python爬取股票最新数据并用excel绘制树状图
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊。

不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们。
以下截图来自金融界网站-大盘云图:
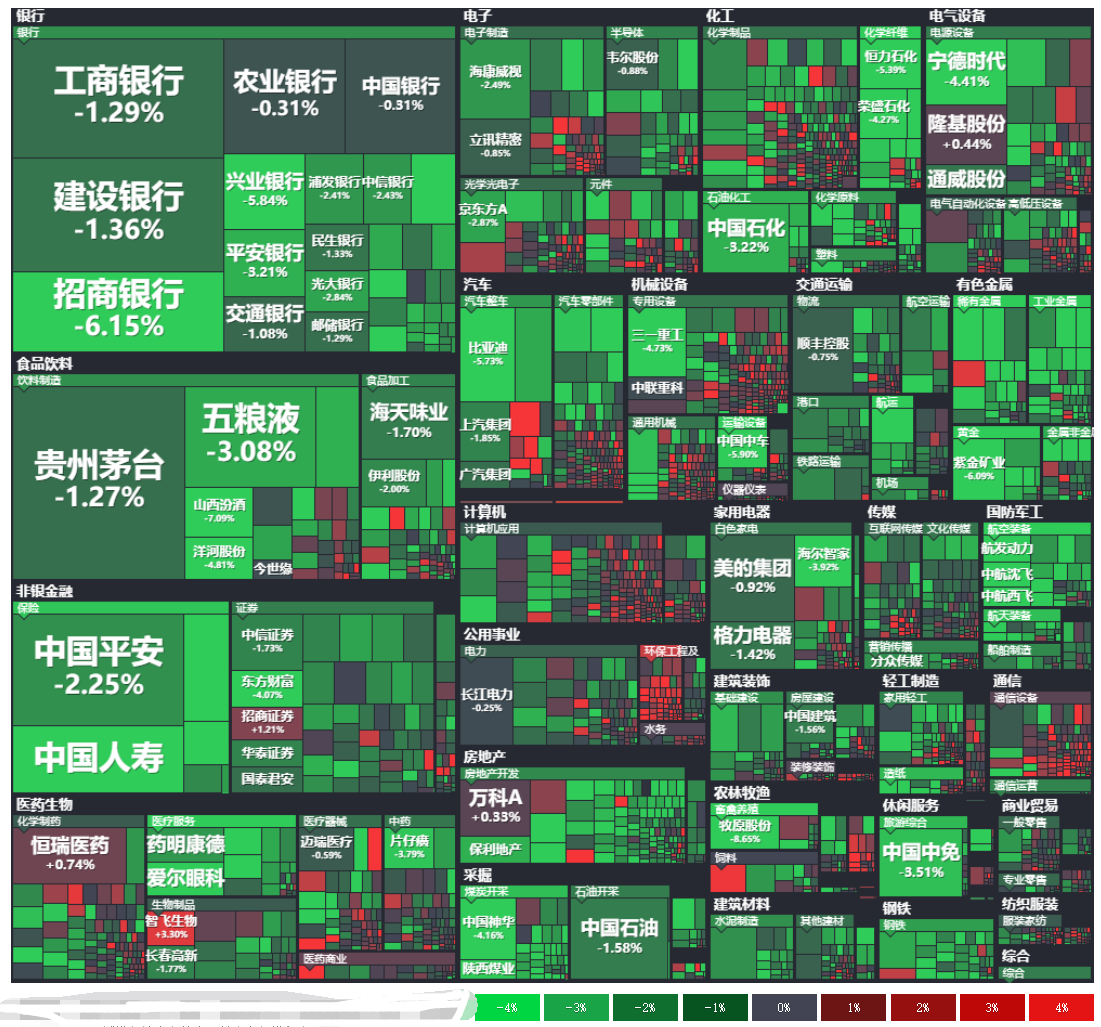
那么,今天我们试着用python爬取最近交易日的股票数据,并试着用excel简单绘制以下上面这个树状图。本文旨在抛砖引玉,吼吼。
1. python爬取网易财经不同板块股票数据
目标网址:
http://quotes.money.163.com/old/#query=hy010000&DataType=HS_RANK&sort=PERCENT&order=desc&count=24&page=0
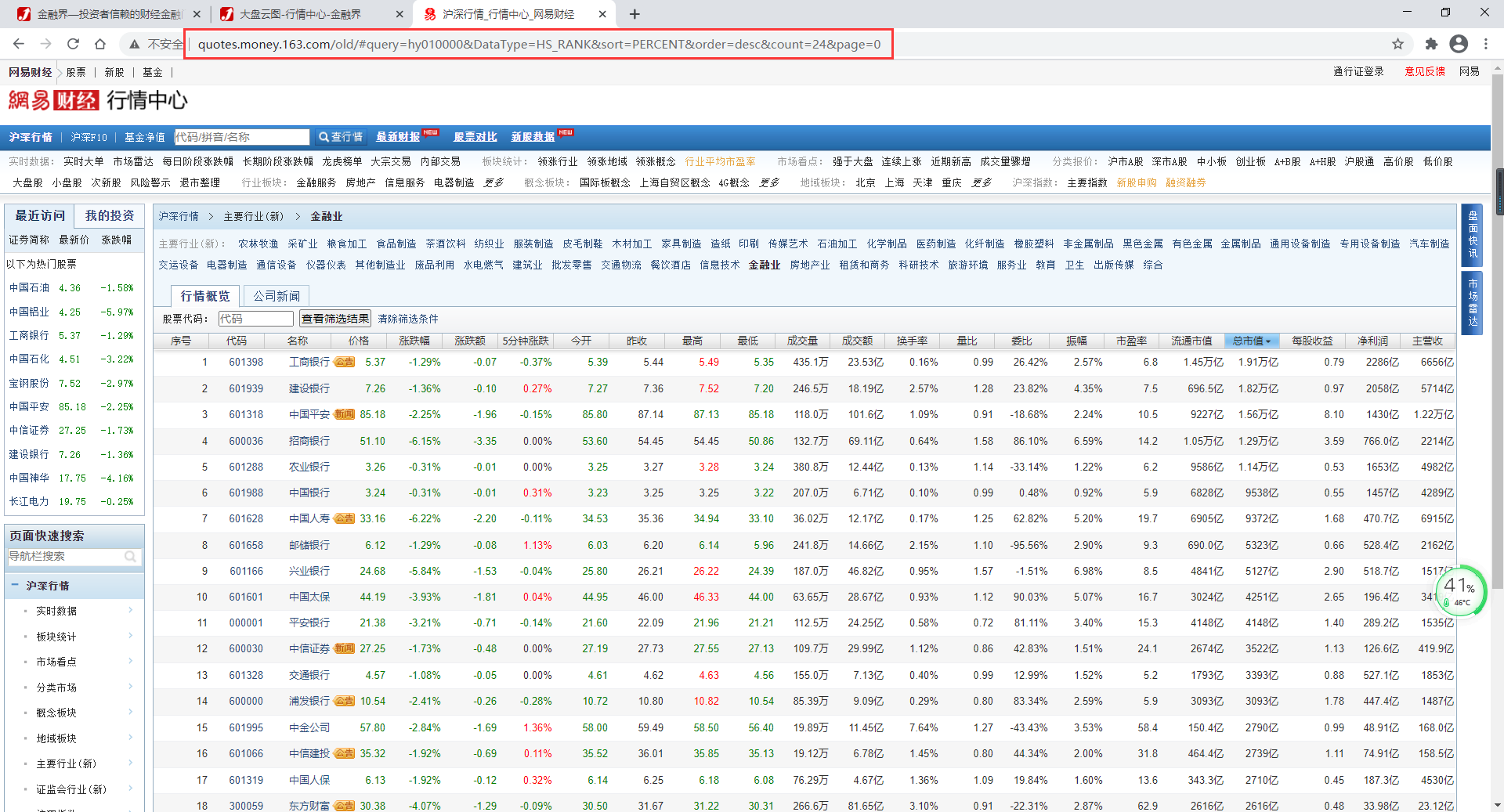
由于这个爬虫部分比较简单,这里不做过多赘述,仅介绍一下思路并附上完整代码供大家参考。
爬虫思路:
- 请求目标网站数据,解析出主要行业(新)的数据:行业板块名称及对应id(如金融,hy010000)
- 根据行业板块对应id构造新的行业股票数据网页
