python序列化与反序列化(json、pickle)-(五)
1.什么是序列化&反序列化?
序列化:将字典、列表、类的实例对象等内容转换成一个字符串的过程。
反序列化:将一个字符串转换成字典、列表、类的实例对象等内容的过程

PS:Python中常见的数据结构可以统称为容器。序列(如列表和元组)、映射(如字典)以及集合(set)是三类主要的容器。
场景一:我们在python中将一个功能给另外一段程序使用,怎么给?
方法一:功能存到文件,然后另一个python程序再从文件里读出来。
场景二:现在反过来怎么把读出来的文件字符串转换成字典?
方法二:eval()函数:将字符串str当成有效的表达式求值并返回计算结果,但存在风险,将str转换成python中的数据结构,推荐使用反序列化。
序列化就是从dic变成str(dic)的过程,反序列化就是从str(dic)变成dic的过程。
2.为什们要使用序列化?
序列化的目的:
1.以某种存储形式使自定义对象持久化(比如从内存存到硬盘)
2.将对象从一个地方传递到另一个地方
3.使程序更具维护性
序列化的2个模块:
json:用于字符串(str)和python数据类型间(比如字典、列表)进行转换
pickle:用于python特有的类型和python的数据类型间转换
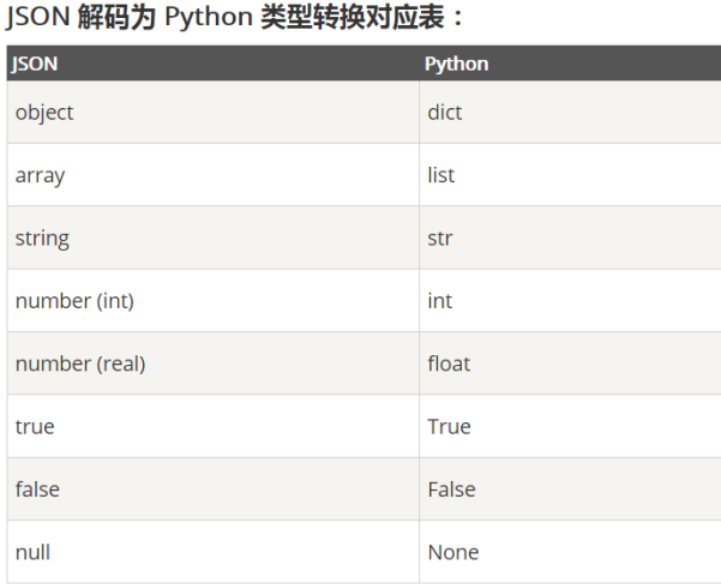
3.json
Json是一种轻量级的数据交换格式,基于ECMAScript的一个子集。Python3中可以使用json模块来对json数据进行编解码.
python本质:字符串,字符串中的值用双引号,包含了2个函数:
python对象->json:json.dumps(python对象)
json->python对象:json.loads(json字符串)
json.dumps():对数据进行编码,就是将mysql里的数据字符串或二进制的形式存储到硬盘。
dumps:输出到终端的操作方法,也就是把一个类型变量转换成str
dump:文件操作的方法,具体的操作json.dump(dict,open('test','w'))
json.loads():对数据进行解码,将抽象的数据内容(python对象)转换成字符串。
json.load和json.loads是反序列化输出的一个结果,dump和dumps是序列化输出终端或文件中去.
