Leetcode学习笔记(6)
题目1 ID112

给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
我的解答:
最开始的版本是这样的:
- /**
- * Definition for a binary tree node.
- * struct TreeNode {
- * int val;
- * struct TreeNode *left;
- * struct TreeNode *right;
- * };
- */
- bool hasPathSum(struct TreeNode* root, int sum){
- if(root==NULL&&sum!=0){
- return false;
- }
- if(root==NULL&&sum==0){
- return true;
- }
- return hasPathSum(root->left,sum-root->val)||hasPathSum(root->right,sum-root->val);
- }
使用递归和或运算,判断根节点到叶子结点中,是否有一条路径的和为sum对sum做减法,若某一个叶子结点处sum等于0,说明存在和为sum的路径,返回true。但是对于特殊输入值如:root为空树,sum=0的时候,本应该返回false,在上面的判断中却返回true,而这种情况又跟叶子结点判true是相同的,导致了错误。当输入案例为示例时,实际上代码是递归到2的左子树根节点时,才返回的true,因为2是叶子结点,所以其左子树根节点为NULL,从而导致跟特殊输入案例相同,将代码修改为在叶子结点时进行判断即可,修改后的代码如下:
- /**
- * Definition for a binary tree node.
- * struct TreeNode {
- * int val;
- * struct TreeNode *left;
- * struct TreeNode *right;
- * };
- */
- bool hasPathSum(struct TreeNode* root, int sum){
- if(root==NULL){
- return false;
- }
- if(root->left==NULL&&root->right==NULL){
- return sum-root->val==0;
- }
- return hasPathSum(root->left,sum-root->val)||hasPathSum(root->right,sum-root->val);
- }
题目2 ID637

给定一个非空二叉树, 返回一个由每层节点平均值组成的数组.
示例 1:
输入:
3
/ \
9 20
/ \
15 7
输出: [3, 14.5, 11]
解释:
第0层的平均值是 3, 第1层是 14.5, 第2层是 11. 因此返回 [3, 14.5, 11].
注意:
节点值的范围在32位有符号整数范围内。
我的解答:
层序遍历,使用列表queue是否为空判断结束,每一层的非空节点值存在temp列表里面,当前层的值存在list1列表中,每往下一层,将temp赋给queue,当temp为空的时候,则证明没有新的为空的结点了,结束while循环。
- # Definition for a binary tree node.
- # class TreeNode:
- # def __init__(self, x):
- # self.val = x
- # self.left = None
- # self.right = None
- class Solution:
- def averageOfLevels(self, root: TreeNode) -> List[float]:
- result=[]
- if not root:
- return result
- queue=[root]
- while len(queue)!=0:
- list1=[]
- temp=[]
- for i in queue:
- list1.append(i.val)
- if i.left:
- temp.append(i.left)
- if i.right:
- temp.append(i.right)
- result.append(float(sum(list1))/len(list1))
- queue=temp
- return result
题目3 ID1305

