HBase数据压缩编码探索
摘要: 本文主要介绍了hbase对数据压缩,编码的支持,以及云hbase在社区基础上对数据压缩率和访问速度上了进行的改进。
前言
你可曾遇到这种需求,只有几百qps的冷数据缓存,却因为存储水位要浪费几十台服务器?你可曾遇到这种需求,几百G的表,必须纯cache命中,性能才能满足业务需求?你可曾遇到,几十M的小表,由于qps过高,必须不停的split,balance,利用多台服务器来抗热点?
面对繁杂的场景,Ali-HBase团队一直致力于为业务提供更多的选择和更低的成本。本文主要介绍了hbase目前两种提高压缩率的主要方法:压缩和DataBlockEncoding。
无损压缩:更小,更快,更省资源
通用压缩作为数据库解决存储的重要手段,通常数据库都存在数据块的概念,针对每个块做压缩和解压。块越大,压缩率越高,scan throughput增加;块越小,随机读IO压力较小,读latency越小。作为一种Tradeoff,线上hbase通常采用64K块大小,在cache中不做压缩,仅在落盘和读盘时做压缩和解压操作。
开源hbase通常使用的LZO压缩或者Snappy压缩。这两种压缩的共同特点是都追求较高的压缩解压速度,并实现合理的数据压缩率。然而,随着业务的快速增涨,越来越多的业务因为因为存储水位问题而扩容。hbase针对这一情况,采用了基于跨集群分区恢复技术的副本数优化、机型升级等方法,但依然无法满足存储量的快速膨胀,因此我们一直致力于寻找压缩更高的压缩方式。
新压缩(zstd、lz4)上线
Zstandard(缩写为Zstd)是一种新的无损压缩算法,旨在提供快速压缩,并实现高压缩比。它既不像LZMA和ZPAQ那样追求尽可能高的压缩比,也不像LZ4那样追求极致的压缩速度。这种算法的压缩速度超过200MB/s, 解压速度超过400MB/s(实验室数据),基本可以满足目前hbase对吞吐量的需求。经验证,Zstd的数据压缩率相对于Lzo基本可以提高25%-30%,对于存储型业务,这就意味着三分之一到四分之一的的成本减少。
