20个最有用的Python数据科学库
核心库与统计
1. NumPy(提交:17911,贡献者:641)
一般我们会将科学领域的库作为清单打头,NumPy 是该领域的主要软件库之一。它旨在处理大型的多维数组和矩阵,并提供了很多高级的数学函数和方法,因此可以用它来执行各种操作。
在过去一年,开发团队对该库进行了大量改进。除了错误修复和解决兼容性问题之外,关键的变更还包括样式改进,即 NumPy 对象的打印格式。此外,一些函数现在可以处理任意编码的文件,只要这些编码受 Python 支持。
2. SciPy(提交:19150,贡献者:608)
另一个科学计算核心库 SciPy,基于 NumPy 而构建,并扩展了 NumPy 的功能。SciPy 的主要数据结构是多维数组,使用 Numpy 实现。该库提供了一些用于解决线性代数、概率论、积分计算等任务的工具。
SciPy 通过与不同的操作系统进行持续集成的方式带来了重大改进,比如新的函数和方法,更重要的是——最新的优化器。此外,开发团队对很多新的 BLAS 和 LAPACK 函数进行了包装。
3.Pandas(提交:17144,贡献者:1165)
Pandas 是一个 Python 库,提供了高级的数据结构和各种分析工具。该库的一大特色是能够将相当复杂的数据操作转换为一两个命令。Pandas 提供了很多内置的方法,用于分组、过滤和组合数据,还提供了时间序列功能。所有这些方法的执行速度都很快。
新发布的 pandas 库还提供了数百个新特性、功能增强、错误修复和 API 变更。这些改进与 Pandas 对数据进行分组和排序的能力有关,支持自定义类型操作。
4. StatsModels(提交:10067,贡献者:153)
Statsmodels 是一个 Python 模块,为统计数据分析提供了很多可能性,例如统计模型估计、运行统计测试等。你可以借助它来实现很多机器学习方法,并探索不同的绘图可能性。
该库在不断演化,带来了更多的可能性。今年带来了时间序列改进和新的计数模型 GeneralizedPoisson、零膨胀模型和 NegativeBinomialP,以及新的多变量方法因子分析、MANOVA 和 ANOVA 的重复测量。
可视化
5. Matplotlib(提交:25747,贡献者:725)
Matplotlib 是一个用于创建二维图表和图形的低级库。你可以用它来构建各种图表,从直方图和散点图到非笛卡尔坐标图。此外,很多流行的绘图库都为 Matplotlib 预留了位置,可与 Matplotlib 结合在一起使用。
该库在绘图样式方面做出了很多变更,如颜色、尺寸、字体、图例等。例如,坐标轴图例的自动对齐和对色盲患者更友好的色环。
6. Seaborn(提交:2044,贡献者:83)
Seaborn 实际上是基于 matplotlib 库构建的高级 API。它为处理图表提供了更恰当的默认选项。此外,它还提供了一组丰富的可视化图库,包括时间序列、联合图和小提琴图等复杂的类型。
Seaborn 的更新主要是问题修复。不过,FacetGrid(或 PairGrid)与增强的交互式 matplotlib 后端之间的兼容性有所改进,为可视化添加了参数和选项。
7. Plotly(提交:2906,贡献者:48)
