(数据科学学习手札79)基于geopandas的空间数据分析——深入浅出分层设色
本文对应代码和数据已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
通过前面的文章,我们已经对geopandas中的数据结构、坐标参考系、文件IO以及基础可视化有了较为深入的学习,其中在基础可视化那篇文章中我们提到了分层设色地图,可以对与多边形关联的数值属性进行分层,并分别映射不同的填充颜色,但只是开了个头举了个简单的例子,实际数据可视化过程中的分层设色有一套策略方法。
作为基于geopandas的空间数据分析系列文章的第五篇,通过本文你将会学习到基于geopandas和机器学习的分层设色。
2 基于geopandas的分层设色
地区分布图(Choropleth maps,又叫面量图)作为可能是最常见的一种地理可视化方法,其核心是对某个与矢量面关联的数值序列进行有意义的分层,并为这些分层选择合适美观的色彩,最后完成对地图的着色,优点是美观且直观,即使对地理信息一窍不通的人,也能通过颜色区分出不同面之间的同质性与异质性:
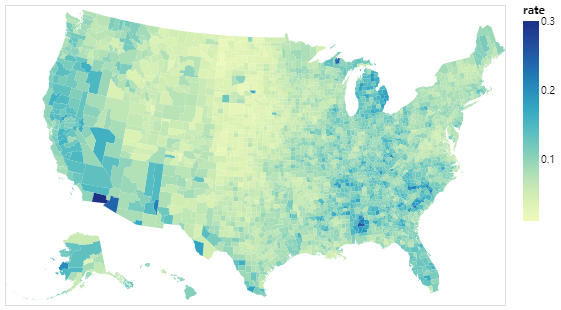 图1
图1
但同样地,如果对数据分层采取的方法有失严谨没有很好的遵循数据特点,会很容易让看到图的人产生出不正确的判断,下面我们按照先分层,后设色的顺序进行介绍。
2.1 基于mapclassify的数据分层
上一篇文章中我们提到过,,在geopandas.GeoDataFrame.plot()中,参数scheme对应的数据分层是基于第三方库mapclassify实现的,因此要想对geopandas中的数据分层有深入的了解,我们就得先来了解一下mapclassify中的各种数据分层算法,用到的数据是系列文章前几期使用地滚瓜烂熟的新冠肺炎疫情数据,数据处理过程同上一篇文章,这里不再解释:
 图2
图2
2.1.1 BoxPlot
BoxPlot即箱线图,是统计学中使用到的一种方法:对个数为\(n\)观测数据从小到大进行排序,分别得到位置处于\(0.25n\)、\(0.5n\)以及\(0.75n\)的观测值,称为\(Q_{1}\)、\(Median\)以及\(Q_{3}\)(即第一四位数、中位数和第三四分位数),并定义\(Q_{3}-Q_{1}\)为\(IQR\),以\(Q_{1}-1.5IQR\)为下限,以\(Q3+1.5IQR\)为上限,将小于下限或大于上限的观测值作为离群异常值,最后用图像的形式表达上述计算结果,如图2的上图,而图2的下图对应着概率估计,可以看出,箱线图法实际上是基于概率估计的一种异常值剔除方法,因为离群值只有\(0.0035*2=0.007\)的概率会出现,即如果你想要找出数据中的异常高低值,BoxPlot是不错的选择:
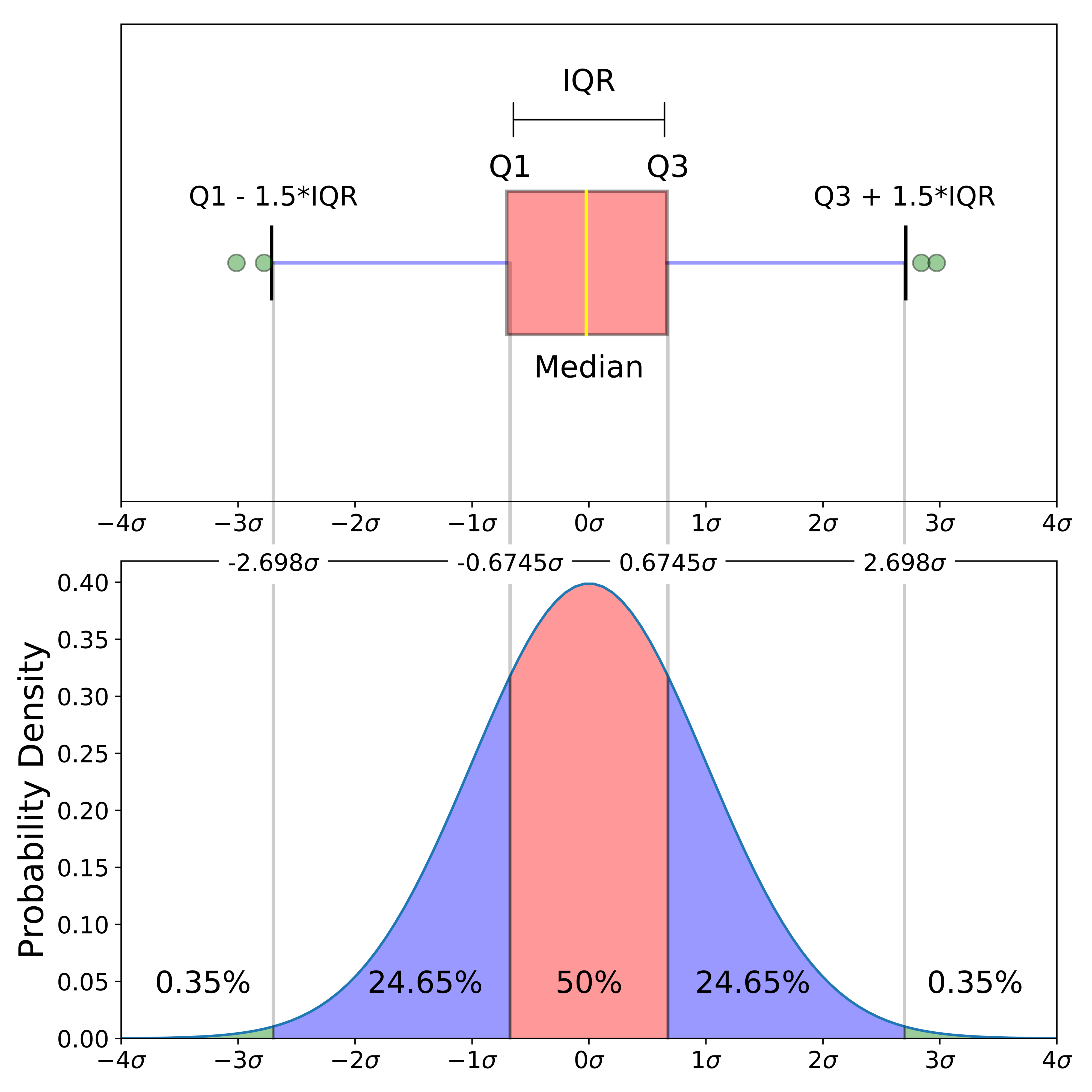 图3
图3
在mapclassify中我们使用BoxPlot()来为数据实现箱线图分层:
import mapclassify as mc
# 对各省2020-03-08对应的累计确诊数量进行分层
bp = mc.BoxPlot(temp['province_confirmedCount'])
# 查看数据分层结果
bp
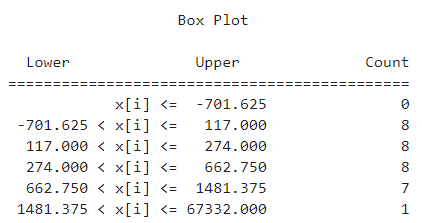 图4
图4
可以看出通过箱线图法将数据分成了五类,其中异常值只有1个即为湖北省,下面我们配合geopandas来对上述结果进行可视化,和上一篇文章一样,按照省级单位名称连接我们的疫情数据与矢量数据:
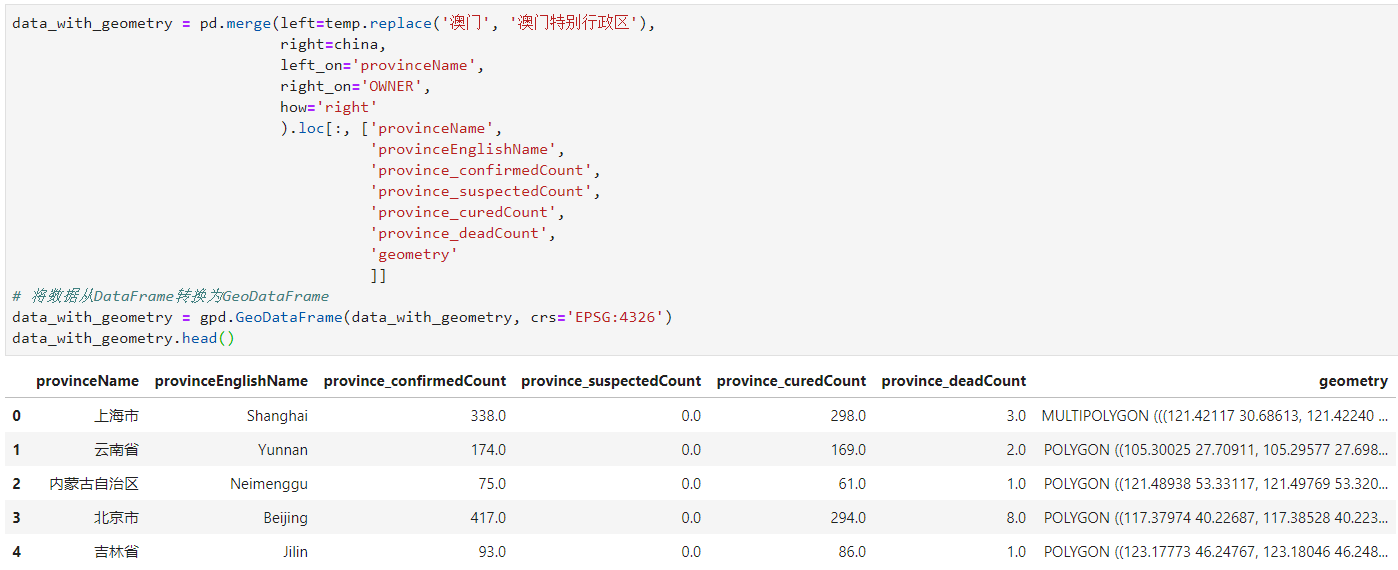 图5
图5
接着对其进行可视化,在上一篇文章图28的基础上,将scheme参数改为BoxPlot,又因为箱线图可以看作无监督问题,故分层数量k在这里无效,删去:
fig, ax = plt.subplots(figsize=(10, 10))
ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax,
column='province_confirmedCount',
cmap='Reds',
missing_kwds={
"color": "lightgrey",
"edgecolor": "black",
"hatch": "////",
"label": "缺失值"
},
legend=True,
scheme='BoxPlot',
