Lucene 基础知识
1. 数据分类
- 结构化数据: 指具有固定格式或有限长度的数据,如数据库等;
- 非结构化数据: 指不定长或无固定格式的数据, 如邮件,word 文档等磁盘上的文件;
1.1 非结构化数据查询方法
- 顺序扫描法(Serial Scanning)
- 全文检索(Full-text Search)
- 将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,
从而达到搜索相对较快的目的; 这部分从非结构化数据中提取出,然后重新组织的信息,称之为索引, 例如字典. - 这种先建立索引,然后再对索引进行搜索的过程就叫全文检索;
- 将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,
2. Lucene 概述
- Lucene 是 apache 下的一个开放源代码的全文检索引擎工具包,提供了完整的查询引擎和索引引擎,部分文本分析引擎;
2.1 Lucene 实现全文检索的流程
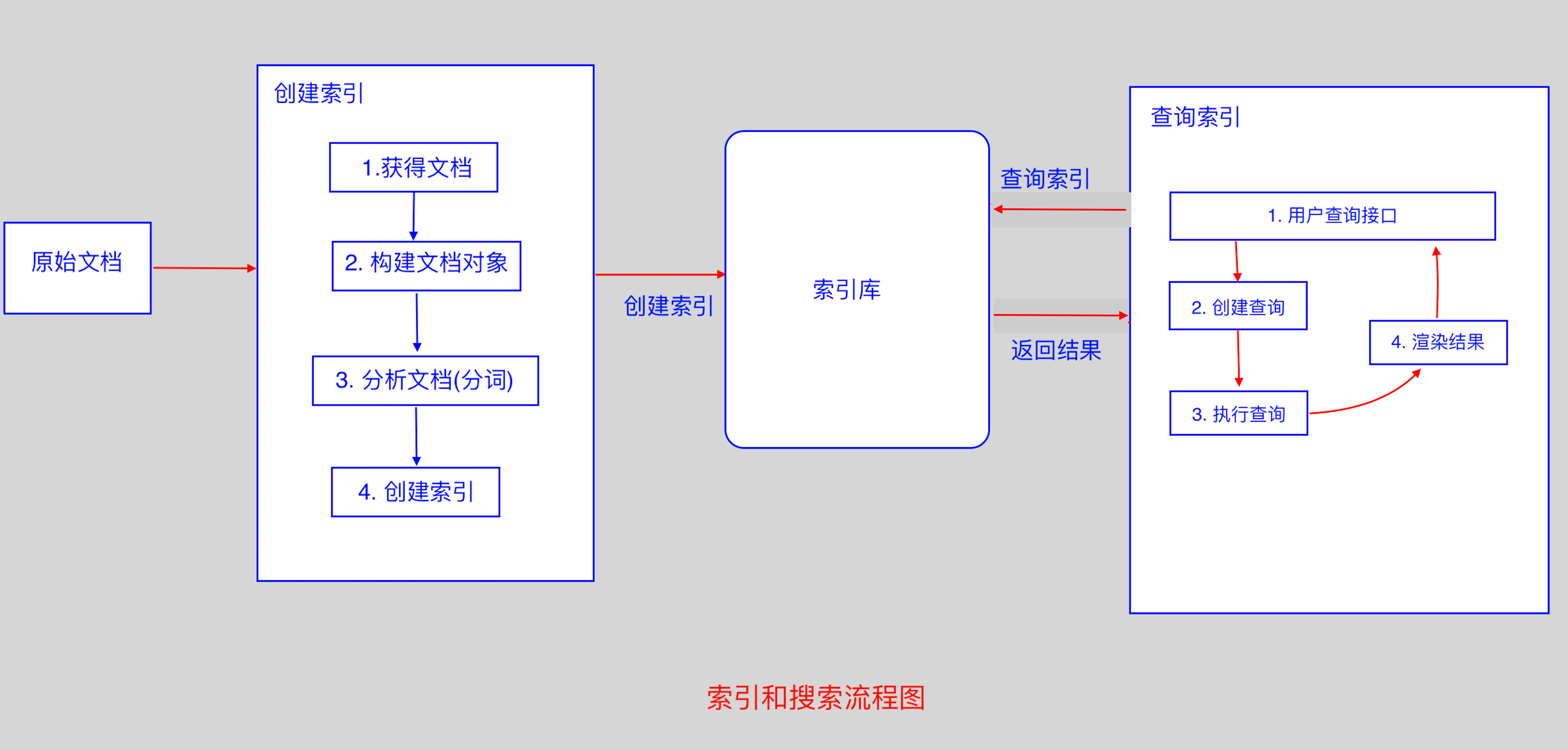
2.2 创建文档对象
- 获取原始内容的目的是为了索引,在索引前,需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),
域中存储内容; - 我们可以将磁盘上的一个文件当成一个 document, Document 中包括一些Field(file_name 文件名称, file_path
文件路径, file_size 文件大小, file_content 文件内容); - 每一个 Document 可以有多个 Field,同一个Document,可以有相同的 Field(域名和域值都相同);
- 每一个 Document 都有一个唯一的编号,就是文档 id;

2.3 分析文档
- 将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词,
将字母转为小写,去除标点符号,去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词; - 每一个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term; term中包含两部分,一部分是文档的域名, 另一部分
是单词的内容; - Field 域的属性
- 是否分析: 是否对域的内容进行分词处理;
- 是否索引: 将 Field 分析后的词或整个 Field 值进行索引,只有建立索引,才能搜索到;
- 是否存储: 存储在文档中的 Field 才可以从 Document 中获取;

2.4 创建索引
- 对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到 Document;
这种索引的结构叫倒排索引结构; - 传统方法是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大,搜索慢;
- 倒排索引结构是根据内容(词语)找文档; 顺序扫描方法是根据文档查找里面的内容;

// 创建索引库// 环境: Lucene 4.10.3// jar 包/** lucene-core-4.10.3* lucene-analyzers-common-4.10.3* lucene-queryparser-4.10.3* commons-io* junit*/// 测试类public class FirstLucene{// 创建索引@Testpublic void testIndex() throws Exception{// 1. 创建一个 indexWriter 对象 new IndexWriter(arg0, arg1);// arg0: 指定索引库的存放位置(Directory 对象)// arg1: config// FSDirectory: File System Directory : 磁盘存储// Directory directory = new RAMDirectory(); 保存索引到内存中Directory directory = FSDirectory.open(new File("/Users/用户名/Documents/dic"));// 指定一个分词器Analyzer analyzer = new StandardAnalyzer();IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3,analyzer);// 创建 indexWriter 对象IndexWriter indexWriter = new IndexWriter(directory, config);// 指定原始文件的目录File f = new File("/Users/用户名/Documents/searchsource");File[] listFiles = f.listFiles();for(File file : listFiles){// 创建文档对象Document document = new Document();// 文件名称String file_name = file.getName();Field fileNameField = new TextField("fileName",file_name,Store.YES);// 文件大小long file_size = FileUtils.sizeOf(file);Field fileSizeField = new LongField("fileSize",file_size, Store.YES);// 文件路径String