- 由于翻页网址不变,按照《》的里的套路找到股票列表数据的真实地址
- 代入参数,获取全部页数,然后翻页爬取全部数据
爬虫代码:
# -*- coding: utf-8 -*-
"""
Created Feb 28 10:30:56 2021
@author: 可以叫我才哥
"""
import requests
import re
import pandas as pd
# 获取全部板块及板块id
url = 'http://quotes.money.163.com/old/#query=hy001000&DataType=HS_RANK&sort=PERCENT&order=desc&count=24&page=0'
r = requests.get(url)
html = r.text
# 替换非字符为空,便于下面的正则
html = re.sub('\s','',html)
# 正则获取 板块及id所在区域
labelHtml = re.findall(r'</span>主要行业\(新\)</a>(.*?)</span>证监会行业\(新\)',html)[0]
# 正则板块和id,结果为由元组组成的列表
label = re.findall(r'"qid="(hy.*?)"qquery=.*?"title="(.*?)">',labelHtml)
# 转化为dataframe类型
dfLabel = pd.DataFrame(label,columns=['id','板块'])
# 根据板块id和翻页获取页面数据(json格式)
def get_json(hy_id, page):
query = 'PLATE_IDS:' + str(hy_id)
params={
'host': 'http://quotes.money.163.com/hs/service/diyrank.php',
'page': page,
'query': query,
'fields': 'NO,SYMBOL,NAME,PRICE,PERCENT,UPDOWN,FIVE_MINUTE,OPEN,YESTCLOSE,HIGH,LOW,VOLUME,TURNOVER,HS,LB,WB,ZF,PE,MCAP,TCAP,MFSUM,MFRATIO.MFRATIO2,MFRATIO.MFRATIO10,SNAME,CODE,ANNOUNMT,UVSNEWS', #你可以不用这么多字段
'sort': 'PERCENT',
'order': 'desc',
'count': '24',
'type': 'query',
}
url = 'http://quotes.money.163.com/hs/service/diyrank.php?'
