GuozhongCrawler系列教程 (1) 三大PageDownloader
GuozhongCrawler QQ群 202568714
教程源代码下载地址:http://pan.baidu.com/s/1pJBmerL
GuozhongCrawler内置三大PageDownloader。各自是採用HttpClient作为内核下载的DefaultPageDownloader、採用HtmlUnitDriver作为内核下载WebDriverDownloader、採用ChromeDriver调用浏览器作为内核下载的ChromeDriverDownloader。
当中DefaultPageDownloader和WebDriverDownloader在实际开发中用的最好性能也是最好的。而ChromeDriverDownloader尽管性能不佳。可是ChromeDriverDownloader可以灵活调用浏览器抓取。
在调试过程中使用ChromeDriverDownloader可以看到爬虫真实的执行流程确实为开发增添了不少乐趣。
首先我们来看下怎样使用大三下载器。
以及它们各种什么特点。
一、DefaultPageDownloader
DefaultPageDownloader既然是採用HttpClient作为内核下载器。
那么他必须兼容全部httpClient应该有的功能。
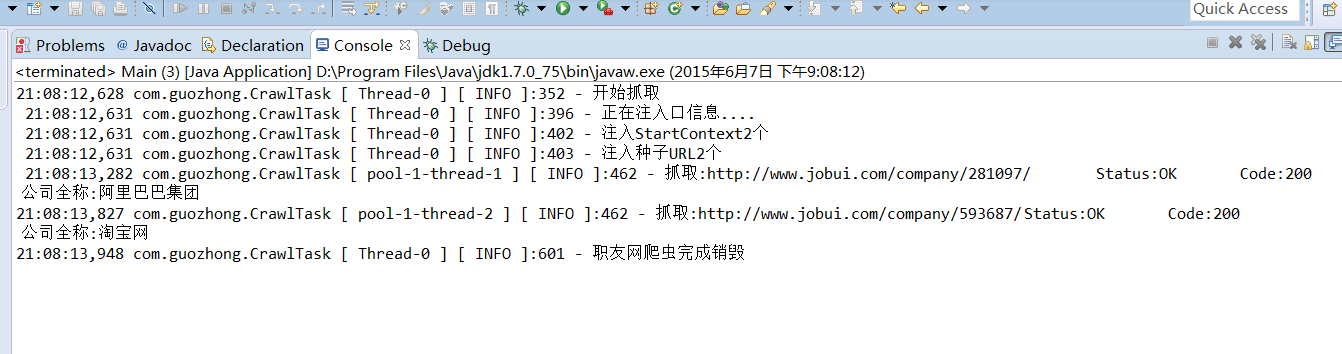
样例我们以职友企业网抓取为样例。我们准备了阿里巴巴和淘宝网两个公司的主页URL。并通过CrawTaskBuilder注入到CrawlTask中。
prepareCrawlTask时指定使用DefaultPageDownloader作为下载器。
String alibaba = "http://www.jobui.com/company/281097/";
String taobao = "http://www.jobui.com/company/593687/";
CrawTaskBuilder builder = CrawlManager.getInstance()
.prepareCrawlTask("职友网爬虫", DefaultPageDownloader.class)
.useThread(2)//使用两个线程下载
.injectStartUrl(alibaba, PageCompanyDescript.class)
.injectStartUrl(taobao, PageCompanyDescript.class)
.usePageEncoding(PageEncoding.UTF8);
CrawlTask spider = builder.build();
CrawlManager.getInstance().start(spider);
PageCompanyDescript.java的实现我们如今临时仅仅输出解析出来的公司名称代码例如以下
public class PageCompanyDescript implements PageProcessor {
@Override
public PageScript getJavaScript() {
return null;
}
@Override
public Pattern getNormalContain() {
return null;
}
@Override
public void process(OkPage page, StartContext context,
List<BasicRequest> queue, List<Proccessable> objectContainer)
throws Exception {
Document doc = Jsoup.parse(page.getContent());
Element h1 = doc.select("h1[id=companyH1]").first();
if(h1 != null){
System.out.println("公司全称:"+h1.text());
}
}
@Override
public void processErrorPage(Page arg0, StartContext arg1)
throws Exception {
}
}
OK。如今測试代码就已经完毕。我们执行。
二、WebDriverDownloader
使用WebDriverDownloader事实上仅仅要把main方法中的prepareCrawlTask("职友网爬虫", DefaultPageDownloader.class)
改成prepareCrawlTask("职友网爬虫", WebDriverDownloader.class)就可以完毕WebDriverDownloader的设置。
为了体现差别我们在PageCompanyDescript中实现getJavaScript方法来运行一段js代码。getJavaScript实现例如以下:
@Override
