3.4 目录和spooling
文件管理部分主要讲文件目录.文件目录它是用于检索文件的.文件目录它是一种文件系统实现按0存取的一种重要手段.一个文件目录它由若干个目录项组成的.每一个目录项它记录了一个文件的相关信息.这个文件信息指明了文件的文件名,文件类型,文件的物理信息,存储的相关的位置,包括建立日期啊相关的一些属性.所以通过对文件的目录项进行分析,就可以得到文件的一些常用的信息.
文件目录有三种目录结构形式.一级目录有一个很大的问题,就是文件名它不能够同名.因为只有一个目录,一个目录如果有多个用户在使用它,用户有自己的取名的习惯,那么很有可能它就会有文件名相同的.一级目录只有一个目录,那么它就不允许存在文件名同名.所以这种形式的目录结构只适用于单用户的系统.
第二种是二级目录结构.二级目录结构它分了两级,第一级的就是主文件目录,主文件目录有很多目录项,这个目录项是按用户来分配的.二级目录把每一个用户分配了一个目录,这些目录之间就可以存在同名了.在不同的目录允许有同名的现象.
windows和doc系统都是使用的是树型目录结构.树型目录结构可以分很多级了.


在树型的目录结构当中,任何一个文件或者是目录,它的路径表示法有两种:一种表示法是绝对路径表示法.绝对路径表示法是指的从根目录开始,逐级的标出这个路径来.从根目录到每一个目录、每一个文件它都有唯一的一条路径.这一条路径就是绝对路径.当前目录底下我们可以直接访问里面的文件.也就是说有一个相对路径,相对路径它是从当前目录开始写这个目录结构的.相对路径的提出使得这个结构变得简化了.W1/f1是相对路径.
二级目录讲过在不同的目录底下我们是允许有同样名字的文件的,但是相同目录底下是不允许有同名的.树型目录结构相当于是二级目录的扩充,每一个用户目录它可以根据自己的情况创建任何名字的一个文件.如果用户D2他创建了一个f2文件是用于存储email地址的一个列表,而D1用户他存储的这个f2不是这个含义,他是存的他的重要资料的一个目录.
方式1采用的是一个相对路径,方式2采用的是一个绝对路径.相对路径和绝对路径它的一个最大区别就是一个必须要从根目录开始一级一级往下找,另外一个就从当前目录往下找就可以了.很明显从当前目录往下面找它要找的这个范围就小了很多.范围小了它的效率也就高了,所以说方式1之所以效率高,是因为它可以从当前路径开始查找所需要的文件.
C选项提到方式1只需要访问1次磁盘,那么实际情况并不是这样子.前面提过目录项里面是存了一个文件的大致信息,它这些信息包括了它的修改时间、创建时间、作者、文件的性质、文件的扩展名等等等等,还包括一个重要东西:文件的起始地址.所以从这个意义上来讲,存储一个文件是把它拆分成了两个部分,一个是目录项,记录了大致的信息,这个是存放在目录表里面的,目录文件里面的.然后就是具体的文件的内容,是存在另外一块空间的.而根据这个目录项我们就可以找到这块空间.所以要访问/打开这个f1,它就要两次访问这个磁盘.第1次是找到/访问这个目录项,把这个目录项的内容找出来,然后取出它目录项里面记录的文件的真实首地址,就把这个文件全部都读出来.所以它要经历两次读取磁盘.所以C和D都是错误的.

Spooling技术
属于设备管理的内容.缓冲的机制.假脱机技术.理解SPOOLING靠技术的含义.
