详解GaussDB(for MySQL)服务:复制策略与可用性分析
摘要:本文通过介绍GaussDB(for MySQL)读写路径,分析其可用性。
简介
数据持久性和服务可用性是数据库服务的关键特征。
在实践中,通常认为拥有 3 份数据副本,就足以保证持久性。
但是 3 份副本,对于可用性的要求是不够的。维护 3 份一致的副本意味着,这些副本必须同时在线,系统才能保证可用。当数据库跨多个节点分片时,某些节点不可用的概率会随着节点数量的增加而呈指数增长。
在 GaussDB(for MySQL) 中,我们针对日志和数据采用不同副本策略,并采用一种新颖的恢复算法,来解决可用性的问题。
下面首先介绍写路径,然后介绍读路径,最后分析理论上的可用性估计,并与其它副本策略进行比较。
写路径
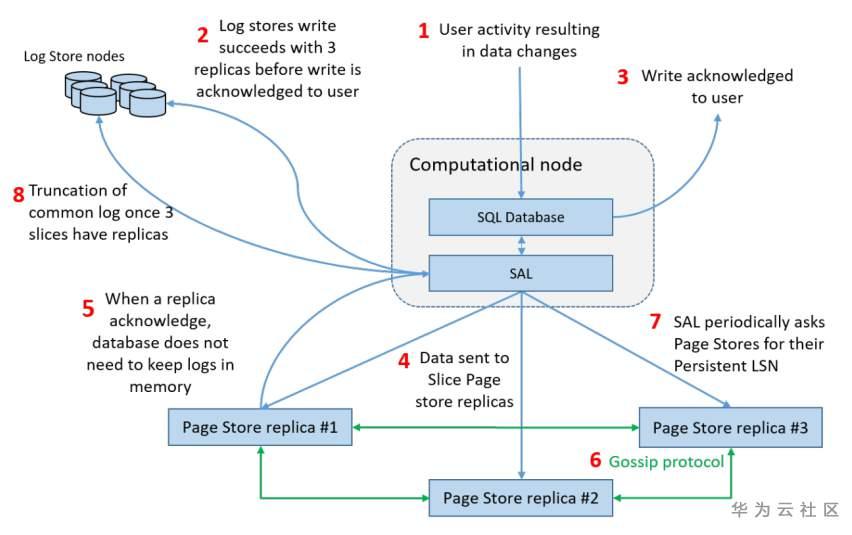
写路径如上图所示,下面对每一个步骤进行说明。
1)用户事务导致对数据库页面的更改,从而生成描述更改的日志记录(redo log,下面简称 redo)。
2)将 redo 写入到 Log Stores。写入 3 份副本,并且采用强一致性,即 3 份均写入成功才算成功。
3)将事务标记为已提交(committed)。
只要集群中有三个或以上的 Log Stores 可用,该数据库就可以进行写操作(因为写入只需要选择可用的节点即可,并不规定一定要写入某个节点)。对于成千上万个节点的群集,这实际上意味着 100% 的写入可用性。
4)redo 写入 Log Stores 之后,会将此 redo 放入到 SAL 的 write buffer 中,之后将此 buffer 写入到管理对应 slice 的 Page Store 上。
5)当任何一个 Page Store 副本返回成功,此写入成功,SAL 的 write buffer 被释放。
6)不同的 Page Store 副本之间使用 gossip 协议检测和修复缺失的日志。
空间回收
数据库运行过程中,会源源不断地产生 redo 日志。如果不将不需要的 redo 删除,可以预见,最终肯定会耗尽磁盘空间。在成功将 redo 写入所有 Slice 副本,并且所有数据库的读副本(read replica)都可以看到该记录之后,就可以将该日志从 Log Store 中删除。独立地跟踪每条 redo 的持久性很费资源,因此我们选择基于 LSN 来跟踪持久性。
对于 Page Store 的每个 slice,都有一个 persistent LSN,它的含义是 slice 接收到的所有日志记录中,保证连续(没有空洞)的最大 LSN。(譬如某个 slice 接收到 LSN 为 1 的 redo log 后,persistent LSN 变为 1,此时如果接收到 LSN 为 3 的 redo log,persistent LSN 依然为 1。之后如果接收到 LSN 为 2 的 redo log,即补齐了空洞之后, persistent LSN 变为 3)。
7)SAL 可以通过定期调用 api 或者在读写接口中获取每个 slice 的 persistent LSN(在恢复中也会使用)。
8)SAL 也会跟踪每个 PLog 的 LSN 范围。如果 PLog 中的所有 redo 的 LSN 都小于数据库 persistent LSN(3 副本中最小 persistent LSN),该 PLog 可被删除。
通过上面的机制,我们能够保证每条 redo 都至少会有三个节点上存在副本(一开始在 Plog Store 节点上有 3 副本,保证在 Page Store 节点上有 3 副本之后,将 Plog Store 节点上的副本删除,以回收磁盘资源)。
读路径
数据库前端以 page 粒度读取数据。
读取或者修改数据时,相应的 page 必须在 buffer pool 中。当 buffer pool 已满,我们又需要引入一个 page 时,必须将某些页面从 buffer pool 中淘汰。
我们对淘汰算法进行了修改,保证只有当所有相关 redo 日志都写入至少 1 个 Page Store 副本后,脏页才能被淘汰。因此,在最新的 redo 记录到达 Page Store 之前,保证相应的页面可从 buffer pool 中获得。 之后,可以从 Page Store 中读取页面。
