技术揭秘:华为云DLI背后的核心计算引擎
摘要:介绍隐藏在华为云数据湖探索服务背后的核心计算引擎Spark,玩转DLI,,轻松完成大数据的分析处理。
本文主要给大家介绍隐藏在华为云数据湖探索服务(后文简称DLI)背后的核心计算引擎——Spark。
DLI团队在Spark之上做了大量的性能优化与服务化改造,但其本质还是脱离不了Spark的核心概念与思想,因此笔者从以下几点阐述,让读者快速对Spark有一个直观的认识,玩转DLI。
Spark的诞生及优势
2009年,Spark诞生于伯克利大学AMPLab,诞生之初是属于伯克利大学的研究性项目。于2010年开源,2013年成为Apache开源项目,经过几年的发展逐渐取代了Hadoop,成为了开源社区炙手可热的大数据处理平台。
Spark官方的解释:“Spark是用于大规模数据处理的统一分析引擎”,把关键词拆开来看,“大规模数据”指的是Spark的使用场景是大数据场景;“统一”主要体现在将大数据的编程模型进行了归一化,同时满足多种类型的大数据处理场景(批处理、流处理、机器学习等),降低学习和维护不同大数据引擎的成本;“分析引擎”表明Spark聚焦在计算分析,对标的是Hadoop中的MapReduce,对其模型进行优化与扩展。
Spark为了解决MapReduce模型的优化和扩展,那么我们先探讨一下MapReduce存在的问题,然后分析Spark在MapReduce之上的改进。
(1)MapReduce中间结果落盘,计算效率低下
随着业务数据不断增多,业务逻辑不断多样化,很多ETL和数据预处理的工作需要多个MapReduce作业才能完成,但是MapReduce作业之间的数据交换需要通过写入外部存储才能完成,这样会导致频繁地磁盘读写,降低作业执行效率。
Spark设计之初,就想要解决频繁落盘问题。Spark只在需要交换数据的Shuffle阶段(Shuffle中文翻译为“洗牌”,需要Shuffle的关键性原因是某种具有共同特征的数据需要最终汇聚到一个计算节点上进行计算)才会写磁盘,其它阶段,数据都是按流式的方式进行并行处理。
(2)编程模型单一,场景表达能力有限
MapReduce模型只有Map和Reduce两个算子,计算场景的表达能力有限,这会导致用户在编写复杂的逻辑(例如join)时,需要自己写关联的逻辑,如果逻辑写得不够高效,还会影响性能。
与MapReduce不同,Spark将所有的逻辑业务流程都抽象成是对数据集合的操作,并提供了丰富的操作算子,如:join、sortBy、groupByKey等,用户只需要像编写单机程序一样去编写分布式程序,而不用关心底层Spark是如何将对数据集合的操作转换成分布式并行计算任务,极大的简化了编程模型
Spark的核心概念:RDD
Spark中最核心的概念是RDD(Resilient Distributed Dataset)——弹性分布式数据集,顾名思义,它是一个逻辑上统一、物理上分布的数据集合,Spark通过对RDD的一系列转换操作来表达业务逻辑流程,就像数学中对一个向量的一系列函数转换。
Spark通过RDD的转换依赖关系生成对任务的调度执行的有向无环图,并通过任务调度器将任务提交到计算节点上执行,任务的划分与调度是对业务逻辑透明的,极大的简化了分布式编程模型,RDD也丰富了分布式并行计算的表达能力。
RDD上的操作分为Transformation算子和Action算子。Transformation算子用于编写数据的变换过程,是指逻辑上组成变换过程。Action算子放在程序的最后一步,用于对结果进行操作,例如:将结果汇总到Driver端(collect)、将结果输出到HDFS(saveAsTextFile)等,这一步会真正地触发执行。
常见的Transformation算子包括:map、filter、groupByKey、join等,这里面又可以分为Shuffle算子和非Shuffle算子,Shuffle算子是指处理过程需要对数据进行重新分布的算子,如:groupByKey、join、sortBy等。常见的Action算子如:count、collect、saveAsTextFile等
