Mybatis源码手记-从缓存体系看责任链派发模式与循环依赖企业级实践
一、缓存总览
Mybatis在设计上处处都有用到的缓存,而且Mybatis的缓存体系设计上遵循单一职责、开闭原则、高度解耦。及其精巧,充分的将缓存分层,其独到之处可以套用到很多类似的业务上。这里将主要的缓存体系做一下简单的分析笔记。以及借助Mybatis缓存体系的学习,进一步窥探责任链派发模式企业级实践,以及对象循环依赖场景下如何避免装载死循环的企业级解决方案。
先来一张之前的执行体系图:

对照这张执行图,不难看出,其实对于一次Mybatis查询调用,即SqlSession -> SimpleExecutor/ReuseExecutor/BatchExecutor -> JDBC,其实缓存就是在SqlSession到Executor*之间做一层截获请求的逻辑。从宏观上很好理解。CachingExecutor作为BaseExecutor的一个前置增强装饰器,其增强的功能就是,判断是否命中了缓存,如果命中缓存,则不进行BaseExecutor的执行派发。
public class CachingExecutor implements Executor {
// BaseExecutor
private final Executor delegate;
public CachingExecutor(Executor delegate) {
this.delegate = delegate;
delegate.setExecutorWrapper(this);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 如果未命中缓存则向BaseExecutor派发
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
}
所以由此来看,mybatis的缓存是先尝试命中CachingExecutor的二级缓存,如果未命中,则派发个BaseExecutor,下来才会去尝试命中一级缓存。由于一级缓存比较简单,我们先来看一级缓存。
二、一级缓存概览
之前执行器的那一节讲过,Mybatis的执行器和SqlSession都是一对一的关系
public class DefaultSqlSession implements SqlSession {
// ...
private final Executor executor;
// ...
}
而每个执行器里边用一个成员变量来做缓存容器
public abstract class BaseExecutor implements Executor {
// ...
protected PerpetualCache localCache;
// ...
}
那么也就是说,一旦SqlSession关闭,即对象销毁,必然BaseExecutor对象销毁,所以一级缓存容器跟着销毁。由此可以推到出:一级缓存是SqlSession级别的缓存。也就是要命中一级缓存,必须是同一个SqlSession,而且未关闭。
再来看一下一级缓存是如何设置缓存的:
public abstract class BaseExecutor implements Executor {
protected PerpetualCache localCache;
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
}
通过这一段源码,可以看到,是在第6行去构建缓存key,在第21行尝试获取缓存。构建缓存key,取决于四个维度:MappedStatement(同一个statementId)、parameter(同样的查询参数)、RowBounds(同样的行数)、BoundsSql(同样的SQL),加上上边SqlSession的条件,一级缓存的命中条件为:相同的SqlSession、statementId、parameter、行数、Sql,才能命中一级缓存。
这里在说一句题外话,就是当mybatis与Spring集成时,SqlSession的管理就交给Spring框架了,每次Mybatis的查询都会由Spring框架新建一个Sqlsession供mybatis用,看起来一级缓存永远失效。解决办法就是给查询加上事务,当加上事务的时候,Spring框架会保证在一个事务里边只提供给mybatis同一个SqlSession对象。
再看下一级缓存何时会被刷新掉,来上源码:
public abstract class BaseExecutor implements Executor {
protected PerpetualCache localCache;
@Override
public void close(boolean forceRollback) {
try {
try {
rollback(forceRollback);
} finally {
if (transaction != null) {
transaction.close();
}
}
} catch (SQLException e) {
log.warn("Unexpected exception on closing transaction. Cause: " + e);
} finally {
transaction = null;
deferredLoads = null;
localCache = null;
localOutputParameterCache = null;
closed = true;
}
}
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
@Override
public void commit(boolean required) throws SQLException {
clearLocalCache();
}
@Override
public void rollback(boolean required) throws SQLException {
if (!closed) {
try {
clearLocalCache();
flushStatements(true);
} finally {
if (required) {
transaction.rollback();
}
}
}
}
@Override
public void clearLocalCache() {
if (!closed) {
localCache.clear();
localOutputParameterCache.clear();
}
}
对于这段源码,清除缓存的场景,着重关注一下clearLocalCache的调用的地方:
即触发更新操作(第29行)、配置flushCache=true(第35行)、配置缓存作用于为STATEMENT(第38行)、commit时候(第42行)、rollback时候(第50行)、执行器关闭时候(第7行)都会清除一级缓存。
三、一级缓存对于嵌套子查询循环依赖场景的解决方案
循环依赖的情况处处可见,比如:一个班主任,下边有多个学生,每个学生又有一个对应的班主任。
对于班主任和学生这种场景,在mybatis层面属于典型的嵌套子查询。mybatis在处理嵌套查询的时候,都会查询,然后在设置属性的时候,如果发现有子查询,则发起子查询。那么,如果不加特殊干预,这种场景将会陷入设置属性触发查询的死循环中。
<select id="selectHeadmasterById" resultMap="teacherMap">
select * from teacher where id = #{id}
</select>
<resultMap id="teacherMap" type="Teacher" autoMapping="true">
<result column="name" property="name"/>
<collection property="students" column="id" select="selectStudentsByTeacherId" fetchType="eager"/>
</resultMap>
<select id="selectStudentsByTeacherId" resultMap="studentMap">
select * from student where teacher_id = #{teacherId}
</select>
<resultMap id="studentMap" type="comment">
<association property="teacher" column="teacher_id" select="selectHeadmasterById" fetchType="eager"/>
</resultMap>
