Prometheus时序数据库-磁盘中的存储结构
Prometheus时序数据库-磁盘中的存储结构
前言
之前的文章里,笔者详细描述了监控数据在Prometheus内存中的结构。而其在磁盘中的存储结构,也是非常有意思的,关于这部分内容,将在本篇文章进行阐述。
磁盘目录结构
首先我们来看Prometheus运行后,所形成的文件目录结构
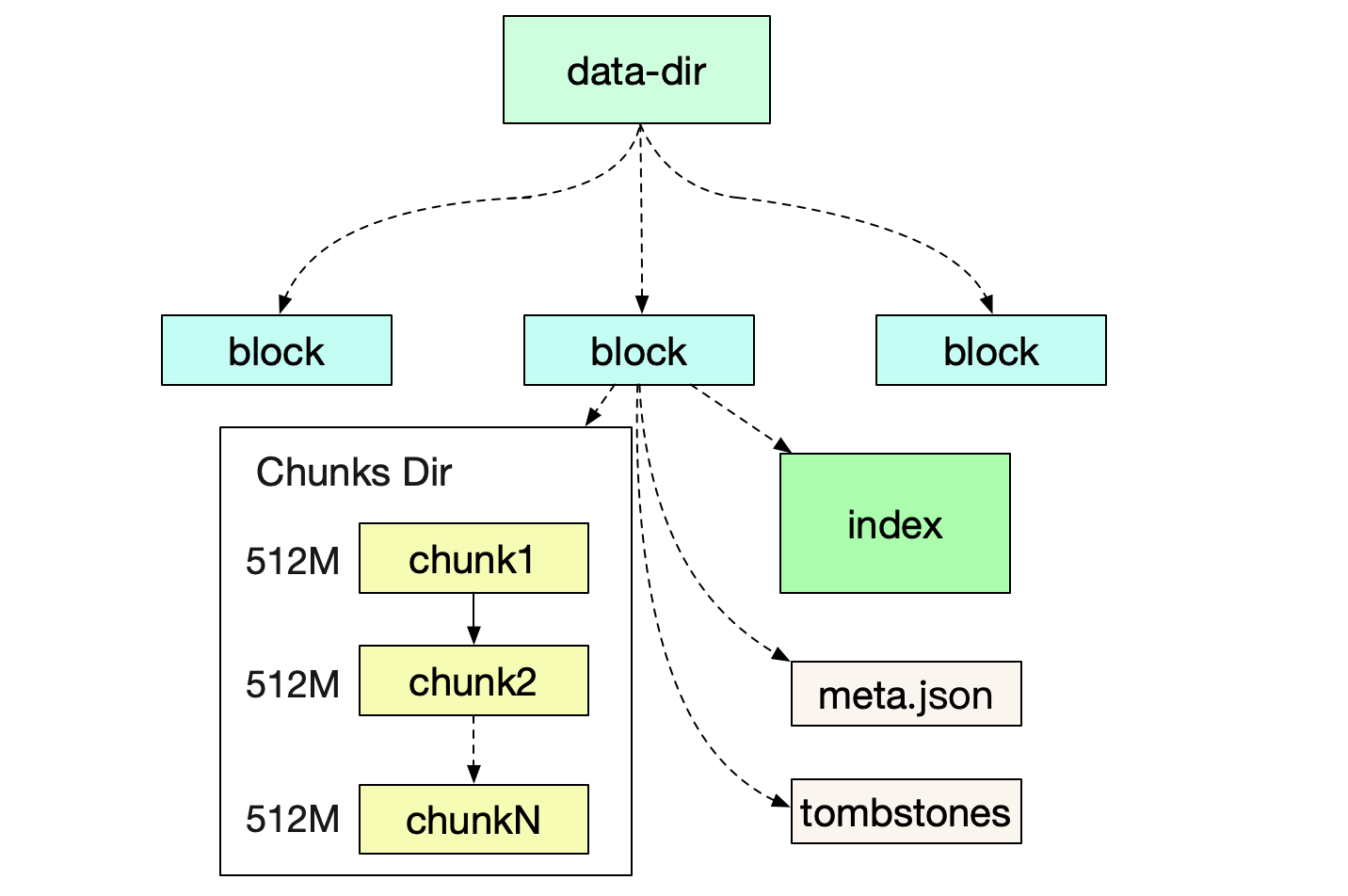
在笔者自己的机器上的具体结构如下:
prometheus-data
|-01EY0EH5JA3ABCB0PXHAPP999D (block)
|-01EY0EH5JA3QCQB0PXHAPP999D (block)
|-chunks
|-000001
|-000002
.....
