (index_col_name, ...)
REFERENCES tbl_name (index_col_name, ...)
[ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT}]
[ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT}]
该语法可以在 CREATE TABLE 和 ALTER TABLE 时使用,如果不指定CONSTRAINT symbol,MYSQL会自动生成一个名字。
ON DELETE、ON UPDATE表示事件触发限制,可设参数:
RESTRICT(限制外表中的外键改动)
CASCADE(跟随外键改动)
SET NULL(设空值)
SET DEFAULT(设默认值)
NO ACTION(无动作,默认的)
实例:
create table t_department(
id int primary key auto_increment,
name varchar(20),
author varchar(10),
price decimal(6,2),
booktypeid int,
constraint `fk` foreign key (`booktypeid`) references `t_booktype` (`id`)
);
注:fk为约束名,booktypeid为本表的外键名,t_booktype为主表名,主表后面跟的id为主表的主键名。
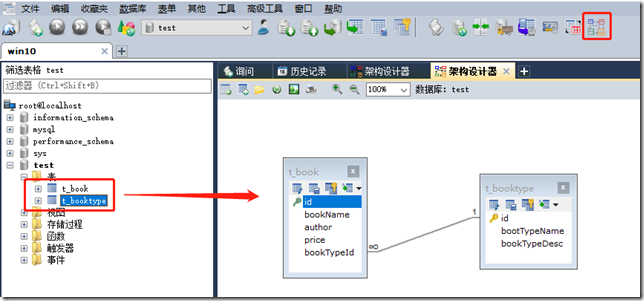
5.1.6 引擎与编码
ENGINE 设置存储引擎,DEFAULT CHARSET 设置编码。例如ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE 时有多种数据库存储引擎:
TYPE = {BDB | HEAP | ISAM | InnoDB | MERGE | MRG_MYISAM | MYISAM }
两种常用引擎MyISAM、InnoDB 大至区别如下:
1)高级处理:
MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。
2)执行速度:
MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快。
3)移值性:
MyISAM类型的二进制数据文件可以在不同操作系统中迁移。也就是可以直接从Windows系统拷贝到Linux系统中使用。
5.2 查看表结构
1)查看基本表结构:DESCRIBE(缩写DESC) 表名;
2)查看表详细结构: SHOW CREATE TABLE 表名; 这种方法可以看到建表的sql
实例:
desc t_bookType;
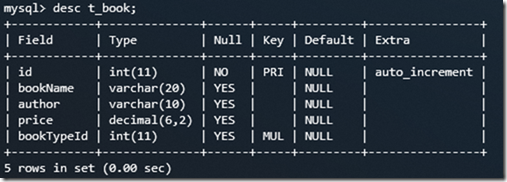
show create table t_bookType;
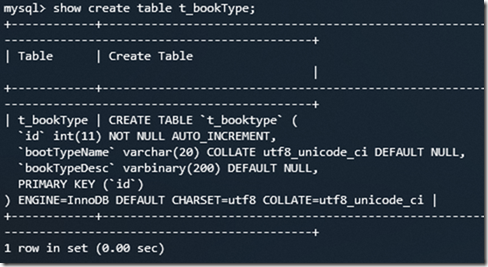
这里我们可以加上格式化输出信息 \G,将查到的结构旋转90度变成纵向,因为有的时候因为格式问题,或是太长导致显示错行
例:
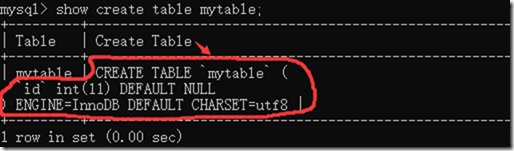
上面的查找的表的创建语句看着很别扭,那么可以使用\G
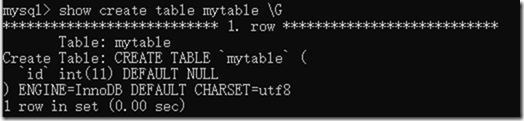
5.3 修改表
1)修改表名
ALTER TABLE 旧表名 RENMAE 新表名 ;
2)修改字段
ALTER TABLE 表名 CHANGE 旧属性名 新属性名 新数据类型
3)增加字段
ALTER TABLE 表名 ADD 属性名1 数据类型 [完整性约束条件] [FIRST | AFTER 属性名 2]
4)删除字段
ALTER TABLE 表名 DROP 属性名
实例:
alter table t_book rename t_book2;
alter table t_book change bookName bookName2 varchar(20);
alter table t_book add testField int first ;
alter table t_book drop testField;
注:
alter [ˈɔːltər] v.(使) 改变,更改
5.4 删除表
DROP TABLE 表名;
实例:
drop table t_book;
6 查询数据
准备:创建用于测试的数据表
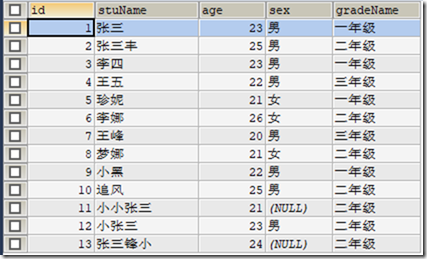
create table `t_student` (
`id` double ,
`stuName` varchar (60),
`age` double ,
`sex` varchar (30),
`gradeName` varchar (60)
);
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('1','张三','23','男','一年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('2','张三丰','25','男','二年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('3','李四','23','男','一年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('4','王五','22','男','三年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('5','珍妮','21','女','一年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('6','李娜','26','女','二年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('7','王峰','20','男','三年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('8','梦娜','21','女','二年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('9','小黑','22','男','一年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('10','追风','25','男','二年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('11','小小张三','21',NULL,'二年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('12','小张三','23','男','二年级');
insert into `t_student` (`id`, `stuName`, `age`, `sex`, `gradeName`) values('13','张三锋小','24',NULL,'二年级');
6.1 单表查询
6.1.1 查询所有字段
SELECT * FROM 表名;
6.1.2 查询指定字段
SELECT 字段1,字段2,字段3...FROM 表名;
SELECT stuName,id,age,sex,gradeName FROM t_student ;
6.1.3 Where 条件查询
SELECT 字段1,字段2,字段3...FROM 表名 WHERE 条件表达式;
SELECT * FROM t_student WHERE id=1;
SELECT * FROM t_student WHERE not id=1;
SELECT * FROM t_student WHERE age<20;
SELECT * FROM t_student WHERE age>22;
SELECT * FROM t_student WHERE not age>22;
6.1.4 为表格和字段取别名
表名 [AS] 表的别名
SELECT * FROM t_book WHERE id=1; SELECT * FROM t_book t WHERE t.id=1; SELECT t.bookName FROM t_book t WHERE t.id=1;
为字段取别名:字段 [AS] 字段的别名
SELECT t.bookName bName FROM t_book t WHERE t.id=1; SELECT t.bookName AS bName FROM t_book t WHERE t.id=1;
6.1.5 带 IN 关键字查询
SELECT 字段1,字段2,字段3...FROM 表名 WHERE 字段 [NOT] IN (元素1,元素2);
查找年龄在21或23的学生
SELECT * FROM t_student WHERE age IN (21,23);
查找年龄不在21或23的学生
SELECT * FROM t_student WHERE age NOT IN (21,23);
6.1.6 带 BETWEEN AND 的范围查询
SELECT 字段 1,字段 2,字段 3...FROM 表名 WHERE 字段 [NOT] BETWEEN 取值 1 AND 取值 2;
SELECT * FROM t_student WHERE age BETWEEN 21 AND 24;
SELECT * FROM t_student WHERE age NOT BETWEEN 21 AND 24;
6.1.7 带 LIKE 的模糊查询
SELECT 字段1,字段2,字段3...FROM 表名 WHERE 字段 [NOT] LIKE ‘字符串’;
注:
1)“%”代表任意字符且任意长度,“_” 代表任意单个字符
2)这里输入的是字符串,但是不要求被查的字段也是字符串,也可以查int类型的
SELECT * FROM t_student WHERE stuName LIKE '张三';
SELECT * FROM t_student WHERE stuName LIKE '张三%';
SELECT * FROM t_student WHERE stuName LIKE '张三_';
SELECT * FROM t_student WHERE stuName LIKE '张三__';
SELECT * FROM t_student WHERE stuName LIKE '_张三';
SELECT * FROM t_student WHERE stuName LIKE '__张三';
SELECT * FROM t_student WHERE stuName LIKE '%张三%';
SELECT * FROM t_student WHERE id LIKE '1%';
6.1.8 空值查询
SELECT 字段1,字段2,字段3...FROM 表名 WHERE 字段 IS [NOT] NULL;
SELECT * FROM t_student WHERE sex IS NULL;
SELECT * FROM t_student WHERE sex IS NOT NULL;
6.1.9 带 AND 的多条件查询
SELECT 字段1,字段2...FROM 表名 WHERE 条件表达式1 AND 条件表达式2 [...AND 条件表达式n]
SELECT * FROM t_student WHERE gradeName='一年级' AND age=23
6.1.10 带 OR 的多条件查询
SELECT 字段 1,字段 2...FROM 表名 WHERE 条件表达式 1 OR 条件表达式 2 [...OR 条件表达式 n]
SELECT * FROM t_student WHERE gradeName='一年级' OR age=23
6.1.11 DISTINCT 去重复查询
[dɪ'stɪŋkt] 独特的
SELECT DISTINCT 字段名 FROM 表名;
SELECT DISTINCT gradeName FROM t_student;
6.1.12 对查询结果排序
SELECT 字段 1,字段 2...FROM 表名 ORDER BY (属性名|列号如1,2,3,4) [ASC|DESC]
注:ASC升序(默认),DESC降序
SELECT * FROM t_student ORDER BY age ASC;
SELECT * FROM t_student ORDER BY age DESC;
SELECT * FROM t_student GROUP BY gradeName;
6.1.13 GROUP BY 分组查询
GROUP BY 属性名 [HAVING 条件表达式][WITH ROLLUP]
在有group by的查询语句中,select指定的字段要么就包含在group by语句的后面,作为分组的依据,要么就包含在聚合函数中。
1)与 GROUP_CONCAT()函数一起使用
GROUP_CONCAT将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
例:将所有学生按年级分组
SELECT gradeName,GROUP_CONCAT(stuName) FROM t_student GROUP BY gradeName;