python对象(基本的数据类型):int、float、str、list、tuple、dict
需求:序列化,将字典info转换成字符串,存到test1.txt文件中。

ex1:用dumps()函数序列化,通过f.write()写入同级目录test1.txt文件。
import json
info={
'name':'wendy',
'age':22
}
f=open("test1.txt",'w')
#json.dumps(info)把一个字典info转换成字符串,从内存存到硬盘的过程叫序列化
#序列化dumps函数不可以序列化,只能处理简单的跨平台数据交互
f.write(json.dumps(info))
f.close()
ex2:用dump()函数序列化,直接json.dump()写入test1.txt文件。
import json
info={
'name':'wendy',
'age':22
}
f=open("test1.txt",'w')
#等于f.write(json.dumps(info))
json.dump(info,f)
f.close()
需求:用loads()函数反序列化,将字符串转换成python对象
#方式一:将字符串转换成python对象
import json
json_str1="""{"name": "wendy", "age": 22}"""
json_str3 = """12"""
name1=json.loads(json_str1) #将字符串转换成字典
name2=json.loads(json_str3) #将数字转换成数字
print(type(name1),type(name2)) #打印类型
print(name1,name2)
#显示结果如下:
<class 'dict'> <class 'int'>
{'name': 'wendy', 'age': 22} 12 #方式二:从同级目录test1.txt中取值,将字符串转换成python对象
#test1.txt中的值:{"name": "wendy", "age": 22}
import json
f=open("test1.txt",'r')
data =json.loads(f.read())#等于json.load(f)
print(data["name"])
#显示结果如下:
wendy
4.pickle
pickle的load、loads和dump、dumps的使用操作,先来说下,pickle和json的差异:
4.1 pickle和json都可以实现序列化和反序列化的操作
4.2 在写入文件的时候,pickle是以加密的方式写入的,在打开文件的时候用'rb'模式,用‘wb’模式写入(二进制的形式)
4.3 pickle可以对类创建的对象进行反序列化输入到文件中
pickle模块的4个功能:dump(序列化,存)、dumps、loads(反序列化,读)、load
import pickle
class ABC:
a=10
def __init__(self,m,n):
self.m=m
self.n=n abc=ABC(1,2)
res=pickle.dumps(abc) #pickle可序列化任意类型,比如:序列化类实例
back_res=pickle.loads(res)
print(res)
print(back_res)
print(back_res.a)
#结果显示
b'\x80\x03c__main__\nABC\nq\x00)\x81q\x01}q\x02(X\x01\x00\x00\x00mq\x03K\x01X\x01\x00\x00\x00nq\x04K\x02ub.'
<__main__.ABC object at 0x000001D7A0B31048>
10
python序列化与反序列化(json、pickle)-(五)的更多相关文章
- day5-python中的序列化与反序列化-json&pickle
一.概述 玩过稍微大型一点的游戏的朋友都知道,很多游戏的存档功能使得我们可以方便地迅速进入上一次退出的状态(包括装备.等级.经验值等在内的一切运行时数据),那么在程序开发中也存在这样的需求:比较简单的 ...
- Python序列化与反序列化-json与pickle
Python序列化与反序列化-json与pickle 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.json的序列化方式与反序列化方式 1>.json序列化 #!/usr ...
- Python开发之序列化与反序列化:pickle、json模块使用详解
1 引言 在日常开发中,所有的对象都是存储在内存当中,尤其是像python这样的坚持一切接对象的高级程序设计语言,一旦关机,在写在内存中的数据都将不复存在.另一方面,存储在内存够中的对象由于编程语言. ...
- python类库32[序列化和反序列化之pickle]
一 pickle pickle模块用来实现python对象的序列化和反序列化.通常地pickle将python对象序列化为二进制流或文件. python对象与文件之间的序列化和反序列化: pi ...
- python模块概况,json/pickle,time/datetime,logging
参考: http://www.cnblogs.com/wupeiqi/articles/5501365.html http://www.cnblogs.com/alex3714/articles/51 ...
- Python序列化和反序列化
Python序列化和反序列化 通过将对象序列化可以将其存储在变量或者文件中,可以保存当时对象的状态,实现其生命周期的延长.并且需要时可以再次将这个对象读取出来.Python中有几个常用模块可实现这一功 ...