如下是使用Spark编程模型编写经典的WordCount程序:

该程序通过RDD的算子对文本进行拆分、统计、汇总与输出。
Spark程序中涉及到几个概念,Application、Job、Stage、Task。每一个用户写的程序对应于一个Application,每一个Action生成一个Job(默认包含一个Stage),每一个Shuffle算子生成一个新的Stage,每一个Stage中会有N个Task(N取决于数据量或用户指定值)。
Spark的架构设计
前面讲述了Spark 核心逻辑概念,那么Spark的任务是如何运行在分布式计算环境的呢?接下来我们来看看开源框架Spark的架构设计。
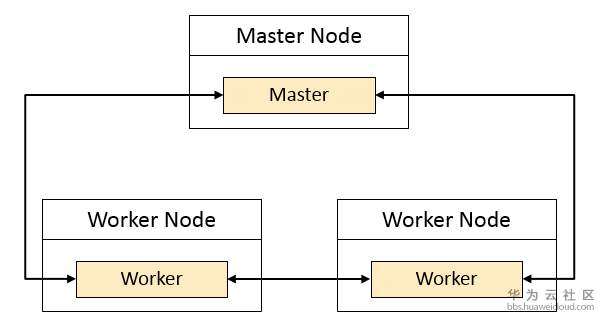
(注:涂色表示进程)
Spark是典型的主从(Master- Worker)架构,Master 节点上常驻 Master守护进程,负责管理全部的 Worker 节点。Worker 节点上常驻 Worker 守护进程,负责与 Master 节点通信并管理 Executor。
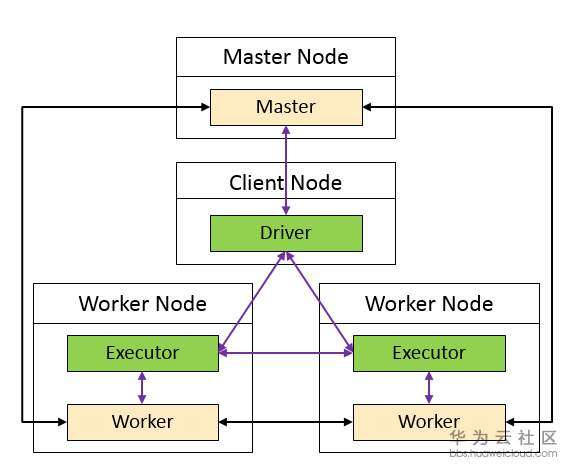
(注:橙色和绿色表示进程)
Spark程序在客户端提交时,会在Application的进程中启动一个Driver。看一下官方对Driver的解释“The process running the main() function of the application and creating the SparkContext”。
我们可以把Master和Worker看成是生产部总部老大(负责全局统一调度资源、协调生产任务)和生产部分部部长(负责分配、上报分部的资源,接收总部的命令,协调员工执行任务),把Driver和Executor看成是项目经理(负责分配任务和管理任务进度)和普通员工(负责执行任务、向项目经理汇报任务执行进度)。
项目经理D to 总部老大M:Hi,老大,我刚接了一个大项目,需要你通知下面的分部部长W安排一些员工组成联合工作小组。
总部老大M to 分部部长W:最近项目经理D接了一个大项目,你们几个部长都安排几个员工,跟项目经理D一起组成一个联合工作小组。
分部部长W to 员工E:今天把大家叫到一起,是有个大项目需要各位配合项目经理D去一起完成,稍后会成立联合工作小组,任务的分配和进度都直接汇报给项目经理D。
项目经理D to 员工E:从今天开始,我们会一起在这个联合工作小组工作一段时间,希望我们好好配合,把项目做好。好,现在开始分配任务…
员工E to 项目经理D:你分配的xxx任务已完成,请分配其它任务。
项目所有任务都完成后,项目经理D to 总部老大M:Hi,老大,项目所有的任务都已经完成了,联合工作小组可以解散了,感谢老大的支持。
以上就是Spark的基本框架,基于Apache Spark/Flink生态,DLI提供了完全托管的大数据处理分析服务。借助DLI服务,你只需要关注应用的处理逻辑,提供构建好的应用程序包,就可以轻松完成你的大规模数据处理分析任务,即开即用,按需计费。
华为云828企业上云节期间,购买数据湖探索DLI优惠更多。
技术揭秘:华为云DLI背后的核心计算引擎的更多相关文章
- 揭秘阿里云EB级大数据计算引擎MaxCompute
日前,全球权威咨询与服务机构Forrester发布了<The Forrester WaveTM: Cloud Data Warehouse, Q4 2018>报告.这是Forrester ...
- 揭秘丨7分钟看懂华为云鲲鹏Redis背后的自研技术【华为云技术分享】
2019年5月,华为云发布全球首个基于自研ARM架构的分布式缓存鲲鹏Redis,搭载华为LibOS+华为编译器+安全容器引擎三项黑科技,在保证Redis强劲高性能外,还降低客户30%的使用成本,真正实 ...