Plotly 是一个可以帮助你轻松构建复杂图形的流行库。该库适用于交互式 Web 应用程序,它提供了很多很棒的可视化效果,包括轮廓图形、三元图和 3D 图表。
这个库在持续地增强和改进,带来新的图形和特性,支持“多链接视图”、动画和串扰集成。
8. Bokeh(提交:16983,贡献者:294)
Bokeh 库使用 Java 小部件在浏览器中创建交互式和可伸缩的可视化图形。该库提供了多种图形、样式、链接图形式的交互能力、添加小部件、定义回调以及更多有用的功能。Bokeh 改进的交互式功能值得称赞,例如可旋转的分类刻度标签,以及小型的缩放工具和自定义工具提示字段增强。
9. Pydot(提交:169,贡献者:12)
Pydot 是一个用于生成面向复杂图形和非面向复杂图形的库。它作为面向 Graphviz 的一个接口,使用 Python 编写。我们可以借助它来显示图形的结构,这在构建神经网络和基于决策树的算法时经常会用到。

机器学习
10. Scikit-learn(提交:22753,贡献者:1084)
这个基于 NumPy 和 SciPy 的 Python 模块是处理数据的最佳库之一。它为很多标准的机器学习和数据挖掘任务提供算法,例如聚类、回归、分类、降维和模型选择。
该库有很多增强功能。交叉验证已经获得更新,现在可以使用多个指标。一些训练方法(如邻近取样和逻辑回归等)得到一些小改进。它的主要更新之一是完成了通用术语和 API 元素词汇表。
11. XGBoost/LightGBM/CatBoost(提交:3277/1083/1509,贡献者:280/79/61)
梯度提升是最流行的机器学习算法之一,它的核心原理在于构建连续精炼的基本模型的集合,即决策树。因此,有些专门的库被设计用于方便快速地实现该方法。我们认为 XGBoost、LightGBM 和 CatBoost 是值得关注的。它们都是解决常见问题最强有力的工具,而且使用方式几乎一样。我们可以使用这些库快速实现高度优化且可扩展的梯度提升,所以它们在数据科学家和 Kaggle 竞争者中非常受欢迎,他们在这些算法的帮助下赢得了很多比赛。
12. Eli5(提交:922,贡献者:6)
通常情况下,机器学习模型的预测结果并不完全是清晰的,这个时候可以借助 Eli5 来解决这个问题。它是一个用于可视化和调试机器学习模型的库,可以逐步跟踪算法的执行过程。它支持 scikit-learn、XGBoost、LightGBM、lightning 和 sklearn-crfsuite 库,并可以为每个库执行不同的任务。
深度学习
13. TensorFlow(提交:33339,贡献者:1469)
TensorFlow 是一个流行的深度学习和机器学习框架,由 Google Brain 开发。它支持在人工神经网络中使用多个数据集。最受欢迎的 TensorFlow 应用场景包括物体识别、语音识别等。还有很多基于 TensorFlow 构建的库,例如 tflearn、tf-slim、skflow 等。
这个库发布新版本的速度很快,引入了很多新功能。最新的修复包括潜在的安全漏洞和改进的 TensorFlow 与 GPU 的集成,现在可以在单台计算机的多个 GPU 上运行 Estimator 模型。
14. PyTorch(提交:11306,贡献者:635)