|-000021
|-index
|-meta.json
|-tombstones
|-wal
|-chunks_head
Block
一个Block就是一个独立的小型数据库,其保存了一段时间内所有查询所用到的信息。包括标签/索引/符号表数据等等。Block的实质就是将一段时间里的内存数据组织成文件形式保存下来。
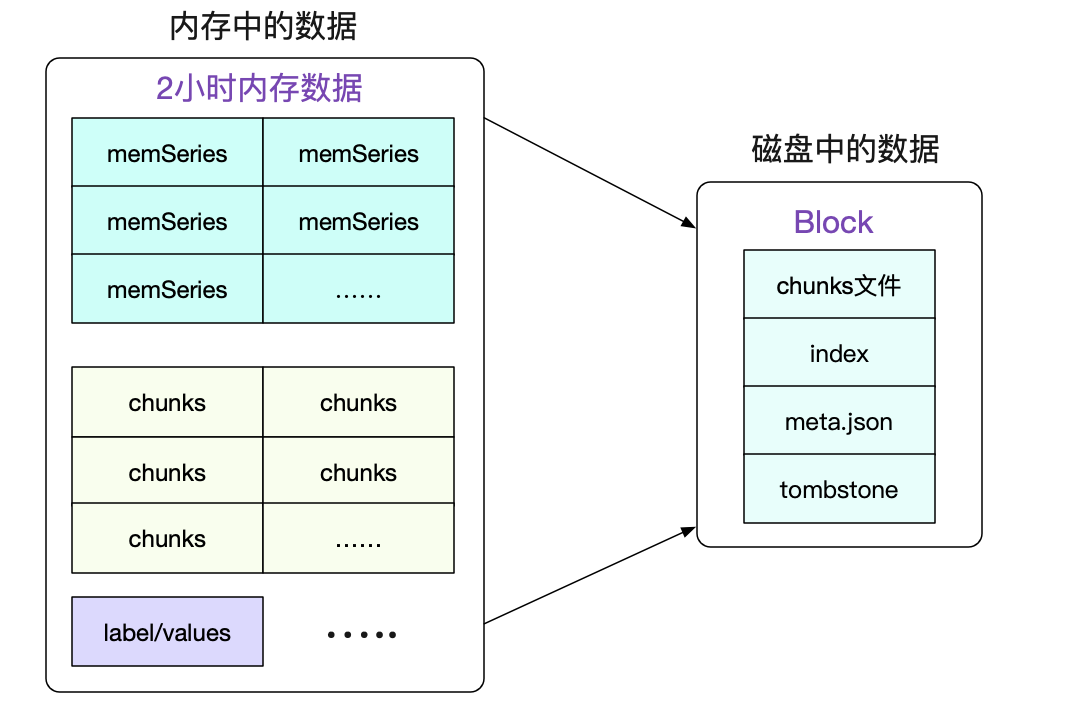
最近的Block一般是存储了2小时的数据,而较为久远的Block则会通过compactor进行合并,一个Block可能存储了若干小时的信息。值得注意的是,合并操作只是减少了索引的大小(尤其是符号表的合并),而本身数据(chunks)的大小并没有任何改变。
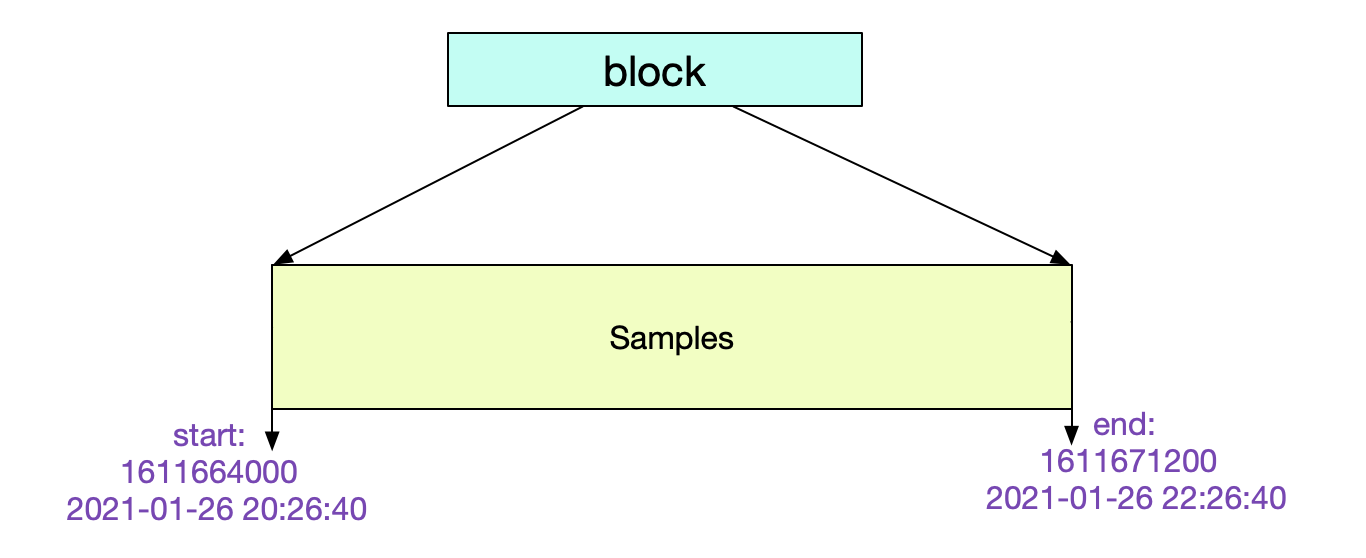
meta.json
我们可以通过检查meta.json来得到当前Block的一些元信息。
{
"ulid":"01EY0EH5JA3QCQB0PXHAPP999D"
// maxTime-minTime = 7200s => 2 h
"minTime": 1611664000000
"maxTime": 1611671200000
"stats": {
"numSamples": 1505855631,
"numSeries": 12063563,
"numChunks": 12063563
}
"compaction":{
"level" : 1
"sources: [
"01EY0EH5JA3QCQB0PXHAPP999D"
]
}
"version":1
}
其中的元信息非常清楚明了。这个Block记录了从2个小时的数据。
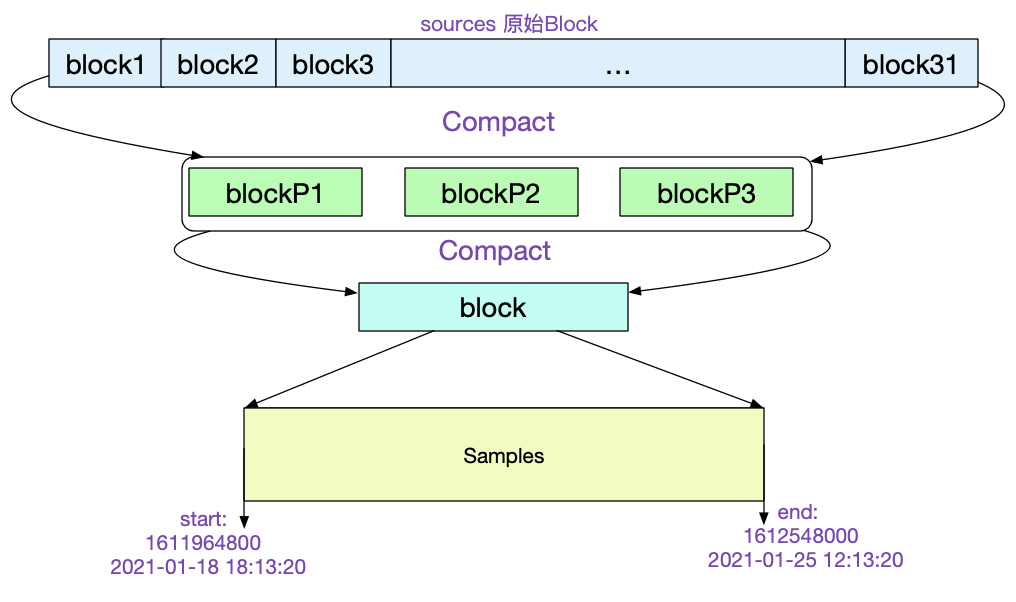
让我们再找一个比较陈旧的Block看下它的meta.json.
"ulid":"01EXTEH5JA3QCQB0PXHAPP999D",
// maxTime - maxTime =>162h
"minTime":1610964800000,
"maxTime":1611548000000
......
