Pulsar 联合 TiDB 推出大数据场景数据应用分析解决方案
方案概述
大数据时代,各类应用对消息解决方案的要求不仅仅是数据的流动,而是要在持续增长的服务和应用中传输海量数据,进行智能的处理和分析,帮助业务做出更加精准的决策。
Pulsar 与 TiDB 联合解决方案提供实时、高吞吐、稳定的数据输出,满足用户在大数据场景中对各类数据的应用与分析需求,广泛适用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等场景。
Apache Pulsar 简介与优势
Apache Pulsar(以下简称:Pulsar)是云原生的分布式消息流系统,采用计算和存储分层的架构和以 Segment 为中心的分片存储,具有更好的性能、可扩展性和灵活性,是一款可以无限扩展的分布式消息队列。目前,StreamNative 公司提供基于 Pulsar 平台的下一代流数据整体解决方案。
Pulsar 起初作为消息整合平台在 Yahoo 内部开发和部署,为 Yahoo Finance、Yahoo Mail 和 Flickr 等雅虎内部关键应用连接数据。目前,Pulsar 在雅虎全球的 10 多个数据中心提供服务,具备全网格复制能力,支持 140 万个主题,处理超过 1000 亿条消息,整体消息的发布延迟小于 5 毫秒。2016 年 Yahoo 把 Pulsar 开源并捐给 Apache 软件基金会(ASF),2018 年 Pulsar 毕业成为 Apache 软件基金会的顶级项目。
与大多数消息传递系统的单片架构不同,Pulsar 采用分层分片式的架构,服务层和存储层都能够独立扩展,以提供更好的性能、可扩展性和灵活性,这种设计对容器非常友好,使得 Pulsar 成为流原生平台的理想选择。
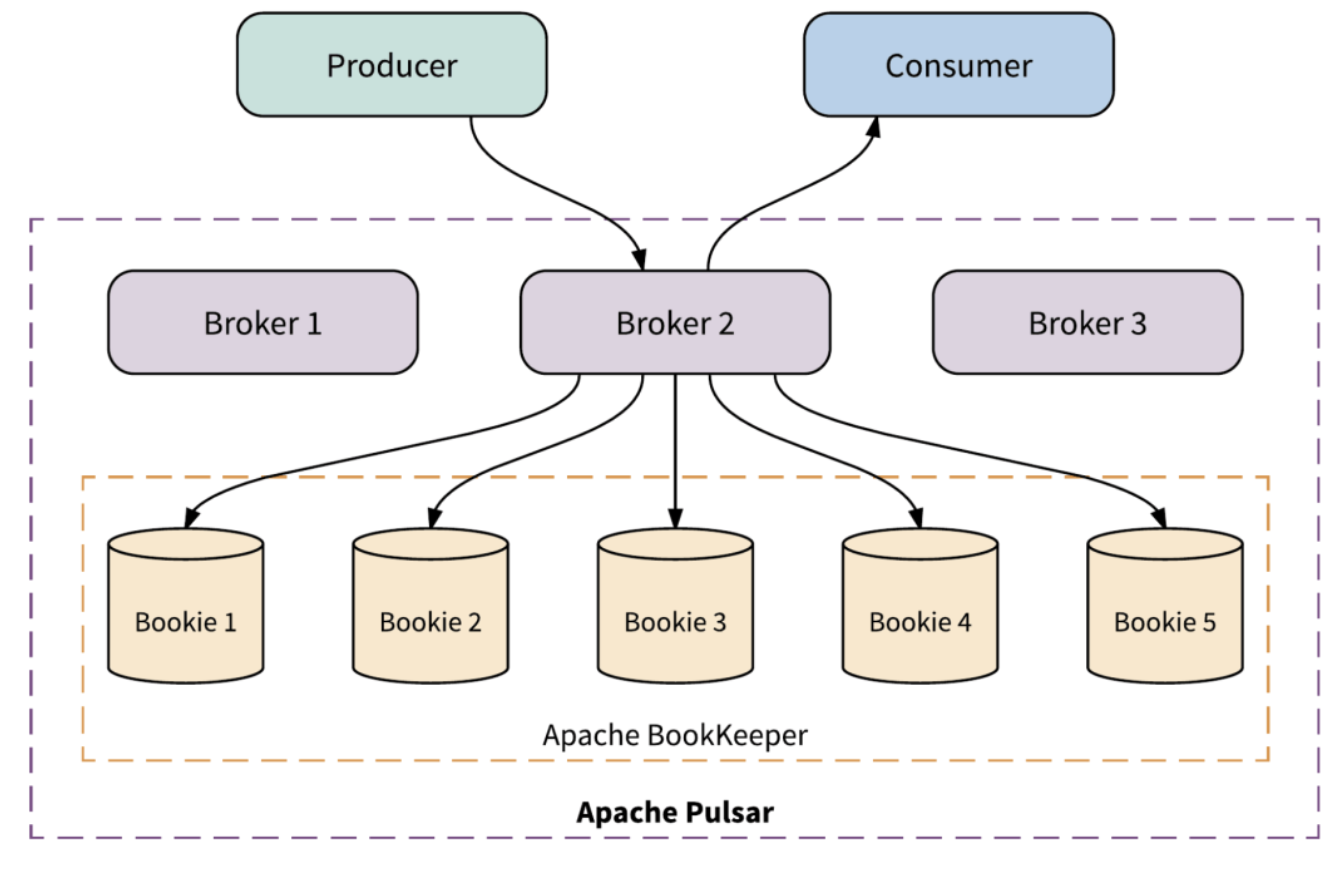
(上图:Apache Pulsar 系统架构)
Pulsar 的企业特性包括消息的持久化存储、多租户、多机房互联互备、加密和安全性等。Pulsar 提供和 Kafka 兼容的 API,以及 Kafka-On-Pulsar(KoP) 组件来兼容 Kafka 的应用程序。KoP 在 Pulsar Broker 中解析 Kafka 协议,用户不用改动客户端的任何 Kafka 代码就能直接使用 Pulsar。
TiDB 与 TiCDC 简介
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。在 4.0 之前,TiDB 提供 TiDB Binlog 实现向下游平台的近实时复制,在 TiDB 4.0 中,引入 TiCDC 作为 TiDB 变更数据的捕获框架。
