java虚拟机入门(五)- 常见垃圾回收器及jvm实现
上节讲完了垃圾回收的基础,包括java的垃圾是什么,如何寻找以及常用的垃圾回收算法,那么那么多的理论知识讲完了,具体是什么样的东西在做着回收垃圾的事情呢?我们接下来就好好聊聊jvm中常用的垃圾回收器。
一、常用的垃圾回收器
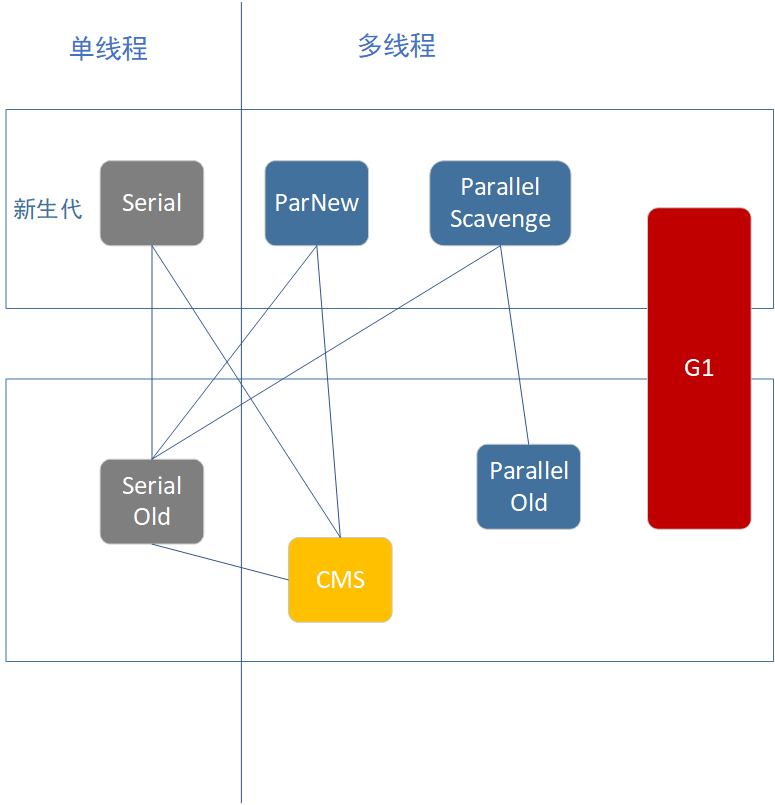
这是我花了10几分钟画的一张图,灰色表示已经被淘汰,蓝色表示依然健壮,黄色表示冲劲十足,毕竟是第一个吃螃蟹的,红色表示十分火热,其实应该还有一个亮红色表示ZGC。俩俩之间的连线表示两者之间的关系,Serial可以和Serial Old 或者CMS组合,ParNew可以和SerialSerial Old 或者CMS组合,以此类推。老年代之间按道理不应该有联系,但是Serial Old 和 CMS却相连,原因我们待会分析完了再看。
1.Serial/Serial Old
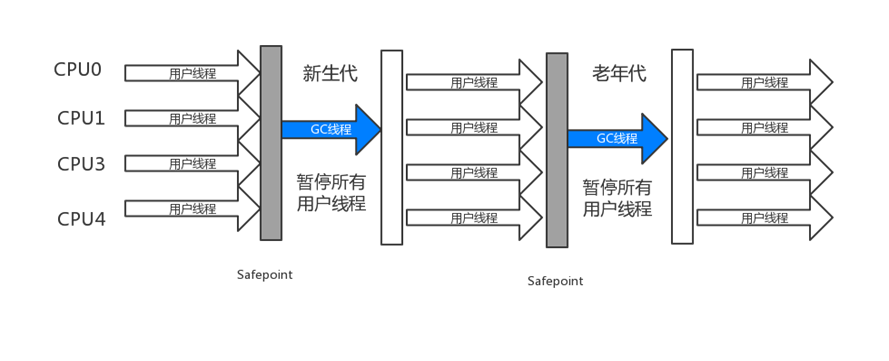
jvm最早时代的垃圾回收器套装,他的回收思路也很简单,如下图,用户线程跑,1.对象持续往新生代塞,2.新生代满,3.暂停用户线程,4.垃圾回收,5.恢复用户线程,老年代同理,这种方式在当年单核cpu打天下我觉得不仅仅是技术的不够成熟,即便相比现有的垃圾回收器,依然是最合适的。但是对于现在多核,大内存来说,已经很鸡肋了。
优点:由于单线程没有线程上下文切换,简单高效,在单核cpu下效率高
缺点:随时会发生STW(stop the world),影响用户体验,而且同样是由于单线程,多核情况下回收效率没有其他多线程垃圾回收器高,导致用户线程暂停时间长,影响使用感受。
STW(stop the world):刚才说到了就来解释一下,防止有同学看不懂,看英文全称,翻译过来就是停止世界,对于程序来说,就是将所有线程全部暂停,这样会导致暂停时间用户请求无法得到发聩,严重影响用户体验。
2.Parallel Scavenge (ParallerGC )/Parallel Old
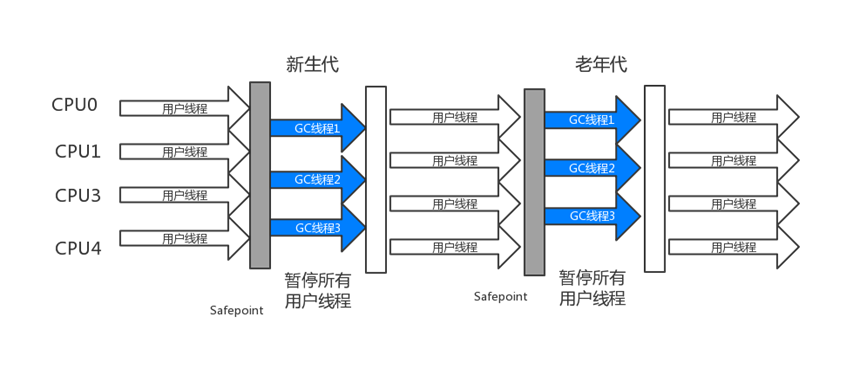