"compaction":{
"level": 5,
"sources: [
31个01EX......
]
},
"parents: [
{
"ulid": 01EXTEH5JA3QCQB1PXHAPP999D
...
}
{
"ulid": 01EXTEH6JA3QCQB1PXHAPP999D
...
}
{
"ulid": 01EXTEH5JA31CQB1PXHAPP999D
...
}
]
从中我们可以看到,该Block是由31个原始Block经历5次压缩而来。最后一次压缩的三个Block ulid记录在parents中。如下图所示:
Chunks结构
CUT文件切分
所有的Chunk文件在磁盘上都不会大于512M,对应的源码为:
func (w *Writer) WriteChunks(chks ...Meta) error {
......
for i, chk := range chks {
cutNewBatch := (i != 0) && (batchSize+SegmentHeaderSize > w.segmentSize)
......
if cutNewBatch {
......
}
......
}
}
当写入磁盘单个文件超过512M的时候,就会自动切分一个新的文件。
一个Chunks文件包含了非常多的内存Chunk结构,如下图所示:
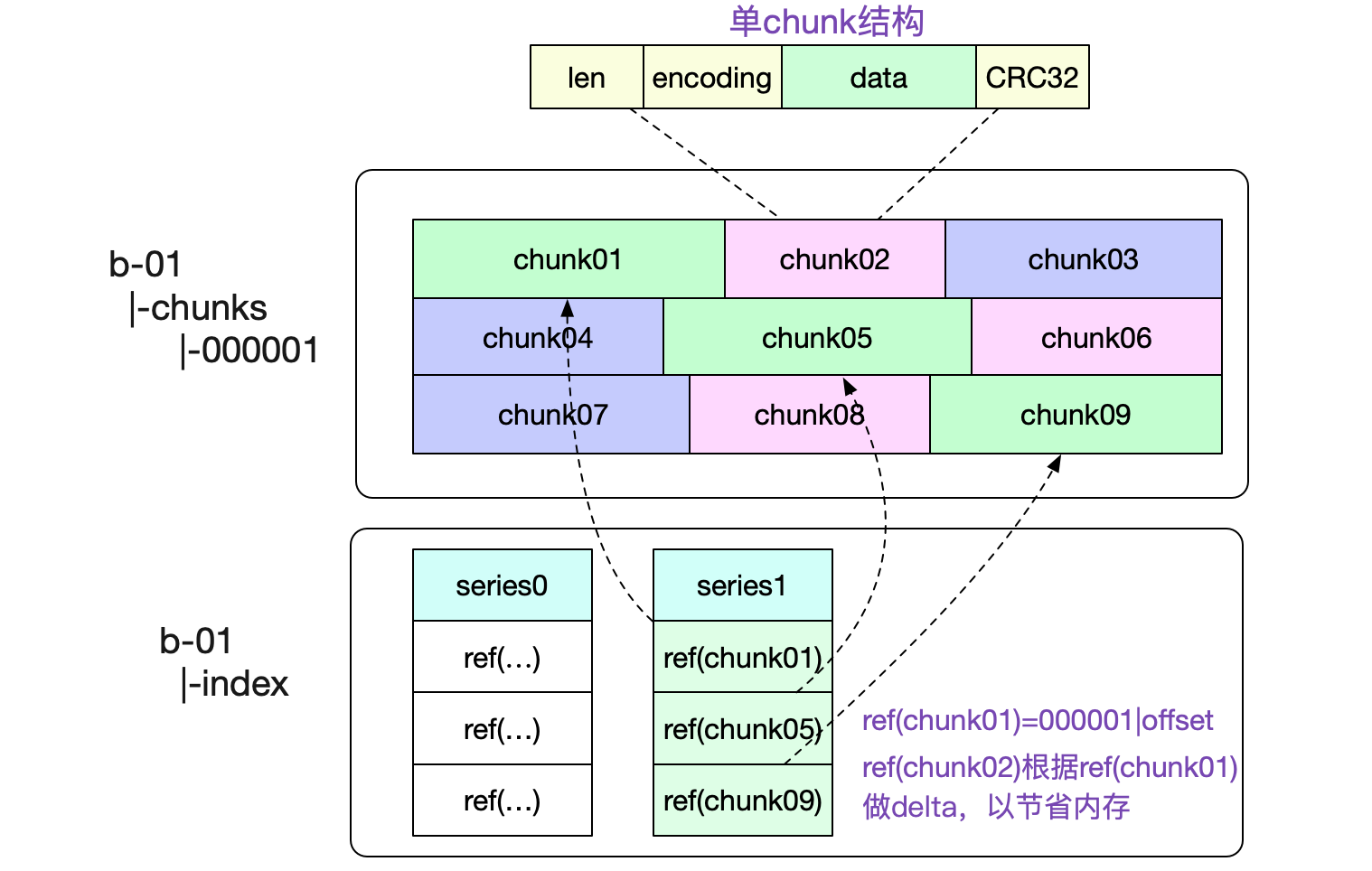
图中也标出了,我们是怎么寻找对应Chunk的。通过将文件名(000001,前32位)以及(offset,后32位)编码到一个int类型的refId中,使得我们可以轻松的通过这个id获取到对应的chunk数据。
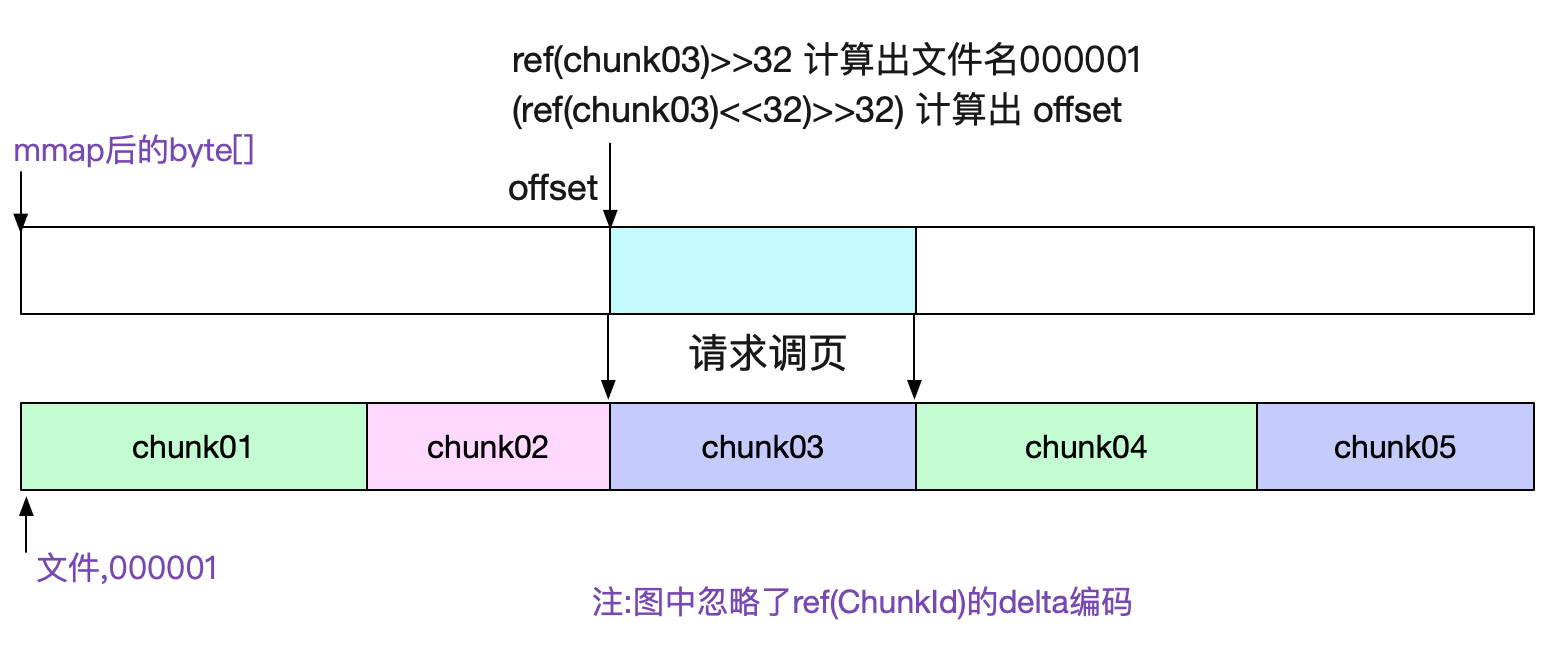
chunks文件通过mmap去访问
由于chunks文件大小基本固定(最大512M),所以我们很容易的可以通过mmap去访问对应的数据。直接将对应文件的读操作交给操作系统,既省心又省力。对应代码为:
func NewDirReader(dir string, pool chunkenc.Pool) (*Reader, error) {
......
for _, fn := range files {
f, err := fileutil.OpenMmapFile(fn)
......
}
......
bs = append(bs, realByteSlice(f.Bytes()))
}
通过sgmBytes := s.bs[offset]就直接能获取对应的数据
index索引结构
前面介绍完chunk文件,我们就可以开始阐述最复杂的索引结构了。
寻址过程
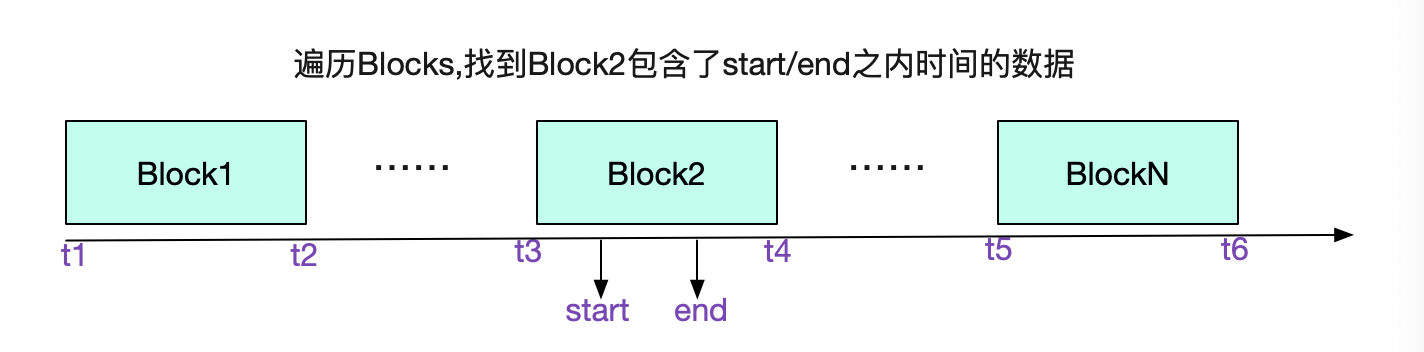
索引就是为了让我们快速的找到想要的内容,为了便于理解。笔者就通过一次数据的寻址来探究Prometheus的磁盘索引结构。考虑查询一个
拥有系列三个标签
({__name__:http_requests}{job:api-server}{instance:0})
且时间为start/end的所有序列数据
我们先从选择Block开始,遍历所有Block的meta.json,找到具体的Block
前文说了,通过Labels找数据是通过倒排索引。我们的倒排索引是保存在index文件里面的。 那么怎么在这个单一文件里找到倒排索引的位置呢?这就引入了TOC(Table Of Content)
TOC(Table Of Content)
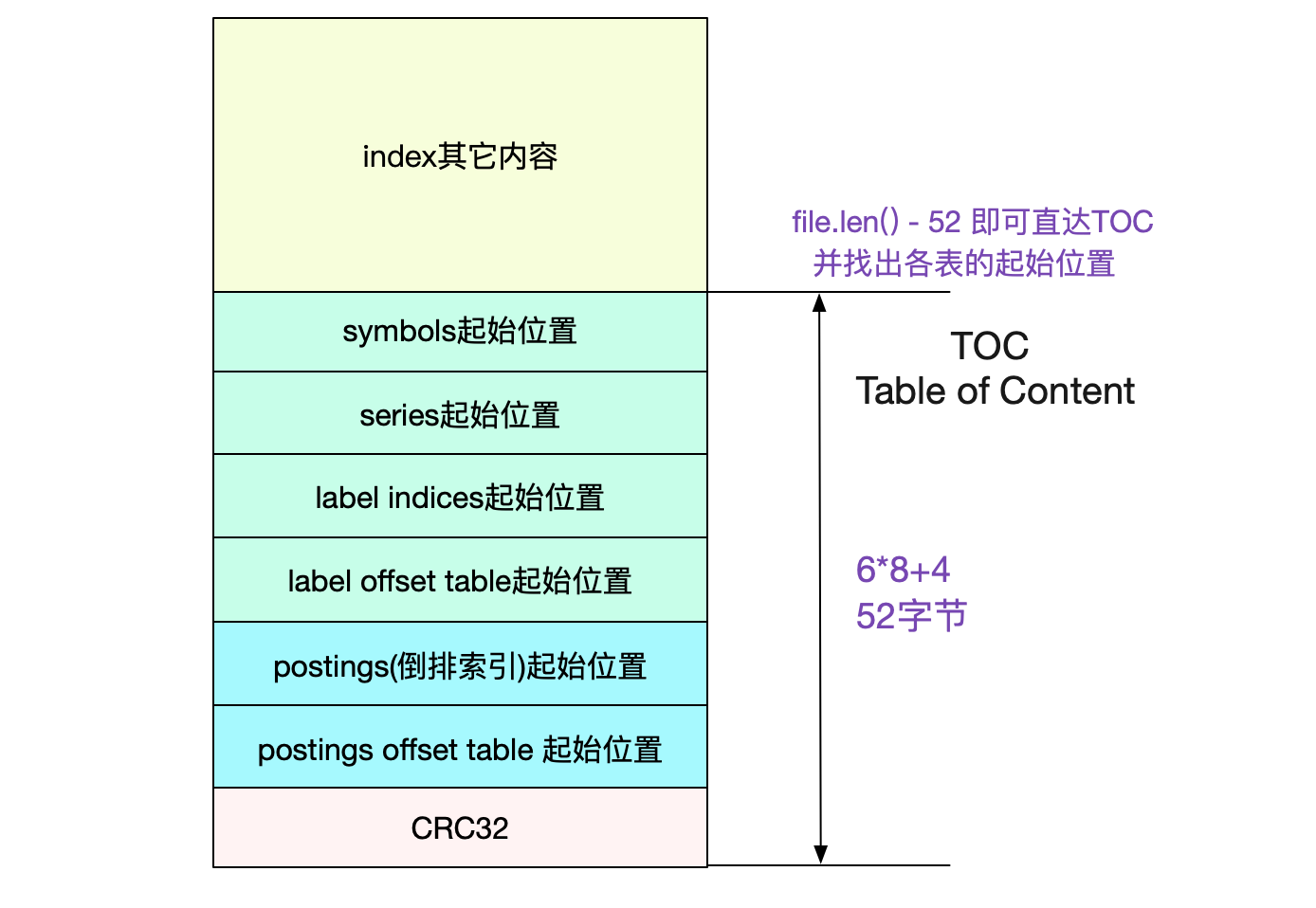
由于index文件一旦形成之后就不再会改变,所以Prometheus也依旧使用mmap来进行操作。采用mmap读取TOC非常容易:
func NewTOCFromByteSlice(bs ByteSlice) (*TOC, error) {