r = requests.get(url,params=params)
j = r.json()
return j
# 空列表用于存取每页数据
dfs = []
# 遍历全部板块
for hy_id,板块 in dfLabel.values:
# 获取页数
j = get_json(hy_id, 0)
pages = j['pagecount']
for page in range(pages):
j = get_json(hy_id, page)
data = j['list']
df = pd.DataFrame(data)
df['板块'] = 板块
dfs.append(df)
print(f'已爬取{len(dfs)}个板块数据')
result = pd.concat(dfs)
2. excel树状图
excel树状图是在office2016级之后版本中新加的图表类型,想要绘制需要基于此版本及之后的版本哦。
2.1. 简单的树状图
简单的树状图绘制流程:框选数据—>插入—>图表—>选中树状图 即可。

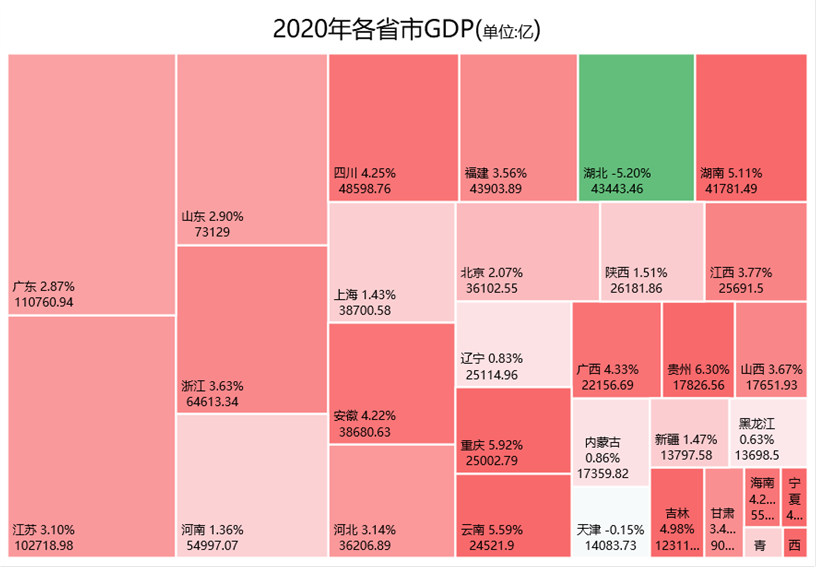
以下图为例,在树状图中,每个色块代表一个省份,色块面积大小则由其GDO值大小决定。
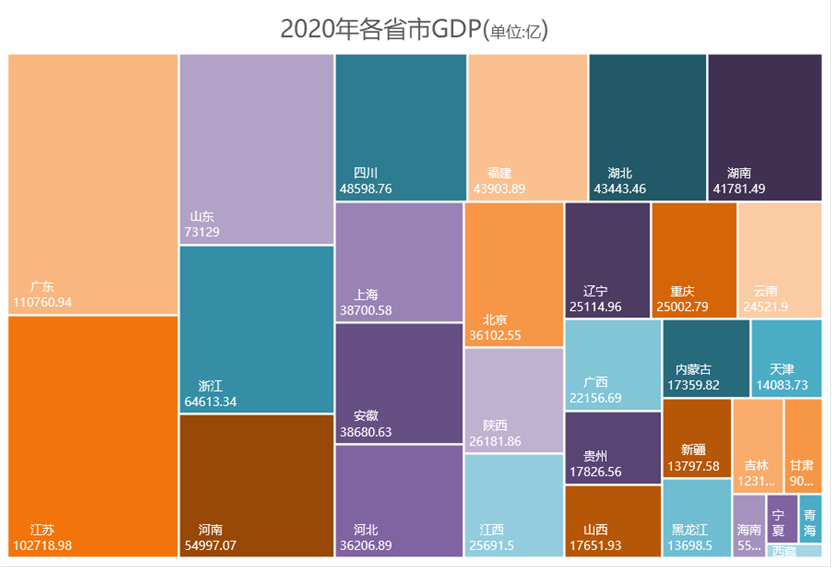
2.2. 带有增长率的树状图
我们发现,在基础的树状图中,色块颜色除了区别色块之外并没有其他特殊含义。拿GDP来说,除了值之外我们一般也会去看其增长率,那么是否可以让色块颜色和增长率有关联呢?
下面我们试着探究一下,如果成功的话,那么金融界的大盘云图似乎也可以用excel树状图来进行绘制了不是!
