Serverless 如何应对 K8s 在离线场景下的资源供给诉求
本文整理自腾讯云云原生产品团队的专家产品经理韩沛在 Techo 开发者大会云原生专题的分享内容——Kubernetes 混部与弹性容器。本次分享主要分为三部分:基于 K8s 的应用混部、提升应用混部效果的关键、弹性容器对混部集群的价值。

讨论 K8s 的混部这个话题,是因为我们发现,在业务 K8s 化后,混部和资源利用率对运维团队是一个绕不过去的话题,这个话题也一直是我们腾讯云原生团队一直关注的重点。
首先,毋庸置疑,Kubernetes 的系统能力和它作为引擎推动的云原生生态影响力都非常强大,助力了很多先进理念在生产环境的大规模实用化,包括微服务、自动扩缩容、CICD、服务网格、应用混部等。
这其中有些部分在现有 K8s 的系统中即可以得到很好的支持,比如微服务、自动扩缩容。有些则依赖 K8s 与生态能力的集成,比如 CICD、服务网格,就依赖 K8s 和一些社区 DevOps 、servicemesh 系统的打通,不过它们中的大部分在生态系统中已经得到了很好的集成支持,通常不需要我们再做太多的工作。
但我们今天的话题——K8s 架构下的应用混部,则是一个较特殊的领域,一方面大部分的企业基础设施升级为云原生架构后,通常会天然支持一些混部能力,从而带来一些显而易见的收益,比如资源利用率的提升。可以说容器化和 K8s 为整个行业进入应用的大规模混部打开了一扇窗。而另一方面,但当我们真正进这个领域时,即使站在 K8s 的肩膀上,混部依然是对企业架构能力的一个巨大挑战。

在容器化之前,在物理或虚拟服务器上部署应用,资源利用率通常很低,一是很多应用本身具有潮汐现象,二是服务器大部分情况只能部署一个应用,而非 K8s 那样在一个节点上部署多个。但容器化托管到 K8s 集群后,很多时候,我们会发现资源利用率还是不高。
上图,是一个 K8s 集群线上业务的典型资源曲线,最上面的蓝线是容器资源 request 申请值,红色线是容器真实运行的曲线值,我们看到 request 和 usage 之间有很大 gap,这是因为对容器资源的评估不可能完全精准,另外,波峰和波谷也有差别,最终导致平均利用率不高。
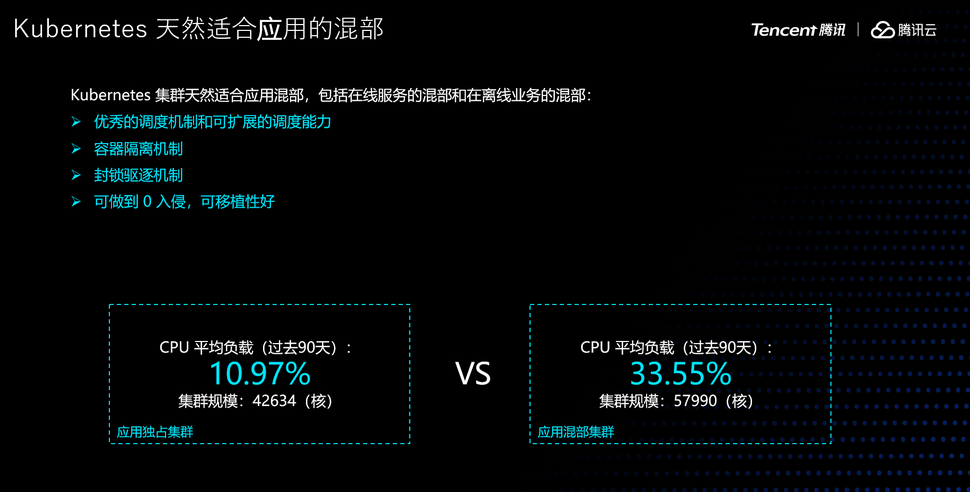
那是不是 K8s 不行呢?当然不是,K8s 在助力我们进行应用混部上虽然还没有解决所有的问题,但绝对是最佳的可选平台之一。
优秀的系统能力使 K8s 天然适合进行混部,包括在线服务的混部和现在业内火热的在离线混部。腾讯内部也通过 K8s 化,在很多场景显著提升了资源利用率。
像腾讯这种规模的计算体量,除了大家熟知明星应用,还有海量的算力在进行服务支撑、离线计算等。通过把这部分应用以及一些潮汐现象明显的产品服务进行混部,资源利用率的提升非常显著。