从jdk1.3开始,jvm使用了多线程的垃圾回收机制以提高回收效率,与Serial/Serial Old 垃圾回收器相比,最大的区别便是在垃圾回收时使用了多线程处理,是一款关注吞吐量的垃圾回收器(吞吐量= 程序运行时间 / (程序运行时间+垃圾回收时间) ),更加适合纯后台运算任务。
优点 : 作为多线程,关注吞吐量的一款垃圾回收器,相比其他单线程或者更加关注于用户体验减少STW而言,效率最高。老年代使用标记整理算法,不会产生浮动垃圾
缺点:随时会发生STW(stop the world),影响用户体验
3.ParNew 和 CMS(Concurrent Mark Sweep)
ParNew和serial垃圾回收器一样,都是做新生代的垃圾回收,而且在处理逻辑上基本也是一样的,唯一的区别就是ParNew是多线程多CPU的,所以垃圾回收的效率要比serial要高,两者都可以搭配CMS使用(不过基本还是用ParNew搭配),
CMS是第一款并发垃圾回收器(即在垃圾回收的同时用户线程也在跑),虽然逐渐被G1所淘汰,但其并发回收的思想,还是值得学习的:
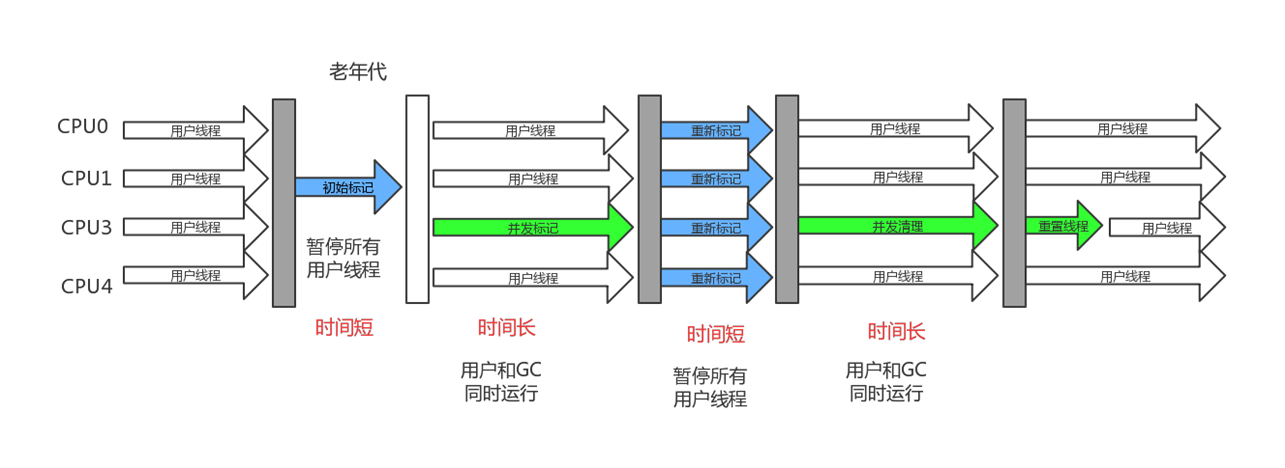
CMS收集器是基于 标记-清除 算法实现的,整个过程主要分为4步:
初始标记:暂停用户线程,标记GCRoot直接关联的对象,此步骤时间短暂,速度很快
并发标记:这一步用户线程和GC线程同时运行,标记所有根可达对象,这一步耗时较长,所以使用并发标记,不影响用户使用。
重新标记:修正刚才并发标记时,用户线程产生的额外垃圾。
并发清除:这一步也是和用户线程同时运行,清除刚才标记的垃圾。
上面四步除了初始标记和重新标记,都不会影响用户的正常使用,而且这两步标记时间都很短暂,所以整体上来说对用户的使用影响很小。
优点:STW时间很短,用户体验良好。
缺点:1.由于垃圾回收器会和用户线程一起使用,所以在垃圾回收的同时,资源会被占用,导致用户量很大时,会导致资源不足。
2.由于CMS在最后回收的同时和用户线程并发运行,在这期间产生的垃圾无法得到回收,会产生浮动垃圾,当内存无法存下浮动垃圾时,jvm会临时使用Serial Old代替,而单线程的Serial Old回收效率很低,所以发生这种情况时,系统会很卡,应该考虑是否需要调整参数或者换垃圾回收器了。