TiCDC(TiDB Change Data Capture)是用来识别、捕捉和输出 TiDB/TiKV 集群上数据变更的工具系统。它既可以作为 TiDB 增量数据同步的工具,将 TiDB 集群的增量数据同步至下游数据库,也提供开放数据协议,支持把数据发布到第三方系统。TiCDC 是 TiDB Binlog 的升级方案 ,提供低延迟、高可用的数据订阅和同步服务,支持超大规模集群的水平扩展。
在 TiDB 生态链上,TiCDC 作为 TiDB 的数据出口有着非常重要的地位,其作用包括:构建 TiDB 主从和灾备系统,链接 TiDB 和其它异构数据库,通过开放数据协议(Open Protocol )与第三方数据生态系统进行对接。
TiCDC Open Protocol 是一种行级别的数据变更通知协议,为监控、缓存、全文索引、分析引擎、异构数据库的主从复制等提供数据源。TiCDC 遵循开放数据协议,向 MQ (Message Queue) 等第三方数据媒介复制 TiDB 的数据变更。
Pulsar 与 TiDB 联合解决方案
在 TiDB v4.0.4 版本中,TiCDC 开放数据协议(Open Protocol )可以与 Pulsar 实现无缝对接,提供实时、高吞吐、稳定的数据输出,满足用户在大数据场景中对各类数据的应用与分析需求,广泛适用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等场景。
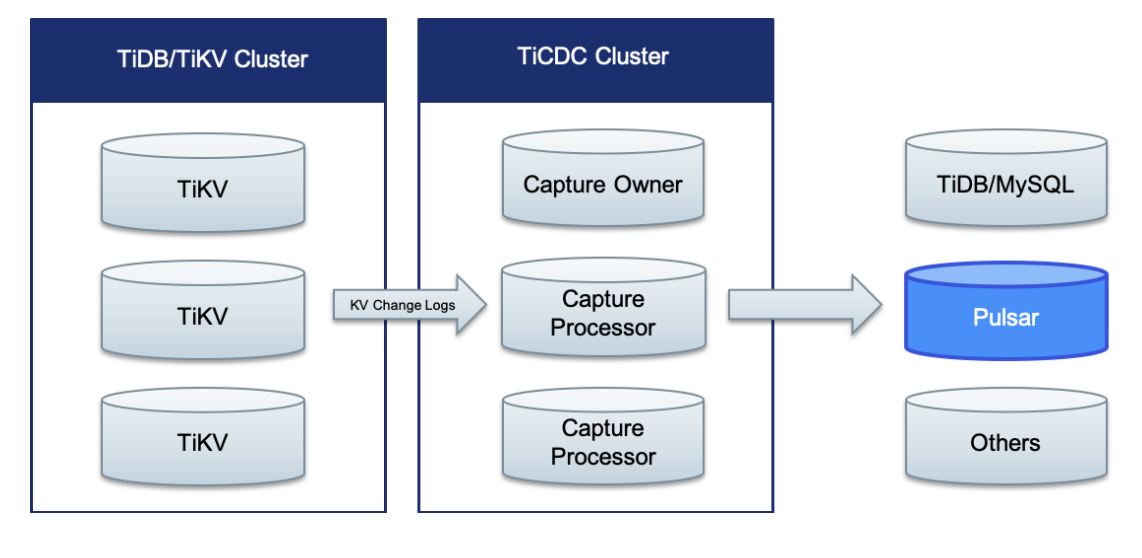
(上图:Pulsar 与 TiDB 联合解决方案 架构图)
借助 Pulsar 所具有的 GEO-Replication 功能,Pulsar 与 TiDB 联合解决方案可以为 TiCDC 的消费者带来地理位置无关的变更事件订阅能力。同时,Pulsar 集群的快速节点扩容、故障的快速恢复能力可以为 TiCDC 事件的消费方提供更优的数据实时性保障。
需求探索
伴鱼少儿英语
伴鱼少儿英语是目前飞速成长的互联网在线英语教育品牌之一,致力于打造更创新、更酷、让学英语更有效的新一代互联网产品。
伴鱼少儿英语原先采用的 Kafka 集群会遇到 Consumer Rebalance 问题,在剔除掉无法消费或者过慢的消费者的时候,会对其他消费者造成因消息过慢触发心跳超时等问题,Pulsar 在运维层面更方便和安全一些。
Pulsar 是原生支持跨数据中心的流数据同步方案,可以提供跨地域的复制功能,满足国内和海外数据中心机房双活的需求。此外,Pulsar 具备延迟队列的功能,随着大量 Topic 的创建,依然可以提供出色的性能和延迟保障,消息分散的落盘策略不会造成 IO 对磁盘的竞争。
