腾讯云大数据套件Hermes-MR索引插件使用总结
版权声明:本文由王亮原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/121
来源:腾云阁 https://www.qcloud.com/community
Hermes是多维分析利器,使用步骤分为索引创建和数据分发两个步骤。
Hermes目前尚未集成到TBDS套件(3.0版本)中且外部有客户需要在自己部署的集群上使用Hermes组件,这里就遇到了Hermes与外部Hadoop集群的适配问题。
Hermes与某客户外部集群集成后,一次压测时(2T数据量,445604010行,477字段全索引)使用单机版的Hermes索引创建插件由于数据量过大,出现Out of Memory等异常现象导致索引插件程序崩溃,实际产生的数据索引量和实际数据量差距很大。基于以上考虑,数平提供了基于MR的索引创建插件,提升索引创建效率。
以下记录了基于hadoop2.2版本的MR索引插件和外部集群的适配过程。
一.集群相关组件版本
Hermes版本:hermes-2.1.0-1.x86_64
Hadoop集群版本:Hadoop 2.7.1.2.3.0.0-2557
Hermes-index-MR插件使用的Hadoop-common:hadoop-common-2.2.0.jar
二.Hermes-MR插件使用方法
1.需修改配置:(以$HERMES_INDEX_MR_HOME表示插件主目录)
$HERMES_INDEX_MR_HOME/conf/hermes.properties
修改内容:hermes.zkConnectionString更改为本集群的zookeeper地址;hermes.hadoop.conf.dir修改为本集群的hadoop配置目录;hermes.hadoop.home修改为本集群的hadoop安装主目录。$HERMES_INDEX_MR_HOME/conf/hermes_index.properties
修改内容:hermes.hadoop.conf更改为本集群的hadoop配置目录;hermes.index.user.conf更改为hermes-MR-index插件的用户配置文件绝对地址。$HERMES_INDEX_MR_HOME/conf/user_conf.xml
修改内容:该配置即hermes-MR-index插件的用户配置文件,一般默认配置项即可。需要注意的是插件支持指定被索引文件的字段分隔符。配置项为higo.input.record.split和higo.input.record.ascii.split。其中higo.input.record.ascii.split的优先级高于前者,指定higo.input.record.ascii.split后第一个配置将无效。其中higo.input.record.split的value项直接指定分隔符内容(如|,\,;等);higo.input.record.ascii.split指定分隔符对应的ascii码数字。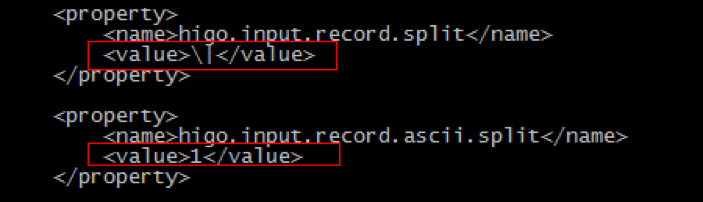
2.运行插件
执行命令:在插件主目录下(其中labcluster为HDFS的nn通过做HA的名称):
sh bin/submit_index_job.sh \
clk_tag_info_test_500 \
20160722 \
hdfs://labcluster/apps/hive/market_mid/clk_tag_info_test/ \
hdfs://labcluster/user/hermes/demo_dir/clk_tag_info_test_500/ \
hdfs://labcluster/user/hermes/demo_dir/schema/clk_tag_info_test_500_hermes.schema \
key_id \
3
参数介绍:
sh bin/submit_index_job.sh表名 数据时间(时间分区) 源数据在HDFS上地址(单文件或目录) 索引输出的HDFS目录 schema文件在HDFS的地址(需手动创建上传) 主键 索引分片数