legend_kwds={
'loc': 'lower left',
'title': '确诊数量分级',
'shadow': True
})
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax.axis('off')
plt.suptitle('新型冠状肺炎累计确诊数量地区分布', fontsize=24) # 添加最高级别标题
plt.tight_layout(pad=4.5) # 调整不同标题之间间距
ax.text(-2800000, 1300000, '* 原始数据来源:丁香园,\n其中台湾及香港数据缺失') # 添加数据说明
fig.savefig('图6.png', dpi=300)
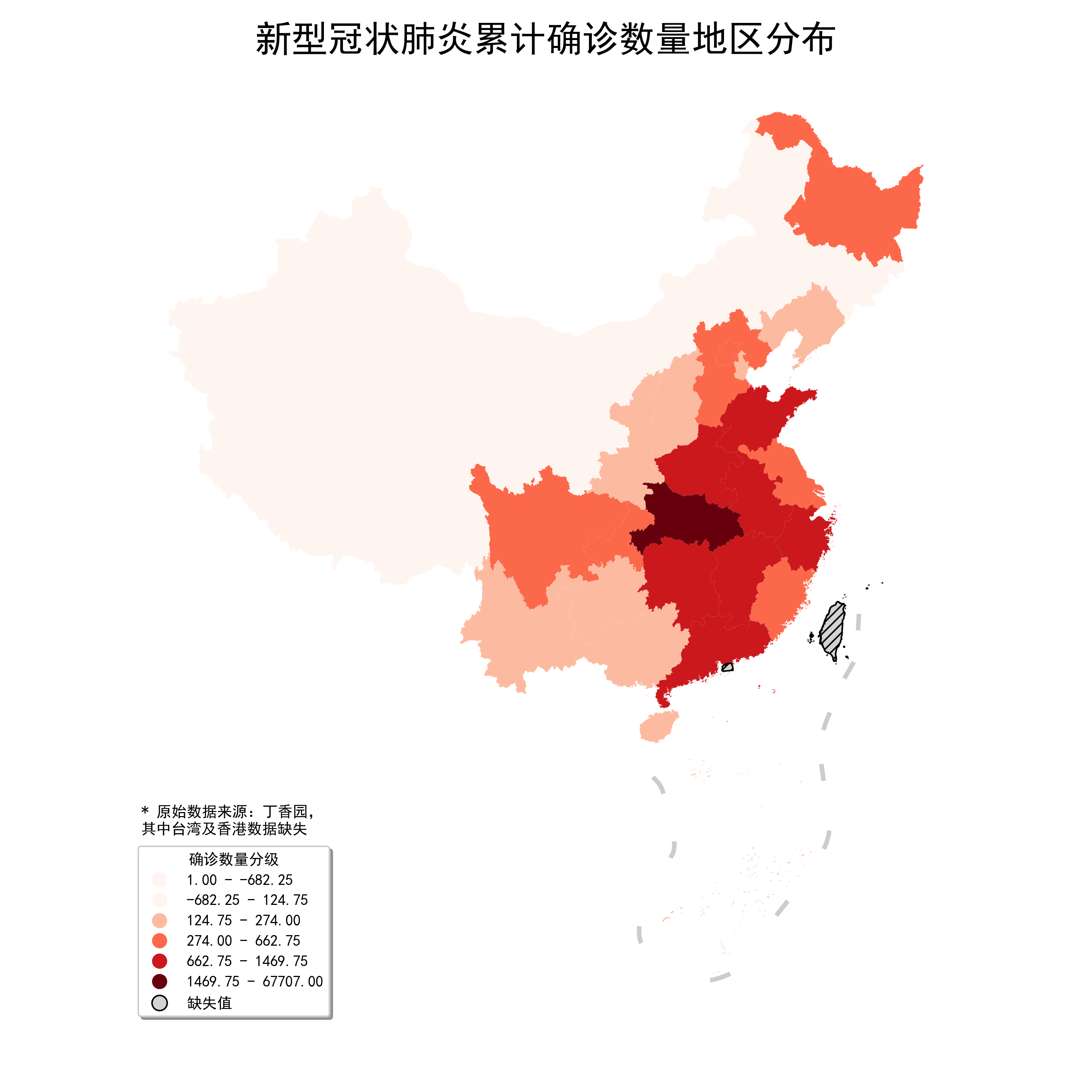 图6
图6
咋看起来没问题,但是如果你仔细观察左下角的图例会发现前两行范围颜色是重复的,且数值范围是错乱的,这是geopandas.GeoDataFrame.plot()中涉及箱线图法的一个小bug,遇到这种问题不用慌,如果你在上一篇文章中去我的Github仓库查看过创作图29对应的代码,一定会想到既然geopandas自身有bug,那我们用matplotlib中的mpatches和legend自定义图例就可以啦,而为了自定义的图例色彩与geopandas映射出的保持一致,我们需要额外使用到matplotlib中的get_cmap(cmap)来制作可独立导出颜色的cmap方案实例,譬如我们这里是Reds,就需要按照前面bp的有记录数量的分层结果,从Reds中产生同样5个档次的颜色,具体操作过程如下:
import matplotlib.patches as mpatches
fig, ax = plt.subplots(figsize=(10, 10))
ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax,
column='province_confirmedCount',
cmap='Reds',
missing_kwds={
"color": "lightgrey",
"edgecolor": "black",
"hatch": "////",
"label": "缺失值"
},
scheme='BoxPlot')
handles, labels = ax.get_legend_handles_labels() #get existing legend item handles and labels
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
# 实例化cmap方案
cmap = plt.get_cmap('Reds')
# 得到mapclassify中BoxPlot的数据分层点
bp = mc.BoxPlot(temp['province_confirmedCount'])
bins = bp.bins
# 制作图例映射对象列表
LegendElement = [mpatches.Patch(facecolor=cmap(_*0.25), label=f'{int(max(bins[_], 0))} - {int(bins[_+1])}')
for _ in range(5)] + \
[mpatches.Patch(facecolor='lightgrey', edgecolor='black', hatch='////', label='缺失值')]
# 将制作好的图例映射对象列表导入legend()中,并配置相关参数
ax.legend(handles = LegendElement, loc='lower left', fontsize=10, title='确诊数量分级', shadow=True, borderpad=0.6)
ax.axis('off')
plt.suptitle('新型冠状肺炎累计确诊数量地区分布(截至2020年03月04日)', fontsize=24) # 添加最高级别标题
plt.title('数据分层方法:BoxPlot', fontsize=18)
plt.tight_layout(pad=4.5) # 调整不同标题之间间距
ax.text(-2900000, 1250000, '* 原始数据来源:丁香园,\n其中台湾及香港数据缺失') # 添加数据说明
fig.savefig('图7.png', dpi=300)