而在另一种情况下,部分表存储量较小,但qps大,对rt要求极高。针对这种场景,我们引入了lz4压缩,其解压速度在部分场景下可以达到lzo的两倍以上。一旦读操作落盘需要解压缩,lz4解压的rt和cpu开销都明显小于lzo压缩。
我们先通过一张图片直观的展示各种压缩算法的性能: 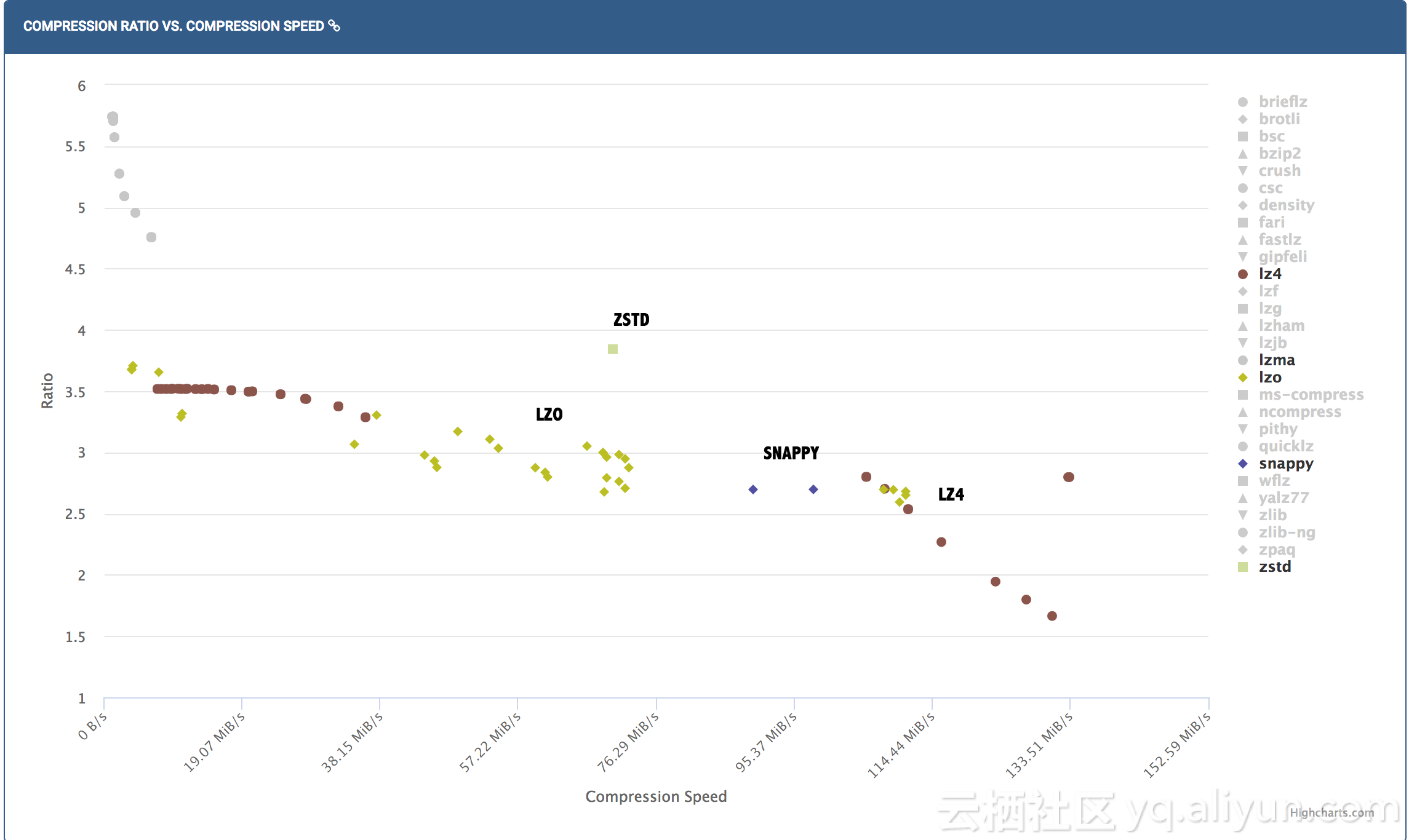
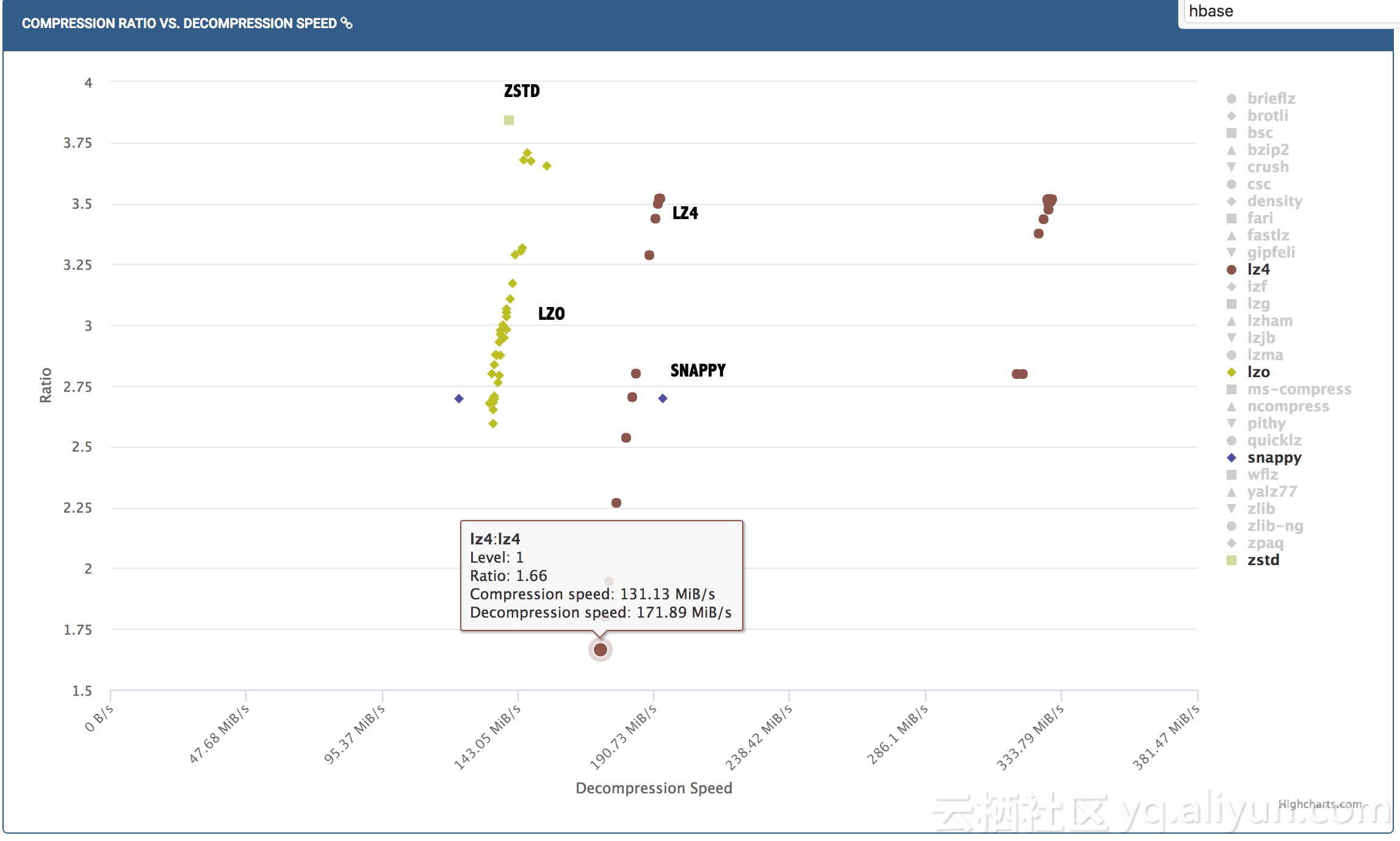
以线上几种典型数据场景为例,看看几种压缩的实际压缩率和单核解压速度(以下数据均来自于实际应用)
| 业务类型 | 无压缩表大小 | LZO(压缩率/解压速度MB/s) | ZSTD(压缩率/解压速度MB/s) | LZ4(压缩率/解压速度MB/s) |
|---|---|---|---|---|
| 监控类 | 419.75T | 5.82/372 | 13.09/256 | 5.19/463.8 |
| 日志类 | 77.26T | 4.11/333 | 6.0/287 | 4.16/ 496.1 |
| 风控类 | 147.83T | 4.29/297.7 | 5.93/270 | 4.19/441.38 |
| 消费类 | 108.04T | 5.93/316.8 | 10.51/288.3 | 5.55/520.3 |
目前,2017年双11,ZSTD已经在线上全面铺开,已累计优化存储数PB。LZ4也已经在部分读要求较高业务上线。
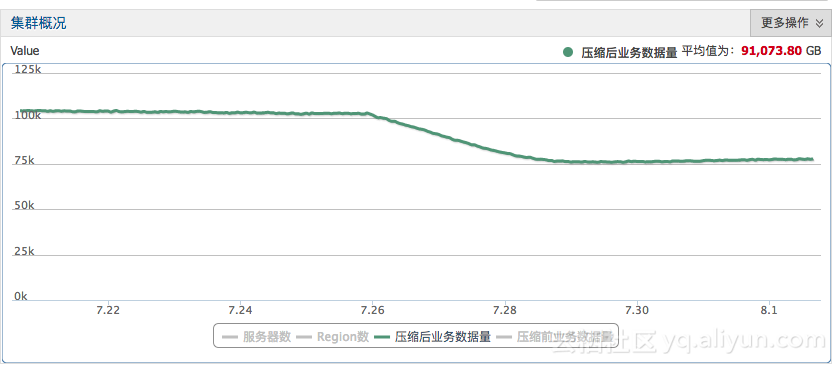
下图为某监控类应用zstd压缩算法后,集群整体存储量的下降情况。数据量由100+T减少到75T。
编码技术:针对结构化数据的即查即解压
