Java集合框架1-- HashMap
HashMap的知识点可以说在面试中经常被问到,是Java中比较常见的一种数据结构。所以这一篇就通过源码来深入理解下HashMap。
1 HashMap的底层是如何实现的?(基于JDK8)
1.1 HashMap的类结构和成员
/**
HashMap继承AbstractMap,而AbstractMap又实现了Map的接口
*/
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
从上面源码可以看出HashMap支持序列化和反序列化,而且实现了cloneable接口,能支持clone()方法复制一个对象。
1.1.1 HashMap源码中的几个成员属性
//最小容量为16,且一定是2的幂次
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大容量为2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//当某节点的链表长度大于8并且hash数组的容量达到64时,链表将会转换成红黑树
static final int TREEIFY_THRESHOLD = 8;
//当链表长度小于6时,红黑树将转换成链表
static final int UNTREEIFY_THRESHOLD = 6;
//链表变成红黑树的最小容量
static final int MIN_TREEIFY_CAPACITY = 64;
从上面的源码可以看出,JDK1.8的HashMap实际上是由数组+链表+红黑树组成,在一定条件下链表会转换成红黑树。这里要谈一下默认加载因子为什么为0.75(3/4),加载因子也叫扩容因子,用来判断HashMap什么时候进行扩容。选择0.75的原因是为了平衡容量与查找性能:扩容因子越大,造成hash冲突的几率就越大,查找性能就会越低,反之扩容因子越小,所占容量就会越大。于此同时,负载因子为3/4的话,和capacity的乘积结果就可以是一个整数。
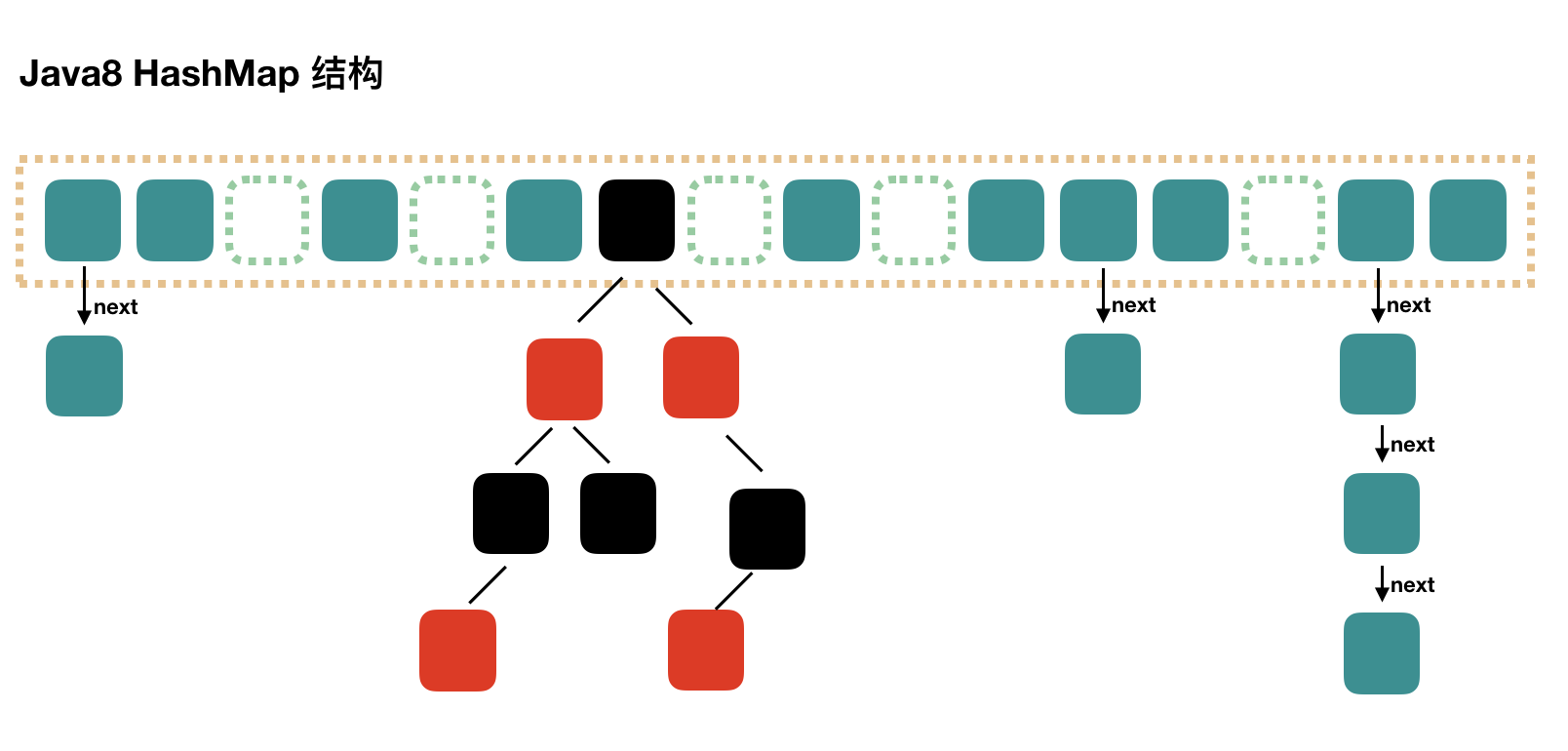
下面再看看hash数组中的元素
1.1.2 HashMap中的数组节点
hash数组一般称为哈希桶(bucket),结点在JDK1.7中叫Entry,在JDK1.8中叫Node。
//1.8中Node实现entry的接口
static class Node<K,V> implements Map.Entry<K,V> {
//每个节点都会包含四个字段:hash、key、value、next
final int hash;
final K key;
V value;
Node<K,V> next;//指向下一个节点
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
//hash值是由key和value的hashcode异或得到
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
//判断o对象是否为Map.Entry的实例
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
//再判断两者的key和value值是否相同
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
//这个是扰动函数,减少hash碰撞
static final int hash(Object key) {
int h;
//将key的高16位与低16位异或(int是2个字节,32位)
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
1.2 HashMap中的方法
1.2.1 查询方法
public V get(Object key) {
Node<K,V> e;
//将key值扰动后传入getNode函数查询节点
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//判断哈希表是否为空,第一个节点是否为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//从第一个节点开始查询,如果hash值和key值相等,则查询成功,返回该节点
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//查询下一个节点
if ((e = first.next) != null) {
//若该节点存在红黑树,则从红黑树中查找节点
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//若该节点存在链表,循着链表查找节点
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
1.2.2 新增方法
向哈希表中插入一个节点
public V put(K key, V value) {
//将扰动的hash值传入,调用putVal函数
return putVal(hash(key), key, value, false, true);
}
//当参数onlyIfAbsent为true时,不会覆盖相同key的值value;当evict是false时,表示是在初始化时调用
