Memcached介绍及相关知识
memcached简介
1、memcached是一个免费开源的、高性能的,具有分布式内存对象的缓存系统。memcached通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。
2、它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。内存中缓存的数据通过API的方式被存取。
3、Memcached基于一个Key存储键/Value值对的Hashmap。
4、其守护进程(daemon )是用C写的,
5、但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。
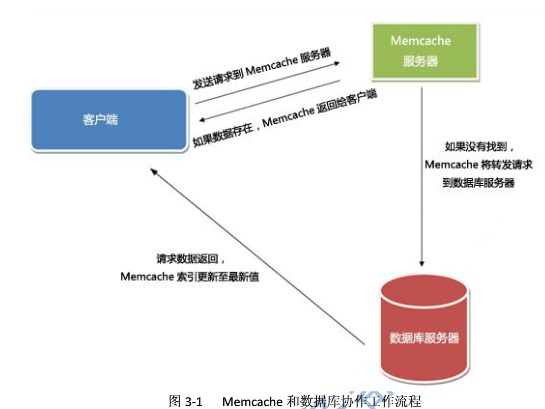
1、Memcached的特征
(1)、协议简单:Memcached使用的是基于广本行的协议,能直接通过telnet在Memcached服务器上存取数据。
(2)、基于libevent的事件处理:libevent是一套利用C开发的程序库,它将BSD系统的kqueue,Linux系统的epoll等事件处理功能封装成一个接口,确保即使服务器端的连接数增加也能发挥很好的性能。Memcached利用这个库进行异步事件处理。
(3)、内置的内存管理方式:Memcached有一套自己管理内存的方式,这套管理方式非常高效,所有的数据都保存在Memcached内置的内存中,当存入的数据占满空间时,使用LRU算法自动删除不使用的缓存,即重用过期数据的内存空间。Memcached是为缓存系统设计的,没有考虑数据的容灾问题,和机器的内存一样,重启机器数据将会丢失。
(4)、互不通信的Memcached之间具有分布特征:各个Memcached服务器之间互不通信,都是独立的存取数据,不共享任何信息。通过对客户端的设计,让Memcached具有分布式,能支持海量缓存和大规模应用。
2、适用memcached的业务场景?
1)如果网站包含了访问量很大的动态网页,因而数据库的负载将会很高。由于大部分数据库请求都是读操作,那么memcached可以显著地减小数据库负载。
2)如果数据库服务器的负载比较低但CPU使用率很高,这时可以缓存计算好的结果( computed objects )和渲染后的网页模板(enderred templates)。
3)利用memcached可以缓存session数据、临时数据以减少对他们的数据库写操作。
4)缓存一些很小但是被频繁访问的文件。
5)缓存Web 'services'(非IBM宣扬的Web Services,译者注)或RSS feeds的结果.。
3、不适用memcached的业务场景?
1)缓存对象的大小大于1MB
Memcached本身就不是为了处理庞大的多媒体(large media)和巨大的二进制块(streaming huge blobs)而设计的。
2)key的长度大于250字符
3)虚拟主机不让运行memcached服务
如果应用本身托管在低端的虚拟私有服务器上,像vmware, xen这类虚拟化技术并不适合运行memcached。Memcached需要接管和控制大块的内存,如果memcached管理 的内存被OS或 hypervisor交换出去,memcached的性能将大打折扣。
4)应用运行在不安全的环境中
Memcached为提供任何安全策略,仅仅通过telnet就可以访问到memcached。如果应用运行在共享的系统上,需要着重考虑安全问题。
5)业务本身需要的是持久化数据或者说需要的应该是database
4、 不能能够遍历memcached中所有的item
这个操作的速度相对缓慢且阻塞其他的操作(这里的缓慢时相比memcached其他的命令)。memcached所有非调试(non-debug)命令,例如add, set, get, fulsh等无论memcached中存储了多少数据,它们的执行都只消耗常量时间。任何遍历所有item的命令执行所消耗的时间,将随着memcached中数据量的增加而增加。当其他命令因为等待(遍历所有item的命令执行完毕)而不能得到执行,因而阻塞将发生。
5、 memcached能接受的key的最大长度是250个字符
memcached能接受的key的最大长度是250个字符。需要注意的是,250是memcached服务器端内部的限制。如果使用的 Memcached客户端支持"key的前缀"或类似特性,那么key(前缀+原始key)的最大长度是可以超过250个字符的。推荐使用较短的key, 这样可以节省内存和带宽。
6、 单个item的大小被限制在1M byte之内
因为内存分配器的算法就是这样的。