hbase作为一种schema free的数据库,相当于传统的关系型数据库更加灵活,用户无需设计好表的结构,也可以在同一张表内写入不同schema的数据。然而,由于缺少数据结构的支持,hbase需要很多额外的数据结构来标注长度信息,且无法针对不同的数据类型采用不同的压缩方式。针对这一问题,hbase提出了编码功能,用来降低存储开销。由于编码对cpu开销较小,且效果较好,通常cache中也会开启编码功能。
旧DIFF Encoding介绍
hbase很早就支持了DataBlockEncoding,也就是是通过减少hbase keyvalue中重复的部分来压缩数据。 以线上最常见的DIFF算法为例,某kv压缩之后的结果:
- 一个字节的flag(这个flag的作用后面解释)
- 如果和上个KV的键长不一样,则写入1~5个字节的长度
- 如果和上个KV的值长不一样,则写入1~5个字节的长度
- 记录和上个KV键相同的前缀长度,1~5个字节
- 非前缀部分的row key
- 如果是第一条KV,写入列族名
- 非前缀部分的的列名
- 写入1~8字节的timestamp或者与上个KV的timestamp的差(是原值还是写与上个KV的差,取决于哪个字节更小)
- 如果和上个KV的type不一样,则写入1字节的type(Put,Delete)
- Value内容
那么在解压缩时,怎么判断和上个KV的键长是否一样,值长是否一样,写入的时间戳究竟是是原值还是差值呢?这些都是通过最早写入的1个字节的flag来实现的,
这个字节中的8位bit,含义是:
- 第0位,如果为1,键长与上个kv相等
- 第1位,如果为1,值长与上个kv相等
- 第2位,如果为1,type与上个kv一样
- 第3位,如果为1,则写入的timestamp是差值,否则为原值
- 第456位,这3位组合起来的值(能表示0~7),表示写入的时间戳的长度
- 第7位,如果为1,表示写入的timestamp差值为负数,取了绝对值。
