为什么 MySQL 回滚事务也会导致 ibd 文件增大?
一个简单的测试:
start transaction;
insert into tb1 values(3, repeat('a', 65000),'x',1);
--commit;
rollback;
下图分别是 tb1.ibd 在插入前,回滚前,回滚后的文件大小:
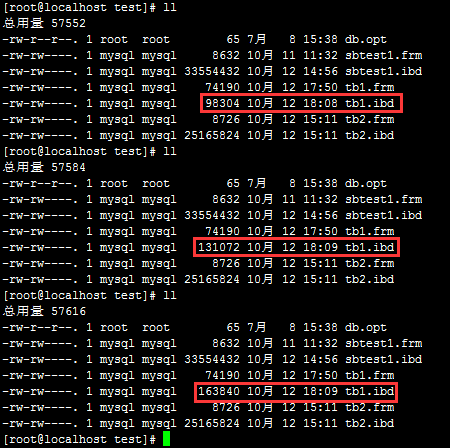
有人在QQ群问:为什么回滚会导致tb1.idb的磁盘空间增大?
---------------------------------------
首先:131072-98304=163840-131072=32768
这里要存储 65000 个字符'a' ,那么字段类型应该是 text. 而 text 字段的处理是很特别的:
Each BLOB or TEXT value is represented internally by a separately allocated object. This is in contrast
to all other data types, for which storage is allocated once per column when the table is opened.
也就是说对于 text/blob 字段来说,它们是另外分配了一个专门的对象来存储,对它们的处理不会在内存中进行缓存,而是直接写入磁盘中。所以未提交时,就可以看到 tb1.idb 发生了增长。
而对于 insert 操作的 rollback,那么必须将之前插入的数据进行 delete 操作,而 delete 操作是逻辑操作,也就是设置一个标志位就行了,于是又分配了一个专门的对象来存储这个设置了删除标志的对象。于是磁盘空间增长了两次(暂时只能这么解释了...),每次都是 32768字节(2的15次方)。一旦提交或者rollback,磁盘空间就可以被回收。
为什么是 32768呢?
text的最大存储空间是 65656 个字节,每次分配的最小单位是 32768字节。
也就是 insert 和 rollback 都导致了一次 text 字段磁盘空间的增长分配,而分配的最小单位是32768.
如何你将 repeat('a',65000) 换成: repeat('a',65535) 在进行测试,你会发现,insert 时,tb1.idb会增长65536,在执行rollback时也会导致 tb1.idb 再次增长32768。
所以应该是 rollback 会导致 text 字段另外分配一次空间,而分配的最小单位是32768。可能和 text 字段的存储结构有关系。这个需要看源码了。
----------------
测试表明,其它非 text 字段的 rollback 操作,不会导致 ibd 文件增大。
测试建表语句如下:
mysql> show create table tb1\G
*************************** 1. row ***************************
Table: tb1
Create Table: CREATE TABLE `tb1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`webtext` text COLLATE utf8mb4_bin,
`tp` varchar(2) COLLATE utf8mb4_bin DEFAULT NULL,
`se` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
1 row in set (0.00 sec)
为什么 MySQL 回滚事务也会导致 ibd 文件增大?的更多相关文章
- mysql innodb 从 ibd 文件恢复表数据
最近内部的 mysql 数据库发生了一件奇怪的事,其中有一个表 users625 突然出现问题, 所有对它的操作都报错误 数据表不存在. mysql> select count(*) from ...
- 硬盘空间满导致mysql ibd文件被删后提示Tablespace is missing for table 'db_rsk/XXX"
昨天一早,开发人员反馈说一个测试环境报Tablespace is missing for table 'db_rsk/XXX",周末刚升级过,特地让开发回去查了下,说脚本中肯定没有drop ...
- Mysql ibd文件恢复指南
背景 mysql在使用的过程中,难免遇到数据库表误操作,基于此,作者亲力亲为,对mysql数据表ibd文件的恢复做以下详细的说明,对开发或者初级dba提供一定的指导作用,博客中如若存在相关问题,请指明 ...
- MySQL从.ibd文件中恢复数据
首先,在MySQL命令行下执行如下命令可以查看MySQL中存放数据的位置: show global variables like "%datadir%"; 我这里的执行结果: +- ...