3. 由于使用标记清除,无法得到规整的内存空间,会产生空间碎片,当有大对象无法存放时,需要进行内存碎片整理,又得进行垃圾回收,而CMS这样还是无法解决问题,因此CMS提供了参数-XX:+UseCMSCompactAtFullCollection,如果无法分配,则使用Serial Old代替,同样也会出现上述卡顿的问题。
问题点:为啥CMS不用标记-整理
因为标记整理算法会涉及到对象的移动,对象移动时,对象的引用需要重新计算,这个时候是没有办法和用户线程同时进行工作的(毕竟很有可能用户线程运行的时候没准就找不到对象了),这个必须要暂停业务线程来处理,这会使得STW的时间更长,而CMS设计初衷就是要减少STW的时间。
4.Garbage First(G1)
我在之前的文章中也提到过现在的jvm设计理念更多的是用空间换时间,提升系统的响应能力,提升用户体验,G1的设计思想就是将提升用户体验放在第一位,解决STW过长的问题,而且更加变态的是,G1可以预测STW的时间,将STW控制在一个可接受范围内。为了做到这一点,它打破堆内存新生代老年代的物理分割,将内存重新分割成,化整为零,我们先看一下它的变化:
前面介绍的垃圾回收器内存分区都是这样的:

而G1的内存分区是这样的:

可以看到G1分割成了很多相同大小的内存块(Region),这些内存卡有时候可以是Eden区,有时候也可以是Survior区,有时候可以是老年代Old区,还单独划分了一块Humongous区域,用来存放大对象(G1将超过一块Region一半以上的对象称为大对象,一块区域存储不下的超级大对象使用连续的Humongous区域存储)。
G1的垃圾回收过程和CMS比较相似,思想上基本是一致的:
初始标记:标记一下GCRoot直接关联的对象(STW)
并发标记: 和用户线程一起,标记出所有GCRoot关联到的对象,这个时候会有一些并发标记时用户线程产生的垃圾无法回收。
重新标记:为了标记前一步并发标记产生的漏标对象,时间很短 (STW)
筛选回收:更新统计数据,对各个Region区域的回收价值和回收成本进行排序(咋排的还没研究过),然后根据配置的期望停顿时间制定回收计划,将要回收的区域的存活对象移到空Region中,清除掉计划回收区域所有对象,将存活对象引用指向新地址。虽然不能保证每次回收都在配置时间内,但是大部分都是可以的。标记整理涉及到对象移动,所以必须要STW。