在业内,Google 基于 K8s 的前身 Borg 系统,从 2015 年至今已发布了多篇与混部相关的论文。于去年发布一篇论文中,可以看到 Borg 支持的混部能力已经逼近 60% 的 CPU 资源利用率。对比其 2011 年和 2019 年的混部效果,可以看到,除了利用率的提升,最显著的变化,一是应用分级粒度更细了,二是各级别的应用运行更加平稳了。尤其是第二点,明显感觉到 Borg 在混部的支撑层面,如调度增强、资源预测回收、任务避让等机制上的进步。
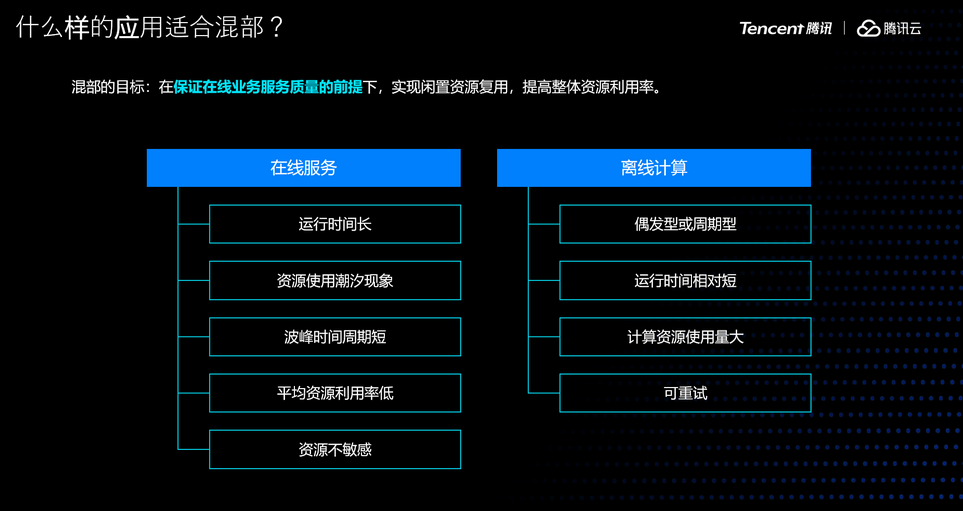
提升混部效果的关键是什么?首先,我们需要明确两个问题。
第一个问题,混部的目的是什么?混部的目的是在保证在线业务服务质量的前提下,实现闲置资源复用,提高整体资源利用率。保证在线业务服务质量是前提,使之不受影响,没有这个前提,利用率提升再高也毫无意义。
第二个问题,什么样的应用适合混部?适合混部的应用有两类:一类是算力要求很高的周期性应用,通常是一些离线计算任务。一类是容易造成资源浪费的应用,通常是一些长时间运行的、具备潮汐现象的在线服务。但要注意,有些在线服务会对某些资源有较高的敏感性,这类服务是对混部系统的最大挑战,因为稍有不慎就会偏离混部的目的,影响了在线服务质量,得不偿失。
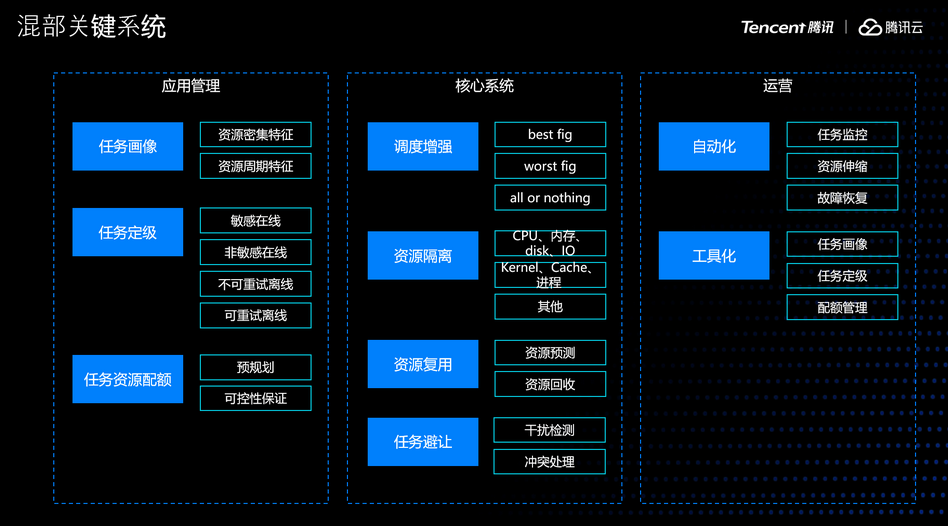
在确定了这两个问题之后,我们来看下混部系统需要有哪些机制。通常分为三层:
一是对混部应用进行特征画像、定级以及分配资源配额的应用管理层。这一层定义应用的级别,混部的时机,以及通过配额保证资源分配不失控。
二是对混部集群进行调度、隔离、资源复用和避让的核心系统。这一层是混部的核心,基本决定了我们的集群能达到什么样的混部效果。
最后,还需要一整套适配的自动化运营系统。