PyTorch 是一个大型框架,可用它基于 GPU 加速执行张量计算、创建动态计算图以及自动计算梯度。此外,PyTorch 还提供了丰富的 API,用于解决与神经网络相关的应用。
该库基于 Torch 而构建,使用 C 语言实现,并包含了使用 Lua 编写的包装器。它的 Python API 于 2017 年推出,从那时起,该框架越来越受欢迎,并吸引了越来越多的数据科学家。
15. Keras(提交:4539,贡献者:671)
Keras 是一个用于处理神经网络的高级库,运行在 TensorFlow 或 Theano 之上,现在发布的新版本可以使用 CNTK 或 MxNet 作为后端。它简化了很多特定任务,并大大减少了样板代码的数量,但它可能不适用于某些复杂的事情。
该库在性能、可用性、文档和 API 方面进行了改进,并推出了一些新特性,如 Conv3DTranspose 层、新的 MobileNet 应用程序和自我规范化网络。
分布式深度学习
16. dist-keras/elephas/spark-deep-learning(提交:1125/170/67,贡献者:5/13/11)
深度学习问题变得越来越重要,因为越来越多的场景要求更多的时间和成本。而像 Apache Spark 这样的分布式计算系统可以更轻松地处理大量数据,这反过来又为深度学习带来更多的可能性。dist-keras、elephas 和 spark-deep-learning 变得越来越流行,并正在迅速发展演化。很难说它们当中哪个更好,因为它们都是为解决一些相同的任务而设计的。这些库和 Keras 可以直接用在 Apache Spark 中,用以训练神经网络。spark-deep-learning 还提供了工具用于为 Python 神经网络创建管道。
自然语言处理
17. NLTK(提交:13041,贡献者:236)
NLTK 是一组库的集合,一个完整的自然语言处理平台。你可以借助 NLTK 以各种方式处理和分析文本,如标记、打标签、提取信息等。NLTK 还用于原型设计和构建研究性系统。
该库的增强还包括 API 和兼容性的微小变更以及面向 CoreNLP 的新接口。
18. SpaCy(提交:8623,贡献者:215)
SpaCy 是一个自然语言处理库,包含了优秀的示例、API 文档和演示应用程序。该库使用 Cython(Python 的 C 扩展)编写。它支持将近 30 种语言,可以方便地与深度学习集成,并保证健壮性和高准确率。SpaCy 有一个为处理整个文档而设计的架构,在处理文档时不需要将它分成短语,这也是 SpaCy 的一个重要特性。
19. Gensim(提交:3603,贡献者:273)
Gensim 基于 Numpy 和 Scipy 而构建,是一个用于语义分析、主题建模和向量空间建模的 Python 库。它提供了主流的 NLP 算法实现,例如 word2vec。Gensim 有自己的 models.wrappers.fasttext 实现,不过仍然可以使用 fasttext 库进行单词表示的高效学习。
数据抓取
20. Scrapy(提交:6625,贡献者:281)