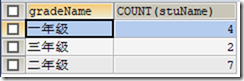
2)与COUNT函数一起使用
例:查询各年级的学生人数
SELECT gradeName,COUNT(stuName) FROM t_student GROUP BY gradeName;
3)与 HAVING 一起使用(限制输出的结果)
HAVING 子句可以让我们筛选分组后的各组数据。它的用法与where类似,但是在GROUP BY后只能用HAVING不能用WHERE。
例:
SELECT gradeName,COUNT(stuName) FROM t_student GROUP BY gradeName HAVING COUNT(stuName)>3;
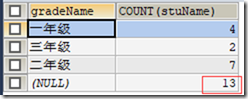
4)与 WITH ROLLUP 一起使用(最后加入一个总和行);
SELECT gradeName,COUNT(stuName) FROM t_student GROUP BY gradeName WITH ROLLUP;
SELECT gradeName,GROUP_CONCAT(stuName) FROM t_student GROUP BY gradeName WITH ROLLUP;

6.1.14 LIMIT 分页查询
SELECT 字段 1,字段 2...FROM 表名 LIMIT [初始位置,]记录数;
注,这里初始位置从0开始。
SELECT * FROM t_student LIMIT 0,5;
SELECT * FROM t_student LIMIT 5,5;
SELECT * FROM t_student LIMIT 10,5;
SELECT 字段 1,字段 2...FROM 表名 LIMIT 记录数 OFFSET 偏移;
查询第二条记录:
SELECT * FROM t_student LIMIT 1 OFFSET 1;
6.2 使用聚合函数查询
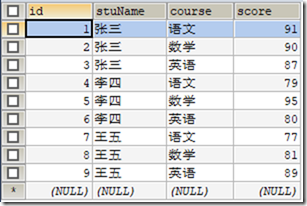
本小节使用到的表数据
create table `t_grade` (
`id` int ,
`stuName` varchar (60),
`course` varchar (60),
`score` int
);
insert into `t_grade` (`id`, `stuName`, `course`, `score`) values('1','张三','语文','91');
insert into `t_grade` (`id`, `stuName`, `course`, `score`) values('2','张三','数学','90');
insert into `t_grade` (`id`, `stuName`, `course`, `score`) values('3','张三','英语','87');
insert into `t_grade` (`id`, `stuName`, `course`, `score`) values('4','李四','语文','79');
insert into `t_grade` (`id`, `stuName`, `course`, `score`) values('5','李四','数学','95');
insert into `t_grade` (`id`, `stuName`, `course`, `score`) values('6','李四','英语','80');
insert into `t_grade` (`id`, `stuName`, `course`, `score`) values('7','王五','语文','77');
insert into `t_grade` (`id`, `stuName`, `course`, `score`) values('8','王五','数学','81');
insert into `t_grade` (`id`, `stuName`, `course`, `score`) values('9','王五','英语','89');
6.2.1 COUNT()函数
1)COUNT()函数用来统计记录的条数;
统计表的记录个数
SELECT COUNT(*) FROM t_grade;
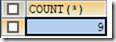
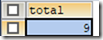
统计表的记录个数,并以别名total显示
SELECT COUNT(*) AS total FROM t_grade;
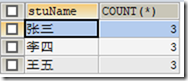
2)与 GOUPE BY 关键字一起使用
统计根据stuName分组后的统计值
SELECT stuName,COUNT(*) FROM t_grade GROUP BY stuName;
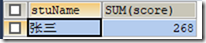
6.2.2 SUN()函数
1)SUM()函数是求和函数
统计张三的成绩
SELECT stuName,SUM(score) FROM t_grade WHERE stuName="张三";
2)与 GOUPE BY 关键字一起使用
统计各学生的总成绩
SELECT stuName,SUM(score) FROM t_grade GROUP BY stuName;
6.2.3 AVG()函数
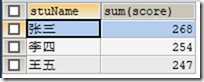
1)AVG()函数是求平均值的函数;
统计张三的平均成绩
SELECT stuName,AVG(score) FROM t_grade WHERE stuName="张三";
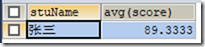
2)与 GOUPE BY 关键字一起使用;
统计各学生的平均成绩
SELECT stuName,AVG(score) FROM t_grade GROUP BY stuName;
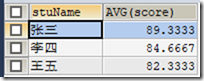
6.2.4 MAX()函数
1)MAX()函数是求最大值的函数;
统计张三的最高分
SELECT stuName,MAX(score) FROM t_grade WHERE stuName="张三";
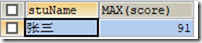
2)与 GOUPE BY 关键字一起使用;
统计各学生的最高分
SELECT stuName,MAX(score) FROM t_grade GROUP BY stuName;
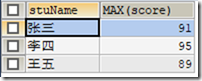
6.2.5 MIN()函数
1)MIN()函数是求最小值的函数;
统计张三各科成绩中的最低分
SELECT stuName,MIN(score) FROM t_grade WHERE stuName="张三";
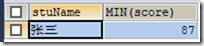
注:这里如果加上科目course会报错,因为MySQL5.7.5后,默认开启了ONLY_FULL_GROUP_BY,对于不确定输出的会报错。
查询:SELECT stuName,course,MIN(score) FROM t_grade WHERE stuName="张三";
错误代码: 1140
In aggregated query without GROUP BY, expression #2 of SELECT list contains nonaggregated column 'test.t_grade.course'; this is incompatible with sql_mode=only_full_group_by
