[转]Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法
原文地址:https://www.cnblogs.com/yysbolg/p/9040649.html
刚开始学习一门技术最麻烦的问题就是搞定IDE环境,直接在PyCharm里安装BeautifulSoup报错,让初学者一头雾水;
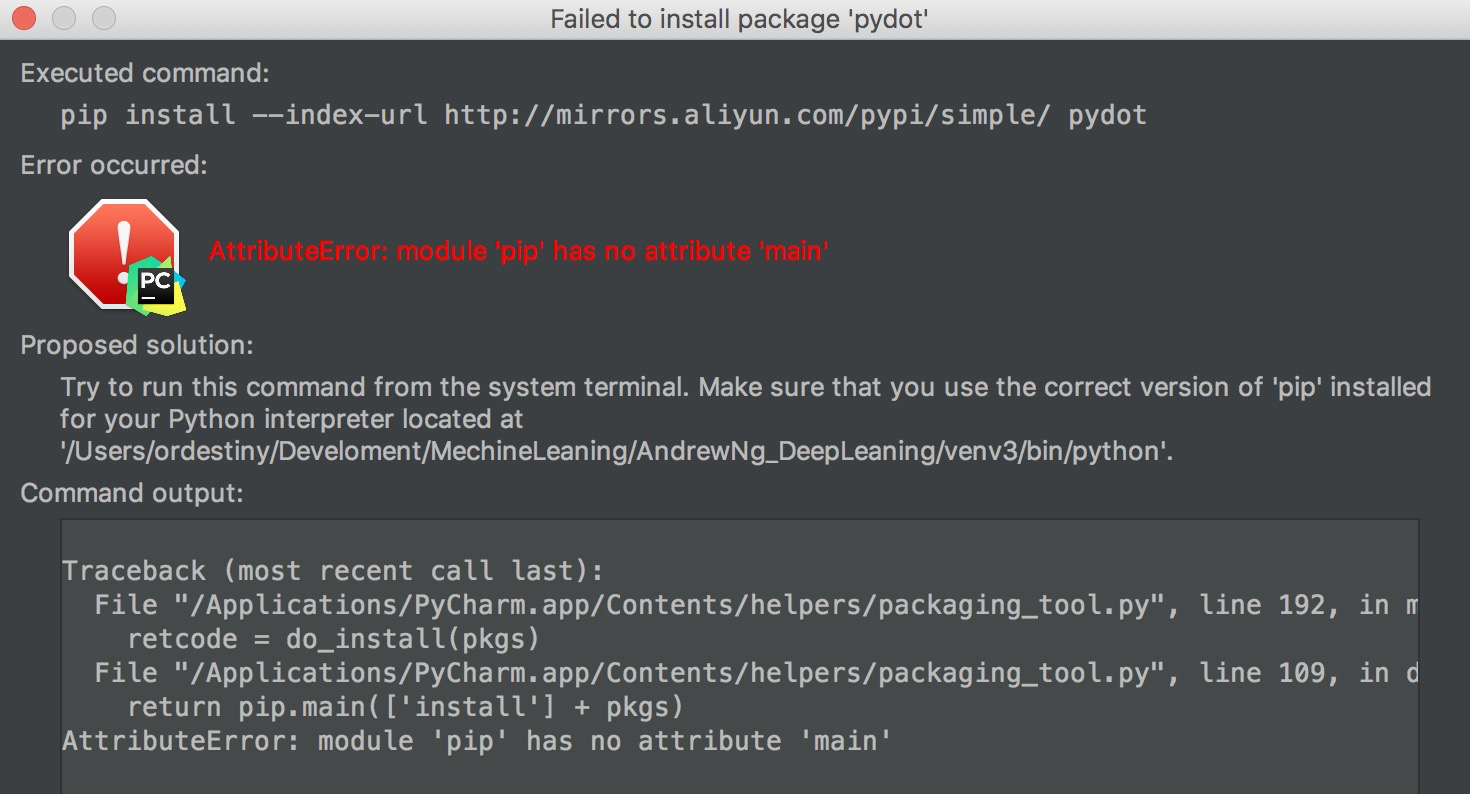
这是由于pip版本的问题,pip 10.0版本的没有main()方法, 因此更改如下代码即可:
可以考虑降个版本:python -m pip install --upgrade pip==9.0.3
解决方法:
找到C:\Program Files\JetBrains\PyCharm 2017.3.2安装目录下的 helpers/packaging_tool.py文件,找到如下代码:
def do_install(pkgs):
try:
import pip
except ImportError:
error_no_pip()
return main(['install'] + pkgs)
def do_uninstall(pkgs):
try:
import pip
except ImportError:
error_no_pip()
return main(['uninstall', '-y'] + pkgs)
修改为如下,保存即可

def do_install(pkgs):
try:
# import pip
try:
from pip._internal import main
except Exception:
from pip import main
except ImportError:
error_no_pip()
return main(['install'] + pkgs) def do_uninstall(pkgs):
try:
# import pip
try:
from pip._internal import main
except Exception:
from pip import main
except ImportError:
error_no_pip()
return main(['uninstall', '-y'] + pkgs)
再次运行,就可以安装这些扩展包啦,Yeah!!!