mybatis在处理这种情况的时候,巧妙的用了一个临时一级缓存占位符与延迟装载(不同于懒加载),解决了查询死循环的问题。这里我们直接上源码:
每次查询,如果没有命中有效缓存(即非占位符缓存)mybatis都会事先给一级缓存写入一个占位符,待数据库查询完毕后,再将真正的数据覆盖掉占位符缓存。
public abstract class BaseExecutor implements Executor {
protected ConcurrentLinkedQueue<DeferredLoad> deferredLoads;
protected PerpetualCache localCache;
protected int queryStack;
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 如果未获取到缓存则查库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}
}
如上Query方法的第22行进去:
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 查库之前先设置占位符缓存
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
BaseExecutor.queryFromDataBase方法的第6行,会触发数据库查询,紧接着会进入结果值设定的逻辑。那么首先会探测有无嵌套的子查询,如果有,则前一步主查询暂时等待,立即发起子查询。
private Object getNestedQueryMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
final String nestedQueryId = propertyMapping.getNestedQueryId();
final String property = propertyMapping.getProperty();
final MappedStatement nestedQuery = configuration.getMappedStatement(nestedQueryId);
final Class<?> nestedQueryParameterType = nestedQuery.getParameterMap().getType();
final Object nestedQueryParameterObject = prepareParameterForNestedQuery(rs, propertyMapping, nestedQueryParameterType, columnPrefix);
Object value = null;
if (nestedQueryParameterObject != null) {
final BoundSql nestedBoundSql = nestedQuery.getBoundSql(nestedQueryParameterObject);
final CacheKey key = executor.createCacheKey(nestedQuery, nestedQueryParameterObject, RowBounds.DEFAULT, nestedBoundSql);
final Class<?> targetType = propertyMapping.getJavaType();
// 判断当前的子查询是否和之前的某一步主查询相同
if (executor.isCached(nestedQuery, key)) {
executor.deferLoad(nestedQuery, metaResultObject, property, key, targetType);
value = DEFERRED;
} else {
final ResultLoader resultLoader = new ResultLoader(configuration, executor, nestedQuery, nestedQueryParameterObject, targetType, key, nestedBoundSql);
if (propertyMapping.isLazy()) {
lazyLoader.addLoader(property, metaResultObject, resultLoader);