思路:
- 我们希望色块颜色能代表增长率,比如红色是上涨,绿色是下降且颜色越深代表绝对值越大
- 再对每个色块进行对应的颜色填充即可
由于 树状图顶多支持多级,色块颜色也只能手动单一填充,怎么办呢?既然手动可以,那么其实就可以用VBA自动化这个过程咯。
2.3.1. 增长率配色
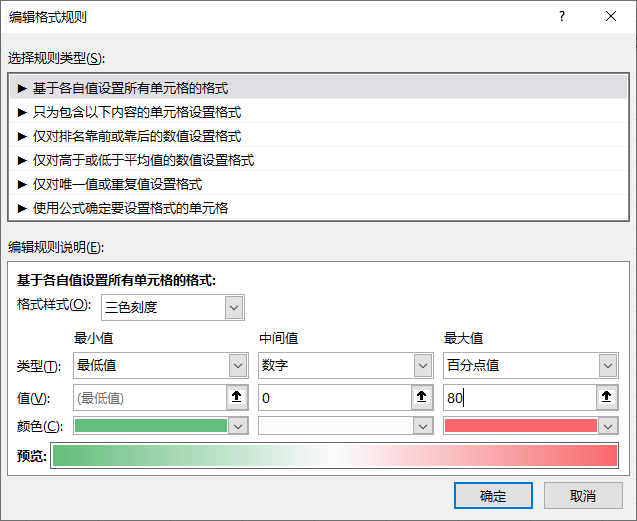
基于思路1,我们需要对增长率进行配色,最简单的就是用条件格式里的色阶。
框选增长率数据—>开始—>条件格式—>色阶(选中那个让值越大颜色越红的,由于这里有负增长率,所以选了带红绿的):
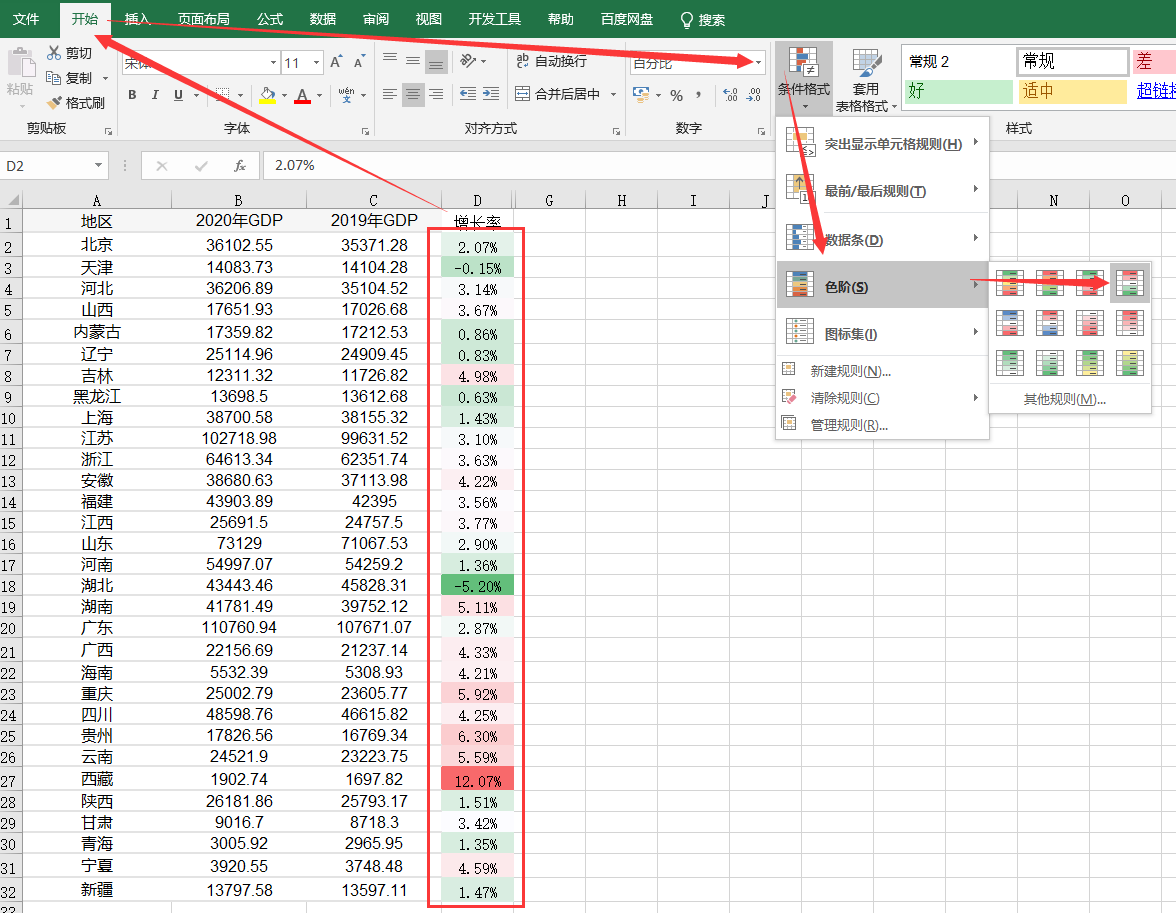
为了更好的展示区分正负增长率,我们在设置完色阶后再进行管理规则:
- 我们将中间值设为数字0,这样负增长率就是绿色,正增长率就是红色;
- 我们将最大值设置为百分点值80,也就是增长率前80%的值都是最红的。
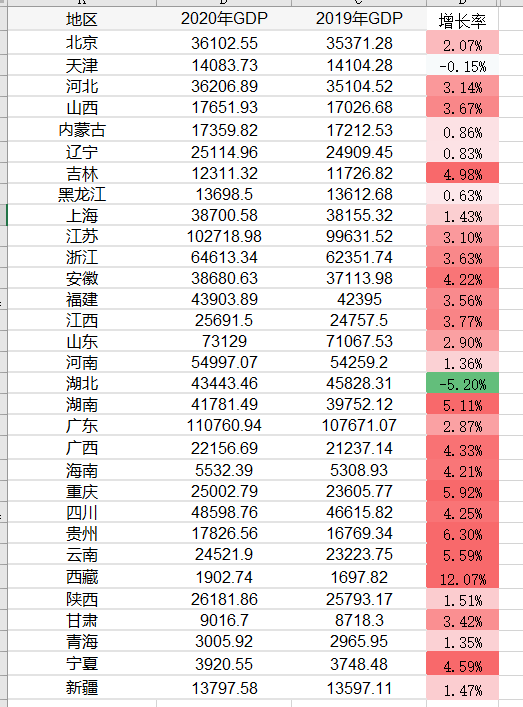
最终配色效果:
2.3.2. VBA填充色块颜色
先看效果:
湖北因为收到疫情影响最大,有接近小半年属于封省状态,全年增长率为负数。