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//若哈希表为空,直接对哈希表进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//若当前节点为空,则直接在该处新建节点
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {//若当前节点非空,则说明发生哈希碰撞,再考虑是链表或者红黑树
Node<K,V> e; K k;
//如果与该节点的hash值和key值都相等,将节点引用赋给e
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果p是树节点的实例,调用红黑树方法新增一个树节点e
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//若该节点后是链表
else {
for (int binCount = 0; ; ++binCount) {
//遍历到链表末尾插入新节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//若插入节点后,链表节点数大于转变成红黑树的临界值(>=8)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//将链表转换成红黑树
treeifyBin(tab, hash);
break;
}
//遍历过程中发现了key和hash值相同的节点,用e覆盖该节点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//对e节点进行处理
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//节点插入成功,修改modCount值
++modCount;
//如果达到扩容条件,直接扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
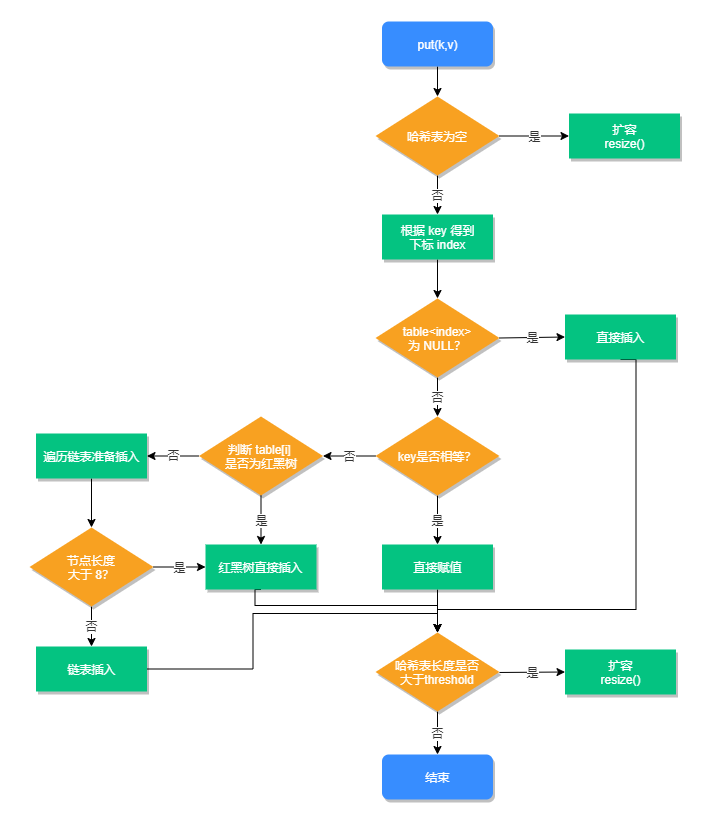
1.2.3 扩容方法(非常重要)
final Node<K,V>[] resize() {
//当前的数组
Node<K,V>[] oldTab = table;
//当前的数组大小和阈值
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
//对新数组大小和阈值初始化
int newCap, newThr = 0;
//若当前数组非空
if (oldCap > 0) {
//若当前数组超过容量最大值,返回原数组不扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//若当前数组低于阈值,直接在数组容量范围内扩大两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//数组为空,且大于最小容量(数组初始化过)
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
//数组为空,且没有初始化
else { // zero initial threshold signifies using defaults
//初始化数组
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//数组为空,且新的阈值为0
if (newThr == 0) {
//求出新的阈值(新数组容量*加载因子)
float ft = (float)newCap * loadFactor;
//判断新阈值是否越界,并做相应的赋值
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//阈值更新
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//构建新的数组并赋值
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//若之前数组非空,将数据复制到新数组中
if (oldTab != null) {
//循环之前数组,将非空元素复制到新数组中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//若循环到该节点是最后一个非空节点,直接赋值
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//若发现该节点是树节点
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//若该节点后是链表
else { // preserve order
//定义现有数组的位置low,扩容后的位置high;high = low + oldCap
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
/*通过(e.hash & oldCap)来确定元素是否需要移动,
e.hash & oldCap大于0,说明位置需要作相应的调整。