给你 root1 和 root2 这两棵二叉搜索树。
请你返回一个列表,其中包含 两棵树 中的所有整数并按 升序 排序。.
示例 1:
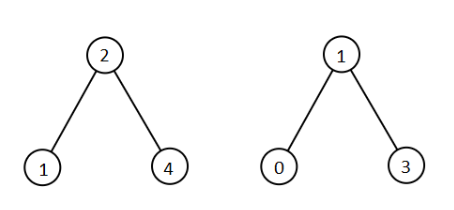
输入:root1 = [2,1,4], root2 = [1,0,3]
输出:[0,1,1,2,3,4]
示例 2:
输入:root1 = [0,-10,10], root2 = [5,1,7,0,2]
输出:[-10,0,0,1,2,5,7,10]
示例 3:
输入:root1 = [], root2 = [5,1,7,0,2]
输出:[0,1,2,5,7]
示例 4:
输入:root1 = [0,-10,10], root2 = []
输出:[-10,0,10]
示例 5:
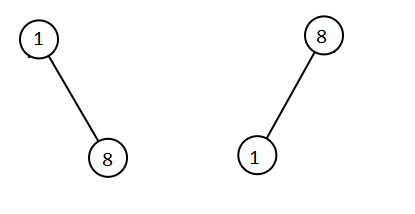
输入:root1 = [1,null,8], root2 = [8,1]
输出:[1,1,8,8]
提示:
每棵树最多有 5000 个节点。
每个节点的值在 [-10^5, 10^5] 之间。
我的解答:
我们已知二叉搜索树中序遍历之后的结果是一个升序序列,使用sortin函数对二叉树进行中序遍历,并将结果赋值给列表,两棵二叉树得到的列表都是升序序列,我们使用sort函数对其进行归并排序,返回最后的结果即两棵二叉树中所有整数的升序排列。
- # Definition for a binary tree node.
- # class TreeNode:
- # def __init__(self, x):
- # self.val = x
- # self.left = None
- # self.right = None
- class Solution:
- def sortin(self,root:TreeNode,sortlist:List):
- if not root:
- return None
- self.sortin(root.left,sortlist)
- sortlist.append(root.val)
- self.sortin(root.right,sortlist)
- def sort(self,sortlist1,sortlist2):
- sortlist=[]
- i,j=0,0
- while True:
- if i==len(sortlist1) or j==len(sortlist2):
- break
- if sortlist1[i]<sortlist2[j]:
- sortlist.append(sortlist1[i])
- i+=1
- else:
- sortlist.append(sortlist2[j])
- j+=1
- if i==len(sortlist1):
- sortlist+=sortlist2[j:]
- if j==len(sortlist2):
- sortlist+=sortlist1[i:]
- return sortlist
- def getAllElements(self, root1: TreeNode, root2: TreeNode) -> List[int]:
- if not root1 and not root2:
- return []
- sortlist1=[]
- sortlist2=[]
- self.sortin(root1,sortlist1)
- self.sortin(root2,sortlist2)
- return self.sort(sortlist1,sortlist2)
题目4 ID94

给定一个二叉树,返回它的中序 遍历。
示例:
输入: [1,null,2,3]
1
\
2
/
3
输出: [1,3,2]
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
我的解答:
递归版本:
- # Definition for a binary tree node.
- # class TreeNode:
- # def __init__(self, x):
- # self.val = x
- # self.left = None
- # self.right = None
- class Solution:
- def __init__(self):
- self.sortlist=[]
- def inorderTraversal(self, root: TreeNode) -> List[int]:
- if not root:
- return []
- self.inorderTraversal(root.left)
- self.sortlist.append(root.val)
- self.inorderTraversal(root.right)
- return self.sortlist
非递归版本:
- # Definition for a binary tree node.
- # class TreeNode:
- # def __init__(self, x):
- # self.val = x
- # self.left = None
- # self.right = None
- class Solution:
- def inorderTraversal(self, root: TreeNode) -> List[int]:
- stack,res=[],[]
- temp=root
- while stack or temp:
- if temp:
- stack.append(temp)
- temp=temp.left
- else:
- temp=stack.pop()
- res.append(temp.val)
- temp=temp.right
- return res
递归版本不再赘述,非递归版本:使用栈来辅助存储根节点,当左子树非空的时候,将左子树根节点入栈,并继续向下重复这一步骤,左子树为空的时候,按照中序遍历的顺序应该输出当前树根节点,此时的根节点在栈顶,弹出根节点并存储在res列表中,判断右子树是否为空,为空则继续弹出栈顶元素,非空则将右子树上的子树结点继续入栈。当栈为空同时结点也为空的时候,代表根节点们全部出栈完毕,同时没有结点入栈,则结束循环。
题目5 ID653