- 揭秘华为云GaussDB(for Influx):数据直方图
摘要:本文带您了解直方图在不同产品中的实现,以及GaussDB(for Influx)中直方图的使用方法. 本文分享自华为云社区<华为云GaussDB(for Influx)揭秘第九期:最佳实践 ...
- 揭秘华为云GaussDB(for Influx)最佳实践:hint查询
摘要:GaussDB(for Influx)通过提供hint功能,在单时间线的查询场景下,性能有大幅度的提升,能有效满足客户某些特定场景的查询需求. 本文分享自华为云社区<华为云GaussDB( ...
- 揭秘阿里云WAF背后神秘的AI智能防御体系
背景 应用安全领域,各类攻击长久以来都危害着互联网上的应用,在web应用安全风险中,各类注入.跨站等攻击仍然占据着较前的位置.WAF(Web应用防火墙)正是为防御和阻断这类攻击而存在,也正是这些针对W ...
- 奇点云数据中台技术汇(三)| DataSimba系列之计算引擎篇
随着移动互联网.云计算.物联网和大数据技术的广泛应用,现代社会已经迈入全新的大数据时代.数据的爆炸式增长以及价值的扩大化,将对企业未来的发展产生深远的影响,数据将成为企业的核心资产.如何处理大数据,挖 ...
- 解构华为云HE2E项目中的容器技术应用
摘要:本文从容器技术应用的角度解构了HE2E项目的代码仓库配置.镜像构建.及docker-compose的部署方式.希望通过本篇文章分享可以使更多的开发者了解容器技术和华为云. 本文分享自华为云社区& ...
- 华为云亮相QCon2020深圳站,带你体会大厂的云原生玩法与秘诀
摘要:在QCon全球软件开发大会上,华为云开发者生态总监张全文作为"云原生应用开发实践"专题出品人,携手华为云四位资深技术专家带来精彩分享. 作为当下技术领域最火热的技术趋势之一, ...
- 华为云PaaS首席科学家:Cloud Native +AI,企业数字化转型的最佳拍档
近日,在2019华为全球分析师大会期间,华为云PaaS首席科学家熊英博士在+智能,见未来(华为云&大数据)的分论坛上,从云计算行业发展谈起,深入云原生发展趋势,对华为云智能应用平台做了深度解读 ...
随机推荐
- Django学习路16_获取学生所在的班级名
在 urls.py 中先导入getgrades from django.conf.urls import url from app5 import views urlpatterns = [ url( ...
- WSGI应用程序示例
import time # WSGI允许开发者自由搭配web框架和web服务器 def app(environ,start_response): status = '200 OK' response_ ...
- pandas_时间序列和常用操作
# 时间序列和常用操作 import pandas as pd # 每隔五天--5D pd.date_range(start = '',end = '',freq = '5D') ''' Dateti ...
- PHP preg_match_all() 函数
preg_match_all 函数用于执行一个全局正则表达式匹配.高佣联盟 www.cgewang.com 语法 int preg_match_all ( string $pattern , stri ...
- CF1037H Security 线段树合并 SAM
LINK:Security 求一个严格大于T的字符串 是原字符串S[L,R]的子串. 容易想到尽可能和T相同 然后再补一个尽可能小的字符即可. 出于这种思想 可以在SAM上先跑匹配 然后枚举加哪个字符 ...
- QDC day4
图论. 强连通图 与 弱连通图 . 最短路 .dij 不支持负权.显然 值得一提的是利用斐波那契堆m+nlogn . 一张 边权都是2的整数次幂 考虑 一下直接 结构体维护这个2的整次幂数组但比大小 ...
- Canal简介
以下内容主要摘自Canal 官方wiki和网友博客:https://www.jianshu.com/p/6299048fad66 一.背景 早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨 ...
- requests入门实践02_下载斗图拉最新表情包
新版本移步:https://www.cnblogs.com/zy7y/p/13376228.html 下载斗图拉最新表情包 要爬取的目标所在网址:http://www.doutula.com/phot ...
- 一站式搞定Ubuntu共享环境配置
1. 添加linux用户 安装的开发用的虚拟机,一般不直接使用root账户,会新建一个普通用户,然后在/etc/sudoers添加上sudo的权限即可. 使用如下命令: sudo adduser -- ...
- Python使用pyexecjs代码案例解析
针对现在大部分的网站都是使用js加密,js加载的,并不能直接抓取出来,这时候就不得不适用一些三方类库来执行js语句 execjs,一个比较好用且容易上手的类库(支持py2,与py3),支持 JS ru ...