value = DEFERRED;
} else {
// 立即发起子查询
value = resultLoader.loadResult();
}
}
}
return value;
}
这块重点关注第13行和第23行。其中第23行又会递归到上边BaseExecutor.query代码片段的第22行。如果getNestedQueryMappingValue代码段走的是滴15行逻辑,那么,会对应BaseExecutor.query代码片段的第28行。这块递归比较绕。下来做下通俗的解释:
首先查询班主任的主查询给一级缓存写入一个占位符缓存,然后去查库,然后设定属性,如果没有嵌套子查询,那么到这里就把设置好属性的值写入覆盖刚才一级占位符缓存。流畅完毕。
但是恰好有嵌套子查询,所以查询班主任的主查询就停在设置属性这一步,然后又发起一次查询,查询学生,然后又进入查询学生设定属性的方法。
设定学生属性方法又发现又有嵌套子查询,所以有发起一次学生查询班主任的查询操作,又进入到设定属性这块,但是发现一级缓存里边有前边住查询的站位缓存。所以没有在查库,而是将本次子查询放入延迟装载的容器里边。本次子查询结束。紧接着前一步子查询(老师查学生)结束。
紧接着查询老师的住查询设定属性完毕,并将自己的结果覆盖之前写入的站位缓存。同时启动了延时装载的逻辑,延时装载就是从一级缓存取出刚才查询老师的一级缓存数据(老师),给第二步子查询(学生)做一下MetaObject属性设置。
说的通俗一点:主查询(查班主任)执行时先写入站位缓存,紧接着挂起,发起第一个嵌套子查询(用老师查学生),紧接着该子查询再挂起,发起学生查老师,但是发现第一步主查询有一级缓存(站位缓存),那么本次子查询自动加入延迟装载队列,然后终结改子查询,等待主查询真正查完,然后延迟装载器再从缓存取出数据给第一个子查询(老师查学生)进行属性设定。
说了这么多,肯定晕车了,这里给出一个时序图:
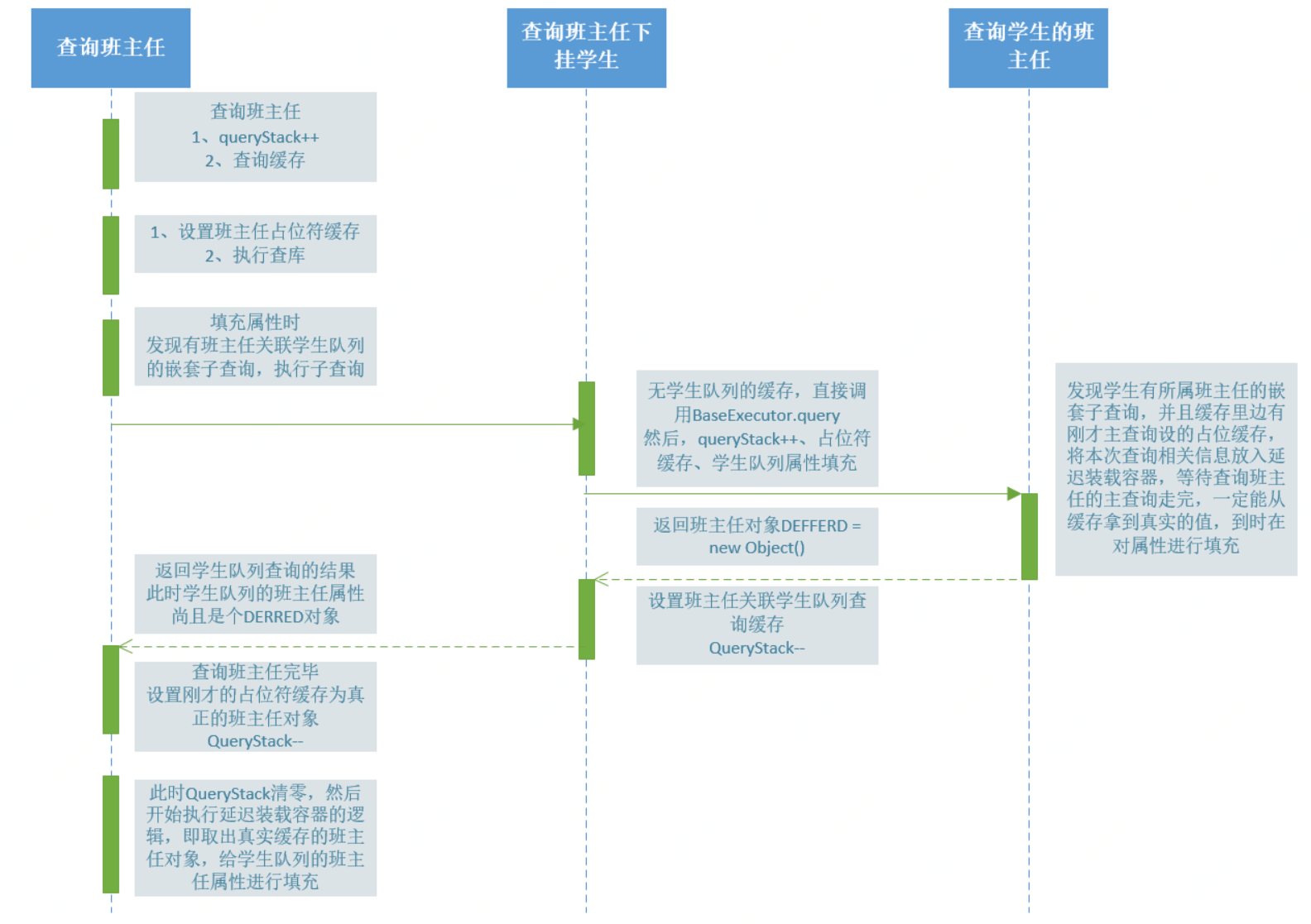
总结一下:
1、占位符缓存作用在于标识与当前查询相同的前边的嵌套查询。比如:查询学生所属班主任,发现前边的主查询就是查询班主任,所以就不在执行班主任查询。等待真正的班主任查询完毕,我们只需去缓存里边取即可。所以我们不执行查询,只是将本次属性设置放入延迟装载队列即可。
2、queryStack用来记录当前查询处于嵌套的第几层。当queryStack == 0时,证明整个查询已经回归到最初的主查询上,此时,所有过程中需要延迟装载的对象,都能启动真实装载了。
3、一级缓存在解决嵌套子查询属性设置循环依赖上启至关作用。所以以及缓存是不能完全关闭的。但是我们可以设置:LocalCacheScope.STATEMENT,来让一级缓存及时清空。参见源码
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// ...
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
// 设置LocalCacheScope.STATEMENT来及时清空缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
}
四、二级缓存
来先上一个二级缓存的执行流程:

二级缓存是BaseExecutor的前置增强包装类CachingExecutor里边实现的,即如果从CachingExecutor里边命中缓存,则不进行BaseExecutor的派发(如下第14行)。
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
11行与17行的区别在于,是否启动二级缓存,如果启动了,则将派发给BaseExecutor的查询结果写入暂存区(第12行,TransactionCacheManager),等事务提交在真正刷入二级缓存。下来我们重点来关注一下缓存的读写(第9行、第12行),这里边真正的执行对象是一系列Cache接口的实现,按职责有:线程安全、日志记录、过期清理、溢出淘汰、序列化、执行存储等等环节。而二级缓存的设计精巧之处就在于此处,完美的按职责进行责任派发,完全解耦。
接下来我们来看下,默认情况下,缓存责任链的初始换过程:
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