详细的回答:
1)Memcached的内存存储引擎,使用slabs来管理内存。内存被分成大小不等的slabs chunks(先分成大小相等的slabs,然后每个slab被分成大小相等chunks,不同slab的chunk大小是不相等的)。chunk的大小 依次从一个最小数开始,按某个因子增长,直到达到最大的可能值。如果最小值为400B,最大值是1MB,因子是1.20,各个slab的chunk的大小 依次是:
slab1 - 400B;slab2 - 480B;slab3 - 576B ...slab中chunk越大,它和前面的slab之间的间隙就越大。因此,最大值越大,内存利用率越低。Memcached必须为每个slab预先分 配内存,因此如果设置了较小的因子和较大的最大值,会需要为Memcached提供更多的内存。
2)不要尝试向memcached中存取很大的数据,例如把巨大的网页放到mencached中。因为将大数据load和unpack到内存中需要 花费很长的时间,从而导致系统的性能反而不好。如果确实需要存储大于1MB的数据,可以修改slabs.c:POWER_BLOCK的值,然后重新编译 memcached;或者使用低效的malloc/free。另外,可以使用数据库、MogileFS等方案代替Memcached系统。
7、 memcached的内存分配器是如何工作的?为什么不适用malloc/free!?为何要使用slabs?
实际上,这是一个编译时选项。默认会使用内部的slab分配器,而且确实应该使用内建的slab分配器。最早的时候,memcached只使用 malloc/free来管理内存。然而,这种方式不能与OS的内存管理以前很好地工作。反复地malloc/free造成了内存碎片,OS最终花费大量 的时间去查找连续的内存块来满足malloc的请求,而不是运行memcached进程。slab分配器就是为了解决这个问题而生的。内存被分配并划分成 chunks,一直被重复使用。因为内存被划分成大小不等的slabs,如果item的大小与被选择存放它的slab不是很合适的话,就会浪费一些内存。
8、memcached对item的过期时间有什么限制?
item对象的过期时间最长可以达到30天。memcached把传入的过期时间(时间段)解释成时间点后,一旦到了这个时间点,memcached就把item置为失效状态,这是一个简单但obscure的机制。
9、什么是二进制协议,是否需要关注?
二进制协议尝试为端提供一个更有效的、可靠的协议,减少客户端/服务器端因处理协议而产生的CPU时间。根据Facebook的测试,解析ASCII协议是memcached中消耗CPU时间最多的环节。
10、 memcached的内存分配器是如何工作的?为什么不适用malloc/free!?为何要使用slabs?
实际上,这是一个编译时选项。默认会使用内部的slab分配器,而且确实应该使用内建的slab分配器。最早的时候,memcached只使用 malloc/free来管理内存。然而,这种方式不能与OS的内存管理以前很好地工作。反复地malloc/free造成了内存碎片,OS最终花费大量 的时间去查找连续的内存块来满足malloc的请求,而不是运行memcached进程。slab分配器就是为了解决这个问题而生的。内存被分配并划分成 chunks,一直被重复使用。因为内存被划分成大小不等的slabs,如果item的大小与被选择存放它的slab不是很合适的话,就会浪费一些内存。
11、memcached是原子的吗?
所有的被发送到memcached的单个命令是完全原子的。如果您针对同一份数据同时发送了一个set命令和一个get命令,它们不会影响对方。它 们将被串行化、先后执行。即使在多线程模式,所有的命令都是原子的。然是,命令序列不是原子的。如果首先通过get命令获取了一个item,修改了它,然 后再把它set回memcached,系统不保证这个item没有被其他进程(process,未必是操作系统中的进程)操作过。memcached 1.2.5以及更高版本,提供了gets和cas命令,它们可以解决上面的问题。如果使用gets命令查询某个key的item,memcached会返 回该item当前值的唯一标识。如果客户端程序覆写了这个item并想把它写回到memcached中,可以通过cas命令把那个唯一标识一起发送给 memcached。如果该item存放在memcached中的唯一标识与您提供的一致,写操作将会成功。如果另一个进程在这期间也修改了这个 item,那么该item存放在memcached中的唯一标识将会改变,写操作就会失败。
12、memcached数据压缩问题?压缩比多少?