Scrapy 是一个用于创建扫描网站页面并收集结构化数据的爬虫的库。此外,Scrapy 可以从 API 中提取数据。因为具备良好的可扩展性和可移植性,该库使用起来非常方便。
该库在过去一年里的变化包括代理服务器的若干次升级以及改进的错误通知和问题识别系统。用在元数据设置中的 Scrapy 解析也有了新的特性。
结论
这些是我们列出的 2018 年数据科学 Python 库的集合。与去年相比,一些新的库越来越受欢迎,而那些经典库也正在不断改进。
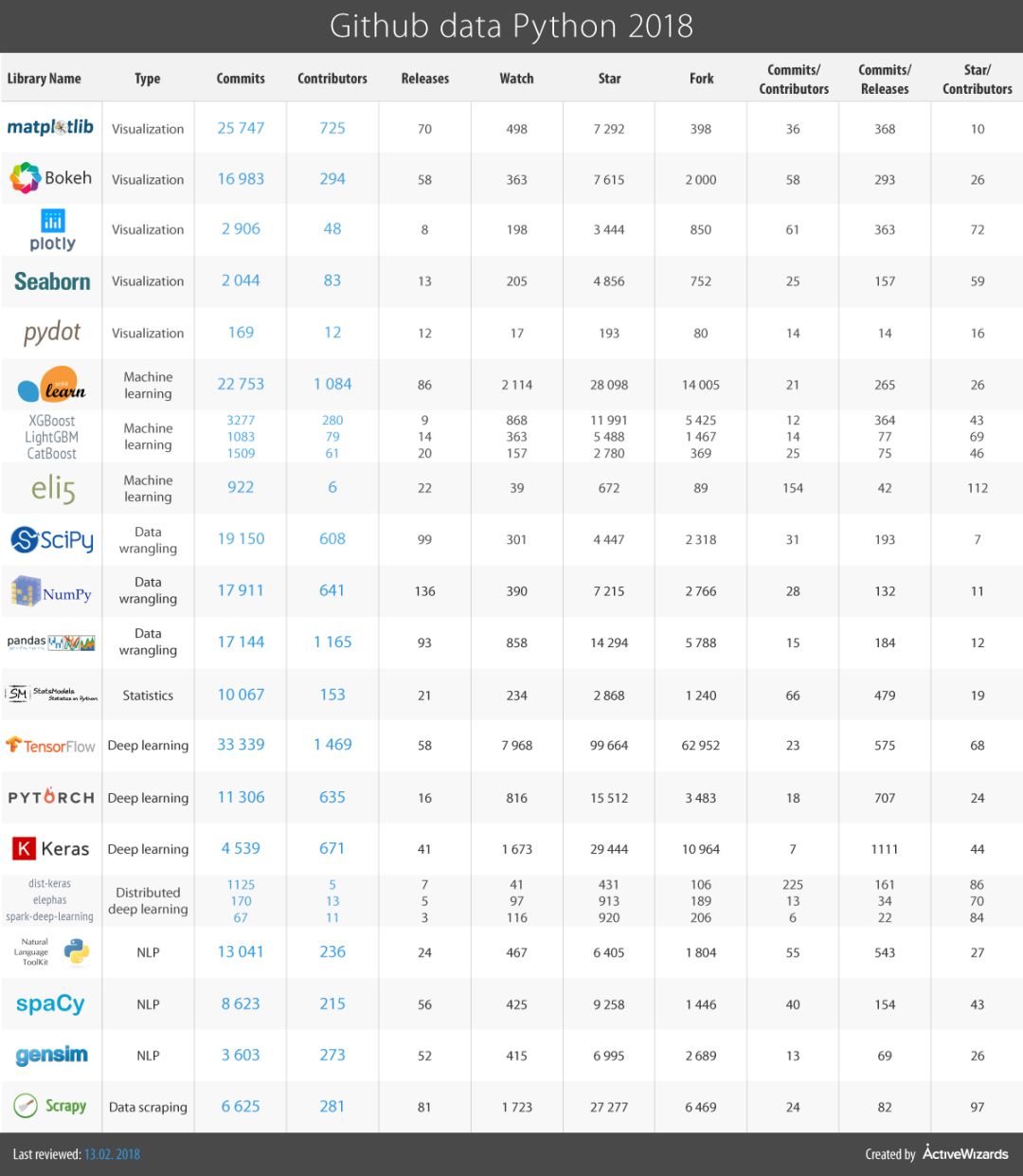
下面的表格显示了这些库在 Github 上的活动统计信息。
各个库的链接地址:
NumPy:http://www.numpy.org/
SciPy:https://scipy.org/scipylib/
Pandas:https://pandas.pydata.org/
StatsModels:http://www.statsmodels.org/devel/
Matplotlib:https://matplotlib.org/index.html
Seaborn:https://seaborn.pydata.org/
Plotly:https://plot.ly/python/
Bokeh:https://bokeh.pydata.org/en/latest/
Pydot:https://pypi.org/project/pydot/
Scikit-learn:http://scikit-learn.org/stable/
XGBoost:http://xgboost.readthedocs.io/en/latest/
LightGBM:http://lightgbm.readthedocs.io/en/latest/Python-Intro.html
CatBoost:https://github.com/catboost/catboost
Eli5:https://eli5.readthedocs.io/en/latest/
TensorFlow:https://www.tensorflow.org/
PyTorch:https://pytorch.org/
Keras:https://keras.io/
dist-keras:http://joerihermans.com/work/distributed-keras/
elephas:https://pypi.org/project/elephas/
spark-deep-learning:https://databricks.github.io/spark-deep-learning/site/index.html
NLTK:https://www.nltk.org/
SpaCy:https://spacy.io/
Gensim:https://radimrehurek.com/gensim/
Scrapy:https://scrapy.org/
20个最有用的Python数据科学库的更多相关文章
- 9 个鲜为人知的 Python 数据科学库
除了 pandas.scikit-learn 和 matplotlib,还要学习一些用 Python 进行数据科学的新技巧. Python 是一种令人惊叹的语言.事实上,它是世界上增长最快的编程语言之 ...