这里其实我一开始觉得CMS的算法其实挺好的,但是会产生浮动垃圾和内存碎片,G1无法解决STW的问题,但是却使用可控时间的算法,控制STW在用户可接受范围内,也算是一种曲线救国的方式吧。
总结:
这篇主要介绍了我们常见的垃圾回收器,从最古老的单线程,到多线程,到并发回收的垃圾回收器,可以看到变化的趋势,还是多线程,大内存,加速垃圾回收效率,减少STW时间,随着计算机的发展,我觉得后面肯定会在多核大内存的基础上做文章,最终发展为用户线程跑的同时,垃圾回收器同时执行回收,完全不影响程序运行,通过类似三色标记的方式,做到实时标记,实时回收。不过以上仅为个人猜想,期待着java的发展吧。
java虚拟机入门(五)- 常见垃圾回收器及jvm实现的更多相关文章
- Java虚拟机解析篇之---垃圾回收器
上一篇说了虚拟机的内存模型,在说到堆内存的时候我们提到了,堆内存是Java内存中区域最大的一部分,而且垃圾回收器主要就是回收这部分的内容.那么这篇就来介绍一下垃圾回收器的原理以及回收的算法. Java ...
- 深入理解JAVA虚拟机阅读笔记3——垃圾回收器
一.垃圾收集器总览 新生代:Serial. ParNew. Parallel Scavenge 老年代:CMS.Serial Old. Parallel Old 最新的:G1 并行和并发的区别: 并行 ...
- java虚拟机入门(四)-垃圾回收的故事
谈到垃圾回收器,java程序员骄傲了起来,c语言你是够快,但是你有管家帮你打扫吗,还不是得靠自己的一双手,有钱就是任性.既然如此令java程序员骄傲的垃圾回收器,怎能让人不想去一探究竟呢! 垃圾回收器 ...
- Java虚拟机内存模型及垃圾回收监控调优
Java虚拟机内存模型及垃圾回收监控调优 如果你想理解Java垃圾回收如果工作,那么理解JVM的内存模型就显的非常重要.今天我们就来看看JVM内存的各不同部分及如果监控和实现垃圾回收调优. JVM内存 ...
- 深入理解JVM(五)——垃圾回收器
轻松学习JVM(五)——垃圾回收器 上一篇我们介绍了常见的垃圾回收算法,不同的算法各有各的优缺点,在JVM中并不是单纯的使用某一种算法进行垃圾回收,而是将不同的垃圾回收算法包装在不同的垃圾回收器当中, ...