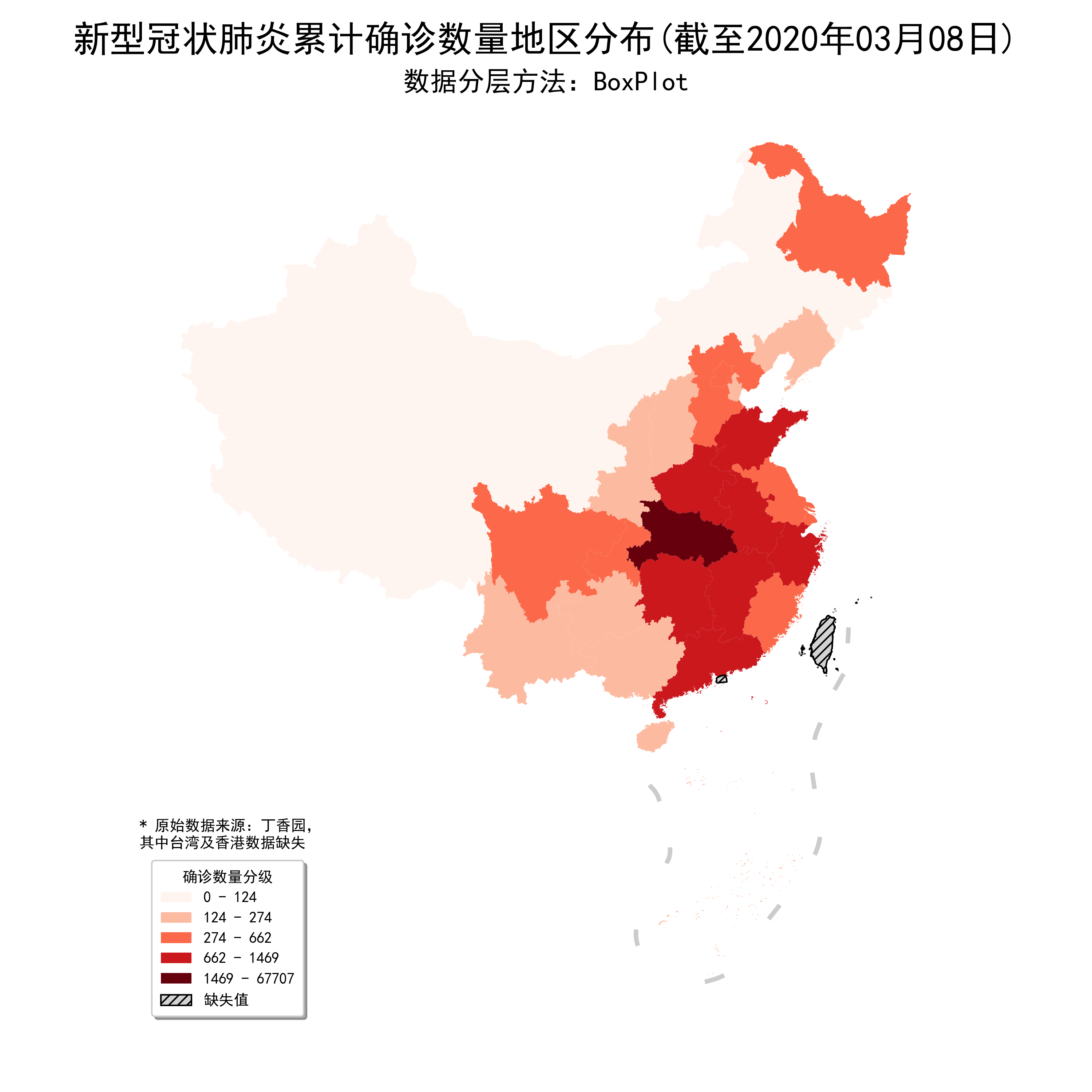 图7
图7
可以看到,通过自定义图例的方式,虽然麻烦了一点,但是我们不仅修复了图例的bug,还为其添加了更加完善的细节,如图形修改为矩形,范围修改为整数。
2.1.2 EqualInterval
EqualInterval即等间距,是最简单的一种分层方法,它在原数据最小值与最大值间以等间距的方式划分出k个层次,mapclassify中对应等间距法的类为EqualInterval():
bp = mc.EqualInterval(temp['province_confirmedCount'])
# 查看数据分层结果
bp
 图8
图8
可以看到对于分布非常不均匀的新冠肺炎确诊数量数据来说,这种方法表现得十分糟糕,中间三个类都没有记录落入,如果使用这种方法强行绘图,效果就会类似上一篇文章中地区分布图部分,最开始那个糟糕的效果那样只有湖北一个地方是最深的暗红色,而其他地方皆为最淡的色阶,这里就不重复演示。
2.1.3 FisherJenks
在了解mapclassify中的FisherJenks之前,我们先来了解一下什么是Jenks Natural Breaks:
- Jenks Natural Breaks
Jenks Natural Breaks旨在为1维数据计算合适的划分点,使得不同组之间的差距尽可能大的同时组内差距尽可能小,其思路非常简单,举一个简单的例子进行说明:
对于一组待分割的序列\(X=[4, 5, 9, 10]\),现在需要为其找到将原始数据分为\(k=2\)部分的方法,那么实际上就有\([4], [5, 9, 10]\)、\([4, 5], [9, 10]\)以及\([4, 5, 9],[10]\)这三种切分方法,现定义sum of squared deviations for array mean(简称SDAM):
\]
以及针对每一种数据分层方法,在其分出的每一组\(G_{i}\)上计算组内离差平方和并累加所有组的结果,定义为sum of squared deviations for class means(简称SDCM_ALL):
\]
有了\(SDAM\)和\(SDAM\_ALL\),现在对分组优劣定义一个评判指标goodness of variance fit(简称GVF),取值范围为\([0,1]\),越高越好:
\]
这样我们就可以对每一种分组方案进行评价,譬如对我们上面简单的例子:
SDCM_{1}=[(4-4)^2]+[(5-8)^2+(9-8)^2+(10-8)^2]=14 \\
SDCM_{2}=[(4-4.5)^2+(5-4.5)^2]+[(9-9.5)^2+(10-9.5)^2]=1 \\
SDCM_{3}=[(4-6)^2+(5-6)^2+(9-6)^2]+[(10-10)^2]=14
\]
则对应各种方案的GVF计算如下:
GVF_{2}=(26-1)/26=0.96
\]
可以看出第二种方案\([4, 5], [9, 10]\)的分层方法效果最好,也与我们对数据的直观感觉相贴合,这就是Jenks Natural Breaks的基本思路,但这种暴力遍历所有分组方案的做法对数据数量及选择分组的个数很敏感,尤其是对分组数量,一旦分组数量过于多,待筛选计算的方案数量就变成了天文数字,下面我来告诉大家为什么:
定义长度为\(n\)的序列\(X=[x_{1},x_{2},...,x_{n}]\)。且满足\(i\leq{j}\)时\(x_{i}\leq{x_{j}}\),即整个序列从小到大单调递增,那么将其分成\(k\)组的过程,可以分解为先选择第一组,且为了保证右边剩余\(k-1\)个组每组至少有1个数据分配,则第一组有\(n-k+1\)种分配方式,而第一组包含的数字数量\(n_{1}\)确定之后,剩余\(n-n_{1}\)个数据的继续分组又可以视为独立的递归分组过程,因此最终需要考虑的方案个数用公式表达起来有些复杂,但是换成计算机中的递归过程就变得一目了然,我经过思考和纸上的推演,写出了下面所示的递归函数f(n, k)来实现方案总数的计算:
def f(n, k):
# 若k退化为2,则显然需要n - 1种方案,譬如4个数字分2组有3种方案
if k == 2:
return n - 1
else:
# 若k未退化为2,则继续递归过程
return sum([f(n-_, k-1) for _ in range(1, n - k + 2)])
有了这个递归函数,我们就可以来直观的看一看为什么不能选择太多分组,首先我们对长度为100的序列分为5组试试:
f(100, 3)
Out[11]: 4851
可以看到待选择的方案才4851个,还是很少的,那么我们接下来将组数提高到5:
f(100, 5)
Out[12]: 3764376
发生了什么?随着递归深度的增大,待选择方案数量一下子就提高到三百多万个!再切换成7试一下:
f(100, 7)
Out[13]: 1120529256
在跑上述代码时,明显能感受到计算花费时间的激增,最终结果也达到惊人的11亿多!看到这,我们就明白了,原始的Jenks Natural Breaks算法虽然很有效,但如果以暴力遍历的方式计算,其复杂度是难以应付日常需求的,为了对其进行优化,以在少量的计算时间内计算出尽可能靠谱的分组结果,一系列改良加速方法被提出,而mapclassify中的FisherJenks,即为jenks教授在论文Fisher, W. D., 1958, On grouping for maximum homogeneity.的基础上提出的改良算法,但这是一个很神秘的算法,根据https://macwright.org/2013/02/18/literate-jenks.html 中的介绍,jenks教授的原始论文没有留下数字化资料,一直为堪萨斯大学地理学系所私有,而随着1996年jenks教授的离世,原论文需要到2072年版权才能到期公开,所以我们现在在各种GIS类软件以及各种开源软件包中使用到的fisher jenks算法,均是对最初的一段Fortran代码的移植和改造,这也成了一段未解之谜,感兴趣的读者可以去https://stat.ethz.ch/pipermail/r-sig-geo/2006-March/000811.html 了解更多。
回到我们的主题,搞清楚了FisherJenks的计算目标之后,我们同样利用mapclassify计算分层结果,其默认分层为5:
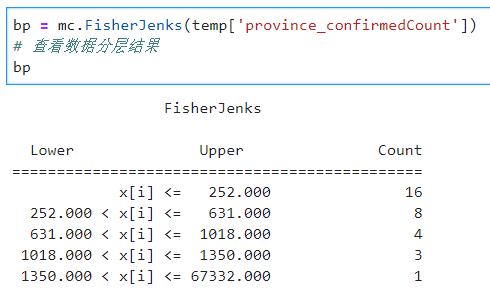 图9
图9
可以看到,在这种方式下,数据的分组较为合理,同样将geopandas.GeoDataFrame.plot()中的参数设置为FisherJenks绘制出图10:
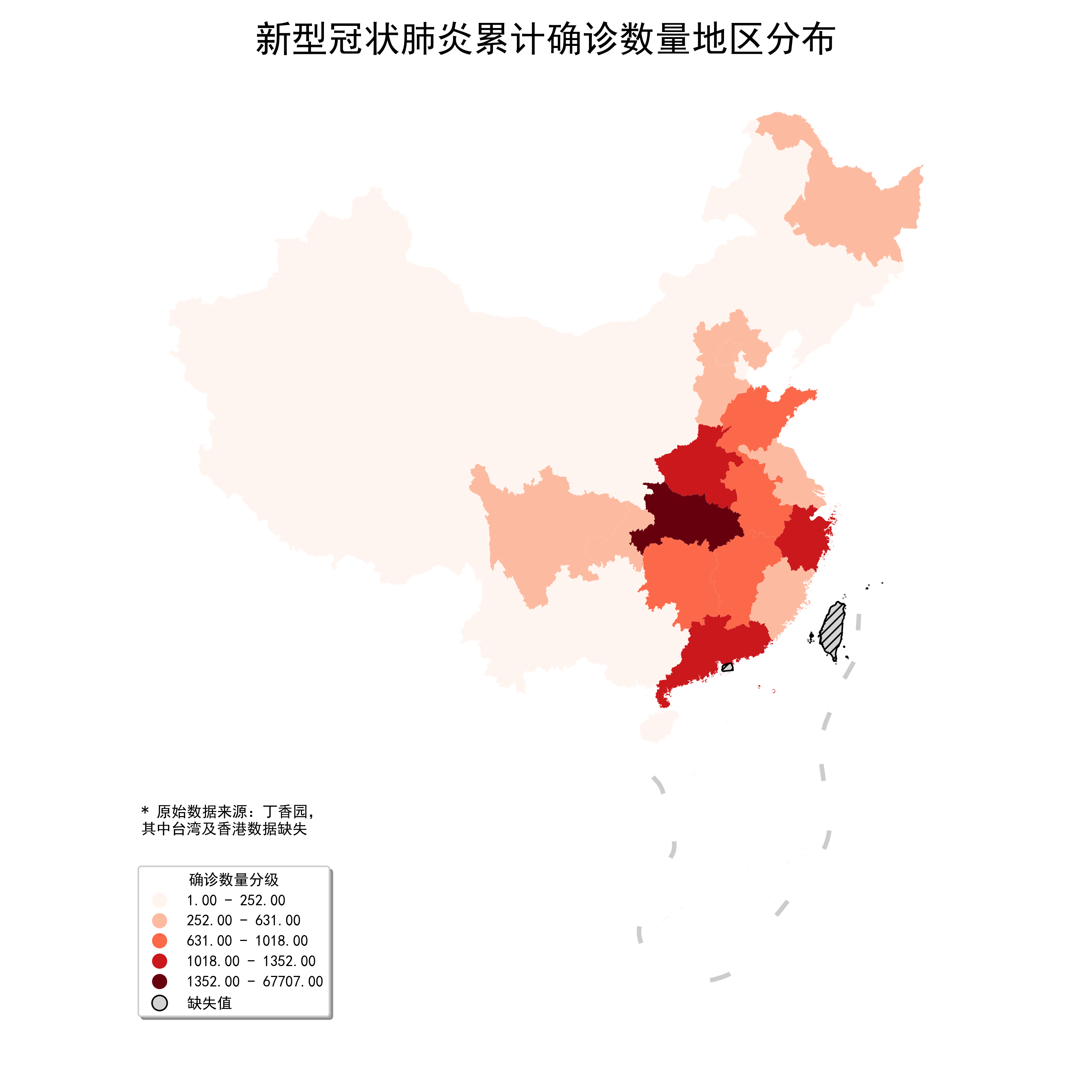 图10
图10
与BoxPlot相比差距还是比较明显,处于第二级严重程度的省份只有河南、广东及浙江,更贴近数据的自然层次结构。
2.1.4 NaturalBreaks
等下!上一小结中的FisherJenks不就是我们俗称的自然断点法吗,怎么又来了个NaturalBreaks?其实我在翻看mapclassify的官方文档看到这里时,也很疑惑,于是我仔细研究了NaturalBreaks对应的源代码,追根溯源,WHAT?,竟然是k-mean算法,而且直接调用的scikit-learn的KMEANS。。。
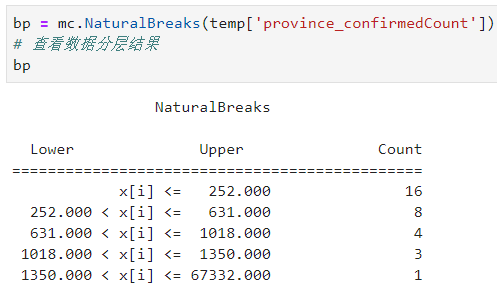 图11
图11
不过也可以理解,毕竟k-means就是在找数据中组内相似度尽可能高且组间差异尽量大的簇,关于k-means我想我就不需要赘述了,毕竟是最基础的数据挖掘算法之一,而scikit-learn里默认的KMEANS使用的k-means++初始方式,只是在原始k-means基础上,修改了后续初始点的概率密度,使得k-means算法更加鲁棒稳定,下面直接来看NaturalBreaks的数据分层结果:
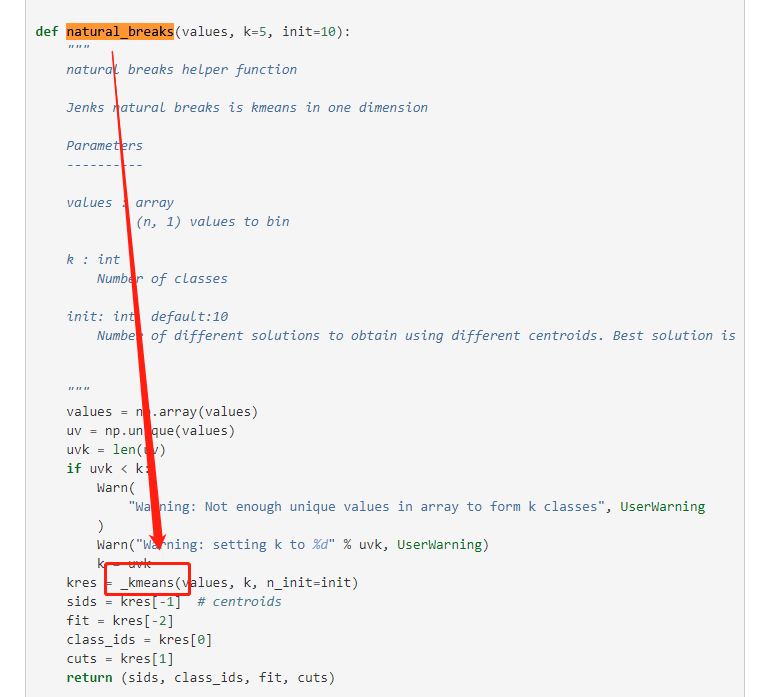 图12
图12
和FisherJenks的结果竟然一样,但如果你多运行几次会发现这个结果不是完全固定的,由于k-means随机初始迭代起点,因此不同次运行的结果可能会有轻微差别(图13),在数据量很大时,基于快速聚类法的NaturalBreaks是较为理想的数据分层选择:
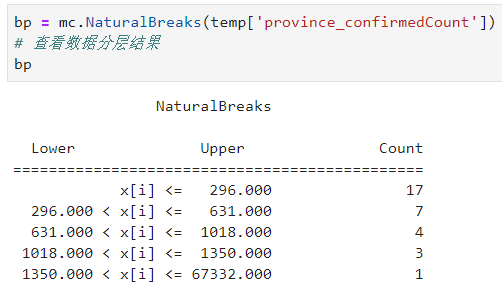 图13
图13
配合geopandas绘图只需要把scheme参数修改为NaturalBreaks即可,因为跟FisherJenks类似,这里就不再赘述。
2.1.5 JenksCaspall