- [python]-数据科学库Numpy学习
一.Numpy简介: Python中用列表(list)保存一组值,可以用来当作数组使用,不过由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针.这样为了保存一个简单的[1,2,3],需要有3 ...
- python中令人惊艳的小众数据科学库
Python是门很神奇的语言,历经时间和实践检验,受到开发者和数据科学家一致好评,目前已经是全世界发展最好的编程语言之一.简单易用,完整而庞大的第三方库生态圈,使得Python成为编程小白和高级工程师 ...
- 干货!小白入门Python数据科学全教程
前言 本文讲解了从零开始学习Python数据科学的全过程,涵盖各种工具和方法 你将会学习到如何使用python做基本的数据分析 你还可以了解机器学习算法的原理和使用 说明 先说一段题外话.我是一名数据 ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
- 《Python数据科学手册》第五章机器学习的笔记
目录 <Python数据科学手册>第五章机器学习的笔记 0. 写在前面 1. 判定系数 2. 朴素贝叶斯 3. 自举重采样方法 4. 白化 5. 机器学习章节总结 <Python数据 ...
- Python数据科学手册
Python数据科学手册(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1KurSdjNWiwMac3o3iLrzBg 提取码:qogy 复制这段内容后打开百度网盘手 ...
- Python数据科学手册Seaborn马拉松可视化里时分秒转化为秒数的问题
Python数据科学手册Seaborn马拉松可视化里时分秒转化为秒数的问题 问题描述: 我实在是太懒了,问题描述抄的网上的哈哈哈:https://www.jianshu.com/p/6ab7afa05 ...
- python书籍推荐:Python数据科学手册
所属网站分类: 资源下载 > python电子书 作者:today 链接:http://www.pythonheidong.com/blog/article/448/ 来源:python黑洞网 ...
随机推荐
- woj1005-holding animals-01pack woj1006-Language of animals-BFS
title: woj1005-holding animals-01pack date: 2020-03-05 categories: acm tags: [acm,woj,pack] 01背包.中等题 ...
- Java之一个整数的二进制中1的个数
这是今年某公司的面试题: 一般思路是:把整数n转换成二进制字符数组,然后一个一个数: private static int helper1(int i) { char[] chs = Integer. ...
- Seven xxx in Seven Weeks ebooks | 七周七 xxx 系列图书 电子书| share 分享 | free of charge 免费!
Seven xxx in Seven Weeks ebooks | 七周七 xxx 系列图书 电子书| share 分享 | free of charge 免费! Seven Languag ...
- Chart.js & CPU 性能监控
Chart.js 可视化动态 CPU 性能监控 https://github.com/gildata/RAIO/issues/337 https://github.com/chartjs/Chart. ...
- web effects collection
web effects collection typewriter effect js 打字机效果 http://www.mattboldt.com/demos/typed-js/ https://g ...
- webpack defineConstants
webpack defineConstants PAGES 全局常量/全局变量 https://webpack.js.org/plugins/define-plugin/ taro https://n ...
- js 在浏览器中使用 monaco editor
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content ...
- SameSite & Cookies
SameSite & Cookies SameSite=None && Secure (HTTPS) https://developer.mozilla.org/en-US/d ...
- 联童科技基于incubator-dolphinscheduler从0到1构建大数据调度平台之路
联童科技是一家智能化母婴童产业平台,从事母婴童行业以及互联网技术多年,拥有丰富的母婴门店运营和系统开发经验,在会员经营和商品经营方面,能够围绕会员需求,深入场景,更贴近合作伙伴和消费者,提供最优服务产 ...
- 基于nginx实现上游服务器动态自动上下线——不需reload
网上关于nginx的介绍有很多,这里讲述的是上游服务(如下图的Java1服务)在没有"网关"的情况下,如何通过nginx做到动态上下线. 传统的做法是,手动修改nginx的upst ...