Cache cache = new CacheBuilder(currentNamespace)
// 这里设置默认的存储为内存
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
// 这里设置默认的溢出淘汰为LRU
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
configuration.addCache(cache);
currentCache = cache;
return cache;
}
然后是初始换过程:
public Cache build() {
setDefaultImplementations();
Cache cache = newBaseCacheInstance(implementation, id);
setCacheProperties(cache);
// issue #352, do not apply decorators to custom caches
if (PerpetualCache.class.equals(cache.getClass())) {
for (Class<? extends Cache> decorator : decorators) {
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache);
}
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
cache = new LoggingCache(cache);
}
return cache;
}
private Cache setStandardDecorators(Cache cache) {
try {
MetaObject metaCache = SystemMetaObject.forObject(cache);
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
if (clearInterval != null) {
cache = new ScheduledCache(cache);
((ScheduledCache) cache).setClearInterval(clearInterval);
}
if (readWrite) {
cache = new SerializedCache(cache);
}
cache = new LoggingCache(cache);
cache = new SynchronizedCache(cache);
if (blocking) {
cache = new BlockingCache(cache);
}
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
}
这里从第3、8、24、28、30、31、33行分别进行了责任装饰初始化。这种依据职责分别拆分然后嵌套的解耦方式,其实是一种很成熟的企业级责任派发设计模式。而且形如第8行的循环装饰嵌套,在很多开源框架中都能见到,比如Dubbo的AOP机制就是这样初始化的。
下边直接列一下Mybatis的二级缓存在设计上所覆盖的功能,以及各功能责任链派发的结构图:
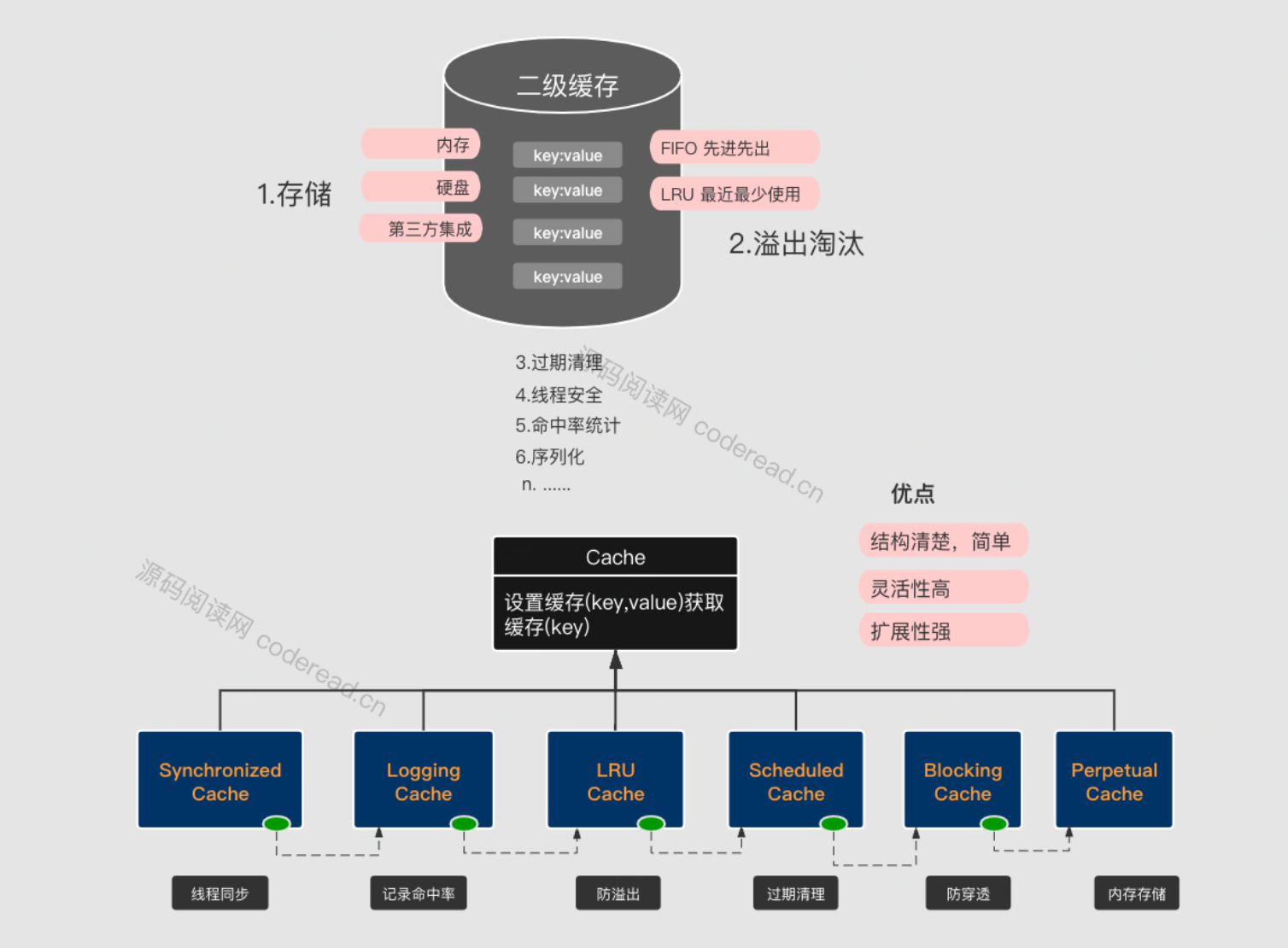
从上边的代码可以看出,如果设置了blocking的话,那么最外层将会包裹BlockingCache、下来是SynchronizedCache,这两个均是进行现成安全,防止缓存穿透的处理。
public class BlockingCache implements Cache {
private final Cache delegate;
private final ConcurrentHashMap<Object, ReentrantLock> locks;
public BlockingCache(Cache delegate) {
this.delegate = delegate;
this.locks = new ConcurrentHashMap<Object, ReentrantLock>();
}
@Override
public void putObject(Object key, Object value) {
try {
delegate.putObject(key, value);