我的理解是,通过张三stuName有多条记录但是内容一样,MIN(score)聚合后只出一条记录,所以这两个字段能输出,但是没有针对course进行处理,此时不知该输出何止,导致错误。
规避方案:
不确定返回字段可以使用ANY_VALUE(column_name),但这个值不一定是你想要的。
思考,那如何才能显示最低分及其科目呢?
2)与 GOUPE BY 关键字一起使用;
统计各学生的最低分
SELECT stuName,MIN(score) FROM t_grade GROUP BY stuName;
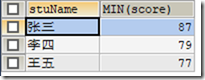
总结,使用了聚合函数,字段必须是唯一的才能一起输出,否则会报错。
6.3 连接查询
连接查询是将两个或两个以上的表按照某个条件连接起来,从中选取需要的数据。
本小节使用到的表数据
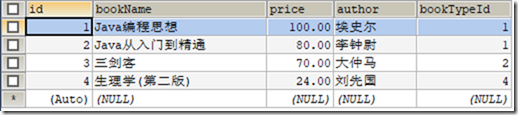
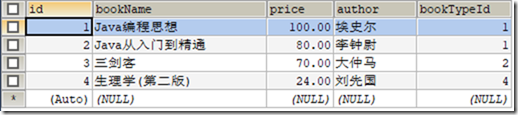
CREATE DATABASE `db_book`;
USE `db_book`; /*Table structure for table `t_book` */
DROP TABLE IF EXISTS `t_book`; CREATE TABLE `t_book` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`bookName` VARCHAR(20) DEFAULT NULL,
`price` DECIMAL(6,2) DEFAULT NULL,
`author` VARCHAR(20) DEFAULT NULL,
`bookTypeId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
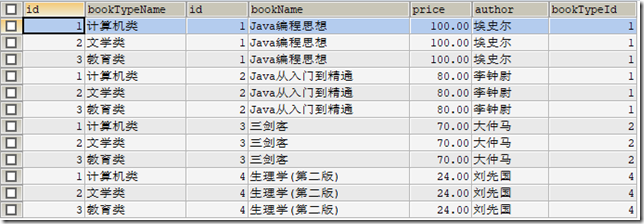
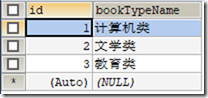
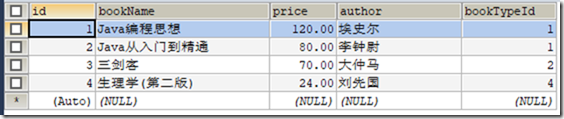
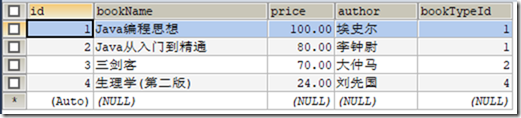
) ENGINE=INNODB CHARSET=utf8; /*Data for the table `t_book` */ INSERT INTO `t_book`(`id`,`bookName`,`price`,`author`,`bookTypeId`) VALUES (1,'Java编程思想','100.00','埃史尔',1),(2,'Java从入门到精通','80.00','李钟尉',1),(3,'三剑客','70.00','大仲马',2),(4,'生理学(第二版)','24.00','刘先国',4); /*Table structure for table `t_booktype` */ DROP TABLE IF EXISTS `t_booktype`; CREATE TABLE `t_booktype` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`bookTypeName` VARCHAR(20) DEFAULT NULL,
PRIMARY KEY (`id`)
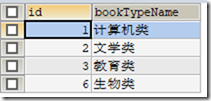
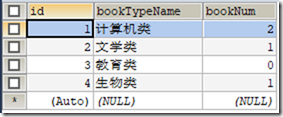
) ENGINE=INNODB CHARSET=utf8; /*Data for the table `t_booktype` */ INSERT INTO `t_booktype`(`id`,`bookTypeName`) VALUES (1,'计算机类'),(2,'文学类'),(3,'教育类');
表t_book
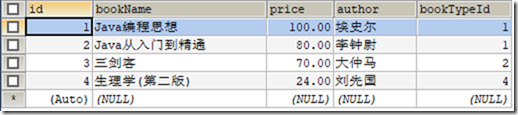
表t_booktype
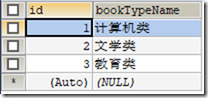
这里如果select两张表,查询的是所有可能的组合,这里有12条记录
SELECT * FROM t_booktype,t_book;
6.3.1 内连接与外连接的区别:
1)内连接查询:
查出来的数据可能不能覆盖所有数据(只查询到匹配的),比如查询表一
中bookId等于表二中的id的数据,但如果表一中某条数据的bookId在表二
中查不到,那么对应的这条数据就不显示。
2)外连接查询:
举例同上,在查不到的情况下,内连接的处理有可能导致两张表可能都不全,
但是外连接能够保证始终会显示其中一张表的所有信息,比如使用左连接查
询,表一的bookId没有在表二中查到,对应的表一数据仍显示,对应的表二
数据使用NULL代替。
6.3.2 内连接查询
需要查找多张表同时存在的数据时,使用内连接。
1)查询两张表bookTypeId相同的记录
SELECT * FROM t_book,t_bookType WHERE t_book.bookTypeId=t_bookType.id;

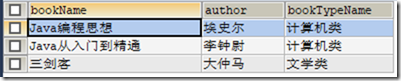
2)查询时过滤部分字段
下面的语句中如果添加id,就会报错。因为两张表都有ID不知该输出哪列,但如果t_bookType.id就可以。
SELECT bookName,author,bookTypeName FROM t_book,t_bookType WHERE t_book.bookTypeId=t_bookType.id;

t_book 取别名tb,select可以使用tb.bookName,若不用别名则使用t_book.bookName。取别名的时候as可以省略
SELECT tb.bookName,tb.author,tby.bookTypeName FROM t_book as tb,t_bookType as tby WHERE tb.bookTypeId=tby.id;
6.3.2 外连接查询
外连接可以查出某一张表的所有信息,其他表多没有的字段可以置NULL
SELECT 属性名列表 FROM 表名1 LEFT|RIGHT JOIN 表名2 ON 表名1.属性名1=表名2.属性名2;
6.3.2.1 左连接查询
LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
注释:在某些数据库中,LEFT JOIN 称为 LEFT OUTER JOIN。
SELECT * FROM t_book LEFT JOIN t_bookType ON t_book.bookTypeId=t_bookType.id;SELECT tb.bookName,tb.author,tby.bookTypeName FROM t_book tb LEFT JOIN t_bookType tby ON tb.bookTypeId=tby.id;

6.3.2.2 右连接查询
可以查询出“表名 2”的所有记录,而“表名 1”中,只能查询出匹配的记录;
SELECT * FROM t_book RIGHT JOIN t_bookType ON t_book.bookTypeId=t_bookType.id;SELECT tb.bookName,tb.author,tby.bookTypeName FROM t_book tb RIGHT JOIN t_bookType tby ON tb.bookTypeId=tby.id;
6.3.4 多条件连接查询
内连接的多条件查询,或外连接的多条件查询。通过and来指定多个条件。
SELECT tb.bookName,tb.author,tby.bookTypeName FROM t_book tb,t_bookType tby WHERE tb.bookTypeId=tby.id AND tb.price>70;