给定一个二叉搜索树和一个目标结果,如果 BST 中存在两个元素且它们的和等于给定的目标结果,则返回 true。
案例 1:
输入:
5
/ \
3 6
/ \ \
2 4 7
Target = 9
输出: True
案例 2:
输入:
5
/ \
3 6
/ \ \
2 4 7
Target = 28
输出: False
我的解答:
中序遍历二叉搜索树后,得到递增列表,使用双指针法判断是否存在两个元素的和等于给定目标值,left指向列表头,right指向列表尾,当left和right指向的值的和等于目标值时,找到这样的两个元素,返回true,当left和right指向的值的和大于目标值时,令right--,缩小两个元素的和,当left和right指向的值的和小于目标值时,令left++,扩大两个元素的和。若left>=right时,证明没有找到这样的两个元素,退出循环,返回false。
- # Definition for a binary tree node.
- # class TreeNode:
- # def __init__(self, x):
- # self.val = x
- # self.left = None
- # self.right = None
- class Solution:
- def inorder(self,root:TreeNode):
- if not root:
- return []
- self.inorder(root.left)
- self.inlist.append(root.val)
- self.inorder(root.right)
- def findTarget(self, root: TreeNode, k: int) -> bool:
- self.inlist=[]
- self.inorder(root)
- left,right=0,len(self.inlist)-1
- while left<right:
- if self.inlist[left]+self.inlist[right]==k:
- return True
- if self.inlist[left]+self.inlist[right]<k:
- left+=1
- if self.inlist[left]+self.inlist[right]>k:
- right-=1
- return False
题目6 ID69

实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
示例 1:
输入: 4
输出: 2
示例 2:
输入: 8
输出: 2
说明: 8 的平方根是 2.82842...,
由于返回类型是整数,小数部分将被舍去。
我的解答:
最简单的方式,直接循环进行判断,时间复杂度为O(n):
- int mySqrt(int x){
- long int i;
- if(x==1){
- return 1;
- }
- for(i=1;i<=x/2;i++){
- if(i*i<=x&&(i+1)*(i+1)>x){
- return i;
- }
- }
- return 0;
- }
使用二分查找法:
- int mySqrt(int x){
- long int i;
- if(x==1){
- return 1;
- }
- int low=1,high=x/2+1;
- long int mid,val;
- while(low<=high){
- mid=(low+high)/2;
- val=mid*mid;
- if(val==x){
- return mid;
- }else if(val>x){
- high=mid-1;
- }else{
- low=mid+1;
- }
- }
- if(val>x){
- return mid-1;
- }
- return mid;
- }
题目7 ID559

给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1
提示:
你可以假设 nums 中的所有元素是不重复的。
n 将在 [1, 10000]之间。
nums 的每个元素都将在 [-9999, 9999]之间。
我的解答:
关键点在于临界条件的判断,多加练习
- int search(int* nums, int numsSize, int target){
- int low=0,high=numsSize-1;
- while(low<=high){
- int mid=(low+high)/2;
- if(nums[mid]==target){
- return mid;
- }else if(nums[mid]>target){
- high=mid-1;
- }else{
- low=mid+1;
- }
- }
- return -1;
- }
题目8 ID744

给你一个排序后的字符列表 letters ,列表中只包含小写英文字母。另给出一个目标字母 target,请你寻找在这一有序列表里比目标字母大的最小字母。
在比较时,字母是依序循环出现的。举个例子:
如果目标字母 target = 'z' 并且字符列表为 letters = ['a', 'b'],则答案返回 'a'
示例:
输入:
letters = ["c", "f", "j"]
target = "a"
输出: "c"
输入:
letters = ["c", "f", "j"]
target = "c"
输出: "f"
输入:
letters = ["c", "f", "j"]
target = "d"
输出: "f"
输入:
letters = ["c", "f", "j"]
target = "g"
输出: "j"
输入:
letters = ["c", "f", "j"]
target = "j"
输出: "c"
输入:
letters = ["c", "f", "j"]
target = "k"
输出: "c"
提示:
letters长度范围在[2, 10000]区间内。
letters 仅由小写字母组成,最少包含两个不同的字母。
目标字母target 是一个小写字母。
我的解答:
经过测试当数组中不不存在这样的字符时,返回数组的第一个字母,顺序遍历代码:
- char nextGreatestLetter(char* letters, int lettersSize, char target){
- int i;
- for(i=0;i<lettersSize;i++){
- if(letters[i]>target){
- return letters[i];
- }
- }
- return letters[0];
- }
二分法查找代码,注意临界判断
- char nextGreatestLetter(char* letters, int lettersSize, char target){
- int low=0,high=lettersSize-1;
- int mid;
- while(low<high){
- mid=(low+high)/2;
- if(target>=letters[mid]){
- low=mid+1;
- }else{
- high=mid;
- }
- }
- if(letters[low]<=target){
- return letters[0];
- }else{
- return letters[low];
- }
- }
题目9 ID35