3.日志观察:
创建索引插件在运行后会在$HERMES_INDEX_MR_HOME/logs输出hermes.log和index.log。前者为hermes相关的记录,后者为索引创建过程记录(包括MR任务相关信息)。正常情况下index.log会记录提交MR任务成功与否以及相关jobid,可通过HADOOP的RM管理页面看到状态,index.log也会记录Map/Reduce的进度,完成后会输出Job ${job.id} completed successfully以及MR任务相关信息(如图)。如果出现错误日志,需具体分析,下文会总结本次集群适配遇到的一系列问题,目前已在TBDS3.0(Hadoop2.7)集群里测试通过。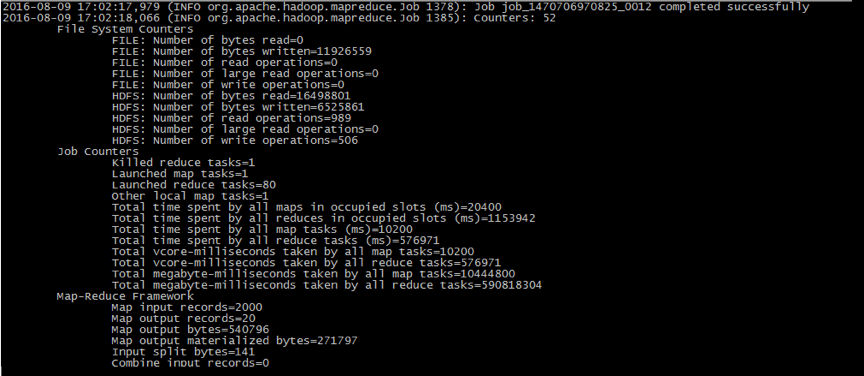
4.适配基本过程
前面已提到Hermes-MR-index插件使用的Hadoop-common.jar版本为2.2,但集群本身为Hadoop2.7。在直接执行插件创建索引时出现以下“奇怪”异常。
Diagnostics: Exception from container-launch.
Container id: container_e07_1469110119300_0022_02_000001
Exit code: 255
Stack trace: ExitCodeException exitCode=255:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:545)
at org.apache.hadoop.util.Shell.run(Shell.java:456)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:722)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:211)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
查询了所有异常日志后一无所获,和数平Hadoop大神请教后,建议替换Hermes-MR-index插件里用到Hadoop*.jar包为集群内版本。这样开始还是遇到了一系列问题,最终在hadoop2.7环境下Hermes-MR-index插件运行正常。
整理了以下思路进行适配:1.将Hermes-MR-index插件用到的hadoop-*.jar全部替换为集群内使用的版本;2.执行插件看日志错误一般会因为新版(2.7)有新的jar包依赖关系,提示错误,根据错误提示缺少的类找到对应jar包,添加到$HERMES_INDEX_MR_HOME/lib目录,重复此操作,直到不再提示缺少类错误。3.执行以上操作时同时需要注意缺少的类关联的jar包的版本必须和实际集群用到的版本一致(重复步骤2时发现的问题)。
5.问题汇总
插件和集群的适配过程中遇到的问题总结如下:
配置项
mapreduce.framework.name异常2016-07-21 15:39:51,522 (ERROR
org.apache.hadoop.security.UserGroupInformation 1600):
PriviledgedActionException as:root (auth:SIMPLE)
cause:java.io.IOException: Cannot initialize Cluster. Please check
your configuration for mapreduce.framework.name and the correspond
server addresses.
Exception in thread "main" java.io.IOException: Cannot initialize
Cluster. Please check your configuration for
mapreduce.framework.name and the correspond server addresses.