- Python 序列化与反序列化
序列化是为了将内存中的字典.列表.集合以及各种对象,保存到一个文件中(字节流).而反序列化是将字节流转化回原始的对象的一个过程. json库 序列化:json.dumps() 反序列化:json.lo ...
- C#序列化及反序列化Json对象通用类JsonHelper
当今的程序界Json大行其道.因为Json对象具有简短高效等优势,广受广大C#码农喜爱.这里发一个序列化及反序列化Json对象通用类库,希望对大家有用. public class JsonHelper ...
- Jackson序列化和反序列化Json数据完整示例
Jackson序列化和反序列化Json数据 Web技术发展的今天,Json和XML已经成为了web数据的事实标准,然而这种格式化的数据手工解析又非常麻烦,软件工程界永远不缺少工具,每当有需求的时候就会 ...
- (推荐JsonConvert )序列化和反序列化Json
在Json文本和.Net对象之间转换最快的方法是试用JsonSerializer. JsonSerializer通过将.Net对象属性名称映射到Json属性名称,并为其复制值,将.Net对象转换为其J ...
随机推荐
- Databricks说的Lakehouse是什么?
在过去的几年里,Lakehouse作为一种新的数据管理范式,已独立出现在Databricks的许多用户和应用案例中.在这篇文章中,我们将阐述这种新范式以及它相对于之前方案的优势. 数据仓库在决策支持和 ...
- nice-ni 耗光cpu
可以看到 低优先级的进程 暂用了比较高的CPU时间. top 命令中可以看到 NI 为19, 其优先级最低 但是使用cpu 最高. 说明这个进程需要经行优化了, 通过gdb 发现此进程一直都在处理报文 ...
- mysql开发常用技巧总结
1.查询某个schema,某张表的创建时间. SELECT CREATE_TIME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA='db_camp ...
- Centos7升级内核后无法启动解决办法
前言 这个问题存在有一段时间了,之前做的centos7的ISO,在进行内核的升级以后就存在这个问题: 系统盘在板载sata口上是可以正常启动新内核并且能识别面板硬盘 系统盘插在面板口上新内核无法启动, ...
- Java 用jxl读取excel并保存到数据库(此方法存在局限,仅限本地电脑操作,放在服务器上的项目,需要把文件上传到服务器,详细信息,见我的别的博客)
项目中涉及到读取excel中的数据,保存到数据库中,用jxl做起来比较简单. 基本的思路: 把excel放到固定盘里,然后前段页面选择文件,把文件的名字传到后台,再利用jxl进行数据读取,把读取到的数 ...
- 怎么用在线思维导图Ayoa规划个人任务
在Ayoa的任务板功能中可以对某一任务进行详细设置,例如改变紧急情况/重要程度.添加到我的计划工具.设置开始日期.截止日期等. 图1:任务详情设置 而这里的"我的计划工具"就是一个 ...
- 如何改变CorelDRAW的外观主题皮肤?
CorelDRAW,我们通常也简称为CDR,是一款专业而且使用广泛的矢量图形绘制软件,也常用于绘制图形以及平面设计中.今天我们以CorelDRAW 2020来为大家演示一下,如何改变CorelDRAW ...
- HDU 4920 Matrix multiplication 题解(内存访问连续性/卡常)
题目链接 题目大意 多组输入,给你两个n×n的矩阵,要你求他们相乘%3的值 题目思路 这个题目主要是要了解内存访问连续化,要尽量每次访问连续的内存 所以第一种方法会超时,第二种则AC.一种卡常技巧 代 ...
- go特性-defer
1:后定义的defer先执行(可以理解为栈的方式) // 222 // 111 func Test1(t *testing.T) { defer fmt.Println("111" ...
- 容器中实现拉取其它服务器的jar包程序
缘由:在做接口自动化测试时,若业务场景有一个前置仓库,在该仓库内完成一系列的场景测试,一旦某一场景测试失败,脏数据对环境造成影响则需要清理: 1.我容器的内核系统为Debian GNU/Linux 1 ...