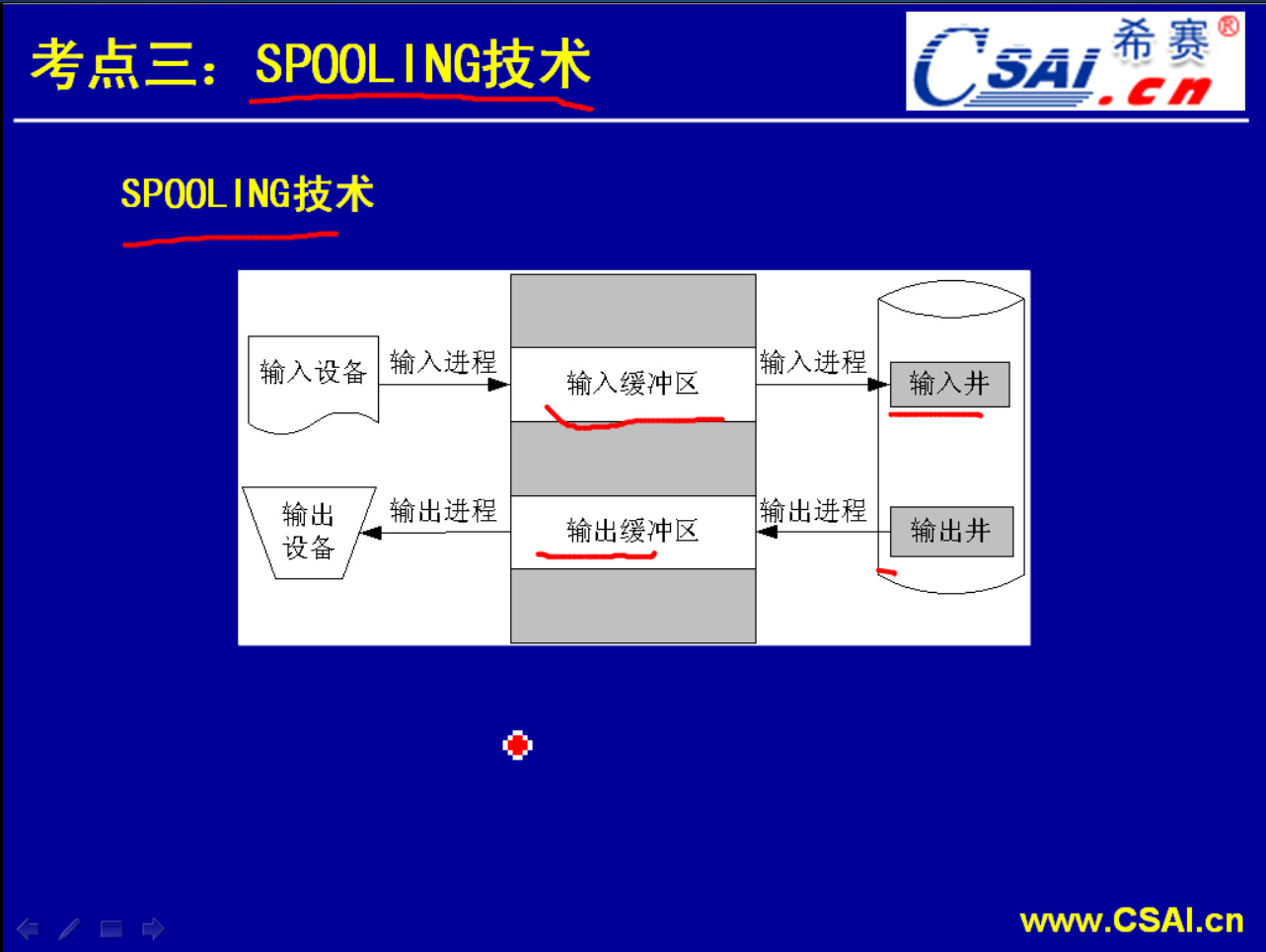
因为打印机是独占设备,它不能够同时几个人打印.关键问题是我们现在不晓得A要用多久,是1分钟呢还是1个小时呢还是10个小时呢?这样B、C、D要做的工作是隔一会儿就提交一次打印,结果就会发现失败.打印机仅仅会告诉你提交失败,现在有人在用这个资源但是它不会告诉你你什么时候申请能够得到资源.这种状态就比较麻烦了,B、C、D老是在尝试但是老是无法完成它的工作.是不是有一种方案我提交之后我就不管了,打印完之后我去拿就可以了呢?这就是SPOOLING技术的想法了.也就是说它们提交作业A、B、C、D并不是直接提交给打印机,而是提交给虚拟打印机,这个虚拟打印机是缓冲池/输入井,它们提交的内容会一条一条的记录在这个缓冲区当中,然后由缓冲区给打印机派发任务,这样子即使A、B、C、D四个人同时提交打印,也不会发生冲突因为你的信息会暂时放在缓冲区当中,逐个的提交给这个打印机.打印机会逐个的完成这些打印任务.然后A、B、C、D直接隔一段时间去取就可以了.而不要老是反复地去提交而提交又失败.这种形式就被称为SPOOLING技术.