[转]Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法的更多相关文章
- Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法
1.安装步骤: 首先,你要先进入pycharm的Project Interpreter界面,进入方法是:setting(ctrl+alt+s) ->Project Interpreter,Pro ...
- python爬虫数据解析之BeautifulSoup
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. BeautfulSoup是python爬虫三 ...
- 【XPath Helper:chrome爬虫网页解析工具 Chrome插件】XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插件网
[XPath Helper:chrome爬虫网页解析工具 Chrome插件]XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插 ...
- python爬虫网页解析之lxml模块
08.06自我总结 python爬虫网页解析之lxml模块 一.模块的安装 windows系统下的安装: 方法一:pip3 install lxml 方法二:下载对应系统版本的wheel文件:http ...
- python爬虫网页解析之parsel模块
08.06自我总结 python爬虫网页解析之parsel模块 一.parsel模块安装 官网链接https://pypi.org/project/parsel/1.0.2/ pip install ...
- 【Python】在Pycharm中安装爬虫库requests , BeautifulSoup , lxml 的解决方法
BeautifulSoup在学习Python过程中可能需要用到一些爬虫库 例如:requests BeautifulSoup和lxml库 前面的两个库,用Pychram都可以通过 File--> ...
- web报表工具FineReport使用中遇到的常见报错及解决办法(二)
web报表工具FineReport使用中遇到的常见报错及解决办法(二) 这里写点抛砖引玉,希望大家能把自己整理的问题及解决方法晾出来,Mark一下,利人利己. 出现问题先搜一下文档上有没有,再看看度娘 ...
- Ubuntu“无法解析或打开软件包的列表或是状态文件”的解决办法。_StarSasumi_新浪博客
Ubuntu"无法解析或打开软件包的列表或是状态文件"的解决办法. (2011-04-30 14:56:14) 转载▼ 标签: ubuntu apt 分类: Ubuntu/Linu ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
随机推荐
- ORM的补充
之前学习的orm的操作类似: create delete update filter/all exclude values values_list get first last order_by 补充 ...
- ASC日志保存时间更改
连接到数据库,选择 OperationsManagerAC,修改dtConfig表即可,新建查询: select * from dtConfig Update dtConfig set value=2 ...
- ZT 理解class.forName()
理解class.forName() 分类: [Java SE 基础] 2012-05-17 07:53 3892人阅读 评论(3) 收藏 举报 classloaderclassjdbcejb数据库 目 ...
- ZT Android Debuggerd的分析及使用方法
Android Debuggerd的分析及使用方法 分类: 移动开发 android framework 2012-12-28 12:00 983人阅读 评论(0) 收藏 举报 目录(?)[+] An ...
- pyenv - python版本管理
1. 安装pyenv brew install pyenv 2. 安装python其它版本(如:python 3.6.7) pyenv install --list #查看可以安装的python版本 ...
- Redis数据的底层存储原理
redis底层是用什么结构来存储数据的呢? 我们从源码上去理解就会容易的多: redis底层是使用C语言来编写的,我们可以看到它的数据结构声明.一个 dict 有两个dictht,一个dictht ...
- scala基础入门
1.scala当中申明值和变量 scala当中的变量申明可以使用两种方式,第一种使用val来申明变量.第二种使用var来申明变量. 申明变量语法 val/var 变量名 [:变量类型] = 变量值 其 ...
- Cinder组件解析
1 Cinder架构图 Cinder是在虚拟机和具体存储设备之间引入了一层“逻辑存储卷”的抽象,Cinder本身并不是一种存储技术,只是提供一个中间的抽象层,Cinder通过调用不同存储后端类型的驱 ...
- SOJ 4309 Sum of xor 异或/思维
Source ftiasch 解题思路: 本题的题解有参考这里,但是那篇年代太久远,讲的也不甚清晰,所以可能会对很多新手造成困扰,所以又写了这一篇. 亦或有很多规律,本题使用到的是n^(n+1)=1, ...
- Tomcat的免安装配置
Tomcat免安装配置 以下配置说明全部针对免安装版本 基于tomcat的安装目录和运行目录是可以不同的,本文都会进行说明 首先简单介绍一下tomcat的目录结构,一般情况下,tomcat包括以下子目 ...