} finally {
releaseLock(key);
}
}
@Override
public Object getObject(Object key) {
acquireLock(key);
Object value = delegate.getObject(key);
if (value != null) {
releaseLock(key);
}
return value;
}
}
public class SynchronizedCache implements Cache {
private Cache delegate;
@Override
public synchronized void putObject(Object key, Object object) {
delegate.putObject(key, object);
}
@Override
public synchronized Object getObject(Object key) {
return delegate.getObject(key);
}
}
再看一下负责溢出淘汰的LruCache:
public class LruCache implements Cache {
private final Cache delegate;
private Map<Object, Object> keyMap;
// 记录当溢出时,需要淘汰的Key
private Object eldestKey;
public void setSize(final int size) {
// LinkedHashMap.accessOrder设置为true,即,每个被访问的元素会一次放到队列末尾。当溢出的时候就能从首部来移除了
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
boolean tooBig = size() > size;
if (tooBig) {
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
@Override
public void putObject(Object key, Object value) {
delegate.putObject(key, value);
cycleKeyList(key);
}
private void cycleKeyList(Object key) {
keyMap.put(key, key);
if (eldestKey != null) {
delegate.removeObject(eldestKey);
eldestKey = null;
}
}
}
二级缓存就讲到这里,总结一下二级缓存件:
1、默认开启,cachEnable开关。作用于提交后。
2、相同的StatementId。
3、相同的SQL、参数、行数。
4、跨Mapper调用。
五、总结
虽然在目前各种分布式应用的场景下,一级缓存和二级缓存都有很大概率的脏读现象,而被禁止,但是Mybatis对这种局部场景的设计是及其精巧的。比如,解决对象循环嵌套查询的场景设计,其实这种成熟的解决方案也被Spring(也存在对象循环注入的情景)所应用。以及责任装饰的设计,Dubbo同样在使用。其实我们能从得到很多启发,比如,对于既定的业务场景,要加入现成安全的考量,那在不侵入业务代码的前提下,我们是否也能增加一层责任装饰,进行派发来完成呢?
Mybatis源码手记-从缓存体系看责任链派发模式与循环依赖企业级实践的更多相关文章
- myBatis源码解析-二级缓存的实现方式
1. 前言 前面近一个月去写自己的mybatis框架了,对mybatis源码分析止步不前,此文继续前面的文章.开始分析mybatis一,二级缓存的实现.附上自己的项目github地址:https:// ...
- Mybatis源码分析之缓存
一.MyBatis缓存介绍 正如大多数持久层框架一样,MyBatis 同样提供了一级缓存和二级缓存的支持 一级缓存: 基于PerpetualCache 的 HashMap本地缓存,其存储作用域为 Se ...
- 【mybatis源码学习】缓存机制
一.mybatis的缓存 一级缓存:sqlsession级别,默认开启(一个事务内有效)二级缓存: sqlsessionFactory级别,需要手动开启,在xml配置cache节点(依赖事务的执行结 ...