6.4 子查询
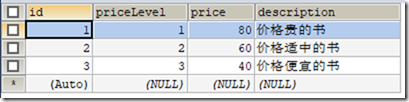
本小结用到了上节的t_book和t_bookType,新增一张表t_pricelevel
CREATE TABLE `t_pricelevel` (
`id` INT PRIMARY KEY AUTO_INCREMENT,
`priceLevel` INT ,
`price` FLOAT ,
`description` VARCHAR (300)
); INSERT INTO `t_pricelevel` (`id`, `priceLevel`, `price`, `description`) VALUES('1','1','80.00','价格贵的书');
INSERT INTO `t_pricelevel` (`id`, `priceLevel`, `price`, `description`) VALUES('2','2','60.00','价格适中的书');
INSERT INTO `t_pricelevel` (`id`, `priceLevel`, `price`, `description`) VALUES('3','3','40.00','价格便宜的书');
表t_pricelevel
表t_book
表t_booktype
6.4.1 带 In 关键字的子查询
一个查询语句的条件可能落在另一个 SELECT 语句的查询结果中。
SELECT * FROM t_book WHERE booktypeId IN (SELECT id FROM t_booktype);

SELECT * FROM t_book WHERE booktypeId NOT IN (SELECT id FROM t_booktype);

6.4.2 带比较运算符的子查询
子查询可以使用比较运算符,这里的子查询必须为可比较的值。
SELECT * FROM t_book WHERE price>=(SELECT price FROM t_pricelevel WHERE priceLevel=1);

6.4.3 带 Exists 关键字的子查询
假如子查询查询到记录,则进行外层查询,否则,不执行外层查询:
SELECT * FROM t_book WHERE EXISTS (SELECT * FROM t_booktype);
同理,也可以使用NOT EXISTS:
SELECT * FROM t_book WHERE NOT EXISTS (SELECT * FROM t_booktype);
6.4.4 带 Any 关键字的子查询
ANY 关键字表示满足子查询中任一条件
SELECT * FROM t_book WHERE price>= ANY (SELECT price FROM t_pricelevel);

6.4.5 带 All 关键字的子查询
ALL 关键字表示满足所有条件
SELECT * FROM t_book WHERE price>= ALL (SELECT price FROM t_pricelevel);

6.4.6 将select结果保存为临时的表,作为另一个select的数据源
例1:
SELECT *FROM (SELECT * FROM t_book ) AS test WHERE test.id=1;
这里必须给临时表去一个别名,否则报错。
例2:
SELECT (SELECT id FROM t_book LIMIT 100,100) AS newid
这句话的意思是将SELECT id FROM t_book LIMIT 100,100的结果保存为临时表并显示出来。
注,只能是返回最多一行一个字段的值,在有的数据库里如果里头的这个select数据limit超范围了,会报错,通过这样转一下能保证不出错,若超范围了返回空。
因为select null返回null。
6.5 合并查询结果
用于将多张表的查询结果合并
表t_book
表t_booktype
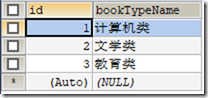
6.5.1 UNION
使用 UNION 关键字是,数据库系统会将所有的查询结果合并到一起,然后去除掉相同的记录
SELECT id FROM t_book UNION SELECT id FROM t_booktype;
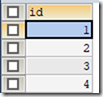
SELECT id,price FROM t_book UNION SELECT id,booktypename FROM t_booktype;
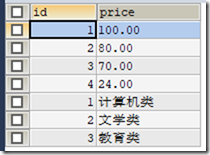
6.5.2 UNION ALL
使用 UNION ALL,不会去除掉相同的记录
SELECT id FROM t_book UNION ALL SELECT id FROM t_booktype;
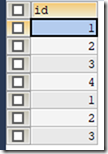
7 数据的更改
7.1 插入数据
1) 给表的所有字段插入数据
格式:INSERT INTO 表名 VALUES(值1,值2,值3,...,值n);
INSERT INTO t_book VALUES(NULL,'我爱我家',20,'张三',1);
2)给表的指定字段插入数据
格式:INSERT INTO 表名(属性1,属性2,...,属性n) VALUES(值1,值2,值3,...,值n);
INSERT INTO t_book(bookName,author) VALUES('我爱我家','张三');
3)同时插入多条记录
INSERT INTO 表名 [(属性列表)] VALUES(取值列表1),(取值列表2) ..., (取值列表 n);
INSERT INTO t_book(id,bookName,price,author,bookTypeId) VALUES (NULL,'我爱我家2',20,'张三',1),(NULL,'我爱我家3',20,'张三',1);
7.2 更新数据
UPDATE 表名 SET 属性名1=取值1,属性名2=取值2,...,属性名n=取值n WHERE 条件表达式;
UPDATE t_book SET bookName='Java编程思想',price=120 WHERE id=1;
UPDATE t_book SET bookName='我' WHERE bookName LIKE '%我爱我家%';
7.3 删除数据
DELETE FROM 表名 [WHERE 条件表达式]
DELETE FROM t_book WHERE id=5;
DELETE FROM t_book WHERE bookName='我';
8 索引
8.1 索引的引入
索引定义:索引是由数据库表中一列或者多列组合而成,其作用是提高对表中数据的查询速度;
类似于图书的目录,方便快速定位,寻找指定的内容;
8.2 索引的优缺点
优点:提高查询数据的速度。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
缺点:过多的使用索引将会造成滥用,虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。
索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
同时建立索引也会占用磁盘空间。
8.3 性能对比实例
110000条记录
SELECT * FROM t_book WHERE bookName = '测试图书书名1';
建立索引前测试查询时间,70毫秒。建立索引后,0毫秒。
在sqlyog中查看索引:
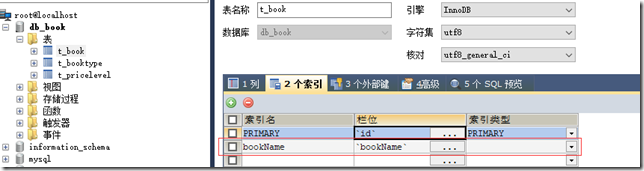
8.4 索引分类和创建
8.4.1 创建语法
1、创建表的时候创建索引
CREATE TABLE 表名 (属性名 数据类型 [完整性约束条件], 属性名 数据类型 [完整性约束条件], .... 属性名 数据类型 [UNIQUE | FULLTEXT | SPATIAL ] INDEX|KEY [别名] (属性名1 [(长度)] [ASC | DESC]) );
说明:
- UNIQUE | FULLTEXT | SPATIAL 为可选参数,分别表示唯一索引、全文索引、空间索引
- INDEX和KEY是同义词,可以替换使用
- 只有字符串类型的字段才能指定索引长度,其中如果是BLOB和TEXT类型,必须指定 length,如果是CHAR,VARCHAR类型,长度可以小于字段实际长度,也可以不指定长度。
- asc或desc指定升序或降序的索引值存储
2、在已经存在的表上创建索引
CREATE [ UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 ON 表名 (属性名 [(长度)] [ ASC | DESC]);
3、用 ALTER TABLE 语句来创建索引
ALTER TABLE 表名 ADD [ UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 (属性名 [(长度)] [ ASC | DESC]);
ALTER TABLE和CREATE INDEX的区别
- CREATE INDEX必须提供索引名,对于ALTER TABLE,如果你不提供将会自动创建;
- CREATE INDEX一个语句一次只能建立一个索引,ALTER TABLE可以在一个语句建立多个,如:
ALTER TABLE HeadOfState ADD PRIMARY KEY (ID), ADD INDEX (LastName,FirstName);
- 只有ALTER TABLE 才能创建主键,
英文原句如下:
With CREATE INDEX, we must provide a name for the index. With ALTER TABLE, MySQL creates an index name automatically if you don’t provide one.Unlike ALTER TABLE, the CREATE INDEX statement can create only a single index per statement. In addition, only ALTER TABLE supports the use of PRIMARY KEY.
8.4.2 索引的分类和举例
8.4.2.1 普通索引
这类索引可以创建在任何数据类型中,它没有任何限制
1)创建表的时候同时创建索引:
CREATE TABLE t_test1( id INT, userName TEXT(20), pwd VARCHAR(20), des VARCHAR(20), INDEX (userName(20)) );
2)CREATE方式创建索引
CREATE INDEX index_pwd ON t_test1(pwd);
3)ALTER方式创建索引
ALTER TABLE t_test1 ADD INDEX index_des (des);
8.4.2.2 唯一性索引
使用 UNIQUE 参数可以设置,与普通索引类似不同之处在于,索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
1)创建表的时候同时创建索引
CREATE TABLE t_test2( id INT, userName TEXT(20), pwd VARCHAR(20), des VARCHAR(20), UNIQUE INDEX (userName(20)) );
2)CREATE方式创建索引
CREATE UNIQUE INDEX index_pwd ON t_test2(pwd);
3)ALTER方式创建索引
ALTER TABLE t_test2 ADD UNIQUE INDEX index_des (des);
8.4.2.3 主键索引
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引:
CREATE TABLE t_test3( id INT, userName TEXT(20), pwd VARCHAR(20), des VARCHAR(20), PRIMARY KEY (`id`) );
8.4.2.4 全文索引
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。不过目前只有char、varchar,text 列上可以创建全文索引。值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多。只有 MyISAM 引擎支持该索引。
1)创建表的适合添加全文索引
CREATE TABLE t_test4( id INT, userName TEXT(20), pwd VARCHAR(20), des VARCHAR(20), FULLTEXT (userName) );
2)CREATE方式创建索引
CREATE FULLTEXT INDEX index_des ON t_test4(des);
3)ALTER方式创建索引
ALTER TABLE t_test4 ADD FULLTEXT index_pwd(pwd);
8.4.2.5 空间索引
5.7之后的版本支持了空间索引,而且支持OpenGIS几何数据模型。
使用 SPATIAL 参数可以设置空间索引。空间索引只能建立在空间数据类型上,这样可以提高系统获取空间数据的效率。
MyISAM 引擎支持该索引。
其他说明:
多列索引(组合索引)
指多个字段上创建的索引,当我们的where查询存在多个条件查询的时候,我们需要对查询的列创建组合索引。
最左匹配原则
假设我们创建(col1,col2,col3)这样的一个组合索引,那么相当于对col1列进行排序,也就是我们创建组合索引,以最左边的为准,只要查询条件中带有最左边的列,不管该列在查询条件中的位置,都会使用索引进行查询。
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);
8.4.3 索引的删除
1)drop命令删除
DROP INDEX 索引名 ON 表名;
2)ALTER命令删除索引
删除主键索引:
不需要指定主键名
ALTER TABLE 表名 DROP PRIMARY KEY;
其他索引:
ALTER TABLE 表名 DROP INDEX 索引名;
8.4.3 显示索引信息
SHOW INDEX FROM 表名;
例:
SHOW INDEX FROM t_test2;