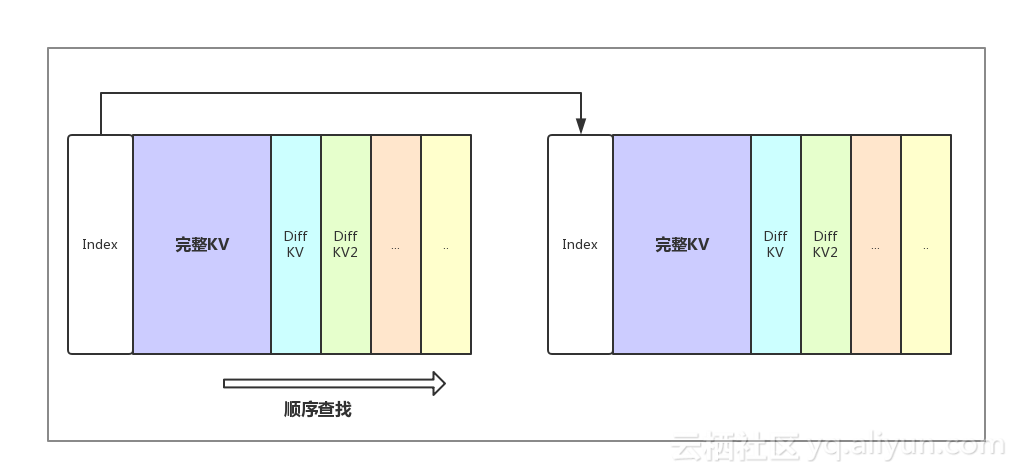
DIFF 编码之后,对某个文件的seek包含以下两步:
- 通过index key找到对应的datablock
- 从第一个完整KV开始,顺序查找,不断decode下一个kv,直到找到目标kv为止。
DIFF encoding对小kv场景使用效果较好,可以减少2-5倍的数据量。
新Indexable Delta Encoding上线
从性能角度考虑,hbase通常需要将Meta信息装载进block cache。如果将block大小较小,Meta信息较多,会出现Meta无法完全装入Cache的情况, 性能下降。如果block大小较大,DIFF Encoding顺序查询的性能会成为随机读的性能瓶颈。针对这一情况,我们开发了Indexable Delta Encoding,在block内部也可以通过索引进行快速查询,seek性能有了较大提高。Indexable Delta Encoding原理如图所示:
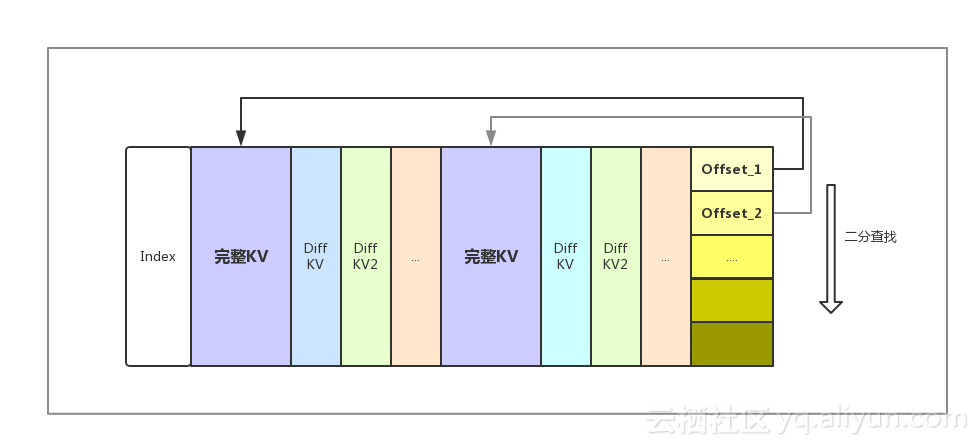
在通过BlockIndex找到对应的数据块后,我们从数据块末尾找到每个完整KV的offset,并利用二分查找快速定位到符合查询条件的完整kv,再顺序decode每一个Diff kv,直到找到目标kv位置。
通过Indexable Delta Encoding, HFile的随机seek性能相对于使用之前翻了一倍,以64K block为例,在全cache命中的随机Get场景下,相对于Diff encoding rt下降50%,但存储开销仅仅提高3-5%。Indexable Delta Encoding目前已在线上多个场景应用,经受了双十一的考验,整体平均读rt减少10%-15%。
云端使用