memcached的单个item最多存储1m数据。cache key 可以用md5加密,有两个原因,1是因为memcached 对于key的长度也是有限制,如果超出限制长度当前这个item会一直处于失效状态,2是因为安全问题。
用PHP Pecl memcache的哥们应该都知道,memcache client的add和set方法中第三个参数是表示是否用压缩存储的
bool Memcache::add ( string key, mixed var [, int flag [, int expire]] ) bool Memcache::set ( string key, mixed var [, int flag [, int expire]] )
flag Use MEMCACHE_COMPRESSED to store the item compressed (uses zlib).
还有一个比较重要的函数,是设置要压缩阀值的
bool Memcache::setCompressThreshold ( int threshold [, float min_savings] ) threshold Controls the minimum value length before attempting to compress automatically.
min_saving Specifies the minimum amount of savings to actually store the value compressed. The supplied value must be between 0 and 1. Default value is 0.2 giving a minimum 20% compression savings.
其中,threshold是设置开始压缩的最小长度,大于这个长度的串才会尝试自动压缩;
min_saving是使用压缩存储的最小节省百分比。当压缩后长度 < 原长度 * (1 - min_saving) 时,才会使用压缩存储。
13、memcached如果有机器宕机了怎么办?
Memcache自身并没有实现集群功能,如果想用Memcahce实现集群需要借助第三方软件或者自己设计编程实现,这里将采用memagent代理实现,memagent又名magent,大家注意下,不要将这二者当成两种工具。(原文地址:http://blog.csdn.net/liu251890347/article/details/38414247)
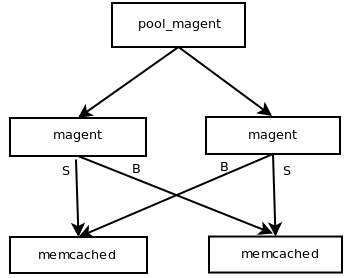
从图中可以看到有两个magent节点,两个memcached节点,每个magent节点又分别代理两个memcached节点,应用系统端使用magent pool来调用memcache进行存储。硬件结构为两台linux服务器,每台服务器上分别安装magent和memcached服务,并设为开机启动。这样做的好处是任何一台服务器宕机后都不影响magent pool获取memcache信息,即实现了memcached的高可用(HA)。
1、通过magent的连接池放的值会分别存在magent代理的所有memcached上去
2、如果有一个memcached宕机通过magent代理方式还能取到值
3、如果memcached修复重启后通过magent代理方式取到的值就会为Null,这是由于memcache重启后里边的值随着 memcache服务的停止就消失了(因为在内存中),但是magent是通过key进行哈希计算分配到某台机器上的,memcache重启后会还从这台 机器上取值,所有取到的值就没空。
解决办法
1、在每次memcache宕机修复后可以写一个程序把集群中的其他memcache的所有信息全给拷贝到当前宕机修复后的memcache中。
2、自己写代理,当从一个memcached服务上取到的值为null时再去其他memcached上取值。
解决方案2:memcached+repcached复制解决单点故障。(原文地址:http://www.rootop.org/pages/2475.html)
采用repcached做memcached的主从冗余。repcached实现了memcached复制的功能,它是一个单master单slave的方案,但master/slave都是可读写的,而且可以相互同步,如果master坏掉slave侦测到连接断了,它会自动listen而成为master;而如果slave坏掉,master也会侦测到连接断,它就会重新listen等待新的slave加入。
Memcached介绍及相关知识的更多相关文章
- HM编码器代码阅读(1)——介绍以及相关知识
HM是HEVC(H.265)的开源实现,可以从网上直接下载.HEVC(H.265)是新一代的视频编解码标准.本人目前研究的只是编码器部分,而且还是入门阶段!为了提高自己,边学边记,由于理解不够深入,难 ...
- PySpark SQL 相关知识介绍
title: PySpark SQL 相关知识介绍 summary: 关键词:大数据 Hadoop Hive Pig Kafka Spark PySpark SQL 集群管理器 PostgreSQL ...