给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
你可以假设数组中无重复元素。
示例 1:
输入: [1,3,5,6], 5
输出: 2
示例 2:
输入: [1,3,5,6], 2
输出: 1
示例 3:
输入: [1,3,5,6], 7
输出: 4
示例 4:
输入: [1,3,5,6], 0
输出: 0
我的解答:
使用二分法,为了避免边界条件出错,可以用二分法的模板,特殊情况时再进行特殊考虑。
模板一:
- int searchInsert(int* nums, int numsSize, int target){
- int low=0,high=numsSize-1;
- int mid;
- while(low<=high){
- mid=(low+high)/2;
- if(nums[mid]==target){
- return mid;
- }else if(nums[mid]>target){
- high=mid-1;
- }else{
- low=mid+1;
- }
- }
- return low;
- }
模板二:
- int searchInsert(int* nums, int numsSize, int target){
- int low=0,high=numsSize;
- int mid;
- while(low<high){
- mid=(low+high)/2;
- if(nums[mid]==target){
- return mid;
- }else if(nums[mid]>target){
- high=mid;
- }else{
- low=mid+1;
- }
- }
- return low;
- }
题目10 ID136

给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
说明:
你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
示例 1:
输入: [2,2,1]
输出: 1
示例 2:
输入: [4,1,2,1,2]
输出: 4
我的解答:
这里用到了一个技巧:异或
异或具有以下几个性质:
1, 交换律 a^b^c等价于a^c^b
2, 任何数与0异或为原数 a^0=a
3, 相同的数异或等于0 a^a=0
所以我们只需要将数组中所有的数异或,就能够得到单独的那个数字
- int singleNumber(int* nums, int numsSize){
- int i;
- int flag=0;
- for(i=0;i<numsSize;i++){
- flag=flag^nums[i];
- }
- return flag;
- }
题目11 ID面试题53-II