解决方法:查看集群的hadoop相关配置(即hermes.properties里指定的hadoop配置路径里配置目录,也可以复制集群的出来,自己做单独修改)mapred-site.xml里的mapreduce.framework.name配置项内容为yarn-tez,但目前插件只支持到yarn,故单独修改此项配置为yarn后保存,异常解决。
插件无法向集群提交任务
2016-07-21 20:14:49,355 (ERROR
org.apache.hadoop.security.UserGroupInformation 1600):
PriviledgedActionException as:hermes (auth:SIMPLE)
cause:java.io.IOException: Failed to run job :
org.apache.hadoop.security.AccessControlException: User hermes
cannot submit applications to queue root.default
解决方法:使用hermes用户向yarn提交任务时无权限提示。修改yarn集群的权限允许hermes即可。TBDS3.0有很方便的访问控制页面进行操作。
提交任务时变量替换异常
Exception message:
/hadoop/data1/hadoop/yarn/local/usercache/hermes/appcache/applicati
on_1469110119300_0004/container_e07_1469110119300_0004_02_000001/lau
nch_container.sh: line 9:
$PWD:$HADOOP_CONF_DIR:/usr/hdp/current/hadoop-
client/*:/usr/hdp/current/hadoop-
client/lib/*:/usr/hdp/current/hadoop-hdfs-
client/*:/usr/hdp/current/hadoop-hdfs-
client/lib/*:/usr/hdp/current/hadoop-yarn-
client/*:/usr/hdp/current/hadoop-yarn-client/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/mapreduce/*:$PWD/mr-
framework/hadoop/share/hadoop/mapreduce/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/common/*:$PWD/mr-
framework/hadoop/share/hadoop/common/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/yarn/*:$PWD/mr-
framework/hadoop/share/hadoop/yarn/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/hdfs/*:$PWD/mr-
framework/hadoop/share/hadoop/hdfs/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/tools/lib/*:/usr/hdp/${hdp.version}/ha
doop/lib/hadoop-lzo-
0.6.0.${hdp.version}.jar:/etc/hadoop/conf/secure:job.jar/job.jar:job
.jar/classes/:job.jar/lib/*:$PWD/*: bad substitution
/hadoop/data1/hadoop/yarn/local/usercache/hermes/appcache/applicatio
n_1469110119300_0004/container_e07_1469110119300_0004_02_000001/laun
ch_container.sh: line 67: $JAVA_HOME/bin/java -
Dlog4j.configuration=container-log4j.properties -
Dyarn.app.container.log.dir=/hadoop/data1/yarn/container-
logs/application_1469110119300_0004/container_e07_1469110119300_0004
_02_000001 -Dyarn.app.container.log.filesize=0 -
Dhadoop.root.logger=INFO,CLA -Dhdp.version=${hdp.version} -Xmx5120m
org.apache.hadoop.mapreduce.v2.app.MRAppMaster
1>/hadoop/data1/yarn/container-
logs/application_1469110119300_0004/container_e07_1469110119300_0004
_02_000001/stdout 2>/hadoop/data1/yarn/container-
logs/application_1469110119300_0004/container_e07_1469110119300_0004
_02_000001/stderr : bad substitution
Stack trace: ExitCodeException exitCode=1:
/hadoop/data1/hadoop/yarn/local/usercache/hermes/appcache/applicatio
n_1469110119300_0004/container_e07_1469110119300_0004_02_000001/laun
ch_container.sh: line 9:
$PWD:$HADOOP_CONF_DIR:/usr/hdp/current/hadoop-
client/*:/usr/hdp/current/hadoop-
client/lib/*:/usr/hdp/current/hadoop-hdfs-
client/*:/usr/hdp/current/hadoop-hdfs-
client/lib/*:/usr/hdp/current/hadoop-yarn-
client/*:/usr/hdp/current/hadoop-yarn-client/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/mapreduce/*:$PWD/mr-
framework/hadoop/share/hadoop/mapreduce/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/common/*:$PWD/mr-
framework/hadoop/share/hadoop/common/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/yarn/*:$PWD/mr-
framework/hadoop/share/hadoop/yarn/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/hdfs/*:$PWD/mr-