基于上述原因,伴鱼少儿英语采用了 TiDB 与 Pulsar 联合解决方案以满足核心业务的需求。
石基信息
石基信息是一家以提供酒店业信息系统整体解决方案为主要业务的高科技公司,主要从事酒店信息管理系统软件的开发与销售、系统集成、技术支持与服务业务。
在特定业务场景下,例如汇总全球所有酒店餐饮集团下单店的收入中心,以及每个收入中心的不同消费类别实时的明细数据,则需要创建几十上百万的 Topic,Pulsar 可以支持百万级别 Topic 数量的扩展,同时还能一直保持良好的性能。
此外,原先的 Kafka 集群在节点扩展的时候,会触发 Consumer Rebalance,造成消费者处理时间过长或者心跳超时等问题,给业务带来一定的影响。石基信息规划采用 Pulsar + TiDB + Flink 方案,构建面向未来的实时数仓解决方案,在满足应用层对分布式关系型数据库需求的同时,提升实时的数据分析和服务效率。
最佳实践
知乎
知乎是中文互联网综合性内容平台,以“让每个人高效获得可信赖的解答”为品牌使命和北极星。知乎在首页个性化内容推荐、已读服务等场景中使用 TiDB 作为核心数据库,通过 TiCDC Open Protocol 输出日志到 Kafka,进行海量的消息处理。随着业务量级的增长,在使用的过程中遇到了诸多因 Kafka 架构和历史版本实现上的限制而引发的问题。
单 Partition 数据量巨大的 Kafka 集群不论是扩容还是故障恢复都需要很长的时间,业务无法容忍长时间的不可用,所以只能选择牺牲数据、重建集群的方式来加快恢复速度。Kafka Topic 过重的资源消耗导致在单一集群上支撑数千乃至数万的 Topic 相对困难。
早期版本 Kafka 不论是读取还是写入都需要发生在 Partition 当前活跃的 Leader 上,读写流量都很高的集群会对 Broker 产生非常大的压力。Kafka 的一些问题在新版本中得到了解决,但是因为协议版本差别太大,无法直接通过升级服务端的方式进行滚动升级。
鉴于以上遇到的问题,考虑到 Pulsar 对原生跨地域复制(GEO-Replication)的支持同知乎未来基础设施云原生化的方向更加契合,知乎开始在一些业务中使用 Pulsar 替换 Kafka 。
知乎对 TiCDC 的核心模块进行了一系列开发工作(https://github.com/pingcap/ticdc/pull/751 ),把 TiCDC Sink 与 Pulsar 进行对接,实现 TiCDC 的数据同步到 Pulsar。Pulsar 与 TiDB 联合解决方案已经在知乎的 CMDB 项目中得以应用,解决了现阶段在 Kafka 上遇到的问题。