public PageScript getJavaScript() {
return new PageScript() {
@Override
public void executeJS(HtmlUnitDriver driver) throws Exception {
WebElement element = driver.findElementById("companyH1");
driver.executeScript("arguments[0].innerHTML='WebDriverDownloader支持运行JavaScript';", element);
}
};
}
OK执行之后的结果例如以下图。

10:10:23,572到 10:10:32,056中间相差了9s的时间。这是由于webdriver的js引擎在jvm中运行确实过慢。但大规模抓取过程中还是建议採用抓包抓取的方式。
三、ChromeDriverDownloader
ChromeDriverDownloader和WebDriverDownloader功能上一样。
仅仅是下载会调用谷歌浏览器。用户须要安装谷歌浏览器和下载chromedriver。放在谷歌浏览器的安装文件夹。
我的文件夹是D:\program files (x86)\Chrome。
那么chromedriver的路径是D:\program files (x86)\Chrome\chromedriver.exe。
这里解释下ChromeDriver是Chromium team开发维护的。它是实现WebDriver有线协议的一个单独的服务。ChromeDriver通过chrome的自己主动代理框架控制浏览 器。ChromeDriver仅仅与12.0.712.0以上版本号的chrome浏览器兼容。
chromedriver下载地址:https://code.google.com/p/chromedriver/wiki/WheredAllTheDownloadsGo?
tm=2
之后我们改动main方法中的代码:
//设置chromedriver.exe路径
System.setProperty("webdriver.chrome.driver", "D:\\program files (x86)\\Chrome\\chromedriver.exe");
String alibaba = "http://www.jobui.com/company/281097/";
String taobao = "http://www.jobui.com/company/593687/";
CrawTaskBuilder builder = CrawlManager.getInstance()
.prepareCrawlTask("职友网爬虫", ChromeDriverDownloader.class)
.useThread(2)//使用两个线程下载
.injectStartUrl(alibaba, PageCompanyDescript.class)
.injectStartUrl(taobao, PageCompanyDescript.class)
.usePageEncoding(PageEncoding.UTF8);
CrawlTask spider = builder.build();
CrawlManager.getInstance().start(spider);
再次运行会弹出谷歌浏览器界面,我们能够看到爬虫抓取过程了。
控制台输出

可能你会注意到。
我们用了useThread(2)//使用两个线程下载。为什么没有出现两个谷歌浏览器同一时候抓。这里解释是由于我们注入种子URL的方式是使用injectStartUrl它会注入2个StartContext。而StartContext好比是一批种子URL的上下文。同一时间是不能同一时候使用的。
为此GuozhongCrawler提供了DynamicEntrance的概念实现多个种子URL同一时候共享一个StartContext的功能。想了解DynamicEntrance的话,请继续关注后期GuozhongCrawler系列教程。谢谢大家!
GuozhongCrawler QQ群 202568714
GuozhongCrawler系列教程 (1) 三大PageDownloader的更多相关文章
- GuozhongCrawler系列教程 (2) CrawTaskBuilder具体解释
GuozhongCrawler是分层架构.要高速学习CrawlTask独立的配置多少要了解框架的源码.所以CrawTaskBuilder提供要更加扁平且易于理解的的方式创建CrawTask 方法具体资 ...
- GuozhongCrawler系列教程 (4) StartContext具体解释
StartContext是注入时全部seed的上下文信息假设爬虫在抓取过程其中须要共享一些变量.那么可使用StartContext作为容器. 构造器具体资料 StartContext public S ...