framework/hadoop/share/hadoop/hdfs/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/tools/lib/*:/usr/hdp/${hdp.version}/ha
doop/lib/hadoop-lzo-
0.6.0.${hdp.version}.jar:/etc/hadoop/conf/secure:job.jar/job.jar:job
.jar/classes/:job.jar/lib/*:$PWD/*: bad substitution
/hadoop/data1/hadoop/yarn/local/usercache/hermes/appcache/applicatio
n_1469110119300_0004/container_e07_1469110119300_0004_02_000001/laun
ch_container.sh: line 67: $JAVA_HOME/bin/java -
Dlog4j.configuration=container-log4j.properties -
Dyarn.app.container.log.dir=/hadoop/data1/yarn/container-
logs/application_1469110119300_0004/container_e07_1469110119300_0004
_02_000001 -Dyarn.app.container.log.filesize=0 -
Dhadoop.root.logger=INFO,CLA -Dhdp.version=${hdp.version} -Xmx5120m
org.apache.hadoop.mapreduce.v2.app.MRAppMaster
1>/hadoop/data1/yarn/container-
logs/application_1469110119300_0004/container_e07_1469110119300_0004
_02_000001/stdout 2>/hadoop/data1/yarn/container-
logs/application_1469110119300_0004/container_e07_1469110119300_0004
_02_000001/stderr : bad substitution
解决方法:从bad substitution可以判定为是某些配置的参数没有正常替换造成。查看具体异常里面用到的变量有$PWD,$JAVA_HOME,${hdp.version}和$HADOOP_CONF_DIR以上变量在hadoop的配置文件里找到逐个替换为实际值而不用变量直到错误提示不再出现。实践中发现是因为hdp.version这个变量没有值造成的,可以在hadoop配置里增加一项此配置或者将用到该变量的地方替换为实际值即可。
一个“奇怪的”错误
2016-07-22 15:25:40,657 (INFO org.apache.hadoop.mapreduce.Job 1374):
Job job_1469110119300_0022 failed with state FAILED due to:
Application application_1469110119300_0022 failed 2 times due to AM
Container for appattempt_1469110119300_0022_000002 exited with
exitCode: 255
For more detailed output, check application tracking
page:http://bdlabnn2:8088/cluster/app/application_1469110119300_0022
Then, click on links to logs of each attempt.
Diagnostics: Exception from container-launch.
Container id: container_e07_1469110119300_0022_02_000001
Exit code: 255
Stack trace: ExitCodeException exitCode=255:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:545)
at org.apache.hadoop.util.Shell.run(Shell.java:456)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java
:722)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.l
aunchContainer(DefaultContainerExecutor.java:211)
at
org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.
ContainerLaunch.call(ContainerLaunch.java:302)
解决方法:这个错误是最难解决的错误,最终是用本文提到的插件和集群版本适配的办法解决,解决方法及思路见“适配基本过程”。替换或者增加了的jar包列表如下:
jackson-core-2.2.3.jar
jersey-json-1.9.jar
jersey-client-1.9.jar
jersey-core-1.9.jar
jackson-xc-1.9.13.jar
jersey-guice-1.9.jar
jersey-server-1.9.jar
jackson-jaxrs-1.9.13.jar
commons-io-2.5.jar
htrace-core-3.1.0-incubating.jar
hermes-index-2.1.2.jar
hadoop-cdh3-hdfs-2.2.0.jar
hadoop-cdh3-core-2.2.0.jar
hadoop-yarn-common-2.7.2.jar
hadoop-yarn-client-2.7.2.jar
hadoop-yarn-api-2.7.2.jar
hadoop-mapreduce-client-jobclient-2.7.2.jar
hadoop-mapreduce-client-core-2.7.2.jar
hadoop-mapreduce-client-common-2.7.2.jar
hadoop-hdfs-2.7.2.jar
hadoop-common-2.7.2.jar
hadoop-auth-2.7.2.jar
无法连接yarn的RM任务提交端口
在TBDS3.0的环境下提交任务后日志提示重连RMserver失败,一直提示该错误
解决方法:查看启动进程发现内部集群接收mr请求的端口为8032,修改项里的RMserveraddress配置的端口后任务通过适配完成替换/新增所有jar包后出现的异常
Exception in thread "main" java.lang.VerifyError: class
org.codehaus.jackson.xc.JaxbAnnotationIntrospector overrides final
method findDeserializer.(Lorg/codehaus/jackso
n/map/introspect/Annotated;)Ljava/lang/Object;
