三、hdfs的JavaAPI操作
下文展示Java的API如何操作hdfs,在这之前你需要先安装配置好hdfs
https://www.cnblogs.com/lay2017/p/9919905.html
依赖
你需要引入依赖如下
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.0</version>
</dependency>
配置修改
core-site.xml
由于Java访问hdfs始终都要通过nameNode来拿到dataNode节点,所以nameNode要配置为可对外访问的地址,不能是localhost了
我们更改core-site.xml配置为虚拟机IP即可,我们虚拟机要作为类似服务器的方式来使用,所以虚拟机网络配置要是桥接模式,这样才有独立IP,并可对宿主机提供访问
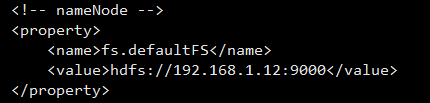
注:如果你不希望使用IP而是希望像使用域名一样来配置,如:
<property>
<name>fs.defaultFS</name>
<value>master:9000</value>
</property>
你可以通过配置虚拟机hostname为master,并配置与IP的解析映射,宿主机配置IP的解析即可,参考:
https://www.cnblogs.com/lay2017/p/9953371.html
hdfs-site.xml
另外,对于服务端文件的操作默认会检查权限,所以为了方便,你可以配置hdfs-site.xml关闭
<!-- permissions -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
示例代码
下面是Java示例代码,对外的API主要是由FileSystem这个抽象类来提供,它的java docs在:http://hadoop.apache.org/docs/stable/api/org/apache/hadoop/fs/FileSystem.html
你可以查看Java docs阅读更多地API,这里演示常用的上传、下载、删除、创建文件夹、列出文件、列出文件和文件夹
package cn.lay.demo.hdfs; import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*; import java.io.FileOutputStream;
import java.io.IOException; /**
* @Description hdfs java api操作示例
* @Author lay
* @Date 2018/11/8 0:04
*/
public class HdfsJavaApiDemo {
// nameNode节点地址
private static final String NAME_NODE = "hdfs://192.168.1.12:9000";
private static Configuration configuration;
private static FileSystem fileSystem;
// 本地文件
private static final String LOCAL_FILE = "C:\\Users\\admin\\Desktop\\helloHdfs.txt";
// 远程文件
private static final String REMOTE_FILE = "/helloHdfs.txt";
// 下载文件
private static final String DOWNLOAD_FILE = "C:\\Users\\admin\\Desktop\\download.txt";
// 远程的文件夹
private static final String REMOTE_DIR = "/newDir/newChildDir"; static {
configuration = new Configuration();
configuration.set("fs.defaultFS", NAME_NODE);
try {
fileSystem = FileSystem.get(configuration);
} catch (IOException e) {
e.printStackTrace();
}
} public static void main(String[] args) {
try {
// upload();
// download();
// remove();
// mkdirs();
// listFiles();
listStatus();
} catch (IOException e) {
e.printStackTrace();
}
} /**
* 文件上传
* @throws IOException
*/
public static void upload() throws IOException {
fileSystem.copyFromLocalFile(new Path(LOCAL_FILE), new Path(REMOTE_FILE));
} /**
* 文件下载
* @throws IOException
*/
public static void download() throws IOException {
// fileSystem.copyToLocalFile(new Path(REMOTE_FILE), new Path(DOWNLOAD_FILE));
FSDataInputStream fsDataInputStream = fileSystem.open(new Path(REMOTE_FILE));
FileOutputStream fileOutputStream = new FileOutputStream(DOWNLOAD_FILE);
IOUtils.copy(fsDataInputStream, fileOutputStream);
fsDataInputStream.close();
fileOutputStream.flush();
fileOutputStream.close();
} /**
* 删除
* @throws IOException
*/
public static void remove() throws IOException {
// 递归
boolean recursive = true;
fileSystem.delete(new Path(REMOTE_FILE), recursive);
} /**
* 创建文件夹
* @throws IOException
*/
public static void mkdirs() throws IOException {
fileSystem.mkdirs(new Path(REMOTE_DIR));
} /**
* 列出文件内容
* @throws IOException
*/
public static void listFiles() throws IOException {
RemoteIterator<LocatedFileStatus> fileStatusList = fileSystem.listFiles(new Path("/"), true);
while (fileStatusList.hasNext()) {
LocatedFileStatus fileStatus = fileStatusList.next();
String path = fileStatus.getPath().toString();
System.out.println("path:" + path);
}
} /**
* 列出文件夹和文件
* @throws IOException
*/
public static void listStatus() throws IOException {
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));
for (FileStatus f : fileStatuses) {
System.out.println("path:" + f.getPath());
}
}
}
注意:文件下载采用了IO流的方式,而不是copyToLocalFile方法,因为该方法需要本地hadoop的环境配置,否则你会看到类似这样的错误:
java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset
并且下载的文件总是0byte,如果遇到这样的问题你可以在hdfs服务端查看目录和文件检查服务端文件有没有问题,命令:
hadoop fs -ls /
其它API
当然hdfs也提供http的方式去访问,可以参考:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/WebHDFS.html
官方文档的HDFS示例讲解是基于C语言的:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/LibHdfs.html
当然你可以在hadoop的Javadocs里面阅读,不过不太方便因为你需要了解它的包和类:http://hadoop.apache.org/docs/current/api/
三、hdfs的JavaAPI操作的更多相关文章
- hdfs深入:10、hdfs的javaAPI操作
/** * 递归遍历hdfs中所有的文件路径 */ @Test public void getAllHdfsFilePath() throws URISyntaxException, IOExcept ...