阿里HBase目前已经在阿里云提供商业化服务,任何有需求的用户都可以在阿里云端使用深入改进的、一站式的HBase服务。云HBase版本与自建HBase相比在运维、可靠性、性能、稳定性、安全、成本等方面均有很多的改进,更多内容欢迎大家关注 https://www.aliyun.com/product/hbase
转自:https://yq.aliyun.com/articles/277084
交流
如果大家对HBase有兴趣,致力于使用HBase解决实际的问题,欢迎加入Hbase技术社区群交流:
微信HBase技术社区群,假如微信群加不了,可以加秘书微信: SH_425 ,然后邀请您。

钉钉HBase技术社区群

HBase数据压缩编码探索的更多相关文章
- BigData NoSQL —— ApsaraDB HBase数据存储与分析平台概览
一.引言 时间到了2019年,数据库也发展到了一个新的拐点,有三个明显的趋势: 越来越多的数据库会做云原生(CloudNative),会不断利用新的硬件及云本身的优势打造CloudNative数据库, ...
- HBase 数据读写流程
HBase 数据读写流程 2016-10-18 杜亦舒 读数据 HBase的表是按行拆分为一个个 region 块儿,这些块儿被放置在各个 regionserver 中 假设现在想在用户表中获取 ro ...
- Hive 实现HBase 数据批量插入
HBase 数据的插入可以使用Java API 来写Java 程序逐条倒入,但是不是很方便.利用Hive自带的一个Jar包,可以建立Hive和HBase的映射关系 利用Hive 的insert可以将批 ...
- HBase数据导出到HDFS
一.目的 把hbase中某张表的数据导出到hdfs上一份. 实现方式这里介绍两种:一种是自己写mr程序来完成,一种是使用hbase提供的类来完成. 二.自定义mr程序将hbase数据导出到hdfs上 ...