......
// indexTOCLen = 6*8+4 = 52
b := bs.Range(bs.Len()-indexTOCLen, bs.Len())
......
return &TOC{
Symbols: d.Be64(),
Series: d.Be64(),
LabelIndices: d.Be64(),
LabelIndicesTable: d.Be64(),
Postings: d.Be64(),
PostingsTable: d.Be64(),
}, nil
}
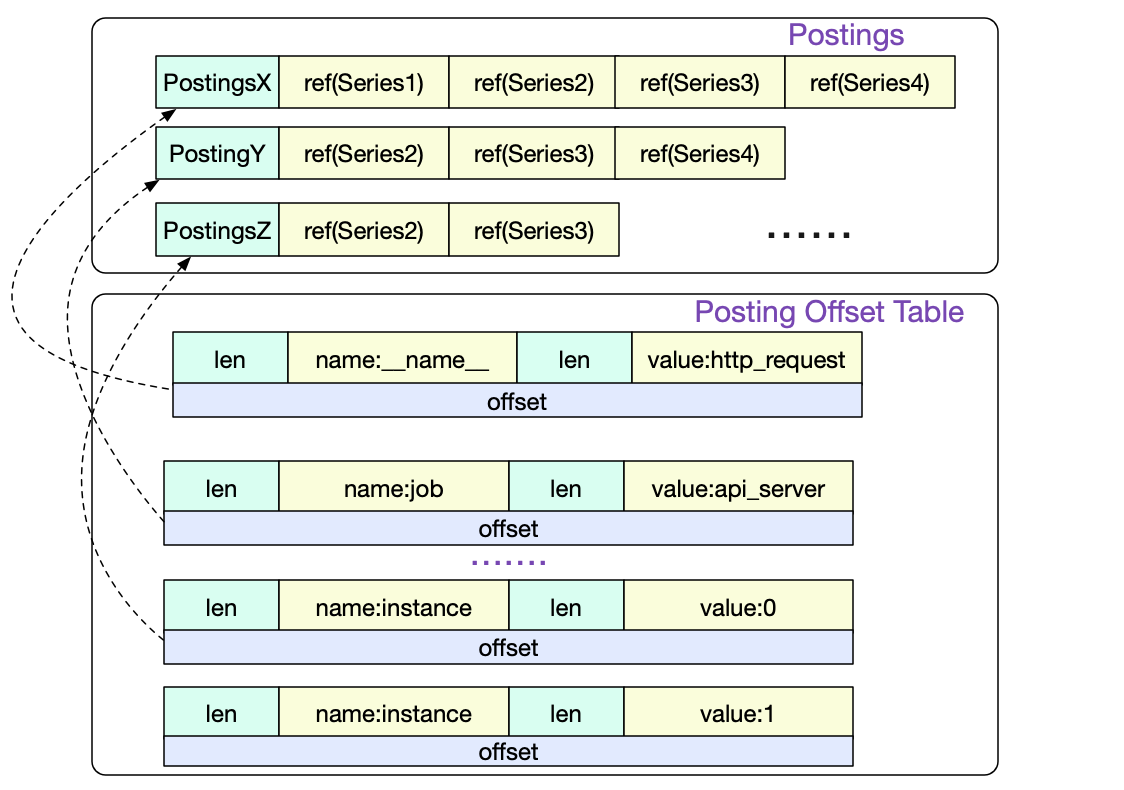
Posting offset table 以及 Posting倒排索引
首先我们访问的是Posting offset table。由于倒排索引按照不同的LabelPair(key/value)会有非常多的条目。所以Posing offset table就是决定到底访问哪一条Posting索引。offset就是指的这一Posting条目在文件中的偏移。
Series
我们通过三条Postings倒排索引索引取交集得出
{series1,Series2,Series3,Series4}
∩
{series1,Series2,Series3}
∩
{Series2,Series3}
=
{Series2,Series3}
也就是要读取Series2和Serie3中的数据,而Posting中的Ref(Series2)和Ref(Series3)即为这两Series在index文件中的偏移。
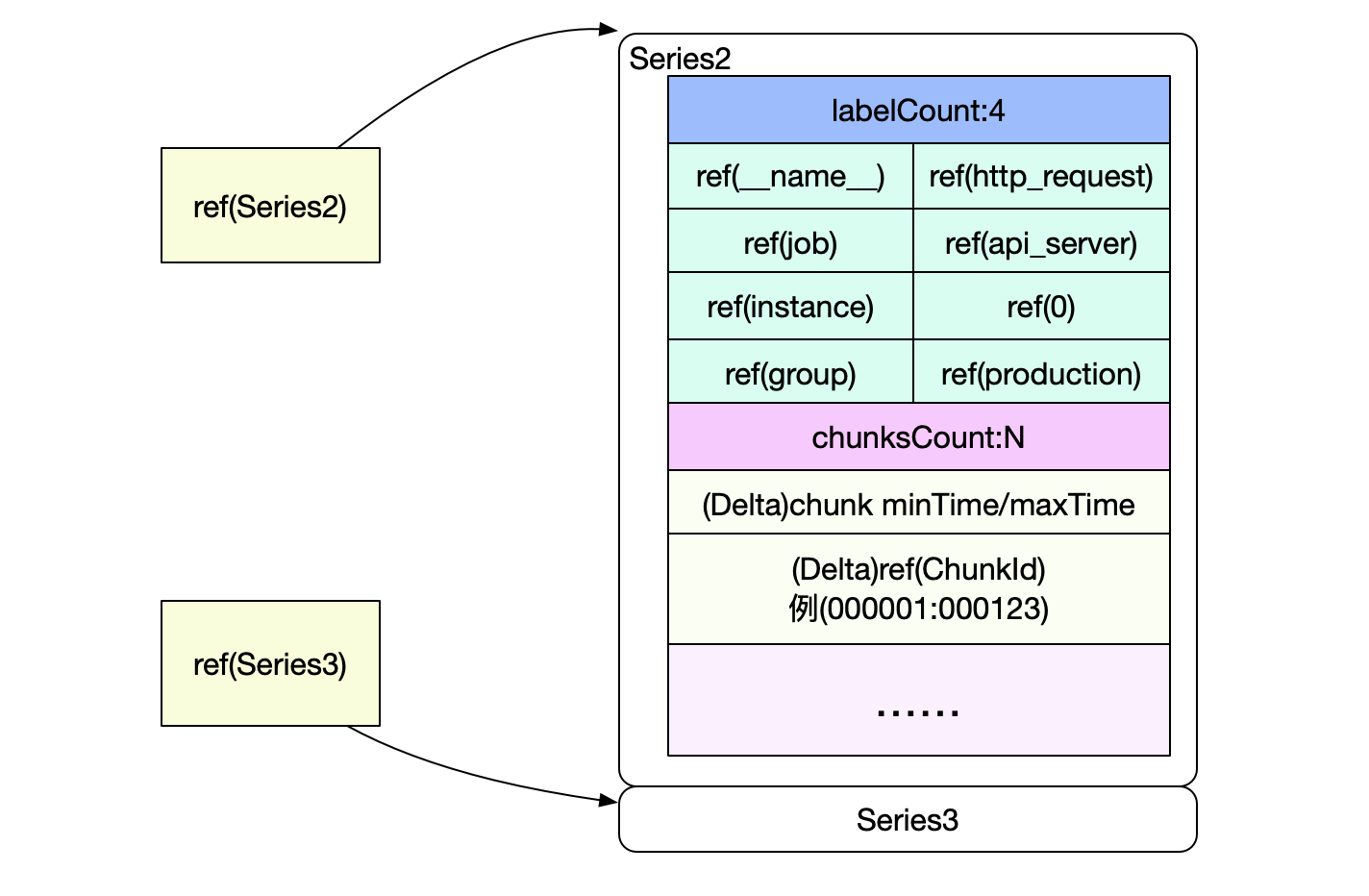
Series以Delta的形式记录了chunkId以及该chunk包含的时间范围。这样就可以很容易过滤出我们需要的chunk,然后再按照chunk文件的访问,即可找到最终的原始数据。
SymbolTable