9 视图view
9.1 视图的介绍
什么是试图?
- 视图是一种虚拟的表,是从数据库中一个或者多个表中导出来的表。
- 数据库中只存放了视图的定义,而并没有存放视图中的数据,这些数据存放在原来的表中。
- 使用视图查询数据时,数据库系统会从原来的表中取出对应的数据。
视图的作用?
作用一:使操作简便化
比如原本表里有20个字段,视图可以只取我们需要的几个字段,方便操作,例如我们要频繁获取user表中的name和group表中的gname。我们可以创建一个视图,包含这两个字段,使用一条select *语句就能获取想要的内容。
作用二:对数据库重构,却不影响程序的运行。
例1,A表创建了视图V1,之后A表添加了新的字段,但是我们对V1的操作不受影响,只要保证V1使用的字段还在就可以。
例2,假如因为某种需求,需要将user拆分成表usera和表userb,该两张表的结构如下:
测试表:usera有id,name,age字段
测试表:userb有id,name,sex字段
这时如果使用sql语句:select * from user;那就会提示该表不存在,这时我们就可以通过创建视图来解决。
作用三:提高了安全性能。
例1,可以对不同的用户,设定不同的视图。如某用户只能获取user表的name和age数据,不能获取sex数据。则可以创建视图。使用sql语句:select * 语句最多就只能获取name和age的数据,其他的数据就获取不了了。
例2,我们对视图进行操作,只会影响我们关系的几个字段,其他的字段比如某些重要字段不会因为误操作而受到影响。
9.2 视图的创建
CREATE [ ALGORITHM ={ UNDEFIEND | MERGE | TEMPTABLE }] VIEW 视图名 [ ( 属性清单) ] AS SELECT 语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ];
1)语法说明:
- ALGORITHM 是可选参数,表示视图选择的算法。
ALGORITHM 包括 3 个选项 UNDEFINED、MERGE 和 TEMPTABLE。其中,UNDEFINED 选项表示 MySQL 将自动选择所要使用的算法;MERGE 选项表示将使用视图的语句与视图定义合并起来,使得视图定义的某一部分取代语句的对应部分;TEMPTABLE 选项表示将视图的结果存入临时表,然后使用临时表执行语句。
- “视图名”参数表示要创建的视图的名称。
- “属性清单”是可选参数,其指定了视图中各种属性的名词,默认情况下与 SELECT 语句中查询的属性相同。
- SELECT 语句参数是一个完整的查询语句,标识从某个表查出某些满足条件的记录,将这些记录导入视图中。
- WITH CHECK OPTION 是可选参数,表似更新视图时要保证在该视图的权限范围之内。
- CASCADED可选参数,表示更新视图时要满足所有相关视图和表的条件,该参数为默认值。LOCAL 表示更新视图时,要满足该视图本身的定义条件即可。
注:我们可以在已有视图上再创建视图
接下来的例子,会使用我们之前创建的t_book和t_bookType作为演示
2)在单表上创建视图
CREATE VIEW v2 AS SELECT bookName,price FROM t_book; SELECT * FROM v2;
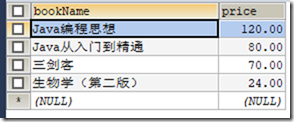
创建视图后对字段取别名
CREATE VIEW v3(b,p) AS SELECT bookName,price FROM t_book; SELECT * FROM v3;
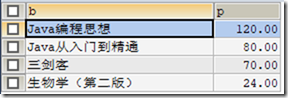
3)在多表上创建视图
CREATE VIEW v4 AS SELECT bookName,bookTypeName FROM t_book,t_booktype WHERE t_book.bookTypeId=t_booktype.id; SELECT * FROM v4;
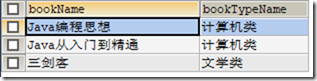
创建时使用别名
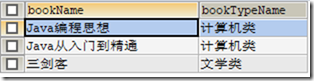
CREATE VIEW v5 AS SELECT tb.bookName,tby.bookTypeName FROM t_book tb,t_booktype tby WHERE tb.bookTypeId=tby.id; SELECT * FROM v5;
9.3 查看视图
1)DESCRIBE 语句查看
DESCRIBE v5;