- JVM(五)垃圾回收器的前世今生
全文共 2195 个字,读完大约需要 8 分钟. 如果垃圾回收的算法属于内存回收的方法论的话,那本文讨论的垃圾回收器就属于内存回收的具体实现. 因为不同的厂商(IBM.Oracle),实现的垃圾回收器 ...
- JVM 专题二十一:垃圾回收(五)垃圾回收器 (二)
3. 回收器 3.1 Serial回收器:串行回收 3.1.1 概述 Serial收集器是最基本.历史最悠久的垃圾收集器了.JDK1.3之前回收新生代唯一的选择. Serial收集器作为Hotspot ...
- java虚拟机入门(一)-jvm基础
转行学java之前,总是听着大佬们说着java像个渣男一样可以跨平台,一次编译到处运行,瞬间,我就坚定了学java的信念,哎呀妈呀,得劲.真的学java之后,好像渣男也不是那么好学的,尤其这货的必杀技 ...
- 探秘Java虚拟机——内存管理与垃圾回收
本文主要是基于Sun JDK 1.6 Garbage Collector(作者:毕玄)的整理与总结,原文请读者在网上搜索. 1.Java虚拟机运行时的数据区 2.常用的内存区域调节参数 -Xms:初始 ...
随机推荐
- UWP ListView添加分割线
先看效果: 我并没有找到有设置ListView分割线的属性 下面是一个比较简单的实现,如果有同学有更好的实现,欢迎留言,让我们共同进步.我的叙述不一定准确 实现的方法就是在DataTemplate里包 ...
- k8s ansible部署部署文档
一:基础系统准备 ubuntu 1804----> root密码:123456 主要操作: 1.更改网卡名称为eth0: # vim /etc/default/grub GRUB_CMDLI ...
- python3全局函数解析
python的全局函数: import builtins dir(builtins) [ 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'bytearray ...
- Django中关于“CSRF verification failed. Request aborted”的问题
遇到该问题的情境 在Django中采用Ajax提交表单,涉及到跨域问题. 解决措施 在html页面中的表单内添加如下代码: {% csrf_token %} 在视图函数所在的py文件中添加如下代码: ...
- Ext CheckBoxGroup使用
一.效果图展示 我这里主要是为了实现选择周期时间.如周一.周二.周三等 二.界面界面代码 下面就是我实现的代码,包含了界面.数据处理.回填数据等.可能架构的方式,您的代码和我的代码有差异,但是大体就是 ...
- 聊聊ERP的VIP卡充值的那些事
我们相信许多客户朋友,不管使用什么品牌的ERP系统,可能都有经历过各种各样的操作痛点,以及在某个阶段之前的功能无法满足现有的操作需求.今天我们就聊聊VIP卡充值操作遇到的一些问题以及相关解决方案,最大 ...
- container_of 宏
宏的作用 该宏的作用就是根据结构体中一个成员变量的地址求结构体首地址 如何做到 如果要想根据结构体成员的地址求结构体的首地址,我们需要分三步: 第一步:明确成员变量的地址: 第二步:计算成员变量在该结 ...
- C语言基础二维数组
(1)二位数组的定义int array[n][m],行下标的取值范围是0~n-1,列下标的取值范围是0~m-1,二维数组最大下标元素是array[n-1][m-1]:如定义一个3行4列的数组 int ...
- Nexus3.X在linux系统搭建maven私服
准备工作: 1.linux服务器上需安装jdk(非yum下来的open_jdk!!!,版本1.8以上) 2.linux服务器上需安装maven(如不会,请点击链接,maven版本自己喜欢就好) 准备工 ...
- AndroidStuidio安装
前言 端午小长假,安卓入门走起 正文 下载AndroidStudio 这里给出google的官网 https://developer.android.com/studio 注意,因404原因,如果你无 ...