服务器反爬虫攻略:Apache/Nginx/PHP禁止某些User Agent抓取网站
我们都知道网络上的爬虫非常多,有对网站收录有益的,比如百度蜘蛛(Baiduspider),也有不但不遵守robots 规则对服务器造成压力,还不能为网站带来流量的无用爬虫,比如宜搜蜘蛛(YisouSpider)(最新补充:宜搜蜘蛛已被UC神马搜索收购!所以本文已去掉宜搜蜘蛛的禁封! ==> 相关文章 )。最近张戈发现nginx日志中出现了好多宜搜等垃圾的抓取记录,于是整理收集了网络上各种禁止垃圾蜘蛛爬站的方法,在给自己网做设置的同时,也给各位站长提供参考。
一、Apache
①、通过修改.htaccess 文件
修改网站目录下的.htaccess,添加如下代码即可(2 种代码任选):
可用代码(1):
- RewriteEngine On
- RewriteCond %{HTTP_USER_AGENT} (^$|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms) [NC]
- RewriteRule ^(.*)$ - [F]
可用代码(2):
- SetEnvIfNoCase ^User-Agent$ .*(FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms) BADBOT
- Order Allow,Deny
- Allow from all
- Deny from env=BADBOT
②、通过修改httpd.conf 配置文件
找到如下类似位置,根据以下代码新增/ 修改,然后重启Apache 即可:
- DocumentRoot /home/wwwroot/xxx
- <Directory "/home/wwwroot/xxx">
- SetEnvIfNoCase User-Agent ".*(FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms)" BADBOT
- Order allow,deny
- Allow from all
- deny from env=BADBOT
- </Directory>
二、Nginx 代码
进入到nginx 安装目录下的conf 目录,将如下代码保存为 agent_deny.conf
cd /usr/local/nginx/conf
vim agent_deny.conf
- #禁止Scrapy等工具的抓取
- if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
- return ;
- }
- #禁止指定UA及UA爲空的訪問
- if ($http_user_agent ~* "FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
- return ;
- }
- #禁止非GET|HEAD|POST方式的抓取
- if ($request_method !~ ^(GET|HEAD|POST)$) {
- return ;
- }
然后,在网站相关配置中的 location / { 之后插入如下代码:
- include agent_deny.conf;
如博客的配置:
- [marsge@Mars_Server ~]$ cat /usr/local/nginx/conf/zhangge.conf
- location / {
- try_files $uri $uri/ /index.php?$args;
- #這個位置新增1行:
- include agent_deny.conf;
- rewrite ^/sitemap_360_sp.txt$ /sitemap_360_sp.php last;
- rewrite ^/sitemap_baidu_sp.xml$ /sitemap_baidu_sp.php last;
- rewrite ^/sitemap_m.xml$ /sitemap_m.php last;
保存后,执行如下命令,平滑重启nginx 即可:
- /usr/local/nginx/sbin/nginx -s reload
三、PHP 代码
将如下方法放到贴到网站入口文件index.php 中的第一个<?php 之后即可:
- //获取UA信息
- $ua = $_SERVER['HTTP_USER_AGENT'];
- //将恶意USER_AGENT存入数组
- $now_ua = array('FeedDemon ','BOT/0.1 (BOT for JCE)','CrawlDaddy ','Java','Feedly','UniversalFeedParser','ApacheBench','Swiftbot','ZmEu','Indy Library','oBot','jaunty','YandexBot','AhrefsBot','MJ12bot','WinHttp','EasouSpider','HttpClient','Microsoft URL Control','YYSpider','jaunty','Python-urllib','lightDeckReports Bot');
- //禁止空USER_AGENT,dedecms等主流采集程序都是空USER_AGENT,部分sql注入工具也是空USER_AGENT
- if(!$ua) {
- header("Content-type: text/html; charset=utf-8");
- die('请勿采集本站');
- }else{
- foreach($now_ua as $value )
- //判断是否是数组中存在的UA
- if(eregi($value,$ua)) {
- header("Content-type: text/html; charset=utf-8");
- die('请勿采集本站!');
- }
- }
四、测试效果
如果是vps,那非常简单,使用curl -A 模拟抓取即可,比如:
模拟宜搜蜘蛛抓取:
- curl -I -A 'YisouSpider' zhang.ge
模拟UA 为空的抓取:
- curl -I -A '' zhang.ge
模拟百度蜘蛛的抓取:
- curl -I -A 'Baiduspider' zhang.ge
三次抓取结果截图如下:
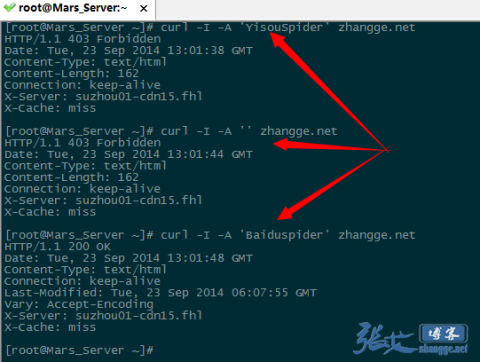
可以看出,宜搜蜘蛛和UA 为空的返回是403 禁止访问标识,而百度蜘蛛则成功返回200,说明生效!