2)SHOW TABLE STATUS 语句查看
SHOW TABLE STATUS LIKE 'v5';

3)SHOW CREATE VIEW 语句查看详细信息
SHOW CREATE VIEW v5;

注:这里我使用SHOW CREATE TABLE v5;得到的结果一样。
4)在 views 表中查看视图详细信息
information_schema库-->views表
USE information_schema; SELECT *FROM views;

9.4 修改视图
使用v1视图为例

1)CREATE OR REPLACE 创建或替换已有视图
CREATE OR REPLACE [ ALGORITHM ={ UNDEFINED | MERGE | TEMPTABLE }] VIEW 视图名 [( 属性清单 )] AS SELECT 语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ];
例:
CREATE OR REPLACE VIEW v1 (bookName,price) AS SELECT bookName,price FROM t_book;
SELECT * FROM v1;
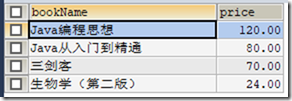
2) ALTER 语句修改视图
ALTER [ ALGORITHM ={ UNDEFINED | MERGE | TEMPTABLE }] VIEW 视图名 [( 属性清单 )] AS SELECT 语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ];

9.5 更新视图
更新视图是指通过视图来插入(INSERT)、更新(UPDATE)和删除(DELETE)表中的数据。因为视图是一个虚拟的表,其中没有数据。通过视图更新时,都是转换基本表来更新。更新视图时,只能更新权限范围内的数据。超出了范围,就不能更新。
以下操作同对表的操作,语法同对表操作一样
1) 插入(INSERT)
INSERT INTO v1 VALUE(NULL,'java test', 120, 'test2', 1);
2) 更新(UPDATE)
UPDATE v1 SET bookName='Java hello',price=122 WHERE id=5;
3) 删除(DELETE)
DELETE FROM v1 WHERE id=5;
9.6 删除视图
删除视图是指删除数据库中已存在的视图。删除视图时只会删除视图的定义,不会删除数据。
DROP VIEW [ IF EXISTS ] 视图名列表 [ RESTRICT | CASCADE ]
10 触发器
10.1 触发器的介绍
触发器(TRIGGER)是由事件来触发某个操作。这些事件包括 INSERT 语句、UPDATE 语句和 DELETE 语句。
当数据库系统执行这些事件时,就会激活触发器执行相应的操作。
例如:你在一张表插入了一条数据,业务上要求在另一张表也需要插入,这时候就可以使用触发器
t_book表
t_bookType表
10.2 创建与使用触发器
1)创建只有一个执行语句的触发器
CREATE TRIGGER 触发器名 BEFORE | AFTER 触发事件 ON 表名 FOR EACH ROW 执行语句
触发事件: INSERT、UPDATE 、 DELETE
实例:
在t_book插入一条数据后,t_bookType里的bookNum相应记录累加
CREATE TRIGGER trig_book AFTER INSERT ON t_book FOR EACH ROW
UPDATE t_bookType SET bookNum=bookNum+1 WHERE new.bookTypeId=t_bookType.id; INSERT INTO t_book VALUE(NULL, 'java新书', 100, 'aaa', 1);
SELECT * FROM t_bookType;
这里涉及到两个过渡变量:new和old,指代新插入的或即将删除的那条记录。
对于INSERT语句,只有NEW是合法的;对于DELETE语句,只有OLD才合法;而UPDATE语句可以在NEW及OLD同时使用。
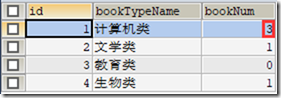
说明:
for each row代表行级触发器,任意一行受影响都会触发的,叫行级触发器。
在oracle 触发器中,分“行级触发器”和“语句级触发器”,“语句级触发器”可不写for each row,无论影响多少行都只执行一次。
mysql不支持语句触发器,所以必须写for each row。
2)创建有多个执行语句的触发器
CREATE TRIGGER 触发器名 BEFORE | AFTER 触发事件 ON 表名 FOR EACH ROW
BEGIN
执行语句1;
...
执行语句N;
END
注:mysql语句执行是以封号做判断,这个多行触发器里带有多条语句,因此需要使用DELIMTTER重新定义结束符为 |(也可以是别的)。
例如下面这个例子中,当从t_book中删除一条语句,会触发三条语句:
DELIMITER |
CREATE TRIGGER trig_book2 AFTER DELETE
ON t_book FOR EACH ROW
BEGIN
UPDATE t_bookType SET bookNum=bookNum-1 WHERE old.bookTypeId=t_booktype.id;
INSERT INTO t_log VALUES(NULL,NOW(),'在book表里删除了一条数据');
DELETE FROM t_test WHERE old.bookTypeId=t_test.id;
END
|
DELIMITER ;
10.3 查看触发器
10.3.1 SHOW TRIGGERS

10.3.2 在 triggers 表中查看
USE information_schema; SELECT * FROM TRIGGERS;

10.4 删除触发器
DROP TRIGGER 触发器名;
11 常用函数
11.1 日期和时间函数
1)CURDATE() 返回当前日期
2)CURTIME() 返回当前时间
3)MONTH(d) 返回日期 d 中的月份值,范围是 1~12
11.2 字符串函数
1)CHAR_LENGTH(s) 计算字符串 s 的字符数;
2)UPPER(s) 把所有字母变成大写字母;
3)LOWER(s) 把所有字母变成小写字母
11.3 数学函数
1)ABS(x) 求绝对值
2)SQRT(x) 求平方根
3)MOD(x,y) 求余
11.4 加密函数
1)PASSWORD(str) 一般对用户的密码加密 不可逆
2)MD5(str) 普通加密 不可逆
3)ENCODE(str,pswd_str) 加密函数,结果是一个二进制数,必须使用 BLOB 类型的字段来保存它;
4)DECODE(crypt_str,pswd_str) 解密函数;
11.5 判断函数
1)if(条件判断,值1,值2)
如果条件判断是true,就等于值1,false就等于值2,有点像三元表达式
例,把salary表中的女改成男,男改成女:
update salary set sex = if( sex = '男','女','男');
2)ifnull(值1, 值2)
ifnull里有两个数,如果值1不是null则取值1,否则取值2
例:
SELECT IFNULL(NULL,"11"); 结果:11
SELECT IFNULL("00","11"); 结果:00
SELECT IFNULL(NULL,NULL); 结果:NULL
12 存储过程和函数
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
优点
- 存储过程可封装,并隐藏复杂的商业逻辑。
- 存储过程可以回传值,并可以接受参数。
- 存储过程无法使用 SELECT 指令来运行,因为它是子程序,与查看表,数据表或用户定义函数不同。
- 存储过程可以用在数据检验,强制实行商业逻辑等。
缺点
- 存储过程,往往定制化于特定的数据库上,因为支持的编程语言不同。当切换到其他厂商的数据库系统时,需要重写原有的存储过程。
- 存储过程的性能调校与撰写,受限于各种数据库系统。
12.1 创建存储过程,函数
CREATE
[DEFINER = user]
PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body CREATE
[DEFINER = user]
FUNCTION sp_name ([func_parameter[,...]])
RETURNS type
[characteristic ...] routine_body proc_parameter:
[ IN | OUT | INOUT ] param_name type func_parameter:
param_name type type:
Any valid MySQL data type characteristic:
COMMENT 'string'
| LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER } routine_body(存储过程体):
[begin_label:] BEGIN
[statement_list]
……
END [end_label]
例:
创建存储过程,根据ID删除t_book表中数据
DELIMITER $$
CREATE PROCEDURE del_matches(IN bid INTEGER)
BEGIN
DELETE FROM t_book WHERE id = bid;
END $$
DELIMITER;
调用存储过程:
call 存储过程名[(传参)];
例:
SELECT * FROM t_book;