file_path = file.getPath();Field filePathField = new StoredField("filePath",file_path);// 文件内容String file_content = FileUtils.readFileToString(file);Field fileContentField = new TextField("fileContent",file_content,Store.YES);document.add(fileNameField);document.add(fileSizeField);document.add(filePathField);document.add(fileContentField);// 使用indexWriter 对象将 document 对象写入索引库,此过程将 索引和document 对象写入索引库indexWriter.addDocument(document);}// 关闭 IndexWriter 对象indexWriter.close();}}// 查看分词完成后的文件: Lukejava -jar lukeall-4.10.3.jar
3. 查询索引
3.1 创建查询
- 用户输入查询关键字执行搜索前,需要先创建一个查询对象,查询对象中可以指定查询要搜索的 Field 文档域,查询关键字等,
查询对象会生成具体的查询语法; - 例如:
fileName:lucene: 表示要搜索Field域的内容为"lucene"的文档;
3.2 执行查询
- 根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表;
- 比如:
fileName:lucene的搜索过程: 在索引上查找域为 fileName, 并且关键字为Lucene的term, 并根据 term 找到
文档 id 列表;
3.3 渲染结果
3.4 IndexSearcher 搜索方法

// 查询索引/** 步骤:* 1. 创建一个 Directory 对象,用于指定索引库存放的位置;* 2. 创建一个 indexReader 对象, 需要指定 Directory 对象, 用于读取索引库中的文件;* 3. 创建一个 indexSearcher 对象, 需要指定 indexReader 对象;* 4. 创建一个 TermQuery 对象,指定查询的域和查询的关键词* 5. 执行查询* 6. 返回查询结果,遍历查询结果并输出;* 7. 关闭 indexReader*/public class IndexSearchTest{@Testpublic void testIndexSearch() throws Exception{Directory directory = FSDirectory.open(new File("/Users/用户名/Documents/dic"));IndexReader indexReader = DirectoryReader.open(directory);IndexSearcher indexSearcher = new IndexSearcher(indexReader);// 创建一个 TermQuery 对象,指定查询的域和查询的关键词Query query = new TermQuery(new Term("fileName","java"));// 执行查询TopDocs topDocs = indexSearcher.search(query,2);SocreDoc[] scoreDocs = topDocs.scoreDocs;for(ScoreDoc scoreDoc : scoreDocs){// 获取文档 idint docID = scoreDoc.doc;// 通过id,从索引中读取出对应的文档Document document = indexReader.document(docID);// 获取文件名称System.out.println(document.get("fileName"));// 获取文件内容System.out.println(document.get("fileContent"));// 文件路径System.out.println(document.get("filePath"));// 文件大小System.out.println(document.get("fileSize"));System.out.println("=======================");}indexReader.close();}}
4. 支持中文分词器(IKAnalyzer)
4.1 分词器(Analyzer)的执行过程
- 从一个 Reader 字符流开始,创建一个基于 Reader 的 Tokenizer分词器,经过三个 TokenFilter,生成语汇单元 Tokens;
- 如果要查看分词器的分词效果,只需要看
Tokenstream中的内容就可以了,每个分词器都有一个方法tokenStream,返回一个
tokenStream对象;