值得注意的是,为了尽量减少我们文件的大小,对于Label的Name和Value这些有限的数据,我们会按照字母序存在符号表中。由于是有序的,所以我们可以直接将符号表认为是一个
[]string切片。然后通过切片的下标去获取对应的sting。考虑如下符号表:
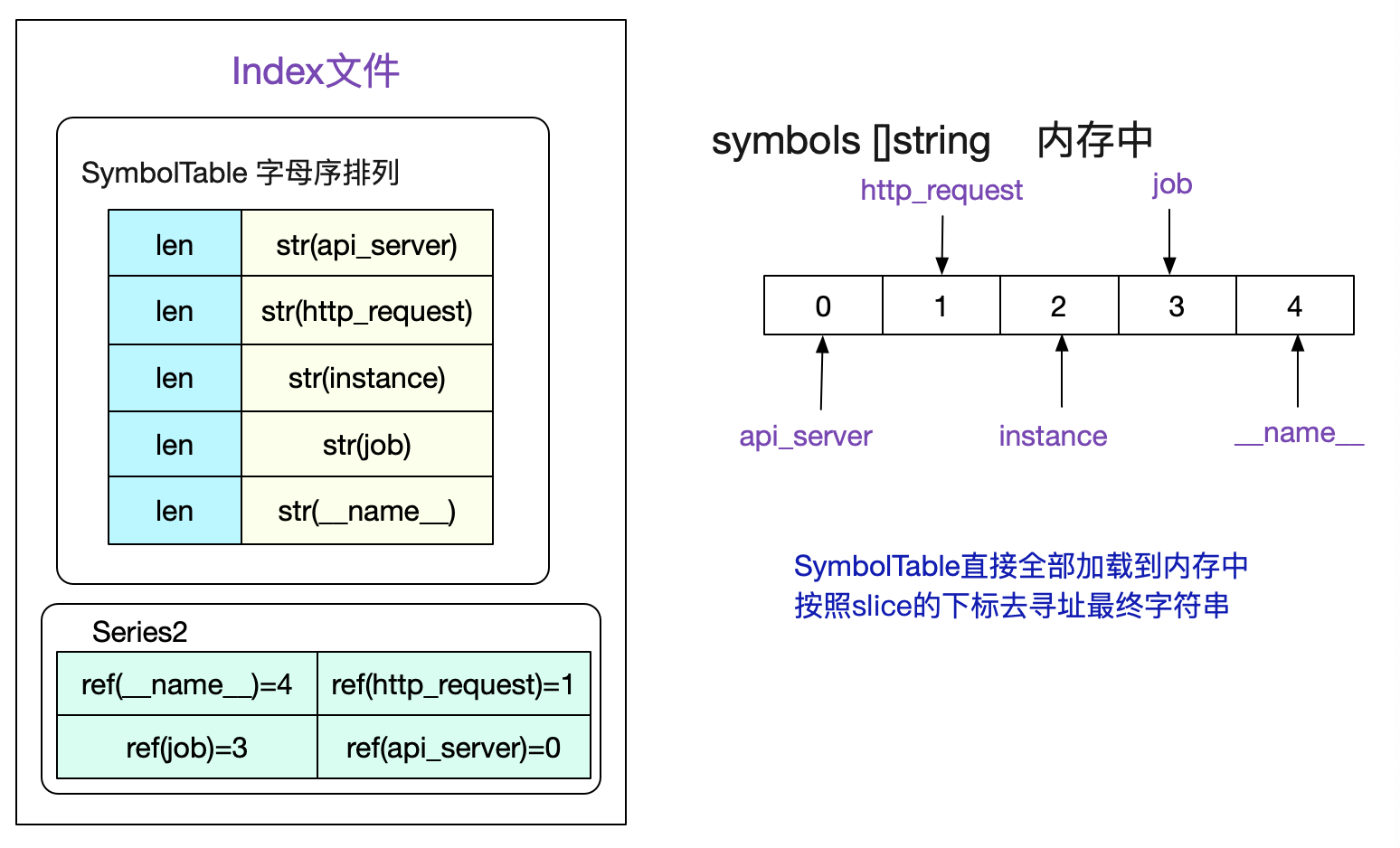
读取index文件时候,会将SymbolTable全部加载到内存中,并组织成symbols []string这样的切片形式,这样一个Series中的所有标签值即可通过切片下标访问得到。
Label Index以及Label Table
事实上,前面的介绍已经将一个普通数据寻址的过程全部讲完了。但是index文件中还包含label索引以及label Table,这两个是用来记录一个Label下面所有可能的值而存在的。
这样,在正则的时候就可以非常容易的找到我们需要哪些LabelPair。详情可以见前篇。
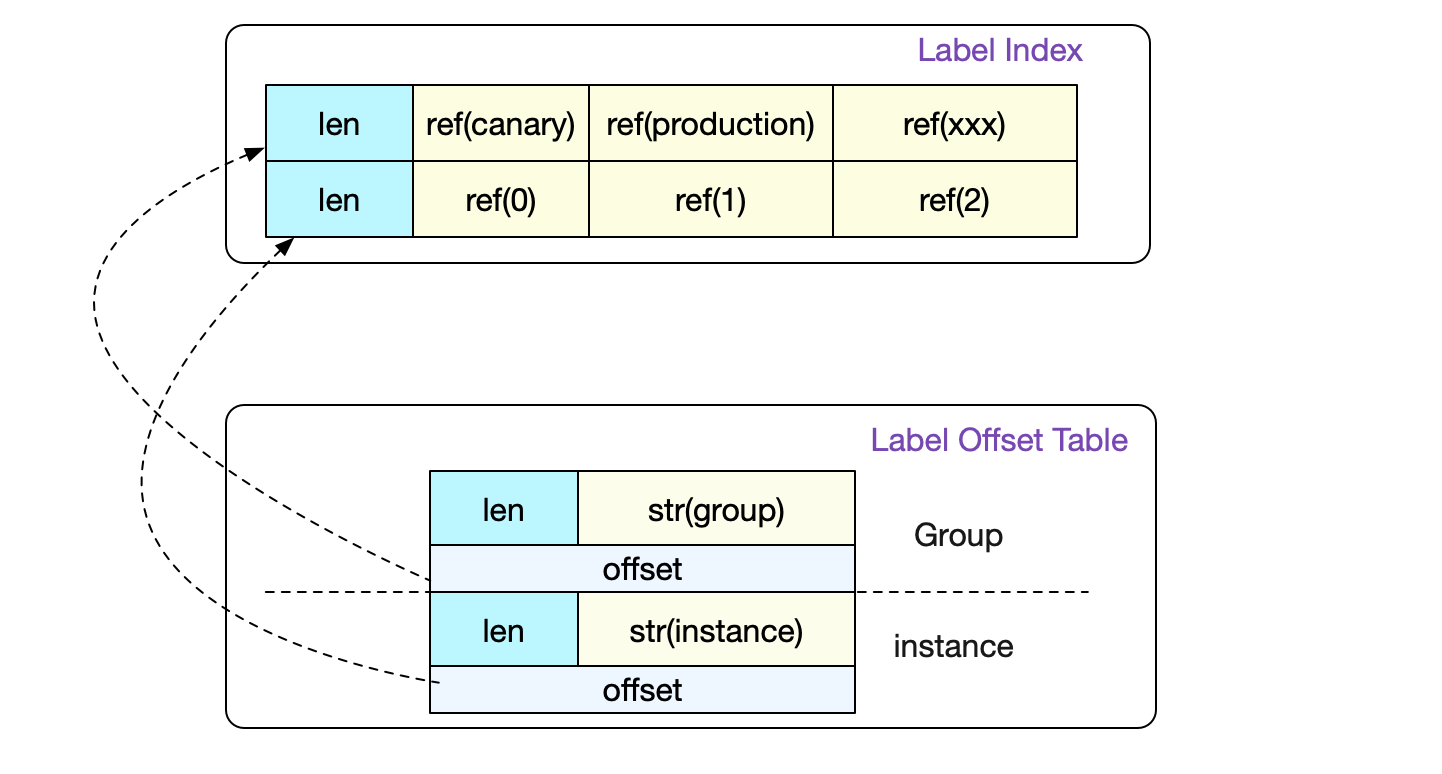
事实上,真正的Label Index比图中要复杂一点。它设计成一条LabelIndex可以表示(多个标签组合)的所有数据。不过在Prometheus代码中只会采用存储一个标签对应所有值的形式。
完整的index文件结构
这里直接给出完整的index文件结构,摘自Prometheus中index.md文档。
┌────────────────────────────┬─────────────────────┐
│ magic(0xBAAAD700) <4b> │ version(1) <1 byte> │
├────────────────────────────┴─────────────────────┤
│ ┌──────────────────────────────────────────────┐ │
│ │ Symbol Table │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Series │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Label Index 1 │ │
│ ├──────────────────────────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Label Index N │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Postings 1 │ │
│ ├──────────────────────────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Postings N │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Label Index Table │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Postings Table │ │
│ ├──────────────────────────────────────────────┤ │
│ │ TOC │ │
│ └──────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────┘
tombstones
由于Prometheus Block的数据一般在写完后就不会变动。如果要删除部分数据,就只能记录一下删除数据的范围,由下一次compactor组成新block的时候删除。而记录这些信息的文件即是tomstones。
总结
Prometheus作为时序数据库,设计了各种文件结构来保存海量的监控数据,同时还兼顾了性能。只有彻底了解其存储结构,才能更好的指导我们应用它!