CALL del_matches(5);
SELECT * FROM t_book;

调用函数:
select call 函数名[(传参)];
12.2 存储过程的参数
PROCEDURE 共有三种参数类型:
- IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
- OUT 输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
- INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
FUNCTION参数总是被认为是IN参数。
1)in 输入参数
输入参数(局部变量)在存储过程中被修改,但并不影响全局变量中同名的变量值,例:
mysql> delimiter $$
mysql> create procedure in_param(in p_in int)
-> begin
-> select p_in;
-> set p_in=2;
-> select P_in;
-> end$$
mysql> delimiter ; mysql> set @p_in=1; mysql> call in_param(@p_in);
+------+
| p_in |
+------+
| 1 |
+------+ +------+
| P_in |
+------+
| 2 |
+------+ mysql> select @p_in;
+---------+
| @p_in |
+---------+
| 1 |
+---------+
2)out输出参数
在存储过程中修改out参数的值,存储过程外的变量值也被修改。
mysql> delimiter //
mysql> create procedure out_param(out p_out int)
-> begin
-> select p_out;
-> set p_out=2;
-> select p_out;
-> end
-> //
mysql> delimiter ; mysql> set @p_out=1;
mysql> call out_param(@p_out);
+---------+
| p_out |
+---------+
| NULL |
+---------+
#因为out是向调用者输出参数,不接收输入的参数,所以存储过程里的p_out为null
+---------+
| p_out |
+---------+
| 2 |
+---------+ mysql> select @p_out;
+-----------+
| @p_out |
+-----------+
| 2 |
+-----------+
#调用了out_param存储过程,输出参数,改变了p_out变量的值
3)inout输入参数
mysql> delimiter $$
mysql> create procedure inout_param(inout p_inout int)
-> begin
-> select p_inout;
-> set p_inout=2;
-> select p_inout;
-> end
-> $$
mysql> delimiter ; mysql> set @p_inout=1;
mysql> call inout_param(@p_inout);
+----------+
| p_inout |
+----------+
| |
+----------+ +----------+
| p_inout |
+----------+
| 2 |
+----------+ mysql> select @p_inout;
+-------------+
| @p_inout |
+-------------+
| 2 |
+-------------+
#调用了inout_param存储过程,接受了输入的参数,也输出参数,改变了变量
注意:
1、如果过程没有参数,也必须在过程名后面写上小括号例
2、确保参数的名字不等于列的名字,否则在过程体中,参数名被当做列名来处理
建议:inout参数就尽量的少用。
12.2 变量
1)变量定义
局部变量声明一定要放在存储过程体的开始:
DECLARE variable_name [,variable_name...] datatype [DEFAULT value];
其中,datatype 为 MySQL 的数据类型,如: int, float, date,varchar(length)
例如:
DECLARE l_int int unsigned default 4000000;DECLARE l_numeric number(8,2) DEFAULT 9.95;DECLARE l_date date DEFAULT '1999-12-31';DECLARE l_datetime datetime DEFAULT '1999-12-31 23:59:59';DECLARE l_varchar varchar(255) DEFAULT 'This will not be padded';
2)变量赋值
SET 变量名 = 表达式值 [,variable_name = expression ...]
3) 用户变量
在MySQL客户端使用用户变量:
mysql > SELECT 'Hello World' into @x;
mysql > SELECT @x;
+---------------+
| @x |
+---------------+
| Hello World |
+---------------+
mysql > SET @y='Goodbye Cruel World';
mysql > SELECT @y;
+---------------------+
| @y |
+---------------------+
| Goodbye Cruel World |
+---------------------+
mysql > SET @z=1+2+3;
mysql > SELECT @z;
+------+
| @z |
+------+
| 6 |
+------+
在存储过程中使用用户变量
mysql > CREATE PROCEDURE GreetWorld() SELECT CONCAT(@greeting,' World');
mysql > SET @greeting='Hello';
mysql > CALL GreetWorld( );
+----------------------------+
| CONCAT(@greeting,' World') |
+----------------------------+
| Hello World |
+----------------------------+
在存储过程间传递全局范围的用户变量
mysql> CREATE PROCEDURE p1() SET @last_procedure='p1';
mysql> CREATE PROCEDURE p2() SELECT CONCAT('Last procedure was ',@last_procedure);
mysql> CALL p1( );
mysql> CALL p2( );
+-----------------------------------------------+
| CONCAT('Last procedure was ',@last_proc |
+-----------------------------------------------+
| Last procedure was p1 |
+-----------------------------------------------+
注:
- 用户变量名一般以@开头
- 滥用用户变量会导致程序难以理解及管理
12.3 MySQL存储过程的查询
我们可以用以下语句进行查询:
select name from mysql.proc where db='数据库名';
select routine_name from information_schema.routines where routine_schema='数据库名';
show procedure status where db='数据库名';
查看存储过程的详细信息:
SHOW CREATE PROCEDURE 数据库.存储过程名;
12.3 存储过程的修改
ALTER PROCEDURE 存储过程名 [ 特征 ... ];
该语句用于修改存储过程的某些特征,如执行权限等。
12.4 存储过程的删除
DROP {PROCEDURE|FUNCTION} [if exists] 名称;
注:如果存储过程或存储函数不存在时,仍然进行删除,可以使用IF EXISTS子句,它可以防止发生错误。
12.5 MySQL存储过程的控制语句
1)条件语句
if 语句
mysql > DELIMITER //
mysql > CREATE PROCEDURE proc2(IN parameter int)
-> begin
-> declare var int;
-> set var=parameter+1;
-> if var=0 then
-> insert into t values(17);
-> end if;
-> if parameter=0 then
-> update t set s1=s1+1;
-> else
-> update t set s1=s1+2;
-> end if;
-> end;
-> //
mysql > DELIMITER ;
case 语句:
mysql > DELIMITER //
mysql > CREATE PROCEDURE proc3 (in parameter int)
-> begin
-> declare var int;
-> set var=parameter+1;
-> case var
-> when 0 then
-> insert into t values(17);
-> when 1 then
-> insert into t values(18);
-> else
-> insert into t values(19);
-> end case;
-> end;
-> //
mysql > DELIMITER ;
case
when var=0 then
insert into t values(30);
when var>0 then
when var<0 then
else
end case
3)循环语句
while 条件 do 循环体 end while
mysql > DELIMITER //
mysql > CREATE PROCEDURE proc4()
-> begin
-> declare var int;
-> set var=0;
-> while var<6 do
-> insert into t values(var);
-> set var=var+1;
-> end while;
-> end;
-> //
mysql > DELIMITER ;
repeat 循环体 until 循环条件 end repeat
它在执行操作后检查结果,而 while 则是执行前进行检查。
mysql > DELIMITER //
mysql > CREATE PROCEDURE proc5 ()