mapclassify中的JenksCaspall本质上为k-medians聚类,其首先根据分层层数\(k\)在数据中找到\(k-1\)个分位数点,将原始数据等分为数量尽可能相同的\(k\)份并以这\(k\)份数据的中位数作为各自的初始点,接着基于k-medians的思想,迭代计算为每个样本点找到与其距离更近的中位数点,并以此重新划分分层以及重新计算各分层中位数点,直至每个数据对应的分层标签不再变化,再将每个分层中数据的最大值作为间断点,下面我们从mapclassify源代码中抽出该部分代码,对其迭代过程可视化,具体的代码较多,请在文章开头的Github仓库中对应本文路径下查看:
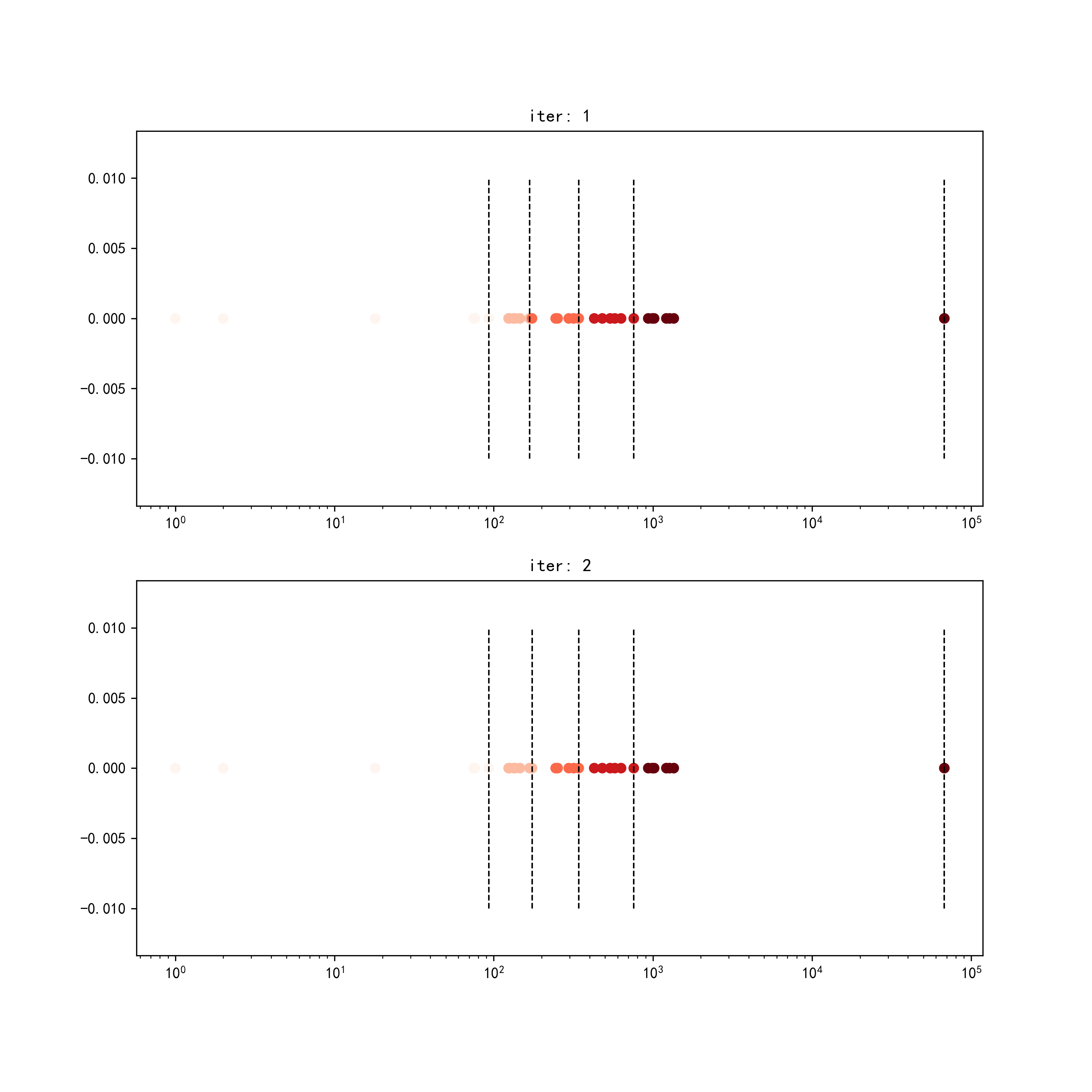 图14
图14
其中颜色区分对应迭代轮次的数据分层归属,虚线代表对应迭代轮次的间断点,仔细可以看出在迭代过程中数据分层的变化情况。
用JenksCaspall数据分层出来的结果,无论数据分布如何,每个分层内部的数据个数都较为均匀,下面我们用JenksCaspall来划分省份疫情严重情况:
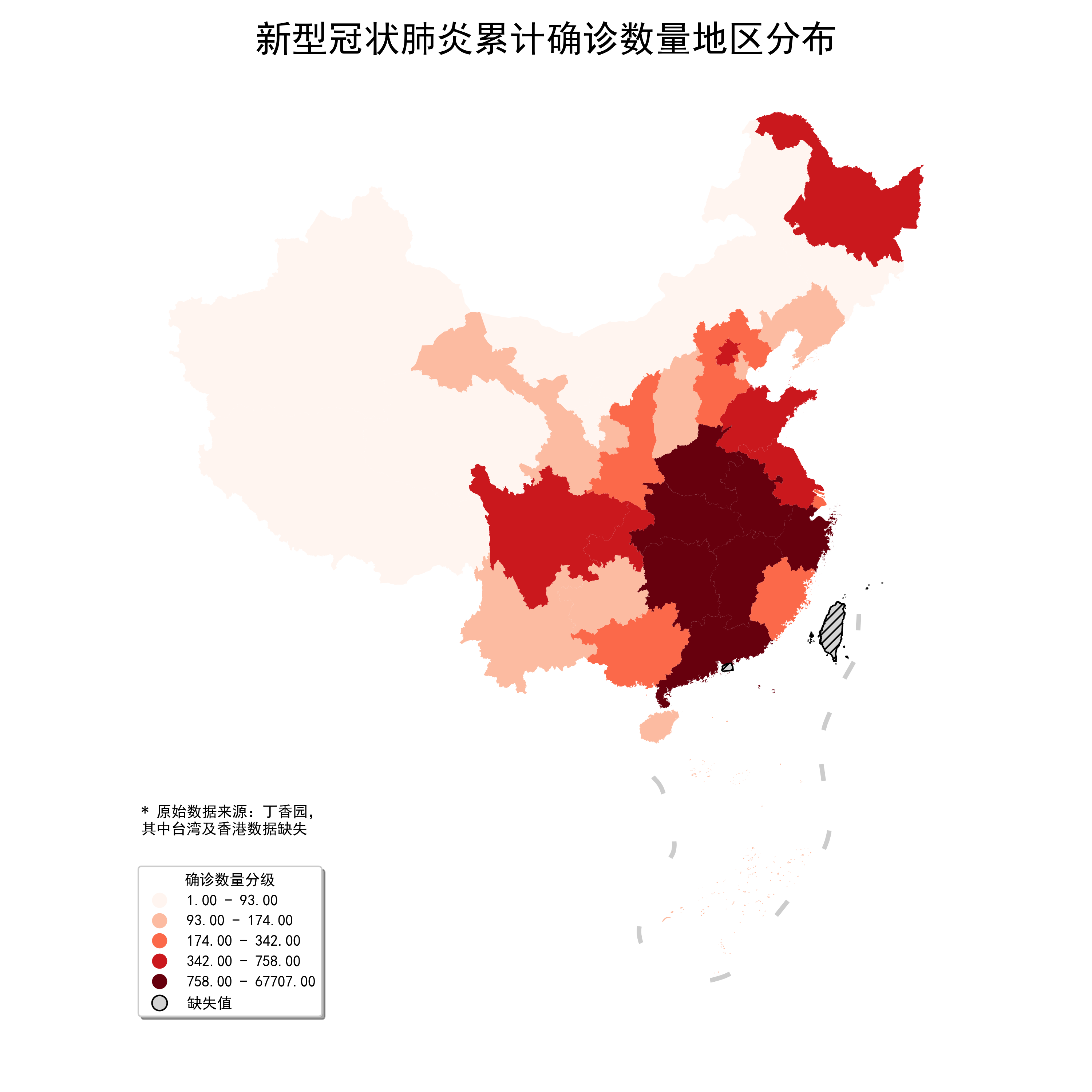 图15
图15
可以看到被分到最严重级别的不再只有湖北省,当你希望数据分层个数较为均匀时,JenksCaspall是个不错的选择。
2.1.6 HeadTailBreaks
HeadTailBreaks是一种较为崭新的数据分层方法,出自Head/Tail Breaks: A New Classification Scheme for Data with a Heavy-Tailed Distribution(https://www.tandfonline.com/doi/abs/10.1080/00330124.2012.700499 ),专门用于对具有重尾特点的数据进行分层,所谓重尾即在整个数据中,较小的值数量往往较多,而最大的位于头部的值数量很少,其数据分布呈现出“尾重头轻”的特点:
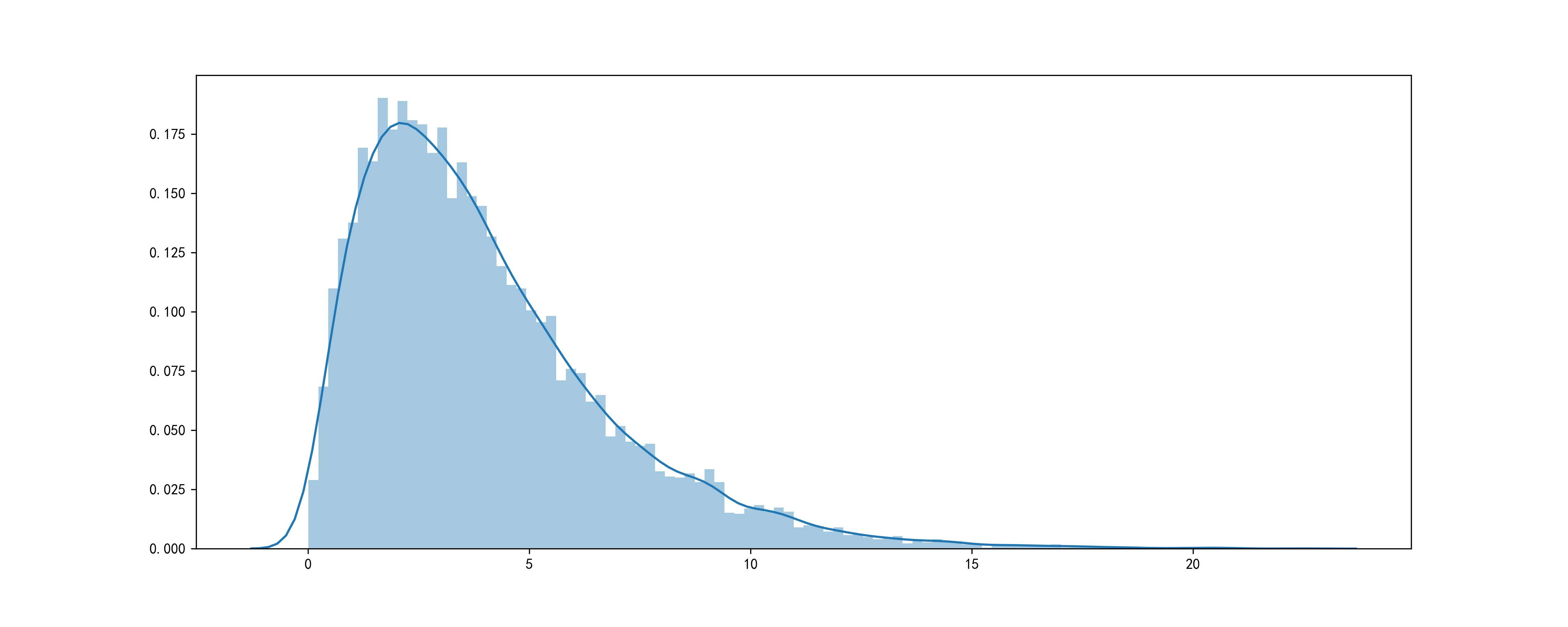 图16
图16
这种典型如人口密度分布数据,数值较低的点往往数量众多,聚集在尾部,形成重尾,HeadTailBreaks的优点是可以尽量在地区分布图中真实反映原始数据的分布特点,如图17(https://sites.google.com/site/thepowerofcartography/head-tail-breaks),左边是FisherJenks,右边是HeadTailBreaks,可以看出,右图相对于左图更好地体现了原始数据的重尾特点,最浅色的图斑数量明显多于次浅色的图斑:
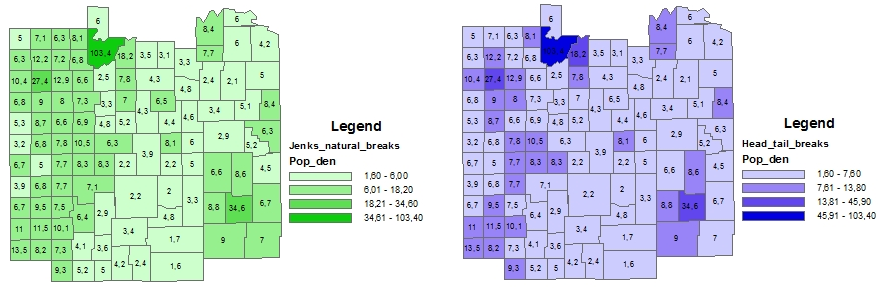 图17
图17
在geopandas中使用时传入scheme='HeadTailBreaks'即可(由于新冠肺炎各省份确诊数量数据尾部和头部最大值之间没有较为连续的中间值过渡,不太适合用此方法故不作演示)。
2.1.7 Quantiles
Quantiles即分位数,原理很简单,根据分位数点对原数据进行等分:
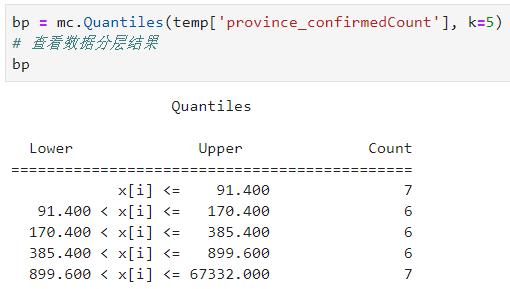 图18
图18
利用Quantiles对确诊数量分组可视化:
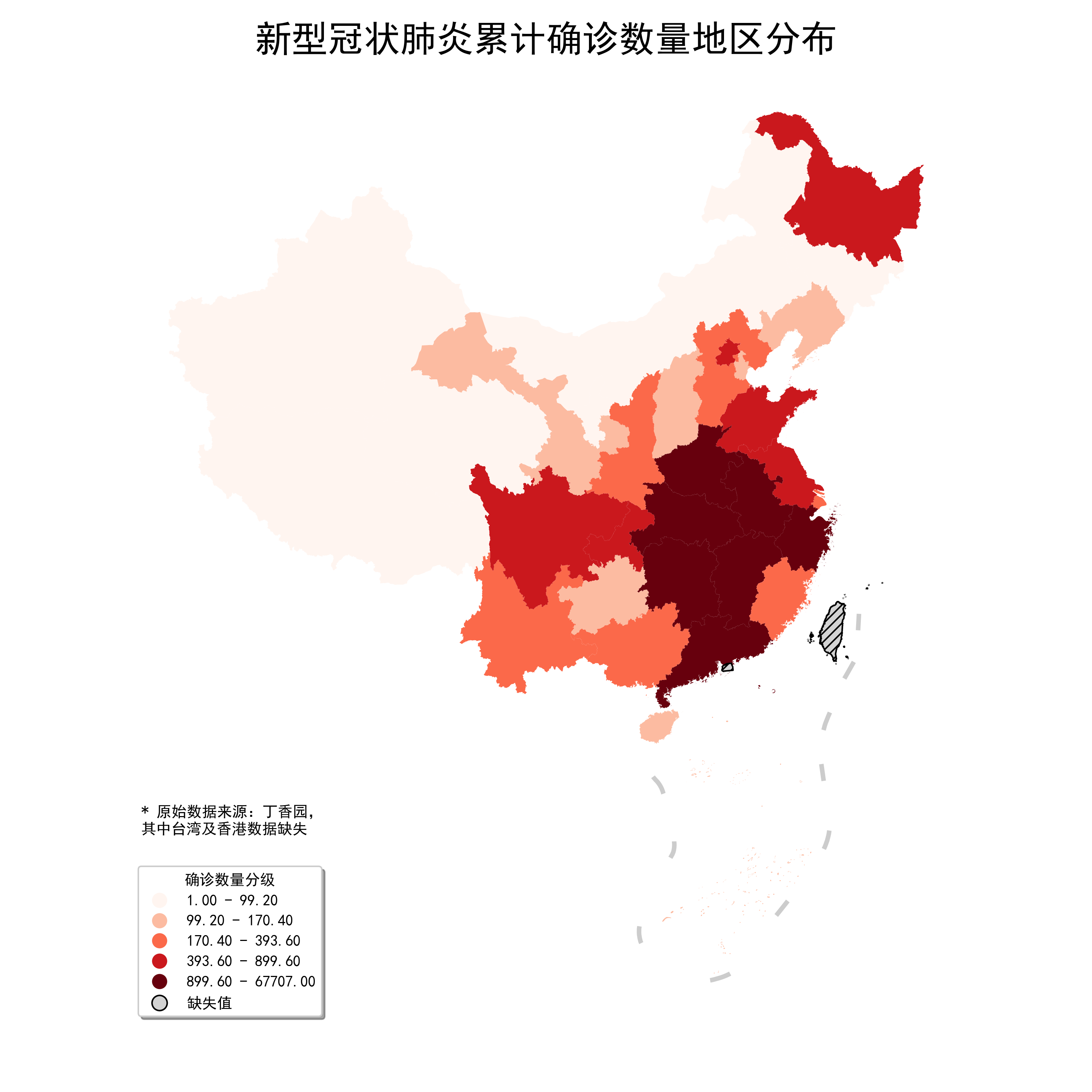 图19
图19
2.1.8 Percentiles
同样是使用分位数对数据进行分层,Percentiles提供了参数pct以允许用户以百分位数的形式传入自定义分隔点,譬如我们将[1, 50, 99, 100]作为pct的传入值,则分组结果如下:
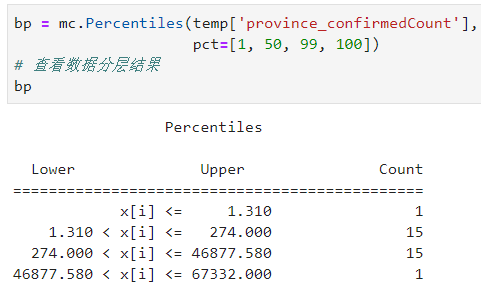 图20
图20
每个传入的百分位点其左边到上一个分隔点为止,包括其本身,将被分到同一组,对应的图像如图21,在geopandas中使用时除了设置scheme='Percentiles'之外,还要在另一个字典型参数classification_kwds中传入{'pct': 百分位数列表}:
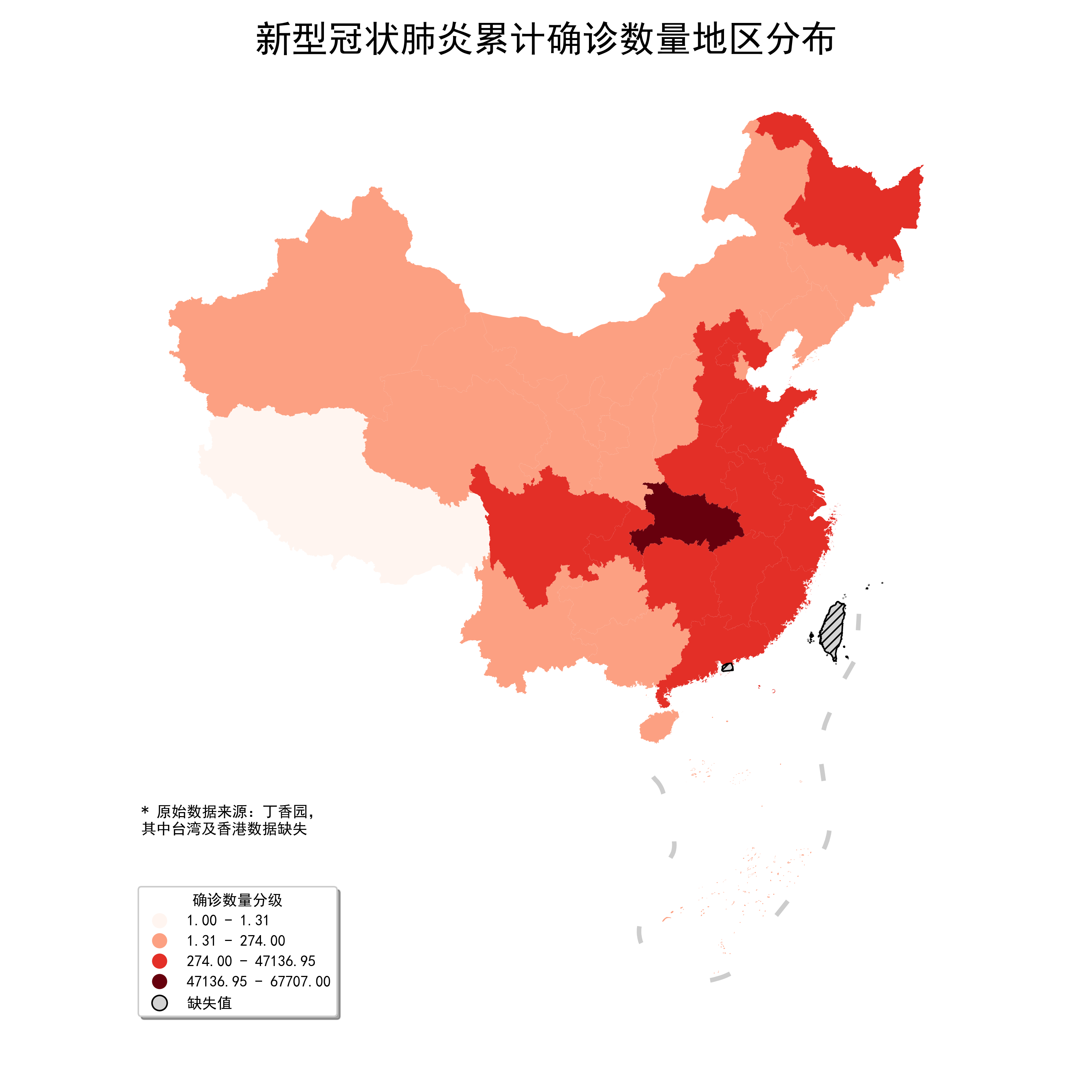 图21
图21
2.1.9 StdMean
StdMean的思想类似前面的箱线图,不同的是箱线图属于非参数方法,而StdMean建立在正态分布为基础的经验法则之上,即对于正态分布而言,68%的数据将分布在距离均值1个标准差之内,95%的数据在2个标准差之内,99.7%的数据在3个标准差之内,即对原始数据标准化之后,根据距离样本均值的不同标准差范围来划分数据,mapclassify中的StdMean默认按照[-2, -1, 1, 2]来划分:
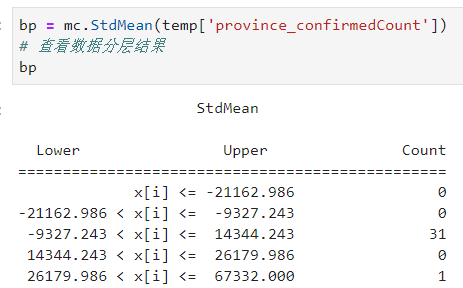 图22
图22