- MySQL 利用frm文件和ibd文件恢复表结构和表数据
文章目录 frm文件和ibd文件简介 frm文件恢复表结构 ibd文件恢复表数据 通过脚本利用ibd文件恢复数据 通过shell脚本导出mysql所有库的所有表的表结构 frm文件和ibd文件简介 在 ...
- MySQL frm+ibd文件还原data的办法【数据恢复】
MySQL frm+ibd文件还原data的办法[数据恢复] 此方法只适合innodb_file_per_table = 1 当误删除ibdata 该怎么办? 如下步骤即可恢复: 1 ...
- 【MySQL】InnoDB引擎ibdata文件损坏/删除后使用frm和ibd文件恢复数据
参考:http://my.oschina.net/sansom/blog/179116 参考:http://www.jb51.net/article/43282.htm 注意!此方法只适用于innod ...
- MySQL表结构为InnoDB类型从ibd文件恢复数据
客户的机器系统异常关机,重启后mysql数据库不能正常启动,重装系统后发现数据库文件损坏,悲催的是客户数据库没有进行及时备份,只能想办法从数据库文件当中恢复,查找资料,试验各种方法,确认下面步骤可行: ...
- mysql通过frm+ibd文件还原data
此方法只适合innodb_file_per_table = 1 当误删除ibdata 该怎么办? 如下步骤即可恢复: 1.准备工作 1)准备一台纯洁的mysql环境[从启动到现在没有 ...
随机推荐
- 不在 sudoers 文件中。此事将被报告。
使用Linux,初学使用root不要太方便,工作中却不会给你这样的,必须要用自己的账号.新账号需要添加sudo的权限. su 使用root登陆 visudo 在root下添加自己的用户名 root A ...
- 一个网站完整详细的SEO优化方案
根据自己的个人经验完成了这篇文章,希望对SEOer有点帮助,高手直接跳过,请勿喷水... 一个完整的SEO优化方案主要由四个小组组成: 一.前端/页编人员 二.内容编辑人员 三.推广人员 四.数据分析 ...
- Dapper简明教程
Dapper是一款轻量级的ORM框架,有关Dapper优缺点的文章网上一大堆,这里小编就不再赘述啦.下面直接进入正题: 使用前准备 添加对Dapper的引用 在使用Dapper之前,我们要首先添加对D ...
- Rafy 领域实体框架 - 树型实体功能(自关联表)
在 Rafy 领域实体框架中,对自关联的实体结构做了特殊的处理,下面对这一功能进行讲解. 场景 在开发数据库应用程序时,往往会遇到自关联表的场景.例如,分类信息.组织架构中的部门.文件夹信息等,都 ...
- Nancy之结合TinyFox调试备忘
最近把一个小项目的数据库换成MongoDB,同时用了MongoRepository 这个开源组件来对数据进行操作. 通过NuGet安装之后,它会自动在web.config文件生成一个连接字符串.但是却 ...
- GridView的使用
首先,gridview是封装好的,直接在设计界面使用,基本不需要写代码: 一.绑定数据源 GridView最好与LinQDatasourse配合使用,相匹配绑定数据: 二.样式控制 1.自动套用样式 ...
- datagridview 单元格格式转换注意
datagridview 单元格内容进行比较时要注意正确写法要用强制转换,否则出错Convert.ToString(grd_order.SelectedRows[0].Cells[1].Value)= ...
- C#中AppDomain.CurrentDomain.BaseDirectory及各种路径获取方法
// 获取程序的基目录.System.AppDomain.CurrentDomain.BaseDirectory // 获取模块的完整路径,包含文件名System.Diagnostics.Proces ...
- Linux安装JDK1.7
发表此篇文章纯属本人愚钝,希望以后再安装JDK不要走那么多曲折的路,也希望可以给后人借鉴. 1.以下以JDK1.7为例 具体官网地址:http://www.oracle.com/technetwork ...
- Spring容器深入(li)
spring中最常用的控制反转和面向切面编程. 一.IOC IoC(Inversion of Control,控制倒转).对于spring框架来说,就是由spring来负责控制对象的生命周期和对象间的 ...