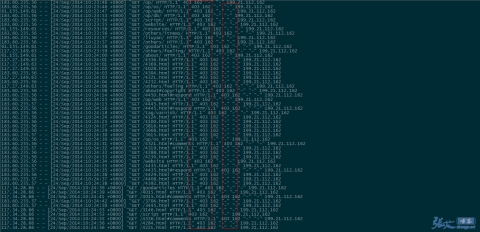
补充:第二天,查看nginx 日志的效果截图:
①、UA 信息为空的垃圾采集被拦截:
②、被禁止的UA 被拦截:
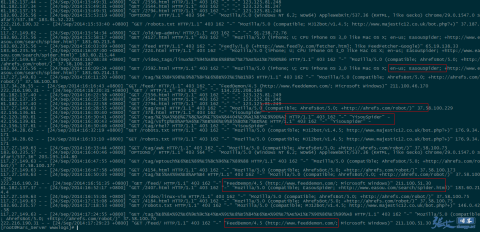
因此,对于垃圾蜘蛛的收集,我们可以通过分析网站的访问日志,找出一些没见过的的蜘蛛(spider)名称,经过查询无误之后,可以将其加入到前文代码的禁止列表当中,起到禁止抓取的作用。
五、附录:UA 收集
下面是网络上常见的垃圾UA 列表,仅供参考,同时也欢迎你来补充。
- FeedDemon 内容采集
- BOT/0.1 (BOT for JCE) sql注入
- CrawlDaddy sql注入
- Java 内容采集
- Jullo 内容采集
- Feedly 内容采集
- UniversalFeedParser 内容采集
- ApacheBench cc攻击器
- Swiftbot 无用爬虫
- YandexBot 无用爬虫
- AhrefsBot 无用爬虫
- YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
- MJ12bot 无用爬虫
- ZmEu phpmyadmin 漏洞扫描
- WinHttp 采集cc攻击
- EasouSpider 无用爬虫
- HttpClient tcp攻击
- Microsoft URL Control 扫描
- YYSpider 无用爬虫
- jaunty wordpress爆破扫描器
- oBot 无用爬虫
- Python-urllib 内容采集
- Indy Library 扫描
- FlightDeckReports Bot 无用爬虫
- Linguee Bot 无用爬虫
服务器反爬虫攻略:Apache/Nginx/PHP禁止某些User Agent抓取网站的更多相关文章
- Nginx反爬虫: 禁止某些User Agent抓取网站
问题 之前客户能够正常访问的一个网站这几天访问很慢,甚至有时候还拒绝访问.通过Nginx访问日志排查,发现有大量的请求指向同一个页面,而且访问的客户端IP地址在不断变化且没有太多规律,很难通过限制IP ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- Apache服务器故障排除攻略
Apache服务器故障排除攻略 应用服务器Apache浏览器配置管理网络应用 随着网络技术的普及.应用和Web技术的不断完善,Web服务已经成为互联网上重要的服务形式之一.原有的客户端/服务器模式正 ...