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:800)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2615)
at java.lang.Class.getDeclaredMethods(Class.java:1860)
at com.sun.jersey.core.reflection.MethodList.getAllDeclaredMethods(Meth
odList.java:70)
at com.sun.jersey.core.reflection.MethodList.<init>(MethodList.java:64)
at com.sun.jersey.core.spi.component.ComponentConstructor.getPostConstr
uctMethods(ComponentConstructor.java:131)
at com.sun.jersey.core.spi.component.ComponentConstructor.<init>(ComponentConstructor.java:123)
at com.sun.jersey.core.spi.component.ProviderFactory.__getComponentProv
ider(ProviderFactory.java:165)
at com.sun.jersey.core.spi.component.ProviderFactory._getComponentProvider(ProviderFactory.java:159)
at com.sun.jersey.core.spi.component.ProviderFactory.getComponentProvider(ProviderFactory.java:153)
at com.sun.jersey.core.spi.component.ProviderServices.getComponent(ProviderServices.java:251)
解决方法:查询这个异常类属于
jackson*.jar,那问题就出在这一系列的包身上,检查发现Hermes-MR-index插件的lib目录下有jackson-core-asl-1.7.3.jar
jackson-mapper-asl-1.7.3.jar
jackson-core-asl-1.9.13.jar
jackson-mapper-asl-1.9.13.jar
这两个包的版本有2个,检查Hadoop集群用的版本为1.9.13,将插件lib目录下的1.7.3版本的两个包删除后,插件正常运行。原因归结为jar包版本冲突。
提示无法找到MR框架路径
Exception in thread "main" java.lang.IllegalArgumentException: Could
not locate MapReduce framework name 'mr-framework' in
mapreduce.application.classpath
at org.apache.hadoop.mapreduce.v2.util.MRApps.setMRFrameworkClasspath(M
RApps.java:231)
at org.apache.hadoop.mapreduce.v2.util.MRApps.setClasspath(MRApps.java:258)
at org.apache.hadoop.mapred.YARNRunner.createApplicationSubmissionContext(YARNRunner.java:458)
at org.apache.hadoop.mapred.YARNRunner.submitJob(YARNRunner.java:285)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:240)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at com.tencent.hermes.hadoop.job.HermesIndexJob.subRun(HermesIndexJob.java:262)
at com.tencent.hermes.hadoop.job.HermesIndexJob.run(HermesIndexJob.java:122)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at com.tencent.hermes.hadoop.job.SubmitIndexJob.call(SubmitIndexJob.java:194)
at com.tencent.hermes.hadoop.job.SubmitIndexJob.main(SubmitIndexJob.java:101)
解决方法:提示
mapreduce.application.framework.path配置里没找到mr框架的路径,检查mapred-site.xml的该配置项确实配置有异常,在该配置项里增加mr框架路径后通过(以下红色为新增配置)。
<property>
<name>mapreduce.application.classpath</name>
<value>$PWD/mr-framework/hadoop/share/hadoop/mapreduce/*:$PWD/mr-
framework/hadoop/share/hadoop/mapreduce/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/common/*:$PWD
/mr-framework/hadoop/share/hadoop/common/lib/*:$PWD/mr-
framework/hadoop/share/hadoop/yarn/*:$PWD/mr-
framework/hadoop/share/hadoop/yarn/lib/*:$PWD/mr-framework/hadoop/sh
are/hadoop/hdfs/*:$PWD/mr-framework/hadoop/share/hadoop/hdfs/lib/*:/usr/hdp/2.2.0.0-
2041/hadoop/lib/hadoop-lzo-0.6.0.2.2.0.0-
2041.jar:/etc/hadoop/conf/secure</value>
</property>
腾讯云大数据套件Hermes-MR索引插件使用总结的更多相关文章
- 阿里云大数据三次技术突围:Greenplum、Hadoop和“飞天”
阿里云大数据三次技术突围:Greenplum.Hadoop和"飞天" 对于企业来说,到底什么是云计算?相信很多企业都有这样的困惑,让我们一起回到这个原始的起点探讨究竟什么是云 ...
- 阿里云大数据计算服务 - MaxCompute (原名 ODPS)
MaxCompute 是阿里EB级计算平台,经过十年磨砺,它成为阿里巴巴集团数据中台的计算核心和阿里云大数据的基础服务.去年MaxCompute 做了哪些工作,这些工作背后的原因是什么?大数据市场进入 ...
- 腾讯大数据之TDW计算引擎解析——Shuffle
转自 https://www.csdn.net/article/2014-05-19/2819831-TDW-Shuffle/1 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,T ...
- 如何通过倾斜摄影数据手动配置s3c索引文件?