对于每一个 slice,SAL 保存最新 redo log 的 LSN。主节点读取 page 时,读请求首先到达 SAL,SAL 会使用上述 LSN 下发读请求。读请求会被路由到时延最低的 Page Store。如果被选择的 Page Store 不可用或者还没有收到提供 LSN 之前的所有 redo,会返回错误。之后 SAL 会尝试下一个 Page Store,遍历所有副本,直到读请求可以被正确响应。
可用性分析
quorum replication
目前业界最广泛使用的强一致性复制技术基于 quorum replication。如果每份数据在 N 个节点上存在副本,每个读取操作必须从NR个节点接收响应,并写入NW个节点。
为了保证强一致性,必须满足 NR + NW > N 。业界许多系统使用 quorum replication 的不同组合方式。 例如,
1)RAID1 磁盘阵列中通常使用 N = 3,NR = 1,NW = 3;
2)PolarDB 中,N = 3,NR = 2,NW = 2;
3)Aurora 中,N = 6,NR = 3,NW = 4。
下面的分析中,仅考虑节点单独出现不可用的场景(不考虑譬如因为断点导致所有节点不可用的场景)。
假设 1 个节点不可用的概率为 x,则当 N - NW + 1 到 N 个节点同时不可用时,写请求会失败。 即一个写请求失败的概率可用如下公式计算:
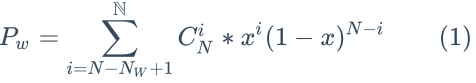
同理,一个读请求失败的概率计算公式如下:
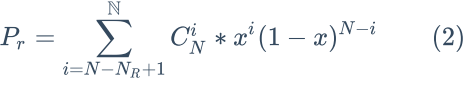
GaussDB(for MySQL)
写
在前面的写路径一节中已经提到,GaussDB(for MySQL) 的写 redo,不需要写到特定的 Log Store 上,所以公式 (1) 并不适用。对于写请求,只有当所有 PLog Store 都不可用时,才会失败。如果集群中 Log Store 足够多,这个概率几乎接近于 0。
读
对于读,每个 Page Store 节点都可以基于其 persistent LSN 决定是否可以为读提供服务。如果不能,它将返回错误,告诉 SAL 尝试另一个节点。在极少数情况下,由于级联故障,没有节点可以提供读服务(并非节点不可用),SAL 会识别这种情况并使用 Log Store 来修复数据。在这种情况下,性能可能下降,但是存储层仍然可用。
SAL 无法恢复的唯一情况是,包含 Slice 副本的所有 Page Store 都不可用,这样的概率是 x^3。
下表对比了 GaussDB(for MySQL) 和几种典型 quorum replication 场景的可用性:

结论
1)对于写,GaussDB(for MySQL) 总是可用的,优于 quorum replication 方案;
2)对于读,除了 x = 0.01 且 quorum 的节点个数为 6 的情况,GaussDB(for MySQL) 总是能提供比 quorum replication 相同或更好的的可用性。并且在上面的场景下,提供的可用性已经足够高,与 quorum replication 相差并不远。
详解GaussDB(for MySQL)服务:复制策略与可用性分析的更多相关文章
- MySQL系列详解八:MySQL多线程复制演示-技术流ken
前言 Mysql 采用多线程进行复制是从 Mysql 5.6 开始支持的内容,但是 5.6 版本下有缺陷,虽然支持多线程,但是每个数据库只能一个线程,也就是说如果我们只有一个数据库,则主从复制时也只有 ...
- MySQL系列详解九:MySQL级联复制演示-技术流ken
前言 级联复制就是master服务器,只给后端一台slave服务器同步数据,然后这个slave服务器在向后端的所有slave服务器同步数据,这样就可以降低master服务器的写压力,和复制数据的网络I ...
- Linux/CentOS 服务安装/卸载,开机启动chkconfig命令详解|如何让MySQL、Apache开机启动?
chkconfig chkconfig在命令行操作时会经常用到.它可以方便地设置和查询不同运行级上的系统服务.这个可要好好掌握,用熟练之后,就可以轻轻松松的管理好你的启动服务了. 注:谨记chkcon ...