- 【Python五篇慢慢弹(5)】类的继承案例解析,python相关知识延伸
类的继承案例解析,python相关知识延伸 作者:白宁超 2016年10月10日22:36:57 摘要:继<快速上手学python>一文之后,笔者又将python官方文档认真学习下.官方给 ...
- 移动WEB像素相关知识
了解移动web像素的知识,主要是为了切图时心中有数.本文主要围绕一个问题:怎样根据设备厂商提供的屏幕尺寸和物理像素得到我们切图需要的逻辑像素?围绕这个问题以iphone5为例讲解涉及到的web像素相关 ...
- 【转】java NIO 相关知识
原文地址:http://www.iteye.com/magazines/132-Java-NIO Java NIO(New IO)是从Java 1.4版本开始引入的一个新的IO API,可以替代标准的 ...
- AJAX跨域调用相关知识-CORS和JSONP(引)
AJAX跨域调用相关知识-CORS和JSONP 1.什么是跨域 跨域问题产生的原因,是由于浏览器的安全机制,JS只能访问与所在页面同一个域(相同协议.域名.端口)的内容. 但是我们项目开发过程中,经常 ...
- Java 容器相关知识全面总结
Java实用类库提供了一套相当完整的容器来帮助我们解决很多具体问题.因为我本身是一名Android开发者,包括我在内很多安卓开发,最拿手的就是ListView(RecycleView)+BaseAda ...
- HTML入门基础教程相关知识
HTML入门基础教程 html是什么,什么是html通俗解答: html是hypertext markup language的缩写,即超文本标记语言.html是用于创建可从一个平台移植到另一平台的超文 ...
- OSPF相关知识与实例配置【第一部分】
OSPF相关知识与实例配置[基本知识及多区域配置] OSPF(开放式最短路径优先协议)是一个基于链路状态的IGP,相比于RIP有无环路:收敛快:扩展性好等优点,也是现在用的最多的:所以这次实验就针对于 ...
随机推荐
- Redux 入门教程
Redux 入门教程(三):React-Redux 的用法(53@2016.09.21) Redux 入门教程(二):中间件与异步操作(32@2016.09.20) Redux 入门教程(一):基本用 ...
- PAT 1147 Heaps[难]
1147 Heaps(30 分) In computer science, a heap is a specialized tree-based data structure that satisfi ...
- 自动化测试中级篇——LazyAndroid UI自动化测试框架使用指南
原文地址https://blog.csdn.net/iamhuanggua/article/details/53104345 简介 一直以来,安卓UI自动化测试都存在以下两个障碍,一是测试工具Mo ...
- centos6.5搭建svn
检查已经安装版本 rpm -qa subversion如果存在旧版本,卸载yum remove subversion 安装svn yum install subversion 验证是否安装成功 sv ...
- 20145328 《网络对抗技术》逆向及Bof基础实践
20145328 <网络对抗技术>逆向及Bof基础实践 实践内容 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回 ...
- Duilib应用修改程序图标方法
本文向大家介绍如何修改duilib应用图标,对于win32或者mfc应用来说,我们可以在注册窗口类时指定WNDCLASS结构体的HIcon属性.那么duilib应用该怎样处理呢?大家都知道Window ...
- Tomcat 启动图解
Tomcat server.xml结构 startup.bat执行流程 catalina.bat执行流程 Tomcat Server处理一个http请求的过程
- SpringBoot Boot内嵌Tomcat
Spring Boot: SpringBoot-start-web 里面依赖的环境中 如果是外部的Tomcat 容器,可以通过修改config进行配置 内嵌的呢? 如何定制和修改Servlet容器的相 ...
- display:box,按比列划分,水平均分,及垂直等高
一.按比例划分 <div class="test"> <p id="p1">Hello</p> <p id=" ...
- 代码注释,神兽护体,代码无bug
/** * * ━━━━━━神兽出没━━━━━━ * ┏┓ ┏┓ * ┏┛┻━━━┛┻┓ * ┃ ┃ * ┃ ━ ┃ * ┃ ┳┛ ┗┳ ┃ * ┃ ┃ * ┃ ┻ ┃ * ┃ ┃ * ┗━┓ ┏━┛ ...