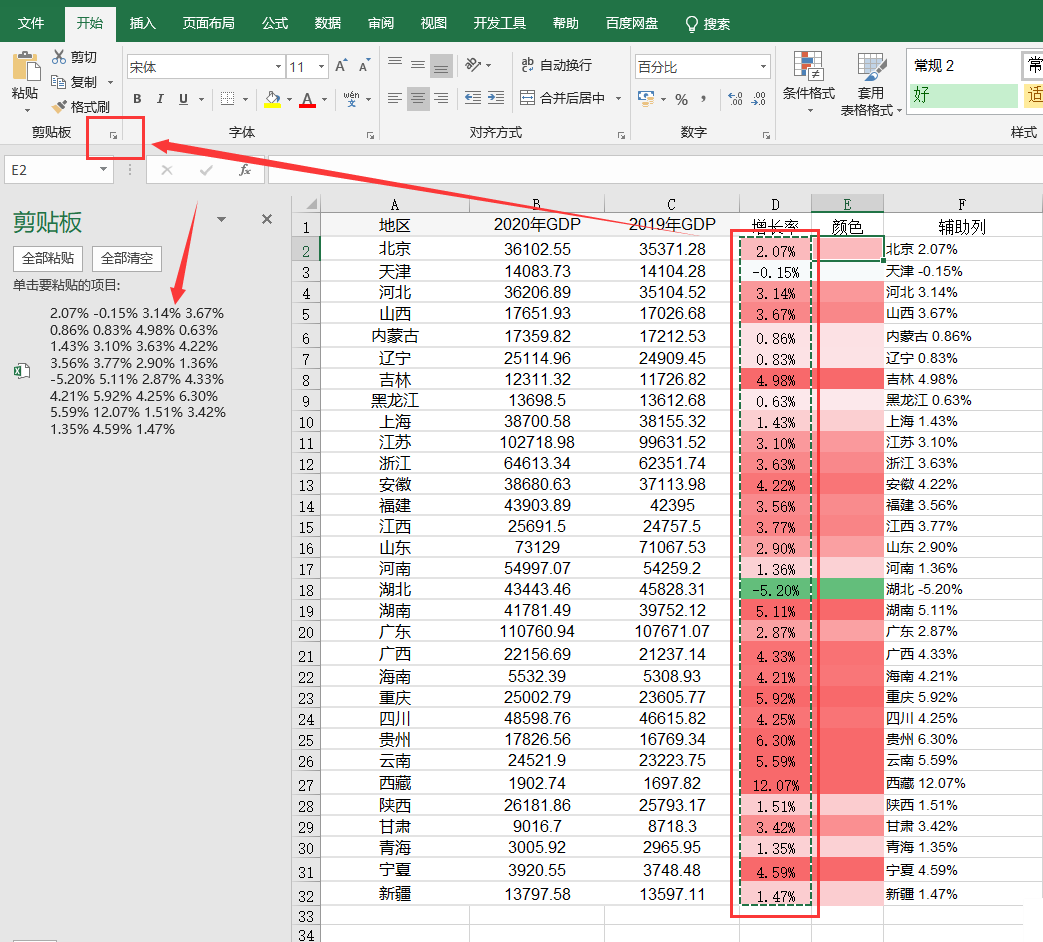
由于条件格式下单元格颜色是不固定的无法通过vba获取,我们需要将颜色赋值到新的一列中去,需要用到如下操作:
**选中增长率数据复制,然后点击剪切板最右下角会出现剪贴板,再鼠标左键选择需要粘贴的地方如E2,点击剪贴板中需要粘贴的数据即可。**这个时候,被粘贴的单元格区域的颜色就是固定的了,你可以选择删除数据只留颜色部分。
VBA思路:
激活需要操作的图表(Activate)
遍历全部的系列和数据点(ActiveChart.FullSeriesCollection(1).Points.Count)
从第一个数据点开始,获取对应增长率单元格颜色(ActiveSheet.Range("E" & i + 1).Interior.Color)
将单元格赋值给该数据点(Selection.Format.Fill.ForeColor.RGB)
VBA代码:
Sub My_Color()
ActiveSheet.ChartObjects("图表 1").Activate
'遍历全部的数据点
For i = 1 To ActiveChart.FullSeriesCollection(1).Points.Count
'选中数据点
ActiveChart.FullSeriesCollection(1).Points(i).Select
'获取单元格颜色
MyColor = ActiveSheet.Range("E" & i + 1).Interior.Color
'将单元格颜色赋值给对应数据点填充色
Selection.Format.Fill.ForeColor.RGB = MyColor
Next
End Sub
执行脚本过程如下:
好了,以上就是本次全部内容,大家可以试着爬取股票数据,然后试着绘制一下。
温馨提示:接近小5000股票数据,vba填充色块颜色会卡死,不建议全选操作。
python爬取股票最新数据并用excel绘制树状图的更多相关文章
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
- 利用Python爬取朋友圈数据,爬到你开始怀疑人生
人生最难的事是自我认知,用Python爬取朋友圈数据,让我们重新审视自己,审视我们周围的圈子. 文:朱元禄(@数据分析-jacky) 哲学的两大问题:1.我是谁?2.我们从哪里来? 本文 jacky试 ...