- Mybatis执行器源码手记
今天将Mybatis的执行器部分做一下简单手记. 一.java原生JDBC 众所周知,Mybatis是一个半自动化ORM框架.其实说白了,就是将java的rt.jar的JDBC操作进行了适度的封装.所 ...
- 【MyBatis源码解析】MyBatis一二级缓存
MyBatis缓存 我们知道,频繁的数据库操作是非常耗费性能的(主要是因为对于DB而言,数据是持久化在磁盘中的,因此查询操作需要通过IO,IO操作速度相比内存操作速度慢了好几个量级),尤其是对于一些相 ...
- MyBatis 源码分析 - 缓存原理
1.简介 在 Web 应用中,缓存是必不可少的组件.通常我们都会用 Redis 或 memcached 等缓存中间件,拦截大量奔向数据库的请求,减轻数据库压力.作为一个重要的组件,MyBatis 自然 ...
- Mybatis源码分析之Cache二级缓存原理 (五)
一:Cache类的介绍 讲解缓存之前我们需要先了解一下Cache接口以及实现MyBatis定义了一个org.apache.ibatis.cache.Cache接口作为其Cache提供者的SPI(Ser ...
- mybatis源码学习(三)-一级缓存二级缓存
本文主要是个人学习mybatis缓存的学习笔记,主要有以下几个知识点 1.一级缓存配置信息 2.一级缓存源码学习笔记 3.二级缓存配置信息 4.二级缓存源码 5.一级缓存.二级缓存总结 1.一级缓存配 ...
- mybatis源码分析之06二级缓存
上一篇整合redis框架作为mybatis的二级缓存, 该篇从源码角度去分析mybatis是如何做到的. 通过上一篇文章知道,整合redis时需要在FemaleMapper.xml中添加如下配置 &l ...
随机推荐
- IDEA启动springboot项目找不到application.yml配置文件
idea启动项目时读取不到application-pro.yml文件,但是配置文件都在resource目录下: 解决:target/classes 目录是IDEA的classpath目录,项目编译后配 ...
- SpringCloud异常处理统一封装我来做-使用篇
SpringCloud异常处理统一封装我来做-使用篇 简介 重复功能我来写.在 SpringBoot 项目里都有全局异常处理以及返回包装等,返回前端是带上succ.code.msg.data等字段.单 ...
- CF948B Primal Sport
题目链接:http://codeforces.com/contest/948/problem/B 知识点: 素数 解题思路: \(f(x)\) 表示 \(x\) 的最大素因子.不难想到:\(X_1 \ ...
- vue使用stylus样式预处理器
vue使用stylus样式预处理器,样式总是报错,需要从上一行的样式回车换行才不会报错 <style lang="stylus" scoped> .navbar mar ...
- css不换行解决
word-wrap: break-word; word-break: break-all; white-space: pre-wrap;
- 干货!JNPF快速开发平台功能一览
JNPF,采用主流的两大技术Java/.Net开发,是一套低代码开发平台,可视化开发环境,有拖拽式的代码生成器,灵活的权限配置.SaaS服务,强大的接口对接,随心可变的工作流引擎,一站式开发多端使 ...
- Java之预定义
作为Java初学者的我,提供一个类似C#的预处理机制.若有不足之处,敬请各位大佬指正(感觉没有,哈哈哈哈哈哈)! Java 没有类似 C++的宏,也没有类似C#的预定义 #if...#endif C# ...
- Java IO(十七)FIleReader 和 FileWriter
Java IO(十七)FIleReader 和 FileWriter 一.介绍 FIleReader 和 FileWriter 是读写字符文件的便利类,分别继承于 InputStreamReader ...
- NodeJS——模块全局安装路径配置以及关于supervisor的问题解释
下载安装NodeJS后,在自己选择的路径下会有如下的文件: 默认情况下NodeJS安装会同时安装npm(模块管理器:用于管理用户require的模块,有全局和本地两种). 注:全局:执行npm in ...
- php序列化和反序列化学习
1.什么是序列化 序列化说通俗点就是把一个对象变成可以传输的字符串. 1.举个例子,不知道大家知不知道json格式,这就是一种序列化,有可能就是通过array序列化而来的.而反序列化就是把那串可以传输 ...