// 查看标准分词器的分词效果public void testTokenStream() throws Exception {//创建一个标准分析器对象Analyzer analyzer = new StandardAnalyzer();//获得tokenStream对象//第一个参数:域名,可以随便给一个//第二个参数:要分析的文本内容TokenStream tokenStream = analyzer.tokenStream("test","The Spring Framework provides a comprehensive"+"programming and configuration model.");//添加一个引用,可以获得每个关键词CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);//添加一个偏移量的引用,记录了关键词的开始位置以及结束位置OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);//将指针调整到列表的头部tokenStream.reset();//遍历关键词列表,通过incrementToken方法判断列表是否结束while(tokenStream.incrementToken()) {//关键词的起始位置System.out.println("start->" + offsetAttribute.startOffset());//取关键词System.out.println(charTermAttribute);//结束位置System.out.println("end->" + offsetAttribute.endOffset());}tokenStream.close();}
5.索引库的维护
// 索引库维护: 就是索引的增删改查public class LuceneManager{public IndexWriter getIndexWriter(){Directory directory = FSDirectory.open(new File("/Users/用户名/Documents/dic"));Analyzer analyzer = new StandardAnalyzer();IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);return new IndexWriter(directory,config);}// 全删除@Testpublic void testAllDelete() throws Exception{IndexWriter indexWriter = getIndexWriter();indexWriter.deleteAll();indexWriter.close();}// 根据条件删除@Testpublic void testDelete() throws Exception{IndexWriter indexWriter = getIndexWriter();Query query = new TermQuery(new Term("fileName","apache"));indexWriter.deleteDocuments(query);indexWriter.close();}// 修改@Testpublic void testUpdate() throws Exception{IndexWriter indexWriter = getIndexWriter();Document doc = new Document();doc.add(new TextField("fileN","测试文件名",Store.YES));doc.add(new TextField("fileC","测试文件内容",Store.YES));// 将 lucene 删除,然后添加 docindexWriter.updateDocument(new Term("fileName","lucene"),doc, new IKAnalyzer());indexWriter.close();}}
6. 索引库查询
- 对要搜索的信息创建 Query 查询对象,Lucene会根据 Query 查询对象生成最终的查询语法;
- 可通过两种方法创建查询对象:
- 使用 Lucene 提供的 Query子类;
- 使用 QueryParse 解析查询表达式, 需要加入
lucene-queryparser-4.10.3.jar
public class LuceneManager{// 获取 IndexSearcherpublic IndexSearcher getIndexSearcher() throws Exception{Directory directory = FSDirectory.open(new File("/Users/用户名/Documents/dic"));IndexReader indexReader = DirectoryReader.open(directory);return new IndexSearcher(indexReader);}// 获取执行结果public void printResult(IndexSearcher indexSearcher, Query query) throws Exception{TopDocs topDocs = indexSearcher.search(query,10);ScoreDoc[] scoreDocs = topDocs.scoreDocs;for(ScoreDoc scoreDoc : scoreDocs){int doc = scoreDoc.doc;Document document = indexSearcher.doc(doc);String fileName = docment.get("fileName");System.out.println(fileName);String fileContent = document.get("fileContent");System.out.println(fileContent);String fileSize = document.get("fileSize");System.out.println(fileSize);String filePath = document.get("filePath");System.out.println(filePath);System.out.println("======================");}}// 查询所有@Testpublic void testMatchAllDocsQuery() throws Exception{IndexSearcher indexSearcher = getIndexSearcher();Query query = new MatchAllDocsQUery();printResult(indexSearcher,query);// 关闭资源indexSearcher.getIndexReader().close();}// 精准查询(TermQuery)// NumericRangeQuery(按数值范围查询)@Testpublic void testNumericRangeQuery() throws Exception{IndexSearcher indexSearcher = getIndexSearcher();/** 创建查询* 参数: 域名, 最小值, 最大值, 是否包含最小值, 是否包含最大值*/Query query = NumericRangeQuery.newLongRange("fileSize",100L,200L,true,true);// 执行查询printResult(query,indexSearcher);}// BooleanQuery(组合查询)public void testBooleanQuery() throws Exception{IndexSearcher indexSearcher = getIndexSearcher();BooleanQuery booleanQuery = new BooleanQuery();Query query1 = new TermQuery(new Term("fileName","apache"));Query query2 = new TermQuery(new Term("fileName","lucene"));// Occur.MUST: 必须满足此条件, 相当于 and// Occur.SHOULD: 应该满足此条件, 但是不满足也可以, 相当于 or// Occur.MUST_NOT: 必须不满足, 相当于 notbooleanQuery.add(query1,Occur.SHOULD);booleanQuery.add(query2,Occur.SHOULD);printResult(indexSearcher,booleanQuery);// 关闭资源indexSearcher.getIndexReader().close();}// 使用 QueryParse 解析查询表达式@Testpublic void testQueryParser() throws Exception{IndexSearcher indexSearcher = getIndexSearcher();// 创建 QueryParser 对象, 其中 arg0: 表示默认查询域, arg1: 分词器QueryParser queryParser = new QueryParser("fileName",new IKAnalyzer());// 此时,表示使用默认域: fileName// Query query = queryParser.parse("apache");// 表示查询 fileContent 域Query query = queryParser.parse("fileContent:apache");printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}// 指定多个默认搜索域@Testpublic void testMultiFieldQueryParser() throws Exception{IndexSearcher indexSearcher = getIndexSearcher();// 指定多个默认搜索域String[] fields = {"fileName", "fileContent"};// 创建 MultiFiledQueryParser 对象MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new IKAnalyzer());Query query = queryParser.parse("apache");// 输出查询条件System.out.println(query);// 执行查询printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}}
Lucene 基础知识的更多相关文章
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- Elasticsearch基础知识要点QA
前言:本文为学习整理实践他人成果的记录型博客.在此统一感谢各原作者,如果你对基础知识不甚了解,可以通过查看Elasticsearch权威指南中文版, 此处注意你的elasticsearch版本,版本不 ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- JAVAEE——Lucene基础:什么是全文检索、Lucene实现全文检索的流程、配置开发环境、索引库创建与管理
1. 学习计划 第一天:Lucene的基础知识 1.案例分析:什么是全文检索,如何实现全文检索 2.Lucene实现全文检索的流程 a) 创建索引 b) 查询索引 3.配置开发环境 4.创建索引库 5 ...