- GuozhongCrawler系列教程 (5) TransactionRequest具体解释
为了实现和维护并发抓取的属性信息提供线程安全的事务请求.TransactionRequest是一个抽象类自己不能设置Processor,却须要实现 TransactionCallBack接口.Tran ...
- Java成神路上之设计模式系列教程之一
Java成神路上之设计模式系列教程之一 千锋-Feri 在Java工程师的日常中,是否遇到过如下问题: Java 中什么叫单例设计模式?请用Java 写出线程安全的单例模式? 什么是设计模式?你是否在 ...
- 从零开始学 Web 系列教程
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新…… github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:http:/ ...
- JS面向对象系列教程 — 对象的基本操作
面向对象概述  面向对象(Object Oriented)简称OO,它是一种编程思维,用于指导我们如何应对各种复杂的开发场景. 这里说的对象(Object),意思就是事物,在面向对象的思维中,它将一 ...
- SpringBoot系列教程web篇之过滤器Filter使用指南
web三大组件之一Filter,可以说是很多小伙伴学习java web时最早接触的知识点了,然而学得早不代表就用得多.基本上,如果不是让你从0到1写一个web应用(或者说即便从0到1写一个web应用) ...
- Angular2入门系列教程7-HTTP(一)-使用Angular2自带的http进行网络请求
上一篇:Angular2入门系列教程6-路由(二)-使用多层级路由并在在路由中传递复杂参数 感觉这篇不是很好写,因为涉及到网络请求,如果采用真实的网络请求,这个例子大家拿到手估计还要自己写一个web ...
- Angular2入门系列教程6-路由(二)-使用多层级路由并在在路由中传递复杂参数
上一篇:Angular2入门系列教程5-路由(一)-使用简单的路由并在在路由中传递参数 之前介绍了简单的路由以及传参,这篇文章我们将要学习复杂一些的路由以及传递其他附加参数.一个好的路由系统可以使我们 ...
随机推荐
- java内部类的四大作用
一.定义 放在一个类的内部的类我们就叫内部类. 二. 作用 1.内部类可以很好的实现隐藏 一般的非内部类,是不允许有 private 与protected权限的,但内部类可以 2.内部类拥有外围类的所 ...
- 使用gcc的-finstrument-functions选项进行函数跟踪【转】
转自:http://blog.csdn.net/jasonchen_gbd/article/details/44044899 版权声明:本文为博主原创文章,转载请附上原博链接. GCC Functio ...
- 标准C程序设计七---61
Linux应用 编程深入 语言编程 标准C程序设计七---经典C11程序设计 以下内容为阅读: <标准C程序设计>(第7版) 作者 ...
- Python日志(logging)模块使用方法简介
A logger is configured to have a log level. This log level describes the severity of the messages th ...
- EXT.JS6中的model,store,proxy的一些用法
//one-to-one Ext.define('Address', { extend: 'Ext.data.Model', fields: [ 'address', 'city', 'state', ...
- 初识mysql语句
操作文件夹(库) 增 create database db1 charset utf8; 查 # 查看当前创建的数据库 show create database db1; # 查看所有的数据库 sho ...
- 从壹开始 [ Ids4实战 ] 之三║ 详解授权持久化 & 用户数据迁移
回顾 哈喽大家周三好,今天终于又重新开启 IdentityServer4 的落地教程了,不多说,既然开始了,就要努力做好
- 平衡树与可持久化treap
平衡树(二叉树) 线段树不支持插入or删除一个数于是平衡树产生了 常见平衡树:treap(比sbt慢,好写吧),SBT(快,比较好写,有些功能不支持),splay(特别慢,复杂度当做根号n来用,功能强 ...
- JSP页面顶端出现错误:The superclass "javax.servlet.http.HttpServlet" was not found on the Java Build Path的问题解决
原理:把RunTime容器添加进去,比如tomcat的. 1.项目右键->[Build Path]->[Configure Build Path...] 2.把tomcat的runtime ...
- mac os+selenium2+Firefox驱动+python3
此文章建立在之前写的chrome+selenium+Python环境配置的基础上,链接http://blog.csdn.net/zxy987872674/article/details/5308289 ...