【R语言进行数据挖掘】回归分析
1、线性回归
线性回归就是使用下面的预测函数预测未来观测量:

其中,x1,x2,...,xk都是预测变量(影响预测的因素),y是需要预测的目标变量(被预测变量)。
线性回归模型的数据来源于澳大利亚的CPI数据,选取的是2008年到2011年的季度数据。
rep函数里面的第一个参数是向量的起始时间,从2008-2010,第二个参数表示向量里面的每个元素都被4个小时间段。
year <- rep(2008:2010, each=4)
quarter <- rep(1:4, 3)
cpi <- c(162.2, 164.6, 166.5, 166.0,
- 166.2, 167.0, 168.6, 169.5,
171.0, 172.1, 173.3, 174.0)
plot函数中axat=“n”表示横坐标刻度的标注是没有的
plot(cpi, xaxt="n", ylab="CPI", xlab="")
绘制横坐标轴
axis(1, labels=paste(year,quarter,sep="Q"), at=1:12, las=3)
接下来,观察CPI与其他变量例如‘year(年份)’和‘quarter(季度)’之间的相关关系。
cor(year,cpi)
cor(quarter,cpi)
输出如下:
cor(quarter,cpi)
[1] 0.3738028
cor(year,cpi)
[1] 0.9096316
cor(quarter,cpi)
[1] 0.3738028
由上图可知,CPI与年度之间的关系是正相关,并且非常紧密,相关系数接近1;而它与季度之间的相关系数大约为0.37,只是有着微弱的正相关,关系并不明显。
然后使用lm()函数建立一个线性回归模型,其中年份和季度为预测因素,CPI为预测目标。
建立模型fit
fit <- lm(cpi ~ year + quarter)
fit
输出结果如下:
Call:
lm(formula = cpi ~ year + quarter)
Coefficients:
(Intercept) year quarter
-7644.488 3.888 1.167
由上面的输出结果可以建立以下模型公式计算CPI:

其中,c0、c1和c2都是模型fit的参数分别是-7644.488、3.888和1.167。因此2011年的CPI可以通过以下方式计算:
(cpi2011 <-fit$coefficients[[1]] + fit$coefficients[[2]]*2011 +
- fit$coefficients[[3]]*(1:4))
输出的2011年的季度CPI数据分别是174.4417、175.6083、176.7750和177.9417。
模型的具体参数可以通过以下代码查看:
查看模型的属性
attributes(fit)
$names
[1] "coefficients" "residuals" "effects" "rank" "fitted.values"
[6] "assign" "qr" "df.residual" "xlevels" "call"
[11] "terms" "model"
$class
[1] "lm"
模型的参数
fit$coefficients
观测值与拟合的线性模型之间的误差,也称为残差
residuals(fit)
1 2 3 4 5 6 7
-0.57916667 0.65416667 1.38750000 -0.27916667 -0.46666667 -0.83333333 -0.40000000
8 9 10 11 12
-0.66666667 0.44583333 0.37916667 0.41250000 -0.05416667
除了将数据代入建立的预测模型公式中,还可以通过使用predict()预测未来的值。
输入预测时间
data2011 <- data.frame(year=2011, quarter=1:4)
cpi2011 <- predict(fit, newdata=data2011)
设置散点图上的观测值和预测值对应点的风格(颜色和形状)
style <- c(rep(1,12), rep(2,4))
plot(c(cpi, cpi2011), xaxt="n", ylab="CPI", xlab="", pch=style, col=style)
标签中sep参数设置年份与季度之间的间隔
axis(1, at=1:16, las=3,
- labels=c(paste(year,quarter,sep="Q"), "2011Q1", "2011Q2", "2011Q3", "2011Q4"))
预测结果如下:

上图中红色的三角形就是预测值。
2、Logistic回归
Logistic回归是通过将数据拟合到一条线上并根据简历的曲线模型预测事件发生的概率。可以通过以下等式来建立一个Logistic回归模型:

其中,x1,x2,...,xk是预测因素,y是预测目标。令
,上面的等式被转换成:

使用函数glm()并设置响应变量(被解释变量)服从二项分布(family='binomial,'link='logit')建立Logistic回归模型,更多关于Logistic回归模型的内容可以通过以下链接查阅:
· R Data Analysis Examples - Logit Regression
· 《LogisticRegression (with R)》
3、广义线性模型
广义线性模型(generalizedlinear model, GLM)是简单最小二乘回归(OLS)的扩展,响应变量(即模型的因变量)可以是正整数或分类数据,其分布为某指数分布族。其次响应变量期望值的函数(连接函数)与预测变量之间的关系为线性关系。因此在进行GLM建模时,需要指定分布类型和连接函数。这个建立模型的分布参数包括binomaial(两项分布)、gaussian(正态分布)、gamma(伽马分布)、poisson(泊松分布)等。
广义线性模型可以通过glm()函数建立,使用的数据是包‘TH.data’自带的bodyfat数据集。
data("bodyfat", package="TH.data")
myFormula <- DEXfat ~ age + waistcirc + hipcirc + elbowbreadth + kneebreadth
设置响应变量服从正态分布,对应的连接函数服从对数分布
bodyfat.glm <- glm(myFormula, family = gaussian("log"), data = bodyfat)
预测类型为响应变量
pred <- predict(bodyfat.glm, type="response")
plot(bodyfat$DEXfat, pred, xlab="Observed Values", ylab="Predicted Values")
abline(a=0, b=1)
预测结果检验如下图所示:
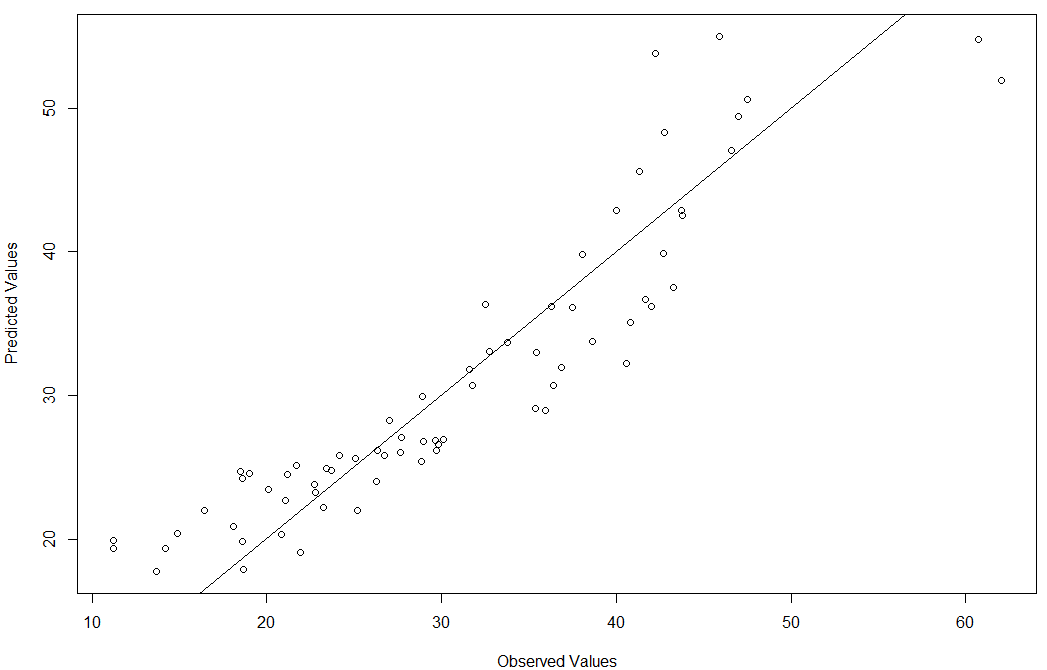
由上图可知,模型虽然也有离群点,但是大部分的数据都是落在直线上或者附近的,也就说明模型建立的比较好,能较好的拟合数据。
4、非线性回归
如果说线性模型是拟合拟合一条最靠近数据点的直线,那么非线性模型就是通过数据拟合一条曲线。在R中可以使用函数nls()建立一个非线性回归模型,具体的使用方法可以通过输入'?nls()'查看该函数的文档。
【R语言进行数据挖掘】回归分析的更多相关文章
- R语言 多元线性回归分析
#线性模型中有关函数#基本函数 a<-lm(模型公式,数据源) #anova(a)计算方差分析表#coef(a)提取模型系数#devinace(a)计算残差平方和#formula(a)提取模型公 ...
- 【R语言进行数据挖掘】决策树和随机森林
1.使用包party建立决策树 这一节学习使用包party里面的函数ctree()为数据集iris建立一个决策树.属性Sepal.Length(萼片长度).Sepal.Width(萼片宽度).Peta ...
- 大数据时代的精准数据挖掘——使用R语言
老师简介: Gino老师,即将步入不惑之年,早年获得名校数学与应用数学专业学士和统计学专业硕士,有海外学习和工作的经历,近二十年来一直进行着数据分析的理论和实践,数学.统计和计算机功底强悍. 曾在某一 ...
- 【R笔记】R语言函数总结
R语言与数据挖掘:公式:数据:方法 R语言特征 对大小写敏感 通常,数字,字母,. 和 _都是允许的(在一些国家还包括重音字母).不过,一个命名必须以 . 或者字母开头,并且如果以 . 开头,第二个字 ...
- R语言笔记完整版
[R笔记]R语言函数总结 R语言与数据挖掘:公式:数据:方法 R语言特征 对大小写敏感 通常,数字,字母,. 和 _都是允许的(在一些国家还包括重音字母).不过,一个命名必须以 . 或者字母开头, ...
- 【转】R语言函数总结
