tensorflow:实战Google深度学习框架第三章
tensorflow的计算模型:计算图–tf.Graph
tensorflow的数据模型:张量–tf.Tensor
tensorflow的运行模型:会话–tf.Session
tensorflow可视化工具:TensorBoard
通过集合管理资源:tf.add_to_collection、tf.get_collection
Tensor主要三个属性:名字(name)、维度(shape)、类型(type)
#张量,可以简单的理解为多维数组 import tensorflow as tf
a = tf.constant([1.0,2.0],name='a')
b = tf.constant([3.0,4.0],name='b')
result = tf.add(a,b,name="add")
print(result) 输出:Tensor("add:0", shape=(2,), dtype=float32)
会话Session需要关闭才能释放资源,通过Python的上下文管理器 with ,可以自动释放资源
#创建会话,并通过上下文管理器来管理
with tf.Session() as sess:
sess.run(result)
#不需要Session.close()关闭会话
#上下文管理器退出,会话自动关闭
tensorflow设备:tf.device(‘/cpu:0’)、tf.device(‘/gpu:2’)
一、前向传播算法:
需要三个部分:神经网络的输入,神经网络的连接结构,每个神经元的参数
将前向传播算法使用矩阵乘法方式表示:
#将前向传播算法使用矩阵乘法方式表示:
a = tf.matmul(x,w1)#x是输入,w1是第一层的参数
y = tf.matmul(a,w2)#a是第一层的输出。w2是第二层的神经元的参数
在tensorflow中变量(tf.Variable)的作用:保存和更新神经网络的参数,变量需要指定初始值:
1、使用随机数初始化
#定义2*3的矩阵变量
weights = tf.Variable(tf.random_normal([2,3], stddev=2))
其他随机数生成函数在表3-2
表3-2 TensorFlow随机数生成函数
| 函数名称 | 随机数分布 | 主要参数 |
|---|---|---|
| tf.random_normal | 正太分布 | 平均值、标准差、取值类型 |
| tf.truncated_normal | 正太分布,如果随机出来的值偏离均值超过2个标准差,重新随机 | 平均值、标准差、取值类型 |
| tf.random_uniform | 平均分布 | 最小、最大取值、取值类型 |
| tf.random_gamma | Gamma分布 | 形状参数alpha、尺度参数beta、取值类型 |
2、使用常数初始化
import tensorflow as tf
#定义长度3的矩阵变量
weights = tf.Variable(tf.zeros([3]))#初始值为0,长度为3的变量
表3-3 TensorFlow常数生成函数
| 函数名称 | 功能 | 样例 |
|---|---|---|
| tf.zeros | 产生全0数组 | tf.zeros([2,3],int32)–>[[0,0,0],[0,0,0]] |
| tf.ones | 产生全1数组 | tf.ones(2,3],int32)–>[[1,1,1],[1,1,1]] |
| tf.fill | 产生一个给定值的数组 | tf.fill([2,3],9)–>[[9,9,9],[9,9,9]] |
| tf.constant | 产生一个给定值常量 | tf.constant([1,2,3])–>[1,2,3] |
3、使用其他变量进行初始化
import tensorflow as tf
w2 = tf.Variable(weights.initialized_value())#将w2初始化为与变量weights相同
w3 = tf.Variable(weights.initialized_value()*2)#将w2初始化为变量weights值的2倍
一个变量在使用前,必须先初始化
*(推荐)使用tf.initialize_all_variables()初始化所有变量
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
前向传播算法实现
import tensorflow as tf #声明w1和w2两个变量,使用seed参数设定随机种子,保证每次产生的随机数相同
w1 = tf.Variable(tf.random_normal([2,3], stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1], stddev=1,seed=1)) #暂时将输入定义为常量,x为1*2的矩阵
x = tf.constant([[0.7,0.9]]) #通过前向传播算法获得输出
a = tf.matmul(x,w1)
y = tf.matmul(a,w2) with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)#初始化所有变量
print(sess.run(y))
所有的变量都被自动的加入tf.GraphKeys.VARIABLES,通过tf.all_variables()函数获取当前计算图的所有变量,
在神经网络中可以使用变量声明函数中的trainable参数区分需要优化的参数(神经网络参数或迭代轮数),如当trainable=True ,这个变量将加入集合tf.GraphKeys.TRAINABLE_VARIABLES中,可以使用tf.trainable_variables()函数得到所有可学习的变量
表3-1 TensorFlow维护的集合列表
| 集合名称 | 集合内容 | 使用场景 |
|---|---|---|
| tf.GraphKeys.VARIABLES | 所有变量 | 持久化TensorFlow模型 |
| tf.GraphKeys.TRAINABLE_VARIABLES | 可学习的变量 | 模型训练、生成模型可视化内容 |