Pulsar 对跨地域复制(GEO-Replication)的支持为生产者和消费者提供了地理位置透明的连接,生产者在任意数据中心生产的内容可以供任意一个数据中心的供消费者使用。分层存储(Tiered Storage)为大量历史数据的保存、审计、流量回放、低频明细历史事件分析等需求提供更低成本的实现方式。从消费模式看从数据多个副本并发读取消息的能力,极大地提升了数据读取的扩展性。此外,延迟消息分发(Delayed Message Delivery)便于实现许多特定的业务逻辑,可用于替代一些相对陈旧的历史技术方案。
目前,知乎对于 Pulsar 的应用处于早期阶段,实际上线的业务数量占比较小,从前期业务的实践来看,Pulsar 与 TiDB 联合解决方案的应用取得了理想效果。知乎将推动各项业务从 Kafka 向 Pulsar 进行全面的迁移,未来也将应用 Pulsar 到跨集群同步 TiDB 数据的场景下。
相关资源
- TiCDC 实操指南:
https://docs.pingcap.com/zh/tidb/stable/manage-ticdc - Apache Pulsar 官方文档
http://pulsar.apache.org/docs/en/standalone/ - Pulsar 与 Kafka 的对比:
About
PingCAP 成立于 2015 年,是一家开源的新型分布式数据库公司,秉承开源是基础软件的未来这一理念,PingCAP 持续扩大社区影响力,致力于前沿技术领域的创新实现。其研发的分布式关系型数据库 TiDB 项目,具备「分布式强一致性事务、在线弹性水平扩展、故障自恢复的高可用、跨数据中心多活」等核心特性,是大数据时代理想的数据库集群和云数据库解决方案。目前已经国内外近 1000 家用户将 TiDB 用于线上生产环境。
StreamNative 是一家围绕 Apache 顶级项目 Apache Pulsar 打造下一代流数据平台的开源基础软件公司,秉承开源是基础软件的未来这一理念,专注于开源生态和社区的构建,致力于前沿技术领域的创新,创始团队成员均是 Apache Pulsar 和 Apache BookKeeper 的核心 PMC 成员。
Pulsar 联合 TiDB 推出大数据场景数据应用分析解决方案的更多相关文章
- 单表60亿记录等大数据场景的MySQL优化和运维之道
此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美图公司数据库高级DBA,负责美图后端数据 ...
- 【转】单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美图公司数据库高级DBA,负责美图后端数据 ...