- elasticsearch基础知识杂记
日常工作中用到的ES相关基础知识和总结.不足之处请指正,会持续更新. 1.集群的健康状况为 yellow 则表示全部主分片都正常运行(集群可以正常服务所有请求),但是 副本 分片没有全部处在正常状态. ...
- Elasticsearch基础知识学习
概要 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为Ap ...
- .NET面试题系列[1] - .NET框架基础知识(1)
很明显,CLS是CTS的一个子集,而且是最小的子集. - 张子阳 .NET框架基础知识(1) 参考资料: http://www.tracefact.net/CLR-and-Framework/DotN ...
- RabbitMQ基础知识
RabbitMQ基础知识 一.背景 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然 ...
- Java基础知识(壹)
写在前面的话 这篇博客,是很早之前自己的学习Java基础知识的,所记录的内容,仅仅是当时学习的一个总结随笔.现在分享出来,希望能帮助大家,如有不足的,希望大家支出. 后续会继续分享基础知识手记.希望能 ...
随机推荐
- LeetCode——Search for a Range
Description: Given a sorted array of integers, find the starting and ending position of a given targ ...
- 170713、springboot编程之多数据源切换
我们在开发过程中可能需要用到多个数据源,我们有一个项目(MySQL)就是和别的项目(SQL Server)混合使用了.其中SQL Server是别的公司开发的,有些基本数据需要从他们平台进行调取,那么 ...
- 徐州网络赛A-Hard To Prepare【dp】【位运算】【快速幂】
After Incident, a feast is usually held in Hakurei Shrine. This time Reimu asked Kokoro to deliver a ...
- Servlet------>jsp EL表达式
取值: ${data}------>pageContext.findAttribute("data"); ${data.name}------>data.getName ...
- SpringCloud 进阶之Zuul(路由网关)
1. Zuul(路由网关) Zuul 包含了对请求的路由和过滤两个最主要的功能; 路由功能:负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础; 过滤功能:负责对请求的处理过程进行干 ...
- 【Loadrunner】使用LoadRunner上传及下载文件
使用LoadRunner上传及下载文件 1)LoadRunner上传文件 web_submit_data("importStudent.do", "Action=http ...
- POJ3233:Matrix Power Series(矩阵快速幂+二分)
http://poj.org/problem?id=3233 题目大意:给定矩阵A,求A + A^2 + A^3 + … + A^k的结果(两个矩阵相加就是对应位置分别相加).输出的数据mod m.k ...
- POJ1006——Biorhythms(中国剩余定理)
Biorhythms Description人生来就有三个生理周期,分别为体力.感情和智力周期,它们的周期长度为23天.28天和33天.每一个周期中有一天是高峰.在高峰这天,人会在相应的方面表现出色. ...
- 文本IO 二进制IO
一.文本IO 字符流 使用PrintWriter写入文件后,必须调用close(),否则数据不能正确保存在文件中. Scanner的next()读取一个由分隔符分隔的字符串,nextLine()读取 ...
- [golang note] 工程组织
golang项目目录结构 <golang_proj> ├─README ├─AUTHORS ├─<bin> ...