如何通过倾斜摄影数据手动配置s3c索引文件? 大家知道,倾斜摄影数据最常见的是OSGB格式,并且是由一个一个的Tile分级文件夹构成的Data文件夹.结构一般如下图所示: 那么,如何才能把模型的各个瓦 ...
- 【转】B-树和B+树的应用:数据搜索和数据库索引
B-树 1 .B-树定义 B-树是一种平衡的多路查找树,它在文件系统中很有用. 定义:一棵m 阶的B-树,或者为空树,或为满足下列特性的m 叉树: ⑴树中每个结点至多有m 棵子树: ⑵若根结点不是叶子 ...
- 数据结构 B-树和B+树的应用:数据搜索和数据库索引
B-树 1 .B-树定义 B-树是一种平衡的多路查找树,它在文件系统中很有用. 定义:一棵m 阶的B-树,或者为空树,或为满足下列特性的m 叉树:⑴树中每个结点至多有m 棵子树:⑵若根结点不是叶子结点 ...
- B-树和B+树的应用:数据搜索和数据库索引
B-树和B+树的应用:数据搜索和数据库索引 B-树 1 .B-树定义 B-树是一种平衡的多路查找树,它在文件系统中很有用. 定义:一棵m 阶的B-树,或者为空树,或为满足下列特性的m 叉树:⑴树中每 ...
- (转)B-树和B+树的应用:数据搜索和数据库索引
B-树 1 .B-树定义 B-树是一种平衡的多路查找树,它在文件系统中很有用. 定义:一棵m 阶的B-树,或者为空树,或为满足下列特性的m 叉树: ⑴树中每个结点至多有m 棵子树: ⑵若根结点不是叶子 ...
- hbase使用MapReduce操作3(实现将 fruit 表中的一部分数据,通过 MR 迁入到 fruit_mr 表中)
Runner类 实现将 fruit 表中的一部分数据,通过 MR 迁入到 fruit_mr 表中. package com.yjsj.hbase_mr; import org.apache.hadoo ...
随机推荐
- java——多线程的实现
package test; class TestThread extends Thread{ public void run() { for(int n=0;n<3;n++) { try{Thr ...
- Java上的jQuery?解析HTML利器—Jsoup
也许大家有过在java运行平台上解析html的经历,通常的方式是将HTML以XML的形式进行结点解析,调用java本身的xml解析类库.这样的方式很容易理解并且很方便,但习惯用jQuery的各位是否在 ...
- pku1204 Word Puzzles AC自动机 二维字符串矩阵8个方向找模式串的起点坐标以及方向 挺好的!
/** 题目:pku1204 Word Puzzles 链接:http://poj.org/problem?id=1204 题意:给定一个L C(C <= 1000, L <= 1000) ...
- 轻松学习之Linux教程二 一览纵山小:Linux操作系统具体解释
本系列文章由@uid=hpw" style="padding:0px; margin:0px; color:rgb(255,0,0); text-decoration:none&q ...
- find 下参数的关系默认是and 一个参数多个选项可以用 -or
[root@ob2 mytmp]# find -type f -name "*.html" -or -name "*.txt"./02.html./aa.htm ...
- MongoDB(三):MongoDB概念解析
在上一篇文章中讲解了如何安装MongoDB,这篇文章中讲解一些有关MongoDB的概念. 不管我们要学习什么数据库,都应该学习其中的基础概念,在MongoDB中基本的概念是文档.集合.数据库,下面挨个 ...
- jqueryEasyui常用代码
//查询: function doSearch(form){ var fields =$('#queryForm').serializeArray(); var $fm = $(form); var ...
- 手动模拟输出json
每次去写太麻烦,写一个样本,下次对照就好了 context.Response.Write("{\"UserName\":\""+HttpContext ...
- 关于Cocos2d-x中坐标系的种类和转换
注意: 当一个节点有一个子节点的时候,如果移动父节点,子节点也会跟着做相应的移动变化,只要被添加到父节点中,子节点就被绑定了,所以子节点的位置,坐标就会被动地变化. 当一个节点有一个子节点的时候,如果 ...
- 机器学习性能评估指标(精确率、召回率、ROC、AUC)
http://blog.csdn.net/u012089317/article/details/52156514 ,y^)=1nsamples∑i=1nsamples(yi−y^i)2