-> begin
-> declare v int;
-> set v=0;
-> repeat
-> insert into t values(v);
-> set v=v+1;
-> until v>=5
-> end repeat;
-> end;
-> //
mysql > DELIMITER ;
4)LABLES 标号
标号可以用在 begin repeat while 或者 loop 语句前,语句标号只能在合法的语句前面使用。可以跳出循环,使运行指令达到复合语句的最后一步。
ITERATE迭代
ITERATE 通过引用复合语句的标号,来从新开始复合语句:
mysql > DELIMITER //
mysql > CREATE PROCEDURE proc10 ()
-> begin
-> declare v int;
-> set v=0;
-> LOOP_LABLE:loop
-> if v=3 then
-> set v=v+1;
-> ITERATE LOOP_LABLE;
-> end if;
-> insert into t values(v);
-> set v=v+1;
-> if v>=5 then
-> leave LOOP_LABLE;
-> end if;
-> end loop;
-> end;
-> //
mysql > DELIMITER ;
13 事务
事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你既需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
- 在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
- 事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
- 事务用来管理 insert,update,delete 语句
一般来说,事务是必须满足4个条件(ACID):原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
- 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- 隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作。因此要显式地开启一个事务务须使用命令 BEGIN 或 START TRANSACTION,或者执行命令 SET AUTOCOMMIT=0,用来禁止使用当前会话的自动提交。
事务控制语句:
- BEGIN 或 START TRANSACTION 显式地开启一个事务;
- COMMIT (COMMIT WORK)。COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的;
- ROLLBACK ( ROLLBACK WORK),不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
- SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT;
- RELEASE SAVEPOINT identifier 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
- ROLLBACK TO identifier 把事务回滚到标记点;
- SET TRANSACTION 用来设置事务的隔离级别。InnoDB 存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE。
MYSQL 事务处理主要有两种方法:
1)用 BEGIN, ROLLBACK, COMMIT来实现
- BEGIN 开始一个事务
- ROLLBACK 事务回滚
- COMMIT 事务确认
2)直接用 SET 来改变 MySQL 的自动提交模式:
- SET AUTOCOMMIT=0 禁止自动提交
- SET AUTOCOMMIT=1 开启自动提交
例:
CREATE TABLE test(
id INT(5)
) ENGINE=INNODB;
SELECT * FROM test;#查询为空
begin; # 开始事务
insert into test value(5);
insert into test value(6);
commit;
select * from test;#查询到两数据 begin; # 开始事务
insert into test values(7);
rollback; #回滚
select * from test; # 因为回滚所以数据没有插入
14 数据备份与还原
14.1 数据备份
备份数据可以保证数据库中数据的安全,数据库管理员需要定期的进行数据库备份;
使用 mysqldump 命令备份
mysqldump -u username -p dbname [table1 table2 ...] > BackupName.sql
dbname 参数表示数据库的名称;table1 和 table2 参数表示表的名称,没有该参数时将备份整个数据库;
BackupName.sql 参数表示备份文件的名称,文件名前面可以加上路径。通常以 sql 作为后缀。
14.2 数据还原
Mysql -u root -p [dbname] < backup.sql
dbname 参数表示数据库名称。该参数是可选参数,可以指定数据库名,也可以不指定。指定数据库名时,表
示还原该数据库下的表。不指定数据库名时,表示还原特定的一个数据库。而备份文件中有创建数据库的语句。
Mysql快速入门(看完这篇能够满足80%的日常开发)的更多相关文章
- 关于 Docker 镜像的操作,看完这篇就够啦 !(下)
紧接着上篇<关于 Docker 镜像的操作,看完这篇就够啦 !(上)>,奉上下篇 !!! 镜像作为 Docker 三大核心概念中最重要的一个关键词,它有很多操作,是您想学习容器技术不得不掌 ...
- MySql基础笔记(一)Mysql快速入门
Mysql快速入门 一)基本概念 1)表 行被称为记录,是组织数据的单位.列被称为字段,每一列表示记录的一个属性. 2)主键 主键用于唯一的标识表中的每一条记录.可以定义表中的一列或者多列为主键, 但 ...
- 看完这篇还不会 GestureDetector 手势检测,我跪搓衣板!
引言 在 android 开发过程中,我们经常需要对一些手势,如:单击.双击.长按.滑动.缩放等,进行监测.这时也就引出了手势监测的概念,所谓的手势监测,说白了就是对于 GestureDetector ...
- MySQL快速入门(二)
目录 MySQL快速入门(二) 约束条件 自增 自增的特性 主键 外键 级联更新/删除 表与表之间的关系 外键约束 操作表方法 查询关键字 练习数据 select··from where 筛选 gro ...
- APP的缓存文件到底应该存在哪?看完这篇文章你应该就自己清楚了
APP的缓存文件到底应该存在哪?看完这篇文章你应该就自己清楚了 彻底理解android中的内部存储与外部存储 存储在内部还是外部 所有的Android设备均有两个文件存储区域:"intern ...
- 【最短路径Floyd算法详解推导过程】看完这篇,你还能不懂Floyd算法?还不会?
简介 Floyd-Warshall算法(Floyd-Warshall algorithm),是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似.该算法名称以 ...
- [转帖]看完这篇文章你还敢说你懂JVM吗?
看完这篇文章你还敢说你懂JVM吗? 在一些物理内存为8g的服务器上,主要运行一个Java服务,系统内存分配如下:Java服务的JVM堆大小设置为6g,一个监控进程占用大约 600m,Linux自身使用 ...
- Java快速入门-03-小知识汇总篇(全)
Java快速入门-03-小知识汇总篇(全) 前两篇介绍了JAVA入门的一系小知识,本篇介绍一些比较偏的,说不定什么时候会用到,有用记得 Mark 一下 快键键 常用快捷键(熟记) 快捷键 快捷键作用 ...
- MySQL 快速入门教程
转:MySQL快速 入门教程 目录 一.MySQL的相关概念介绍 二.Windows下MySQL的配置 配置步骤 MySQL服务的启动.停止与卸载 三.MySQL脚本的基本组成 四.MySQL中的数据 ...
随机推荐
- Configure Visual Studio with UNIX end of lines
As OP states "File > Advanced Save Options", select Unix Line Endings. https://stackove ...
- [Inno Setup] 如何读取命令行输入的参数
以 /verysilent 为例 [Code] var isVerySilent: Boolean; function InitializeSetup(): Boolean; var j: Integ ...
- opencv-7-鼠标绘制自定义图形
opencv-7-鼠标绘制自定义图形 opencvc++qt 开始之前 昨天写了具体的基本的图形绘制, 然后我们使用相应的函数接口进行调用, 便能够在图像上绘制出来相应的图形, 我们以图像绘制为例, ...
- Scala的Higher-Kinded类型
Scala的Higher-Kinded类型 Higher-Kinded从字面意思上看是更高级的分类,也就是更高一级的抽象.我们先看个例子. 如果我们要在scala中实现一个对Seq[Int]的sum方 ...
- Libra白皮书解读
文章目录 Libra简介 Libra区块链 Libra货币和存储 Libra协会 Libra简介 Libra是facebook发起的一个区块链项目,其使命是建立一套简单的.无国界的货币和为数十亿人服务 ...
- C# 基础知识系列- 14 IO篇 文件的操作
0. 前言 本章节是IO篇的第二集,我们在上一篇中介绍了C#中IO的基本概念和一些基本方法,接下来我们介绍一下操作文件的方法.在编程的世界中,操作文件是一个很重要的技能. 1. 文件.目录和路径 在开 ...
- 徐州I
#include<bits/stdc++.h> using namespace std; #define rep(i,a,b) for(int i=a;i<=b;++i) #defi ...
- python(数据类型)
一.基本数据类型 (1)numbers 数字 整型 int a = 1 print (type(a)) 长整型 long python3.x 中无此类型 >>> 2 ** 100 1 ...
- python(安装)
1.下载安装包 https://www.python.org/downloads/ 2.安装 默认安装路径:C:\python3(建议自定义安装路径) 3.配置环境变量 [右键计算机]-->[属 ...
- muduo网络库源码学习————线程池实现
muduo库里面的线程池是固定线程池,即创建的线程池里面的线程个数是一定的,不是动态的.线程池里面一般要包含线程队列还有任务队列,外部程序将任务存放到线程池的任务队列中,线程池中的线程队列执行任务,也 ...