反之等于0时说明在该容量范围内,下标位置不变。
*/
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//低位下标位置不变
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//处于高位位置要改变为j + oldCap
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap实际上是线程不安全的,在JDK1.7中,链表的插入方式为头插法,在多线程下插入可能会导致死循环。因此在JDK1.8中替换成尾插法(其实想要线程安全大可用ConcurrentHashMap、Hashtable)
//JDK1.7源码
void transfer(Entry[] newTable boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
//多线程在这里会导致指向成环
Entry<K,V> next = e.next;
if(rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, new Capacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
假如HashMap的容量为2,其中在数组中有一个元素a(此时已经到达扩容的临界点)。创建两个线程t1、t2分别插入b、c,因为没有锁,两个线程都进行到扩容这一步,那么其中有节点位子因为扩容必然会发生变化(以前的容量不够),这个时候假设t1线程成功运行,插入成功。但是由于t2线程的合并,加上节点位置的挪动,就会造成链表成环。最后读取失败
1.2.4 删除方法
//通过key值删除该节点,并返回value
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value;
}
//删除某个节点
//若matchValue为true时,需要key和value都要相等才能删除;若movable为false时,删除节点时不移动其他节点
final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//若数组非空
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
//设node为删除点
Node<K,V> node = null, e; K k; V v;
//查到头节点为所要删除的点,直接赋于node
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
//否则遍历
else if ((e = p.next) != null) {
//当节点为树节点
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
//节点为链表时
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//对取回的node节点进行处理,当matchValue为false,或者value相等时
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) //为树节点
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p) //为链表头结点
tab[index] = node.next;
else //为链表中部节点
p.next = node.next;
//修改modCount和size
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
2.一些面试题
2.1 JDK1.8 HashMap扩容时做了哪些优化
新元素下标方面,1.8通过高位运算
(e.hash & oldCap) == 0分类处理表中的元素:低位不变,高位原下标+原数组长度;而不是像1.7中计算每一个元素下标。在resize()函数中,1.8将1.7中的头插逆序变成尾插顺序。但是仍然建议在多线程下不要用HashMap。
2.2 HashMap与Hashtable的区别
- 线程安全:Hashtable是线程安全的,不允许key,value为null。
- 继承父类:Hashtable是Dictionary类的子类(Dictionary类已经被废弃),两者都实现了Map接口。
- 扩容:Hashtable默认容量为11,扩容为原来的容量2倍+1,所以Hashtable获取下标直接用模运算符%。
- 存储方式:Hashtable中出现冲突后,只有用链表方式存储。
2.3 HashMap线程不安全,那么有哪些Map可以实现线程安全
- Hashtable: 直接在方法上加synchronized关键字,锁住整个哈希桶
- ConcurrentHashMap:使用分段锁,相比于Hashtable性能更高
- Collectons.synchronizedMap:是使用Collections集合工具的内部类,通过传入Map封装一个SynchronizedMap对象,内部定义一个对象锁,方法通过对象锁实现。
参考博文:
HashMap 底层实现原理是什么?JDK8 做了哪些优化?