- 58 字体反爬攻略 python3
1.下载安装包 pip install fontTools 2.下载查看工具FontCreator 百度后一路傻瓜式安装即可 3.反爬虫机制 网页上看见的 后台源代码里面的 从上面可以看出,生这个字变 ...
- 爬虫学习笔记(1)-- 利用Python从网页抓取数据
最近想从一个网站上下载资源,懒得一个个的点击下载了,想写一个爬虫把程序全部下载下来,在这里做一个简单的记录 Python的基础语法在这里就不多做叙述了,黑马程序员上有一个基础的视频教学,可以跟着学习一 ...
- Python爬虫入门教程 24-100 微医挂号网医生数据抓取
1. 写在前面 今天要抓取的一个网站叫做微医网站,地址为 https://www.guahao.com ,我们将通过python3爬虫抓取这个网址,然后数据存储到CSV里面,为后面的一些分析类的教程做 ...
- 网页爬虫--python3.6+selenium+BeautifulSoup实现动态网页的数据抓取,适用于对抓取频率不高的情况
说在前面: 本文主要介绍如何抓取 页面加载后需要通过JS加载的数据和图片 本文是通过python中的selenium(pyhton包) + chrome(谷歌浏览器) + chromedrive(谷歌 ...
- linux服务器安全配置攻略
引言: 最小的权限+最少的服务=最大的安全 所以,无论是配置任何服务器,我们都必须把不用的服务关闭.把系统权限设置到最小话,这样才能保证服务器最大的安全.下面是CentOS服务器安全设置,供大家参考. ...
- (转)linux服务器安全配置攻略
引言: 最小的权限+最少的服务=最大的安全 所以,无论是配置任何服务器,我们都必须把不用的服务关闭.把系统权限设置到最小话,这样才能保证服务器最大的安全.下面是CentOS服务器安全设置,供大家参考. ...
随机推荐
- $_SERVER["HTTP_HOST"]
$_SERVER["HTTP_HOST"]访问的网站的域名
- unittest单元测试框架之coverage代码覆盖率统计
什么是coveage? coverage是一个检测单元测试覆盖率的工具,即检查你的测试用例是否覆盖到了所有的代码.当你通过pip install coverage成功安装完coverage后,就会在p ...
- IntelliJ IDEA建立source同级的文件夹
1.项目中一般都是将配置文档放入到config的source文件夹下,但是IDE没有直接建立source文件夹的方式,所以我们只做文件夹需要如下操作: 选中项目--->右键,选择new ---& ...
- Web挖掘
Web挖掘 Web挖掘的目标是从Web的超链接.网页内容和使用日志中探寻有用的信息.依据Web挖掘任务,可以划分为三种主要类型:Web结构挖掘.Web内容挖掘和Web使用挖掘.Web结构挖掘简单的说就 ...
- dojoConfig包的配置(7/26号夜)
主页代码: <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> ...
- 布局分析002:入门级的CSS导航弹出菜单
这种弹出菜单非常有意思,也有记录的意义,甚至可以说,掌握了这种弹出菜单,基本上CSS掌握的差不多. 主要涉及下面三个重要知识: CSS的继承性质. relative absolute定位. 子选择符& ...
- Linux 基础教程 40-df和du命令
df df用于显示文件系统的整体磁盘使用量. 基本用法 df [选项] [目录/文件] 其常用选项如下所示: 选项 说明 -a, --all 显示所有文件系统,包括/proc等虚拟文件系统 - ...
- django def validate_column和validate
VIewDemo class RegUserSet(mixins.CreateModelMixin,viewsets.GenericViewSet): serializer_class = RegUs ...
- OpenStack 业务链networking-sfc介绍 (1) - 概述
原文链接:https://blog.csdn.net/bc_vnetwork/article/details/65630355 1. Service Function Chain概述 Neutron ...
- Delphi XE7的安卓程序如何调用JAVA的JAR,使用JAVA的类?
本文使用工具和全部源码下载: http://download.csdn.net/detail/sunylat/8190765 为什么我们要在Delphi XE7的安卓程序调用JAVA的JAR,使用JA ...