- MySQL系列详解六:MySQL主从复制/半同步演示-技术流ken
前言 随着技术的发展,在实际的生产环境中,由单台MySQL数据库服务器不能满足实际的需求.此时数据库集群就很好的解决了这个问题了.采用MySQL分布式集群,能够搭建一个高并发.负载均衡的集群服务器.在 ...
- MySQL系列详解三:MySQL中各类日志详解-技术流ken
前言 日志文件记录了MySQL数据库的各种类型的活动,MySQL数据库中常见的日志文件有 查询日志,慢查询日志,错误日志,二进制日志,中继日志 .下面分别对他们进行介绍. 查询日志 1.查看查询日志变 ...
- 详解 Spotlight on MySQL监控MySQL服务器
前一章详解了Spotlight on Unix 监控Linux服务器 ,今天再来看看Spotlight on MySQL怎么监控MySQL服务器. 注:http://www.cnblogs.com/J ...
- MySQL系列详解一:MySQL&&多实例安装-技术流ken
简介 MySQL是一个真正的多用户.多线程SQL数据库服务器.SQL(结构化查询语言)是世界上最流行的和标准化的数据库语言,它使得存储.更新和存取信息更加容易.MySQL是一个客户机/服务器结构的实现 ...
- 详解GaussDB(DWS) explain分布式执行计划
摘要:本文主要介绍如何详细解读GaussDB(DWS)产生的分布式执行计划,从计划中发现性能调优点. 前言 执行计划(又称解释计划)是数据库执行SQL语句的具体步骤,例如通过索引还是全表扫描访问表中的 ...
- 图文详解linux/windows mysql忘记root密码解决方案
经常有用户过来咨询说自己的mysql服务器忘记密码了怎么办,为了更好的解决大家的困扰,本文特归档整理了windows和linux系统下,mysql忘记密码的解决方案.本文内容是我亲测实用,当然过程中踩 ...
随机推荐
- 数据可视化基础专题(十):Matplotlib 基础(二) 自定义配置文件和绘图风格(rcParams和style)
https://matplotlib.org/api/rcsetup_api.html#module-matplotlib.rcsetup 一.什么是rcParams?我们在使用matplotlibl ...
- Flask 基础组件(四):模板
1.模板的使用 1.1 语法 1.1.1 流程控制 逻辑语法 Jinja2模板语言中的 for {% for foo in g %} {% endfor %} Jinja2模板语言中的 if {% ...
- JS中this指向的更改
JS中this指向的更改 JavaScript 中 this 的指向问题 前面已经总结过,但在实际开中, 很多场景都需要改变 this 的指向. 现在我们讨论更改 this 指向的问题. call更改 ...
- pointer-events:none 的应用
相信很多人都遇到过 Retina屏的1px边框 的问题. 很多人都用 :before,:after 伪类 eg: .div:after { position: absolute; top: 0; ...
- Kubernetes实战指南(三十一):零宕机无缝迁移Spring Cloud至k8s
1. 项目迁移背景 1.1 为什么要在"太岁"上动土? 目前公司的测试环境.UAT环境.生产环境均已经使用k8s进行维护管理,大部分项目均已完成容器化,并且已经在线上平稳运行许久. ...
- 使用数据泵(expdp、impdp)迁移数据库流程
转载原文地址为:http://blog.itpub.net/26736162/viewspace-2652256/ 使用数据泵迁移数据库流程 How To Move Or Copy A Databas ...
- Springboot整合SpringSecurity--对静态文件进行权限管理
文章目录 一.要求 二.依赖管理 三.配置config文件 四.扩展 一.要求 index.html 可以被所有用户访问 1.html只能被VIP1访问 2.html只能被VIP2访问 3.html只 ...
- humlbe bundle如何绑定二次验证码_虚拟MFA_两步验证_谷歌身份验证器?
一般点账户名——设置——安全设置中开通虚拟MFA两步验证 具体步骤见链接 humlbe bundle如何绑定二次验证码_虚拟MFA_两步验证_谷歌身份验证器? 二次验证码小程序于谷歌身份验证器APP的 ...
- 华为云如何使用二次验证码/虚拟MFA/两步验证/谷歌验证器?
一般点账户名——设置——安全设置中开通虚拟MFA两步验证 具体步骤见链接 华为云如何使用二次验证码/虚拟MFA/两步验证/谷歌验证器? 二次验证码小程序于谷歌身份验证器APP的优势 1.无需下载ap ...
- 线上CUP负载过高排查方法
1.top命令查看线程占据的CPU 注意:上面行的cpu是多个内核的平均CPU,不可能超过100% 下面的cpu是每个进程实际占用的cpu,可能超过100% 备注:查看多个内核cpu,只需要在输入 ...