- HBase 学习之一 <<HBase使用客户端API动态创建Hbase数据表并在Hbase下导出执行>>
HBase使用客户端API动态创建Hbase数据表并在Hbase下导出执行 ----首先感谢网络能够给我提供一个开放的学习平台,如果没有网上的技术爱好者提供 ...
- 怎样将关系型数据表转换至hbase数据表
首先须要把关系型数据库的数据表的数据添加由 "纵向延伸",转变为HBase数据表的"横向延伸" 一.Hbase的存储结构 a) HBase以表(HTa ...
- HBase数据存储格式
好的数据结构,对于检索数据,插入数据的效率就会很高. 常见的数据结构 B+树 根节点和枝节点非常easy,分别记录每一个叶子节点的最小值,并用一个指针指向叶子节点. 叶子节点里每一个键值都指向真正的 ...
- HBase数据同步ElasticSearch该程序
ElasticSearch的River机械 ElasticSearch本身就提供了River机械,对于同步数据. 在这里,现在能找到的官方推荐River: http://www.elasticsear ...
- HBase数据备份及恢复(导入导出)的常用方法
一.说明 随着HBase在重要的商业系统中应用的大量增加,许多企业需要通过对它们的HBase集群建立健壮的备份和故障恢复机制来保证它们的企业(数据)资产.备份Hbase时的难点是其待备份的数据集可能非 ...
随机推荐
- 机房合作(三):We are Team,We are Family
导读:拖拖拉拉,机房的合作也算是接近了尾声了.在这个过程中,真心是感谢我的两个组员.这个机房合作,看似简单,但我的组员给我的帮助和感动,都是不可忽略的.记得刚开始的时候,我就说过:不怕猪一样的组长,咱 ...
- 【Luogu】P2762太空飞行计划(最大权闭合图)
题目链接 woc这题目的输入格式和输出格式真的恶心 首先我们就着样例讲一下闭合图 如图所示,第一层是两个实验节点,带来正收益:第二层是三个仪器节点,带来负收益:问讲道理到终点可以获得多大收益. 闭合图 ...
- NIO Channel的学习笔记总结
摘自:http://blog.csdn.net/tsyj810883979/article/details/6876603 1.1 非阻塞模式 Java NIO非堵塞应用通常适用用在I/O读写等方 ...
- 【CCF】交通规划 Dijstra变形 优先级队列重载
[题意] 给定一个无向图,求这个图满足所有点到顶点的最短路径不变的最小生成树 [AC] 注意双向边要开2*maxm 注意优先级队列 参考https://www.cnblogs.com/cielosun ...
- day2之爬取拉勾网
认证流程 浏览器清空cookies 步骤一 访问拉勾网网站 https://www.lagou.com/ 做了些什么: 以get方式请求"https://www.lagou.com/&qu ...
- *AtCoder Regular Contest 096E - Everything on It
$n \leq 3000$个酱,丢进拉面里,需要没两碗面的酱一样,并且每个酱至少出现两次,面的数量随意.问方案数.对一给定质数取模. 没法dp就大力容斥辣.. $Ans=\sum_{i=0}^n (- ...
- 使用<sstream> 替代<stdio.h>
c++ 字符串流 sstream(常用于格式转换) 使用stringstream对象简化类型转换C++标准库中的<sstream>提供了比ANSI C的<stdio.h>更 ...
- AC日记——小书童——刷题大军 洛谷 P1926
题目背景 数学是火,点亮物理的灯:物理是灯,照亮化学的路:化学是路,通向生物的坑:生物是坑,埋葬学理的人. 文言是火,点亮历史宫灯:历史是灯,照亮社会之路:社会是路,通向哲学大坑:哲学是坑,埋葬文科生 ...
- 记一次ORM的权衡和取舍
面对ORM的选型,有些人是根据自己熟悉程度来评判,有些人是根据他人的推荐来抉择,有些人觉得都差不多,随便了.当自己要真正做选择的时候,以上的这些依据都无法真正说服自己,因为不同的业务需求,不同的团队构 ...
- BZOJ——1611: [Usaco2008 Feb]Meteor Shower流星雨
http://www.lydsy.com/JudgeOnline/problem.php?id=1611 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 1 ...