- HDFS设计思想、元数据、简单JAVAAPI操作HDFS
一. 设计思路 分布式文件系统 在Hadoop中文件系统是一个顶层的抽象. 分布式文件系统相当与对文件系统进行了一个扩展(类似于java中的接口). HDFS是分布式文件系统的一个实现,分布式文件系统 ...
- Hadoop开发第6期---HDFS的shell操作
一.HDFS的shell命令简介 我们都知道HDFS 是存取数据的分布式文件系统,那么对HDFS 的操作,就是文件系统的基本操作,比如文件的创建.修改.删除.修改权限等,文件夹的创建.删除.重命名等. ...
- 大数据入门第五天——离线计算之hadoop(下)hadoop-shell与HDFS的JavaAPI入门
一.Hadoop Shell命令 既然有官方文档,那当然先找到官方文档的参考:http://hadoop.apache.org/docs/current/hadoop-project-dist/had ...
- HDFS基本命令行操作及上传文件的简单API
一.HDFS基本命令行操作: 1.HDFS集群修改SecondaryNameNode位置到hd09-2 (1)修改hdfs-site.xml <configuration> //配置元数据 ...
- HDFS之二:HDFS文件系统JavaAPI接口
HDFS是存取数据的分布式文件系统,HDFS文件操作常有两种方式,一种是命令行方式,即Hadoop提供了一套与Linux文件命令类似的命令行工具.HDFS操作之一:hdfs命令行操作 另一种是Java ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- Update(stage3):第1节 redis组件:4、安装(略);5、数据类型(略);6、javaAPI操作;
第三步:redis的javaAPI操作 操作string类型数据 操作hash列表类型数据 操作list类型数据 操作set类型的数据 详见代码
- 读Hadoop3.2源码,深入了解java调用HDFS的常用操作和HDFS原理
本文将通过一个演示工程来快速上手java调用HDFS的常见操作.接下来以创建文件为例,通过阅读HDFS的源码,一步步展开HDFS相关原理.理论知识的说明. 说明:本文档基于最新版本Hadoop3.2. ...
随机推荐
- Python(序列化json,pickle,shelve)
序列化 参考:https://www.cnblogs.com/yuanchenqi/articles/5732581.html # dic = str({'1':'111'}) # # f = ope ...
- 利用jaxb实现xml和bean的相互转换
1.使用jar包生成xsd文件 java -jar trang.jar a.xml a.xsd xml格式 生成的xsd文件 2.使用xjc命令生成bean文件 xjc a.xsd 生成的相关bean ...
- 《快学Scala》第二章 控制结构和函数
- Bootstrap Table使用方法详解
http://www.jb51.net/article/89573.htm bootstrap-table使用总结 bootstrap-table是在bootstrap-table的基础上写出来的,专 ...
- 电信10兆指的是多少Mbps
一般电信10兆(10Mbps)指的是:下载速度最大在1.25MB/s 1Mbps(兆位/秒) = 0.125MB/S(兆字节/秒) 8Mbps(兆位/秒) = 1MB/ ...
- keycloak ssl-required报错问题处理
两台主机,网段不同,第一台129.30.108.179/24 第二台172.16.160.92/24 都安装keycloak : docker run -d --name keycl ...
- JavaScript DOM编程艺术 笔记(四)
DOM document object model(map) 家谱树---节点树 父 子 兄弟 元素节点 <div> 文本节点 内容 属性节点 value src getE ...
- windows安装tesseract-OCR及使用
tesseract是Python的一个OCR(光学字符识别)库 首先下载tesseract的exe安装文件 https://github.com/UB-Mannheim/tesseract/wik ...
- 浅谈mongodb与Python的交互
1. mongdb和python交互的模块 pymongo 提供了mongdb和python交互的所有方法 安装方式: pip install pymongo 2. 使用pymongo 导入pymon ...
- TEMP_CHEMISTRY
1.\[CuSO_4\ and\ excess\ Ba(OH_2)\ :\ Cu^{2+}+SO_4^{2-}+Ba^{2+}+2OH^- \xrightarrow{\quad\quad} Cu(OH ...