欢迎大家关注我公众号,里面有各种干货,还有大礼包相送哦!

Prometheus时序数据库-磁盘中的存储结构的更多相关文章
- Prometheus时序数据库-内存中的存储结构
Prometheus时序数据库-内存中的存储结构 前言 笔者最近担起了公司监控的重任,而当前监控最流行的数据库即是Prometheus.按照笔者打破砂锅问到底的精神,自然要把这个开源组件源码搞明白才行 ...
- Prometheus时序数据库-数据的插入
Prometheus时序数据库-数据的插入 前言 在之前的文章里,笔者详细的阐述了Prometheus时序数据库在内存和磁盘中的存储结构.有了前面的铺垫,笔者就可以在本篇文章阐述下数据的插入过程. 监 ...
- Prometheus时序数据库-数据的查询
Prometheus时序数据库-数据的查询 前言 在之前的博客里,笔者详细阐述了Prometheus数据的插入过程.但我们最常见的打交道的是数据的查询.Prometheus提供了强大的Promql来满 ...
- 0160 十分钟看懂时序数据库(I)-存储
摘要:2017年时序数据库忽然火了起来.开年2月Facebook开源了beringei时序数据库:到了4月基于PostgreSQL打造的时序数据库TimeScaleDB也开源了,而早在2016年7月, ...
- Prometheus时序数据库-报警的计算
Prometheus时序数据库-报警的计算 在前面的文章中,笔者详细的阐述了Prometheus的数据插入存储查询等过程.但作为一个监控神器,报警计算功能是必不可少的.自然的Prometheus也提供 ...
- Atitit.数据库表的物理存储结构原理与架构设计与实践
Atitit.数据库表的物理存储结构原理与架构设计与实践 1. Oracle和DB2数据库的存储模型如图: 1 1.1. 2. 表数据在块中的存储以及RowId信息3 2. 数据表的物理存储结构 自然 ...
- MySQL索引(二)B+树在磁盘中的存储
MySQL索引(二)B+树在磁盘中的存储 回顾  上一篇文章<MySQL索引为什么要用B+树>讲了MySQL为什么选择用B+树来作为底层存储结构,提了两个知识点: B+树索引并不能直接找 ...
- (续)一个demo弄清楚位图在内存中的存储结构
本来续---数字图像处理之位图在计算机中的存储结构一文,通过参考别人的代码,进行修改和测试终于成功运行. 该实例未使用任何API和相关类,相信如果对此实例能够完全理解那么将有进一步进行数字图像处理的能 ...
- 时序数据库连载系列: 时序数据库一哥InfluxDB之存储机制解析
InfluxDB 的存储机制解析 本文介绍了InfluxDB对于时序数据的存储/索引的设计.由于InfluxDB的集群版已在0.12版就不再开源,因此如无特殊说明,本文的介绍对象都是指 InfluxD ...
随机推荐
- shell编程基础一
1.定义变量 a=1 shell定义变量要注意等号前后不能有空格,不然会报错,请严格按照格式编写. 2.打印输出 echo 1 使用echo打印,后面留一个空格. 3.shell中通过 ${变量名} ...
- Codeforces Round #589 (Div. 2) Another Filling the Grid (dp)
题意:问有多少种组合方法让每一行每一列最小值都是1 思路:我们可以以行为转移的状态 附加一维限制还有多少列最小值大于1 这样我们就可以不重不漏的按照状态转移 但是复杂度确实不大行(减了两个常数卡过去的 ...
- [CCPC2019网络赛] 1008-Fishing Master(思维)
>传送门< 题意:现在需要捕$n$条鱼并且将它们煮熟来吃.每条鱼要煮相应的时间才能吃(可以多煮一会),锅里每次只能煮一条鱼,捕一条鱼的时间是相同的,但是在捕鱼的时间内不能做其他事(比如换一 ...
- hdu4126Genghis Khan the Conqueror (最小生成树+树形dp)
Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 327680/327680 K (Java/Others) Total Submiss ...
- SP3267 DQUERY - D-query 莫队板子题
题意可见:https://www.luogu.com.cn/problem/SP3267 可在vj上提交:https://vjudge.net/problem/SPOJ-DQUERY 题意翻译 给出一 ...
- Bubble Cup 13 - Finals [Online Mirror, unrated, Div. 1] K. Lonely Numbers (数学)
题意:定义两个数\(a,b\)是朋友,如果:\(gcd(a,b)\),\(\frac{a}{gcd(a,b)}\),\(\frac{b}{gcd(a,b)}\)能构成三角形,现在给你一个正整数\(n\ ...
- [POJ 2585] Window Pains 拓朴排序
题意:你现在有9个2*2的窗口在4*4的屏幕上面,由于这9这小窗口叠放顺序不固定,所以在4*4屏幕上有些窗口只会露出来一部分. 如果电脑坏了的话,那么那个屏幕上的各小窗口叠放会出现错误.你的任务就是判 ...
- Codeforces Round #544 (Div. 3) E. K Balanced Teams (DP)
题意:有\(n\)个人,每个人的能力值是\(a_i\),现在你想将这些人分成\(k\)组(没必要全选),但是每组中最高水平和最低水平的人的能力差值必须\(\le 5\),问最多能选多少人. 题解:想了 ...
- PowerShell随笔2---初始命令
PowerShell便捷之处 PowerShell中兼容运行cmd的命令,比如 ipconfig.ping命令等 PowerShell的命令更友好,可读性更强.比如停止一个服务 CMD命令:sc st ...
- 正则指引 pdf 高清版
链接:https://pan.baidu.com/s/1Xeuma4toE_L-MxROvTGBxw 提取码:nqyj