一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0~n-1之内。在范围0~n-1内的n个数字中有且只有一个数字不在该数组中,请找出这个数字。
示例 1:
输入: [0,1,3]
输出: 2
示例 2:
输入: [0,1,2,3,4,5,6,7,9]
输出: 8
限制:
1 <= 数组长度 <= 10000
我的解答:
方法一:
因为是递增排序数组数字是0到n-1,只需要将0到n-1的数字相加,再将数组中的数字求和,两者之差则为缺少的那个数字,如果差值为0.证明缺少的数字是n,如输入[0,1],这样的案例,缺少的数字是2。
- int missingNumber(int* nums, int numsSize){
- int i;
- if(nums[0]!=0){
- return 0;
- }
- int sum1=0,sum2=0;
- for(i=0;i<numsSize;i++){
- sum1+=nums[i];
- }
- for(i=0;i<nums[numsSize-1]+1;i++){
- sum2+=i;
- }
- if(sum2-sum1==0){
- return numsSize;
- }else{
- return sum2-sum1;
- }
- }
方法二:
排序数组的搜索问题,应当第一时间想到二分法解决。经过观察可得,如果缺少的数字在数组中值的右边,则num[mid]==mid,令low=mid+1,若缺少的数字在数组中值的左边,则num[mid]!=mid,以此二分判断查找缺少数字的索引并返回。
- int missingNumber(int* nums, int numsSize){
- int low=0,high=numsSize-1;
- while(low<=high){
- int mid=(low+high)/2;
- if(nums[mid]==mid){
- low=mid+1;
- }else{
- high=mid-1;
- }
- }
- return low;
- }
Leetcode学习笔记(6)的更多相关文章
- Leetcode学习笔记(4)
题目1 ID121 给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格. 如果你最多只允许完成一笔交易(即买入和卖出一支股票),设计一个算法来计算你所能获取的最大利润. 注意你不能在买入股 ...
- Leetcode学习笔记(2)
题目1 ID面试题 01.04 给定一个字符串,编写一个函数判定其是否为某个回文串的排列之一. 回文串是指正反两个方向都一样的单词或短语.排列是指字母的重新排列. 回文串不一定是字典当中的单词. 示例 ...
- Leetcode学习笔记(1)
scrapy爬虫的学习告一段落,又因为现在在学习数据结构,做题平台是lettcode:https://leetcode-cn.com/ 每周都要交一次做题的笔记,所以把相关代码和思路同时放在博客上记录 ...
- leetcode学习笔记--开篇
1 LeetCode是什么? LeetCode是一个在线的编程测试平台,国内也有类似的Online Judge平台.程序开发人员可以通过在线刷题,提高对于算法和数据结构的理解能力,夯实自己的编程基础. ...
- Leetcode学习笔记(5)
之前断了一段时间没做Leetcode,深感愧疚,重新续上 题目1 ID104 给定一个二叉树,找出其最大深度. 二叉树的深度为根节点到最远叶子节点的最长路径上的节点数. 说明: 叶子节点是指没有子节点 ...
- Leetcode学习笔记(3)
题目1 ID88 给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 num1 成为一个有序数组. 说明: 初始化 nums1 和 nums2 的元素数量 ...
- Manacher算法学习笔记 | LeetCode#5
Manacher算法学习笔记 DECLARATION 引用来源:https://www.cnblogs.com/grandyang/p/4475985.html CONTENT 用途:寻找一个字符串的 ...
- [Java] LinkedList / Queue - 源代码学习笔记
简单地画了下 LinkedList 的继承关系,如下图.只是画了关注的部分,并不是完整的关系图.本博文涉及的是 Queue, Deque, LinkedList 的源代码阅读笔记.关于 List 接口 ...
- 学习笔记之机器学习(Machine Learning)
机器学习 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0 机器学习是人工智能的一个分 ...
随机推荐
- 19Jinja2中宏定义
1 @app.route('/') 2 def hello_world(): 3 return render_template('index.html') 4 5 6 {% macro input(n ...
- 11content_processor
1,content_processor 上下文处理器应该返回一个字典,字典中的key会被模板中当成变量来渲染 上下文处理器返回的字典,在所有页面中都是可以使用的 被这个装饰器修饰的钩子函数,必须要返回 ...
- 企业网络拓扑RSTP功能实例
组网图形 RSTP简介 以太网交换网络中为了进行链路备份,提高网络可靠性,通常会使用冗余链路.但是使用冗余链路会在交换网络上产生环路,引发广播风暴以及MAC地址表不稳定等故障现象,从而导致用户通信质 ...
- MyBatis 中 @Param 注解的四种使用场景
https://juejin.im/post/6844903894997270536 第一种:方法有多个参数,需要 @Param 注解 第二种:方法参数要取别名,需要 @Param 注解 第三种:XM ...
- Mybatis执行SQL的流程
前篇:Mybatis初始化过程 SqlSession : SqlSession是一个接口,它有两个实现类:DefaultSqlSession (默认)和 SqlSessionManager (弃用,不 ...
- nginx&http 第三章 ngx http 框架处理流程
1. nginx 连接结构 ngx_connection_t 这个连接表示是客户端主动发起的.Nginx服务器被动接受的TCP连接,我们可以简单称其为被动连接.同时,在有些请求的处理过程中,Nginx ...
- 一文带你玩转对象存储COS文档预览
随着"互联网+"的发展,各行各业纷纷"去纸化",商务合同.会议纪要.组织公文.商品图片.培训视频.学习课件.随堂讲义等电子文档无处不在.而要查看文档一般需要先下 ...
- sqlilab less19-less22
less19 当账号密码正确时,会将当前的refer和ip存入数据库.对这两个值同时没有进行过滤.考虑使用sqlmap对这两个参数进行注入 less-20 当cookie uname存在时,并且不是p ...
- 原生sql查询返回结果集处理方法
今天博主用原生写查询的时候发现,查询出来的居然不是我数据表里的数据,而是一个对象 object(mysqli_result)#2 (5) { ["current_field"]=& ...
- CG-CTF RSAEASY
最近学习rsa涨了不少新知识,这次遇到了一个比较简单但是需要想想的题目,因为发现网上没有查到wp就想写一下提供一些思路. 首先题目给了n,p-q,e,然后n很大,无法使用工具分解,呢么感觉肯定是利用p ...