3.4 目录和spooling的更多相关文章
- flume 前世今生
Cloudera 开发的分布式日志收集系统 Flume,是 hadoop 周边组件之一.其可以实时的将分布在不同节点.机器上的日志收集到不同的存储系统.Flume 初始的发行版本目前被统称为 Flum ...
- 分布式日志收集收集系统:Flume(转)
Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力.Fl ...
- FLUME NG的基本架构
Flume简介 Flume 是一个cloudera提供的 高可用高可靠,分布式的海量日志收集聚合传输系统.原名是 Flume OG (original generation),但随着 FLume 功能 ...
- Nginx日志通过Flume导入到HDFS中
关注公众号:分享电脑学习回复"百度云盘" 可以免费获取所有学习文档的代码(不定期更新) flume上传到hdfs: 当我们的数据量比较大时,比如每天的日志文件达到5G以上 使用ha ...
- Flume-ng-1.4.0 spooling source的方式增加了对目录的递归检测的支持
因为flume的spooldir不支持子目录文件的递归检测,并且业务需要,所以修改了源码,重新编译 代码修改参考自:http://blog.csdn.net/yangbutao/article/det ...
- 把Flume的Source设置为 Spooling directory source
把Flume的Source设置为 Spooling directory source,在设定的目录下放置需要读取的文件,一些文件在读取过程中会报错. 文件格式和报错如下: 实验一 读取汉子和“:&qu ...
- 带你看懂大数据采集引擎之Flume&采集目录中的日志
一.Flume的介绍: Flume由Cloudera公司开发,是一种提供高可用.高可靠.分布式海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于采集数据:同时,flum ...
- 1.8-1.10 大数据仓库的数据收集架构及监控日志目录日志数据,实时抽取之hdfs系统上
一.数据仓库架构 二.flume收集数据存储到hdfs 文档:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#hd ...
- Flume-Spooling Directory Source 监控目录下多个新文件
使用 Flume 监听整个目录的文件,并上传至 HDFS. 一.创建配置文件 flume-dir-hdfs.conf https://flume.apache.org/FlumeUserGuide.h ...
随机推荐
- attack on titans(动态规划递推,限制条件,至少转至多方法,进击的巨人)
题目意思: 给n个士兵排队,每个士兵三种G.R.P可选,求至少有m个连续G士兵,最多有k个连续R士兵的排列的种数. 原题 Attack on Titans Time Limit: 2 Seconds ...
- 洛谷—— P1450 [HAOI2008]硬币购物
P1450 [HAOI2008]硬币购物 硬币购物一共有$4$种硬币.面值分别为$c1,c2,c3,c4$.某人去商店买东西,去了$tot$次.每次带$di$枚$ci$硬币,买$si$的价值的东西.请 ...
- 「 Luogu P1231 」 教辅的组成
题目大意 有 $\text{N1}$ 本书 $\text{N2}$本练习册 $\text{N3}$本答案,一本书只能和一本练习册和一本答案配对.给你一些书和练习册,书和答案的可能的配对关系.问你最多可 ...
- World Cup(The 2016 ACM-ICPC Asia China-Final Contest dfs搜索)
题目: Here is World Cup again, the top 32 teams come together to fight for the World Champion. The tea ...
- 服务器做ssh免秘钥登陆
集群内服务器做非root用户免秘钥登陆:1.node1新建用户abc1,制作公钥.私钥(一路回车键即可)ssh-keygen –t rsa将自动在/home/abc1/.ssh/目录下创建公私钥文件如 ...
- APUE 文件IO
文件 IO 记录书中的重要知识和思考实践部分 Unix 每个文件都对应一个文件描述符(file descriptor),为一个非负整数,一个文件可以有多个fd, 后面所有与文件(设备,套接字等)有关操 ...
- ubuntu 下安装wine
PPA地址: https://launchpad.net/~ubuntu-wine/+archive/ppa 添加wine的ppa源 sudo add-apt-repository ppa:ubunt ...
- 全面了解cookie和session
http协议: http即超文本传输协议(万维网定义的),一种基于浏览器请求与服务器响应的链接,它是一个很纯粹的传输协议.http协议主要的特征就是它是一种无状态的协议(只针对cookie与sessi ...
- 运用循环求和( sum operation in python)
1.for loop example 1: sum of 1+2+...+10 ********** >>> sum=0 >>> for x in [1,2,3,4 ...
- 【模板】Lca倍增法
Codevs 1036 商务旅行 #include<cstdio> #include<cmath> #include<algorithm> using namesp ...