| tf.GraphKeys.SUMMARIES | 日志生成相关张量 | TensorFlow计算可视化 |
| tf.GraphKeys.QUEUE_RUNNERS | 处理输入的QueueRunner | 输入处理 |
| tf.GRaphKeys.MOVING_AVEGAGE_VARIABLES | 所有计算了滑动平均值的变量 | 计算变量的滑动平均值 |
二、反向传播算法
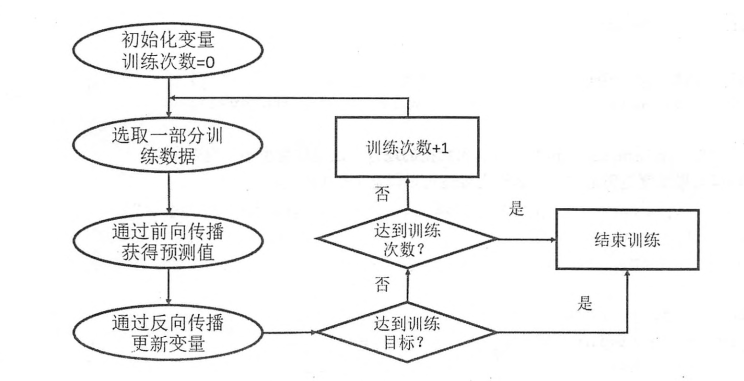
1、上面我们使用x = tf.contant([[0.7,0.9]])表达训练数据,若都使用常量,计算图将非常大(一个常量,计算图增加一个节点),利用率低,故tensorflow提供placeholder机制提供输入数据
placeholder机制:
定义一个位置,这个位置中的数据在程序运行时再指定
定义时,数据类型需要指定(指定后不可改变)
例如使用placeholder实现前向传播算法:
import tensorflow as tf w1 = tf.Variable(tf.random_normal([2,3], stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1], stddev=1,seed=1)) #定义placeholder存放输入数据,指定维度降低出错几率(可以不指定)
x = tf.placeholder(tf.float32, shape=(1, 2), name="x") #通过前向传播算法获得输出
a = tf.matmul(x,w1)
y = tf.matmul(a,w2) with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)#初始化所有变量
#feed_dict是一个字典,,在字典给出placeholder的取值
print(sess.run(y,feed_dict={x:[[0.7,0.9]]}))
2、得到前向传播的结果后,需要定义一个损失函数表示预测值与真实值的差距,然后通过反向传播算法缩小差距
#使用交叉熵损失函数表示预测值和真实值的差距
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
#定义学习率
learning_rate = 0.001
#定义反向传播算法优化神经网络的参数
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
with tf.Session() as sess:
sess.run(train_step)#优化GraphKeys.TRAINABLE_VARIABLES集合中的变量
TensorFlow支持7种优化算法,常用的三种优化算法:tf.train.AdamOptimizer,tf.train.GradientDescentOptimizer,tf.train.MomentumOptimizer
完整的样例程序:
训练神经网络步骤:
1. 定义神经网络结构和前向传播输出结果
2. 定义损失函数及反向传播优化算法
3. 生成会话(tf.Session)并在训练数据上反复运行反向传播优化算法
import tensorflow as tf
from numpy.random import RandomState
# 定义神经网络的参数,输入和输出节点
batch_size = 8
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
x = tf.placeholder(tf.float32, shape=(None, 2), name="x-input")
y_= tf.placeholder(tf.float32, shape=(None, 1), name='y-input')
#定义前向传播过程,损失函数及反向传播算法
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
#生成模拟数据集
rdm = RandomState(1)
X = rdm.rand(128,2)
Y = [[int(x1+x2 < 1)] for (x1, x2) in X]
#创建一个会话来运行TensorFlow程序
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op) # 输出目前(未经训练)的参数取值。
print("w1:", sess.run(w1))
print("w2:", sess.run(w2))
print("\n") # 训练模型。
STEPS = 5000
for i in range(STEPS):
start = (i*batch_size) % 128
end = (i*batch_size) % 128 + batch_size
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 1000 == 0:
total_cross_entropy = sess.run(cross_entropy, feed_dict={x: X, y_: Y})
print("After %d training step(s), cross entropy on all data is %g" % (i, total_cross_entropy)) # 输出训练后的参数取值。
print("\n")
print("w1:", sess.run(w1))
print("w2:", sess.run(w2))
tensorflow:实战Google深度学习框架第三章的更多相关文章
- Tensorflow 实战Google深度学习框架 第五章 5.2.1Minister数字识别 源代码
import os import tab import tensorflow as tf print "tensorflow 5.2 " from tensorflow.examp ...
- [Tensorflow实战Google深度学习框架]笔记4
本系列为Tensorflow实战Google深度学习框架知识笔记,仅为博主看书过程中觉得较为重要的知识点,简单摘要下来,内容较为零散,请见谅. 2017-11-06 [第五章] MNIST数字识别问题 ...