- [转载] 单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
原文: http://mp.weixin.qq.com/s?__biz=MzAwMDU1MTE1OQ==&mid=209406532&idx=1&sn=2e9b0cc02bdd ...
- 单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
015-08-09 杨尚刚 高可用架构 此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美 ...
- Hadoop! | 大数据百科 | 数据观 | 中国大数据产业观察_大数据门户
你正在使用过时的浏览器,Amaze UI 暂不支持. 请 升级浏览器 以获得更好的体验! 深度好文丨读完此文,就知道Hadoop了! 来源:BiThink 时间:2016-04-12 15:1 ...
- Druid:一个用于大数据实时处理的开源分布式系统——大数据实时查询和分析的高容错、高性能开源分布式系统
转自:http://www.36dsj.com/archives/28590 Druid 是一个用于大数据实时查询和分析的高容错.高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分 ...
- [转帖]etcd 在超大规模数据场景下的性能优化
etcd 在超大规模数据场景下的性能优化 阿里系统软件技术 2019-05-27 09:13:17 本文共5419个字,预计阅读需要14分钟. http://www.itpub.net/2019/ ...
- etcd 在超大规模数据场景下的性能优化
作者 | 阿里云智能事业部高级开发工程师 陈星宇(宇慕) 概述 etcd是一个开源的分布式的kv存储系统, 最近刚被cncf列为沙箱孵化项目.etcd的应用场景很广,很多地方都用到了它,例如kuber ...
- [Elasticsearch] ES聚合场景下部分结果数据未返回问题分析
背景 在对ES某个筛选字段聚合查询,类似groupBy操作后,发现该字段新增的数据,聚合结果没有展示出来,但是用户在全文检索新增的筛选数据后,又可以查询出来, 针对该问题进行了相关排查. 排查思路 首 ...
随机推荐
- setOff与scrollTop区别
1.offsetTop : 当前对象到其上级层顶部的距离. 不能对其进行赋值.设置对象到页面顶部的距离请用style.top属性. 2.offsetLeft : 当前对象到其上级层左边的 ...
- 从jdbc到spring-boot-starter-jdbc
从jdbc到spring-boot-starter-jdbc jdbc 是什么 JDBC是一种用于执行SQL语句的API,可以为多种关系数据库提供统一访问,它是由一组用Java语言编写的类和接口.是J ...
- idea只导入部分依赖
首先为啥会导入部分依赖的呢? 可能是网络问题下载不下来,可以排除这一个,因为刚换的merrio阿里的源,而且之前都能下载 也可能是maven的设置问题,上网上搜了一些设置之后,还是不管用 然后怀疑是不 ...
- 冷饭新炒:理解Snowflake算法的实现原理
前提 Snowflake(雪花)是Twitter开源的高性能ID生成算法(服务). 上图是Snowflake的Github仓库,master分支中的REAEMDE文件中提示:初始版本于2010年发布, ...
- Windows10上安装Linux子系统(WSL2,Ubuntu),配合Windows Terminal使用
Linux 的 Windows 子系统可让开发人员按原样运行 GNU/Linux 环境 - 包括大多数命令行工具.实用工具和应用程序 - 且不会产生传统虚拟机或双启动设置开销. WSL 说白了安装Li ...
- 2020-04-08:谈一下IOC底层原理
Ioc的底层原理 (1)xml配置文件 (2)dom4j解析xml (3)工厂设计模式 (4)反射
- C#设计模式之19-观察者模式
观察者模式(Observer Pattern) 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/423 访问. 观察者模式 ...
- ubuntu升级已安装git版本
# To get the very latest version of git, you need to add the PPA (Personal Package Archive) from the ...
- manjaro与python开发环境配置
1.manjaro配置 1.1.启动项 sudo update-grub 注:Manjaro(archLinux)系统时间快8小时--> sudo timedatectl set-local-r ...
- 使用BurpSuite、Hydra和medusa爆破相关的服务
一.基本定义 1.爆破=爆破工具(BP/hydra)+字典(用户字典/密码字典). 字典:就是一些用户名或者口令(弱口令/使用社工软件的生成)的集合. 2.BurpSuite 渗透测试神器,使用Jav ...