2.1.10 UserDefined
关于数据分层最后要介绍的是自定义分层,即按照用户输入的分隔点来自由划分数据集,譬如我们按照新浪新闻疫情地图的划分方式:
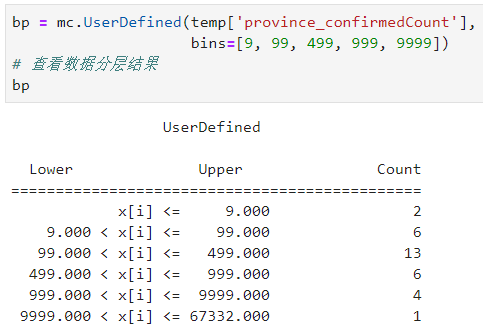 图23
图23
结合geopandas使用时除了设置scheme='UserDefined'以外,还要设置classification_kwds中的bins=分隔点列表:
fig, ax = plt.subplots(figsize=(10, 10))
ax = data_with_geometry.to_crs(albers_proj).plot(ax=ax,
column='province_confirmedCount',
cmap='Reds',
missing_kwds={
"color": "lightgrey",
"edgecolor": "black",
"hatch": "////",
"label": "缺失值"
},
legend=True,
scheme='UserDefined',
classification_kwds={
'bins': [9, 99, 499, 999, 9999]
},
legend_kwds={
'loc': 'lower left',
'title': '确诊数量分级',
'shadow': True
})
ax = nine_lines.geometry.to_crs(albers_proj).plot(ax=ax,
edgecolor='grey',
linewidth=3,
alpha=0.4)
ax.axis('off')
plt.suptitle('新型冠状肺炎累计确诊数量地区分布', fontsize=24) # 添加最高级别标题
plt.tight_layout(pad=4.5) # 调整不同标题之间间距
ax.text(-2800000, 1300000, '* 原始数据来源:丁香园,\n其中台湾及香港数据缺失') # 添加数据说明
fig.savefig('图24.png', dpi=300)
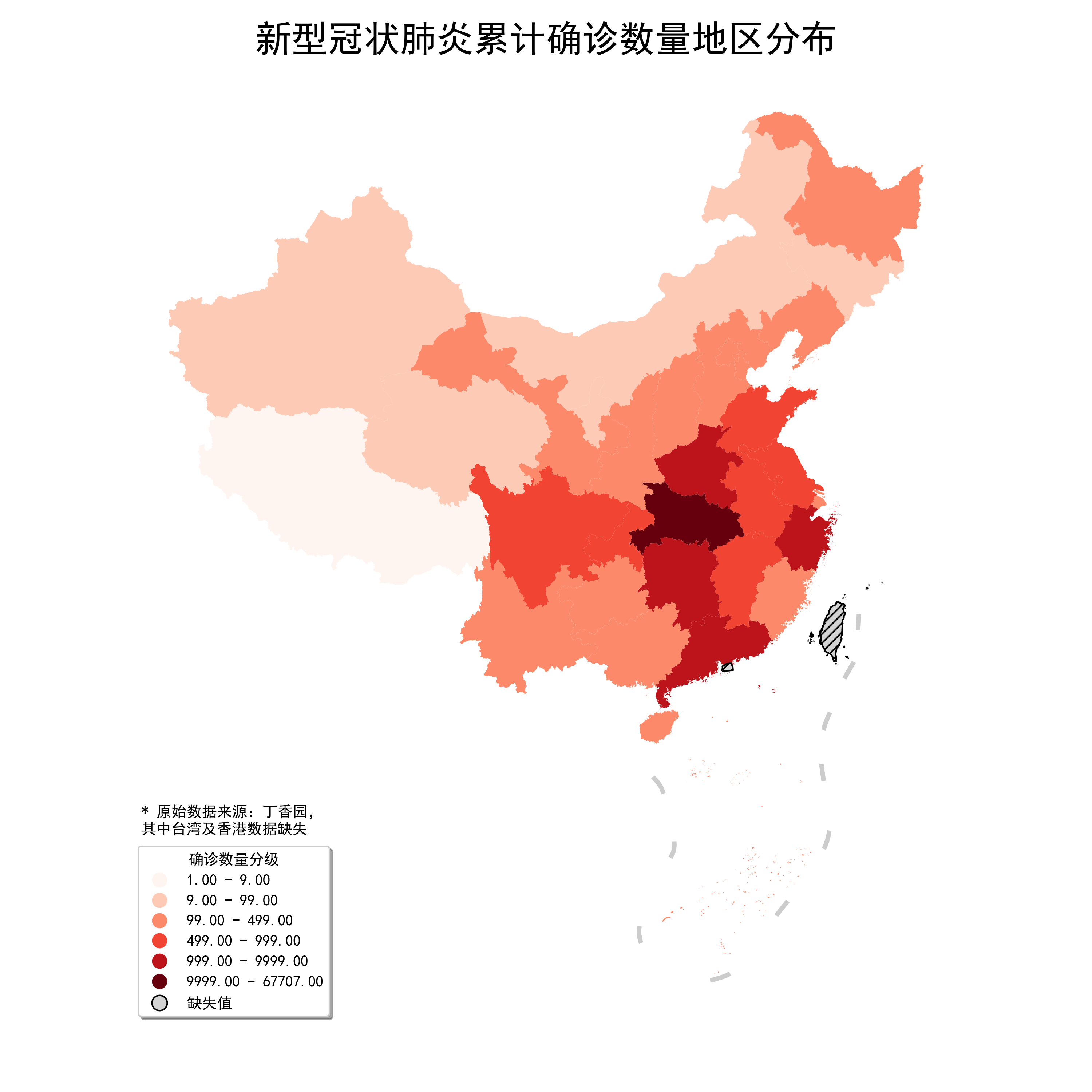 图24
图24
2.2 色彩方案的选择
前面已经详细介绍了数据分层常用的各种方法及使用场景,“分层”的部分做完之后,就到了设色的部分,其实色彩搭配是比较主观的事情,但想要自己创造出美观合理的配色方案并不是容易的事情,下面我们来介绍两种选择配色方案的方法。
2.2.1 基于palettable的配色
下面我要给大家介绍的Python第三方库palettable在我之前关于词云图的一篇文章中介绍stylecloud时介绍过,是专门帮助我们为可视化作品配色的。
palettable不依赖其他三方库,纯Python实现,其强大之处在于内置了数量惊人的经典配色方案,囊括了CartoColors、cmocean、Colorbrewer2、Cubehelix、Light & Bartlein、matplotlib、MyCarta、Scientific、Tableau以及The Wes Anderson Palettes blog中的大量经典配色方案:
palettable.cartocolors.divergingpalettable.cartocolors.qualitativepalettable.cartocolors.sequentialpalettable.cmocean.divergingpalettable.cmocean.sequentialpalettable.colorbrewer.divergingpalettable.colorbrewer.qualitativepalettable.colorbrewer.sequentialpalettable.lightbartlein.divergingpalettable.lightbartlein.sequentialpalettable.matplotlibpalettable.mycartapalettable.scientific.divergingpalettable.scientific.sequentialpalettable.tableaupalettable.wesanderson
使用起来非常简单,譬如如果我们想要使用palettable.cmocean.sequential中的色彩,其中cmocean表示色彩来源,sequential表示连续型色彩,就可以先在对应的示例网页下查看所有方案:
 图25
图25
比如我对其中的Dense方案很中意:
 图26
图26
就可以按照如下方式,先从palettable中导入对应颜色,譬如我们导入Dense_20,20表示其自带的离散色彩数量,并查看其自带的离散色彩RGB值、离散色盘以及连续色盘示例:
from palettable.cmocean.sequential import Dense_20
from pprint import pprint
print('对应离散颜色:')
pprint(Dense_20.colors)
print('离散:')
Dense_20.show_discrete_image()
print('连续:')
Dense_20.show_continuous_image()
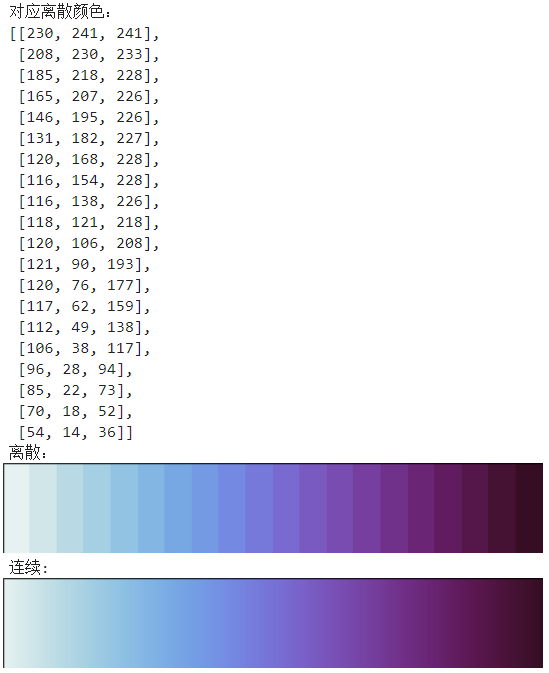 图27
图27
使用.mpl_colormap将其转换为matplotlib可接受的cmap数据结构,作为cmap参数值传入绘图部分即可:
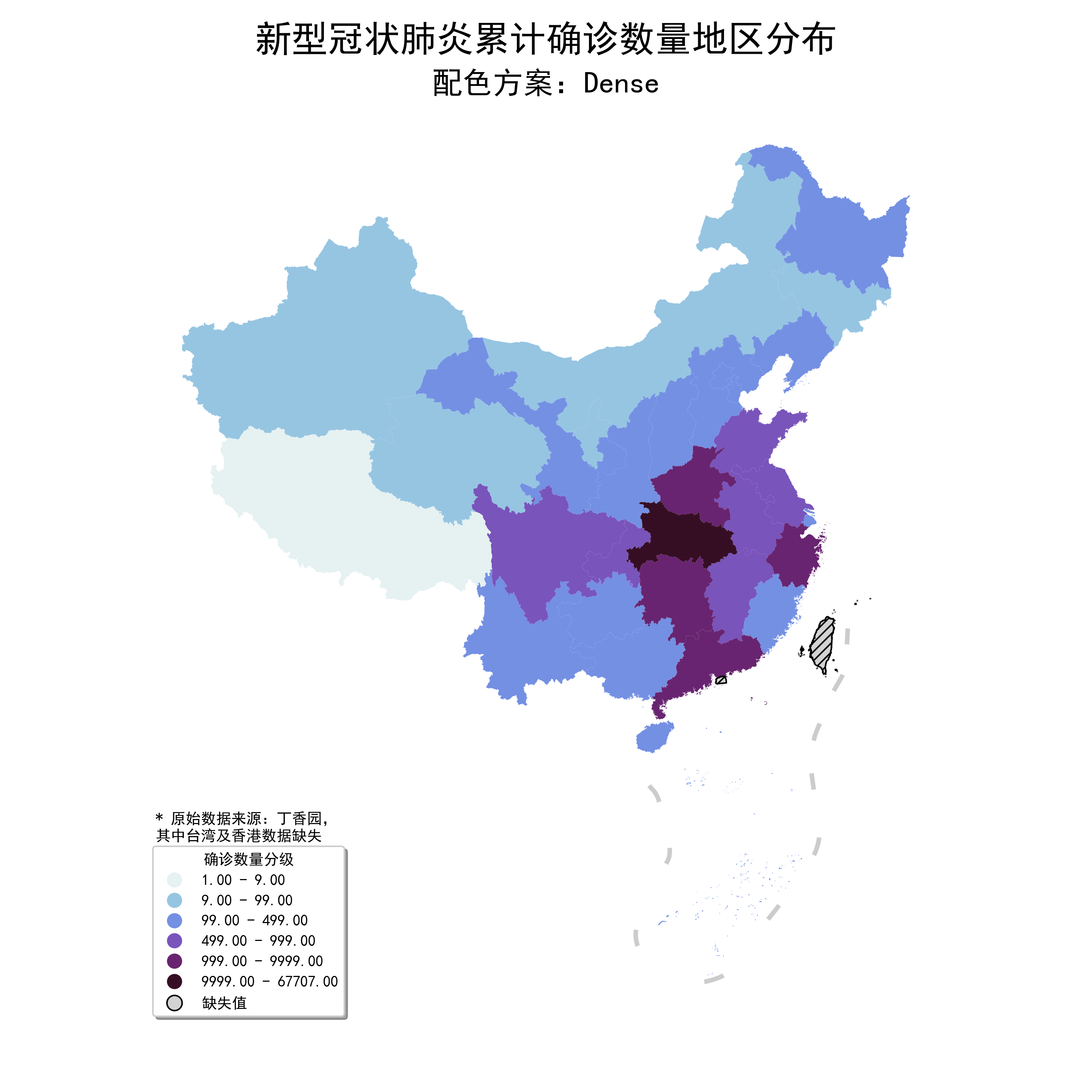 图28
图28
如果想要翻转映射方向,换成Dense_20_r再重复上述操作即可:
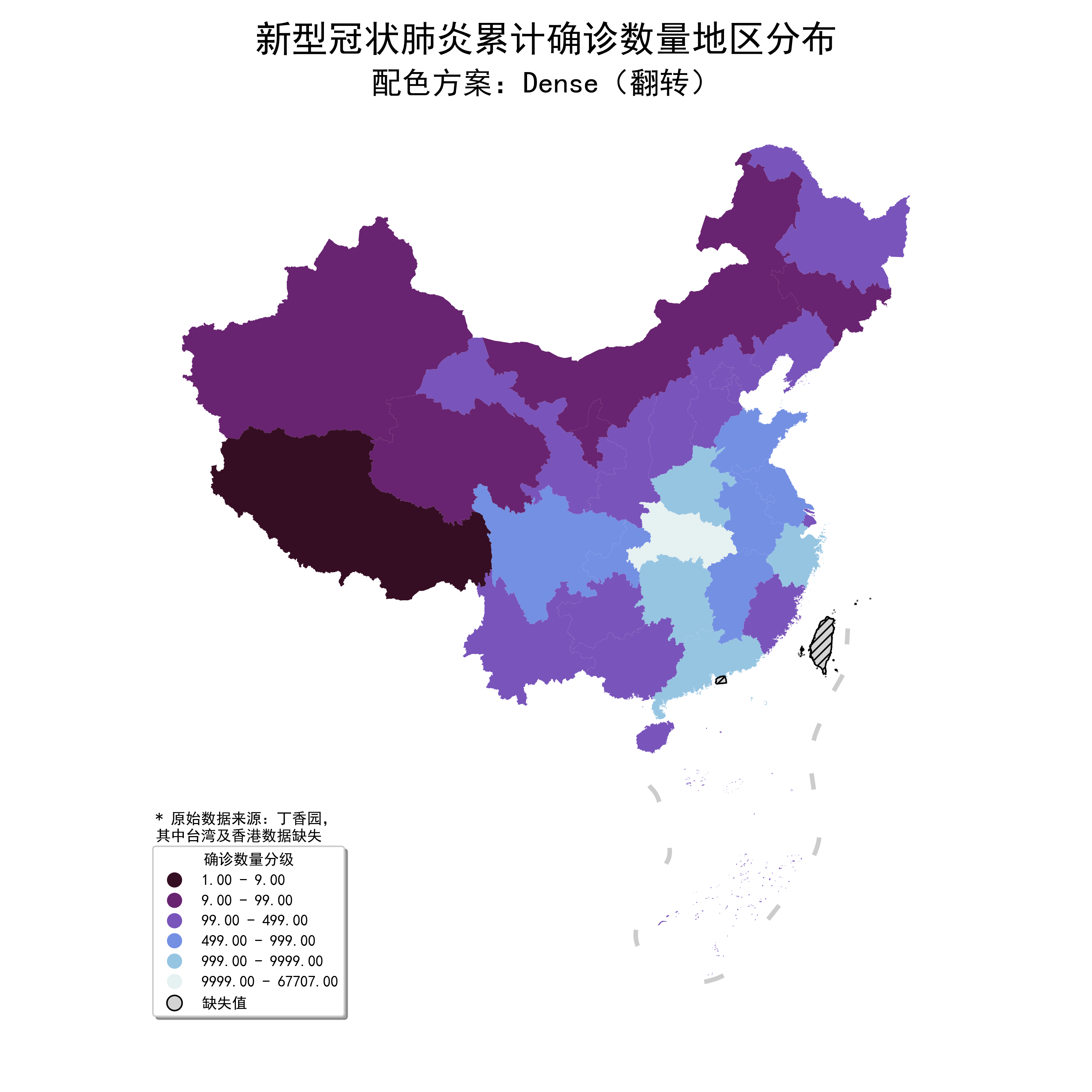 图29
图29
更多palettable自带色彩方案,可以在https://jiffyclub.github.io/palettable/ 下查看探索。
2.2.2 基于图片主色的配色
我们在生活中偶然会看到配色方案让人眼前一亮的海报或画作,这时如果你想将这些作品中的主要颜色也应用到自己的可视化作品上,可以参考我下面的做法,这里以我很喜欢的贾樟柯导演的《一直游到海水变蓝》中文版海报为例:
 图30
图30
思路是抽取所有像素点的RGB三通道值,分别作为三个特征,输入k-means中进行聚类,将聚类数量设置为你想要提取出的主色数量:
from sklearn.cluster import KMeans
# 构建特征
rgb = pd.DataFrame([sea[x][y] for x in range(sea.shape[0]) for y in range(sea.shape[1])],
columns=['r', 'g', 'b'])
# k-means聚类,其中n_clusters表示聚类数量,n_jobs=-1表示开启所有核心并行运算
model = KMeans(n_clusters=5, n_jobs=-1)
model.fit(rgb) # 训练模型
# 提取聚类簇重心,即我们需要的主色,绘制调色板
plt.bar([i for i in range(model.cluster_centers_.__len__())],
height=[1 for i in range(model.cluster_centers_.__len__())],
color=[tuple(c) for c in (model.cluster_centers_ / 255.)],
width=1)
plt.axis('off')
 图31
图31
再来个例子,提取《一直游到海水变蓝》海外版海报主色:
 图32
图32
对应提取到的5种主色如图33:
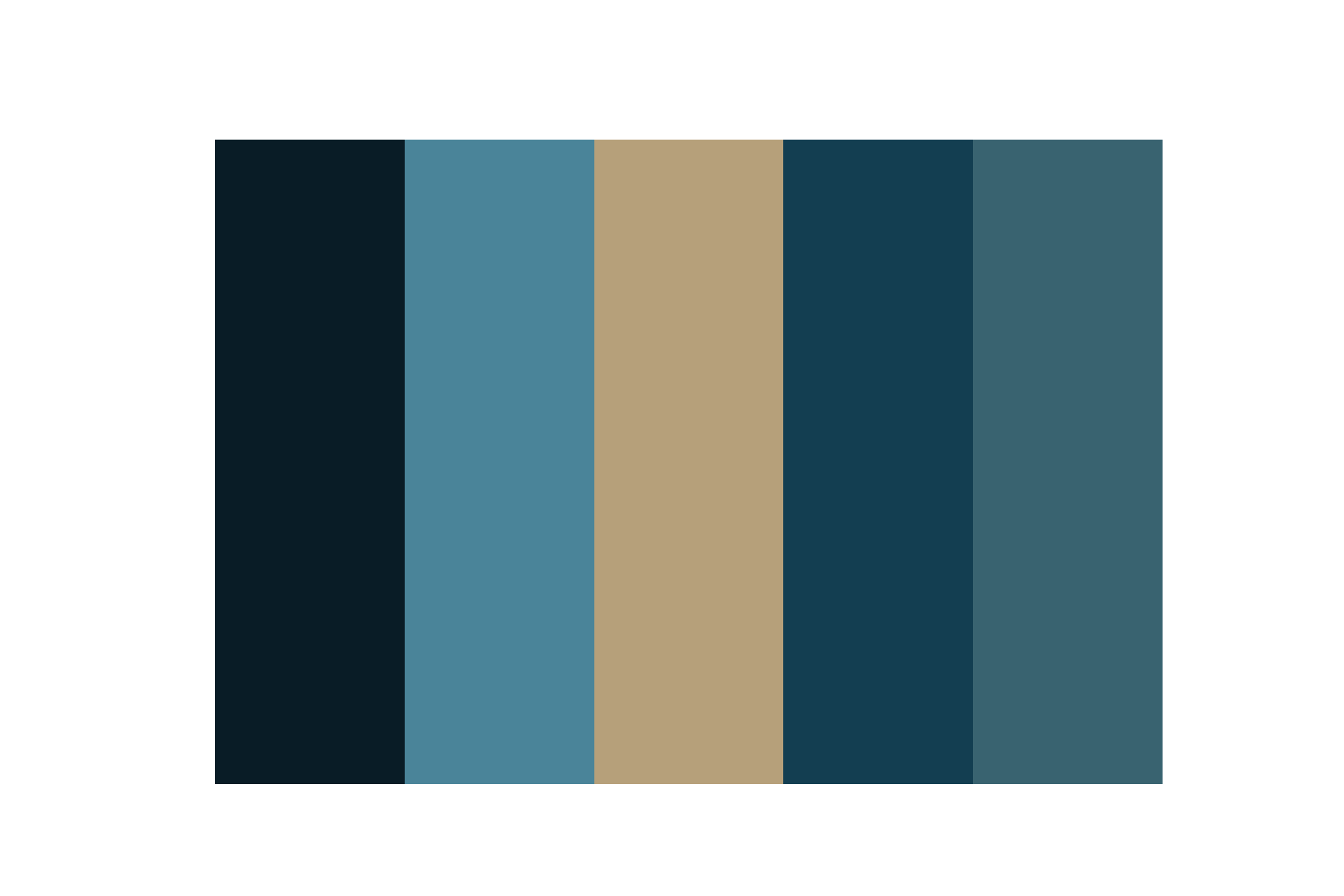 图33
图33
类似的,你可以试着提取你喜爱的平面作品的主色。
以上就是本文的全部内容,如有笔误望指出。
(数据科学学习手札79)基于geopandas的空间数据分析——深入浅出分层设色的更多相关文章
- (数据科学学习手札89)geopandas&geoplot近期重要更新
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 最近一段时间(本文写作于2020-07-1 ...
- (数据科学学习手札146)geopandas中拓扑非法问题的发现、诊断与修复
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,geopandas作为在Pyt ...
- (数据科学学习手札129)geopandas 0.10版本重要新特性一览
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 就在前不久,我们非常熟悉的Python地理 ...
- (数据科学学习手札139)geopandas 0.11版本重要新特性一览