- 用Python爬取股票数据,绘制K线和均线并用机器学习预测股价(来自我出的书)
最近我出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中用股票范例讲述Pyth ...
- 如何使用python爬取网页动态数据
我们在使用python爬取网页数据的时候,会遇到页面的数据是通过js脚本动态加载的情况,这时候我们就得模拟接口请求信息,根据接口返回结果来获取我们想要的数据. 以某电影网站为例:我们要获取到电影名称以 ...
- Python爬取招聘网站数据,给学习、求职一点参考
1.项目背景 随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大.因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于 ...
- python 爬取网页简单数据---以及详细解释用法
一.准备工作(找到所需网站,获取请求头,并用到请求头) 找到所需爬取的网站(这里举拉勾网的一些静态数据的获取)----------- https://www.lagou.com/zhaopin/Pyt ...
- 用Python爬取大众点评数据,推荐火锅店里最受欢迎的食品
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:有趣的Python PS:如有需要Python学习资料的小伙伴可以加点 ...
- 这价格看得我偷偷摸了泪——用python爬取北京二手房数据
如果想了解更多关于python的应用,可以私信我,或者加群,里面到资料都是免费的 http://t.cn/A6Zvjdun 近期,有个朋友联系我,想统计一下北京二手房的相关的数据,而自己用Excel统 ...
- python爬取拉勾网职位数据
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站--拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助. 完成 ...
随机推荐
- Codeforces Round #671 (Div. 2)
比赛链接:https://codeforces.com/contest/1419 A. Digit Game 题意 给出一个 $n$ 位数,游戏规则如下: 1-indexed Raze标记奇数位 Br ...
- 【uva 1612】Guess(算法效率,2种想法)
题意:已知 N 位选手的3题的预期得分,得分要不全拿,要不为0.且知道最后的实际名次,而且得分相同的选手,ID小的排在前面.问这样的名次可能吗.若可能,输出最后一名的最高可能得分.(N≤16384) ...
- java——字符串常量池、字符串函数以及static关键字的使用、数组的一些操作函数、math函数
字符串常量池: 字符串比较函数: 字符串常用方法: 字符串截取函数: 字符串截取函数: static关键字使用: 要调用类中的static类型的变量的时候,可以用"类名.变量名&quo ...
- Codeforces Round #582 (Div. 3) F. Unstable String Sort
传送门 题意: 你需要输出一个长度为n的字符序列(由小写字母组成),且这个字符串中至少包含k个不同的字符.另外题目还有要求:给你两个长度为p和q的序列,设字符序列存在s中 那么就会有s[Pi]< ...
- C/C++程序内存的各种变量存储区域和各个区域详解
转自 https://blog.csdn.net/jirryzhang/article/details/79518408 C语言在内存中一共分为如下几个区域,分别是: 1. 内存栈区: 存放局部变量名 ...
- Leetcode(32)-最长有效括号
给定一个只包含 '(' 和 ')' 的字符串,找出最长的包含有效括号的子串的长度. 示例 1: 输入: "(()" 输出: 2 解释: 最长有效括号子串为 "()&quo ...
- MDK5生成BIn文件的方法
配置MDK5 生成bin文件的 第一步:方法打开option for Target 第二步:选择 user 第三步:找到After Build/Rebuild 第四步:勾选run,点击文件选择小图标选 ...
- 高并发之ReentrantLock、CountDownLatch、CyclicBarrier
本系列研究总结高并发下的几种同步锁的使用以及之间的区别,分别是:ReentrantLock.CountDownLatch.CyclicBarrier.Phaser.ReadWriteLock.Stam ...
- css scroll text without wrap & webkit-scrollbar
css scroll text without wrap hidden webkit-scrollbar .tabs-title-box::-webkit-scrollbar, .tabs-conte ...
- input composition event All In One
input composition event All In One input event compositionStart & compositionEnd & compositi ...