Java集合框架1-- HashMap的更多相关文章
- Java集合框架:HashMap
转载: Java集合框架:HashMap Java集合框架概述 Java集合框架无论是在工作.学习.面试中都会经常涉及到,相信各位也并不陌生,其强大也不用多说,博主最近翻阅java集合框架的源码以 ...
- Java集合框架之HashMap浅析
Java集合框架之HashMap浅析 一.HashMap综述: 1.1.HashMap概述 位于java.util包下的HashMap是Java集合框架的重要成员,它在jdk1.8中定义如下: pub ...
- (转)Java集合框架:HashMap
来源:朱小厮 链接:http://blog.csdn.net/u013256816/article/details/50912762 Java集合框架概述 Java集合框架无论是在工作.学习.面试中都 ...
- Java 集合框架:HashMap
原文出处:Java8 系列之重新认识 HashMap 摘要 HashMap 是 Java 程序员使用频率最高的用于映射 (键值对) 处理的数据类型.随着 JDK(Java Developmet Kit ...
- java集合框架之HashMap
参考http://how2j.cn/k/collection/collection-hashmap/365.html#nowhere HashMap的键值对 HashMap储存数据的方式是-- 键值对 ...
- java集合框架之HashMap和Hashtable的区别
参考http://how2j.cn/k/collection/collection-hashmap-vs-hashtable/692.html#nowhere HashMap和Hashtable的区别 ...
- Java集合框架(四)-HashMap
1.HashMap特点 存放的元素都是键值对(key-value),key是唯一的,value是可以重复的 存放的元素也不保证添加的顺序,即是无序的 存放的元素的键可以为null,但是只能有一个key ...
- 深入理解java集合框架之---------HashMap集合
深入理解HaspMap死循环问题 由于在公司项目中偶尔会遇到HashMap死循环造成CPU100%,重启后问题消失,隔一段时间又会反复出现.今天在这里来仔细剖析下多线程情况下HashMap所带来的问题 ...
- Java集合框架系列大纲
###Java集合框架之简述 Java集合框架之Collection Java集合框架之Iterator Java集合框架之HashSet Java集合框架之TreeSet Java集合框架之Link ...
- java集合框架之java HashMap代码解析
java集合框架之java HashMap代码解析 文章Java集合框架综述后,具体集合类的代码,首先以既熟悉又陌生的HashMap开始. 源自http://www.codeceo.com/arti ...
随机推荐
- JavaScript图形实例:图形放大镜效果
1. 基本四瓣花型图案 根据四瓣花卉线的参数方程: t= r*(1+sin(12*θ)/5)*(0.5+sin(4*θ)/2); x=t*cos(θ)); y=t*sin(θ)); 编写如下的HTML ...
- MySQL高级用法
-- 关联查询-- select * from Goods_BomItems s,Goods_Bom t where t.GoodsBomId = s.GoodsBomId and t.GoodsBo ...
- 如何在使用spring boot的时候,去掉使用tomcat
在spring boot中引入spring-boot-starter-web依赖的时候,不想使用spring boot提供的tomcat怎么办呢? 如下配置则可以解决问题: <dependenc ...
- 《JavaScript高级程序设计》(第二版)
这本书的作者是 Nicholas C.Zakas ,博客地址是 http://www.nczonline.net/ ,大家可以去多关注,雅虎的前端工程师,是YUI的代码贡献者,可想而知这本书得含金量, ...
- Spring系列.Bean简介
Bean属性配置 Spring在读取配置文件中bean的metadata后会构造一个个BeanDefination对象.后面Spring会根据这些BeanDefinition创建对象.在配置一个bea ...
- Swoole 中 TCP、UDP 和长连接、短连接
TCP 服务 swoole 文档 - TCP 服务 tcp 服务端 <?php // 1. 创建 swoole 默认创建的是一个同步的阻塞tcp服务 $host = "0.0.0.0& ...
- CentOS7开机报错piix4_smbus ****host smbus controller not enabled
vi /etc/modprobe.d/blacklist.conf 输入:blacklist i2c_piix4 保存退出::wq 重启:reboot (完)
- 关键字 package 和 import
1. package的使用 1.1 使用说明: * 1.为了更好的实现项目中类的管理,提供包的概念 * 2.使用package声明类或接口所属的包,声明在源文件的首行 * 3.包,属于标识符,遵循标识 ...
- BZOJ 1131 [POI2008] STA-Station 题解
题目 The first stage of train system reform (that has been described in the problem Railways of the th ...
- 合并两个有序链表(剑指offer-16)
题目描述输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则. 解答方法1:递归 /* public class ListNode { int val; List ...