原博: R语言与数据挖掘:公式:数据:方法 R语言特征 对大小写敏感 通常,数字,字母,. 和 _都是允许的(在一些国家还包括重音字母).不过,一个命名必须以 . 或者字母开头,并且如果以 . 开头, ...
- [译]用R语言做挖掘数据《一》
介绍 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到程序: 1. ...
- R语言rvest包网络爬虫
R语言网络爬虫初学者指南(使用rvest包) 钱亦欣 发表于 今年 06-04 14:50 5228 阅读 作者 SAURAV KAUSHIK 译者 钱亦欣 引言 网上的数据和信息无穷无尽,如 ...
- R语言 逐步回归分析
逐步回归分析是以AIC信息统计量为准则,通过选择最小的AIC信息统计量,来达到删除或增加变量的目的. R语言中用于逐步回归分析的函数 step() drop1() add1() #1.载 ...
随机推荐
- mysql函数之八:mysql函数大全
对于针对字符串位置的操作,第一个位置被标记为1. ASCII(str) 返回字符串str的最左面字符的ASCII代码值.如果str是空字符串,返回0.如果str是NULL,返回NULL. mysql& ...
- 配置web应用
web应用配置虚拟主机1.web应用的虚拟路径映射,就是web应用的真实存在的路径配置一个虚拟路径 在conf目录下的Server.xml 的<Host>标签中,配置<Context ...
- $bzoj4569$
$st表+并查集$ $考虑暴力方法:我们每次将对应相等的位置用并查集连起来,那么最终答案就是9*10^{连通块个数-1}$ $很明显上面这个办法过不去,问题在于重复次数太多了,如果一个区间已经对应相等 ...
- ERROR (UnicodeEncodeError): 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128
ERROR (UnicodeEncodeError): 'ascii' codec can't encode characters in position 0-1: ordinal not in ra ...
- Android开发—— 传递数据
一:使用静态变量传递数据 (1)静态变量传递数据,在目标Activity中声明静态变量,然后使用setText()方法将静态变量的值导出即可: (2)静态变量传递数据,在主Activity中对目标Ac ...
- CodeForces 1098F. Ж-function
题目简述:给定字符串$s[1 \dots n](n \leq 2 \times 10^5)$,以及$Q \leq 2 \times 10^5$个询问,每个询问有两个参数$1 \leq l \leq r ...
- B - Alyona and Mex
Description Someone gave Alyona an array containing n positive integers a1, a2, ..., an. In one oper ...
- python 之 staticmethod,classmethod,property的区别
绑定方法和非绑定方法: 普通def定义的都是绑定给对象的方法,对象调用时会自动传入对象本事,而类调用时需手动传入对象. 加上@classmethod装饰器就是绑定给类的方法,会自动传类本身 加上@st ...
- 两种好用的清除浮动的小技巧(clearfix hack)
方法一:使用内容生成的方式清除浮动 这种方法不能解决margin在垂直边界上的叠加问题,如果不涉及margin的边界叠加问题使用这种方法清除浮动就行了 . /* :after 选择器向选定的元素之后插 ...
- Tessellation
Tessellation细分曲面技术是AMD(ATI)常年研发多代的技术,经过多年发展最终被采纳成为DX11的一项关键技术,因此历来都是宣传重点.和光线追踪不同,现在的光栅化图形渲染技术的核心是绘制大 ...