- 1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
学习过程是Tensorflow 实战google深度学习框架一书的第六章的迁移学习环节. 具体见我提出的问题:https://www.tensorflowers.cn/t/5314 参考https:/ ...
- TensorFlow+实战Google深度学习框架学习笔记(5)----神经网络训练步骤
一.TensorFlow实战Google深度学习框架学习 1.步骤: 1.定义神经网络的结构和前向传播的输出结果. 2.定义损失函数以及选择反向传播优化的算法. 3.生成会话(session)并且在训 ...
- 学习《TensorFlow实战Google深度学习框架 (第2版) 》中文PDF和代码
TensorFlow是谷歌2015年开源的主流深度学习框架,目前已得到广泛应用.<TensorFlow:实战Google深度学习框架(第2版)>为TensorFlow入门参考书,帮助快速. ...
- TensorFlow实战Google深度学习框架1-4章学习笔记
目录 第1章 深度学习简介 第2章 TensorFlow环境搭建 第3章 TensorFlow入门 第4章 深层神经网络 第1章 深度学习简介 对于许多机器学习问题来说,特征提取不是一件简单的事情 ...
- TensorFlow实战Google深度学习框架-人工智能教程-自学人工智能的第二天-深度学习
自学人工智能的第一天 "TensorFlow 是谷歌 2015 年开源的主流深度学习框架,目前已得到广泛应用.本书为 TensorFlow 入门参考书,旨在帮助读者以快速.有效的方式上手 T ...
- TensorFlow实战Google深度学习框架10-12章学习笔记
目录 第10章 TensorFlow高层封装 第11章 TensorBoard可视化 第12章 TensorFlow计算加速 第10章 TensorFlow高层封装 目前比较流行的TensorFlow ...
- tensorflow:实战Google深度学习框架第四章01损失函数
深度学习:两个重要特性:多层和非线性 线性模型:任意线性模型的组合都是线性模型,只通过线性变换任意层的全连接神经网络与单层神经网络没有区别. 激活函数:能够实现去线性化(神经元的输出通过一个非线性函数 ...
随机推荐
- linux apache服务器
apache服务器 服务端功能是侦听和响应客户端的http请求.http协议的默认端口是80. 1996年以来,apache成为最流行的web服务器. IIS web服务器只能安装在windows上. ...
- 最优配对问题(集合上的动态规划) —— 状压DP
题目来源:紫书P284 题意: 给出n个点的空间坐标(n为偶数, n<=20), 把他们配成n/2对, 问:怎样配对才能使点对的距离和最小? 题解: 设dp[s]为:状态为s(s代表着某个子集) ...
- 网络测试常用的命令-比较ping,tracert和pathping等命令之间的关系
无论你是一个网络维护人员,还是正在学习TCP/IP协议,了解和掌握一些常用的网络测试命令将会有助于您更快地检测到网络故障所在,同时也会有助你您了解网络通信的内幕. 下面我们逐步介绍几个常用的命令: 1 ...
- iOS端使用二维码扫描(ZBarSDK)和生成(libqrencode)功能
如今二维码随处可见,无论是实物商品还是各种礼券都少不了二维码的身影.手机中二维码使用也很广泛,如微信等.正好最近收集总结了下二维码的使用方法 下面介绍一下如何在iOS设备上使用二维码 首先在githu ...
- 我在面试.NET/C#程序员时会提出的问题
我在面试.NET/C#程序员时会提出的问题 2011-03-03 15:38 by 老赵, 28107 visits 说起来我也面试过相当数量的.NET(包括C#,后文不重复)程序员了,有的通过电话, ...
- log4j 配置文件详解
[1]从零开始 a). 新建Java Project>>新建package>>新建java类: b). import jar包(一个就够),这里我用的是log4j-1.2.14 ...
- bzoj 2836 魔法树——树链剖分
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=2836 树剖裸题.然而WA.RE了好久…… 原来是跳 top 的那个地方! top 不相等的时 ...
- DAG上的DP
引例:NYOJ16 矩形嵌套 时间限制:3000 ms | 内存限制:65535 KB 难度:4 描述 有n个矩形,每个矩形可以用a,b来描述,表示长和宽.矩形X(a,b)可 ...
- 解压缩zip,tar,tar.gz,tar.bz2文件
.tar解包:tar xvf FileName.tar打包:tar cvf FileName.tar DirName(注:tar是打包,不是压缩!)———————————————.gz解压1:gunz ...
- sizeToFit的学习与认知
今天一扫前两日的坏心情,终于有心情平静下来,今天我是根据网络上的一些资料进行学习,今天学习的内容是 sizeToFit() 方法在不方便手动布局的场景中的使用. 首先感谢资料的提供者:参考1 参考2 ...