【机器学习算法-python实现】协同过滤(cf)的三种方法实现
(转载请注明出处:http://blog.csdn.net/buptgshengod)
1.背景
icf指的是item collaborative filtering,是将商品进行分析推荐。同理ucf的u指的是user,他是找出知趣类似的人,进行推荐。
通常来讲icf的准确率可能会高一些。通过这次參加天猫大数据比赛。我认为仅仅有在数据量很庞大的时候才适合用cf,假设数据量很小。cf的准确率会很可怜。
博主在比赛s1阶段,大概仅仅有几万条数据的时候,尝试了icf,准确率不到百分之中的一个。
。。
。。
2.经常用法

(1)欧氏距离法
数值越小。表示类似的越高。
def OsDistance(vector1, vector2):
sqDiffVector = vector1-vector2
sqDiffVector=sqDiffVector**2
sqDistances = sqDiffVector.sum()
distance = sqDistances**0.5
return distance
(2)皮尔逊相关系数
两个变量之间的相关系数越高。从一个变量去预測还有一个变量的准确度就越高,这是由于相关系数越高,就意味着这两个变量的共变部分越多,所以从当中一个变量的变化就可越多地获知还有一个变量的变化。
假设两个变量之间的相关系数为1或-1,那么你全然可由变量X去获知变量Y的值。
· 当相关系数为0时。X和Y两变量无关系。
· 当X的值增大。Y也增大。正相关关系,相关系数在0.00与1.00之间
· 当X的值减小,Y也减小,正相关关系。相关系数在0.00与1.00之间
· 当X的值增大。Y减小,负相关关系。相关系数在-1.00与0.00之间
当X的值减小。Y增大,负相关关系,相关系数在-1.00与0.00之间
相关系数的绝对值越大。相关性越强,相关系数越接近于1和-1,相关度越强,相关系数越接近于0,相关度越弱。

在python中用函数corrcoef实现。详细方法见http://infosec.pku.edu.cn/~dulz/doc/Numpy_Example_List.htm
(3)余弦类似度
0度角的余弦值是1,而其它不论什么角度的
在比較过程中。向量的规模大小不予考虑,仅仅考虑到向量的指向方向。余弦相
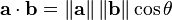
def cosSim(inA,inB):
num = float(inA.T*inB)
denom = la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom)
【机器学习算法-python实现】协同过滤(cf)的三种方法实现的更多相关文章
- python每次处理一个字符的三种方法
python每次处理一个字符的三种方法 a_string = "abccdea" print 'the first' for c in a_string: print ord(c) ...
- Python 文件行数读取的三种方法
Python三种文件行数读取的方法: #文件比较小 count = len(open(r"d:\lines_test.txt",'rU').readlines()) print c ...
- Python 判断文件是否存在的三种方法
通常在读写文件之前,需要判断文件或目录是否存在,不然某些处理方法可能会使程序出错.所以最好在做任何操作之前,先判断文件是否存在. 这里将介绍三种判断文件或文件夹是否存在的方法,分别使用os模块.Try ...
- python webdriver api-上传文件的三种方法
上传文件: 第一种方式,sendkeys(),最简单的 #encoding=utf-8 from selenium import webdriver import unittest import ti ...
- Python 中删除列表元素的三种方法
列表基本上是 Python 中最常用的数据结构之一了,并且删除操作也是经常使用的. 那到底有哪些方法可以删除列表中的元素呢?这篇文章就来总结一下. 一共有三种方法,分别是 remove,pop 和 d ...
- python列表删除重复元素的三种方法
给定一个列表,要求删除列表中重复元素. listA = ['python','语','言','是','一','门','动','态','语','言'] 方法1,对列表调用排序,从末尾依次比较相邻两个元素 ...
- 用Python获取Linux资源信息的三种方法
方法一:psutil模块 #!usr/bin/env python # -*- coding: utf-8 -*- import socket import psutil class NodeReso ...
- Python判断文件是否存在的三种方法
通常在读写文件之前,需要判断文件或目录是否存在,不然某些处理方法可能会使程序出错.所以最好在做任何操作之前,先判断文件是否存在. 这里将介绍三种判断文件或文件夹是否存在的方法,分别使用os模块.Try ...
- Python判断文件是否存在的三种方法【转】
转:http://www.cnblogs.com/jhao/p/7243043.html 通常在读写文件之前,需要判断文件或目录是否存在,不然某些处理方法可能会使程序出错.所以最好在做任何操作之前,先 ...
- python删除list中元素的三种方法
a.pop(index):删除列表a中index处的值,并且返回这个值. del(a[index]):删除列表a中index处的值,无返回值. del中的index可以是切片,所以可以实现批量删除. ...
随机推荐
- find 命令search使用
GNU在目录树中查找的时候,是根据所给的名字从根节点开始从左到右匹配.根据优先级规则,直到在某一个节点找到结果了才会移动到下一个文件名字. 1.找空目录 find ./path -depth -ty ...
- logging模块,程序日志模板
6.11自我总结 1.logging模块 用于程序的运行日志 1.初级 #首先程序运行分会出现5中情况 1.logging.info('info') #程序正常运行级别为10 2.logging.de ...
- python爬虫(爬取视频)
爬虫爬视频 爬取步骤 第一步:获取视频所在的网页 第二步:F12中找到视频真正所在的链接 第三步:获取链接并转换成机械语言 第四部:保存 保存步骤代码 import re import request ...
- Django之ORM操作(重要)
Django ORM操作 一般操作 看专业的官网文档,做专业的程序员! 必知必会13条 <1> all(): 查询所有结果 <2> get(**kwargs): 返回与所给 ...
- GitHub中国区前100名到底是什么样的人?(转载)
本文根据Github公开API,抓取了地址显示China的用户,根据粉丝关注做了一个排名,分析前一百名的用户属性,剖析这些活跃在技术社区的牛人到底是何许人也!后续会根据我的一些经验出品<技术人员 ...
- [jenkins学习篇] 安装jenkins
1 下载war包,https://jenkins.io/download/ 2 安装jar包,java -jar jenkins.war 3 打开网址:http://localhost:8080 4 ...
- cell展开的几种方式
一.插入新的cell 原理: (1)定义是否展开,和展开的cell的下标 @property (assign, nonatomic) BOOL isExpand; //是否展开 @property ( ...
- BZOJ 2337 [HNOI2011]XOR和路径 ——期望DP
首先可以各位分开求和 定义$f(i)$表示从i到n的期望值,然后经过一些常识,发现$f(n)=1$的时候的转移,然后直接转移,也可以找到$f(n)=0$的转移. 然后高斯消元31次就可以了. #inc ...
- Ubuntu 下使用 sshfs 挂载远程目录到本地
参考链接:http://blog.csdn.net/netwalk/article/details/12952719 一.Ubuntu 上安装sshfs Ubuntu源中已经包含了sshfs,以及所需 ...
- __getattr__ 与 __getattribute__的区别
原文博客地址 http://www.cnblogs.com/bettermanlu/archive/2011/06/22/2087642.html