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,就在几天前,geopandas ...
- (数据科学学习手札111)geopandas 0.9.0重要新特性一览
本文示例文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 就在几天前,geopandas释放了其最新正式版 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札82)基于geopandas的空间数据分析——geoplot篇(上)
本文示例代码和数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在前面的基于geopandas的空间数据分 ...
- (数据科学学习手札84)基于geopandas的空间数据分析——空间计算篇(上)
本文示例代码.数据及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在本系列之前的文章中我们主要讨论了g ...
- (数据科学学习手札74)基于geopandas的空间数据分析——数据结构篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 geopandas是建立在GEOS.GDAL.P ...
随机推荐
- TCP并发、GIL、锁
TCP实现并发 #client客户端 import socket client = socket.socket() client.connect(('127.0.0.1',8080)) while T ...
- OA-APP增加空间
第一步:虚拟机增加一块200G的硬盘,使用fdisk -l 命令可以看到增加的硬盘(centos6可能需要重启系统) 第二步:然后对 /dev/sdc进行分区 第三步:创建一个分区 第四步:重新查看磁 ...
- E. Tree Painting(树形换根dp)
http://codeforces.com/contest/1187/problem/E 分析:问得分最高,实际上就是问以哪个节点出发得到的分数最多,而呈现成代码形式就变成了换根,max其得分!!!而 ...
- every|each|the用于姓氏的复数形式|comrades-in-arms|clothes are|word|steel|affect|effect
________ man in the crowd raised his hand. A. All B. Each C. Every D. Both 题目解析 考查代词的用法.此句意思是:人群 ...
- C# 开启线程的几种方式
1.异步委托开启线程 public static void Main(string[] args) { Action<int,int> a=add; a.BeginInvoke(,,nul ...
- Qt QByteArray 与 char* 的转换
QByteArray 转换为 char * char *ch;//不要定义成ch[n]; QByteArray byte; ch = byte.data(); char * 转换为 QByteArra ...
- Qt static关键字全局变量
创建全局变量.h文件 globalvariable.h #ifndef GLOBALVARIABLE_H #define GLOBALVARIABLE_H #include <QImage> ...
- win10安装motionbuilder失败,怎么强力卸载删除注册表并重新安装
一些搞设计的朋友在win10系统下安装motionbuilder失败或提示已安装,也有时候想重新安装motionbuilder的时候会出现本电脑windows系统已安装motionbuilder,你要 ...
- iphone开发学习之路--基本语法
关键字:Objective-C(以下简称O-C)是C语言的一个超集,也就是C语言的语法O-C都是兼容的,所以为了避免冲突O-C的关键字都是以@符号开始的,比如:@class.@public .@try ...
- svn merge Property conflicts
svn merge代码的时候,出现Property conflicts的解决方案.可以参考:http://stackoverflow.com/questions/23677286/conflict-w ...