混部的基本原理是对闲置资源的再分配。通常,闲置资源有两个来源。集群内会有碎片资源,这是资源分配颗粒度问题导致的,这些碎片资源可以分配给颗粒度更小的应用使用。另外,在线服务申请的资源通常会大于实际使用的资源,配合应用画像,预测出这部分服务的波峰波谷,可以将这部分闲置资源分配给其他应用。
基于这个背景,引申出混部最核心的两个子模块:资源复用和任务避让。顾名思义,资源复用就是把上述两种闲置资源通过预测、回收的机制,实时再分配给混部应用使用。而任务避让,就是检测核心在线服务是否收到了混部的影响。一旦发生干扰,马上触发冲突处理机制,进行压制和再调度等操作。

可以这么说,这两个模块决定了混部的效果和可混部的应用范围。除了理论上的问题,还有一些重要的点必须考虑:为了保证混部效果,频繁对集群实时情况进行预测和资源回收,对集群本身带来了额外的负担,如何在尽可能资源复用和尽量降低资源预测回收频率之间找到平衡?还有,为了保证在线服务的质量,任务回避通常不可避免,这就降低了次优先级应用的执行效率,高负载时可能导致任务的频繁重试和堆积,进而可能拖累整个集群。
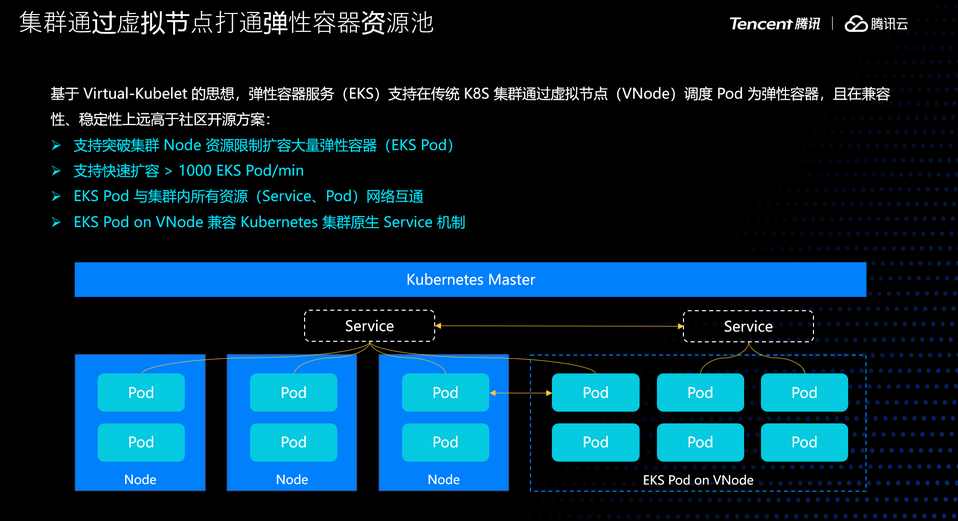
为了解决这些问题,腾讯云云原生团队做了一直在思考和尝试,目前较先进的一种方式是通过 serverless 容器即弹性容器,来拓展整个混部集群的资源池。
弹性容器是腾讯云推出的无服务器容器产品。它支持一种能力,类似开源virtual kubelet 的方式,但又相比开源方案能力更强、更适合生产。它支持在一个既有 K8s 集群中通过部署虚拟节点的方式把 pod 调度为弹性容器。调度为弹性容器的 pod 与原集群中的其他 pod 网络互通,如果关联了service ,service间也可互通。
所以无论是已有 workload 的扩容、还是新的 workload,都可以以一种平滑的方式进行调度。且该能力对集群不会产生额外的维护成本。
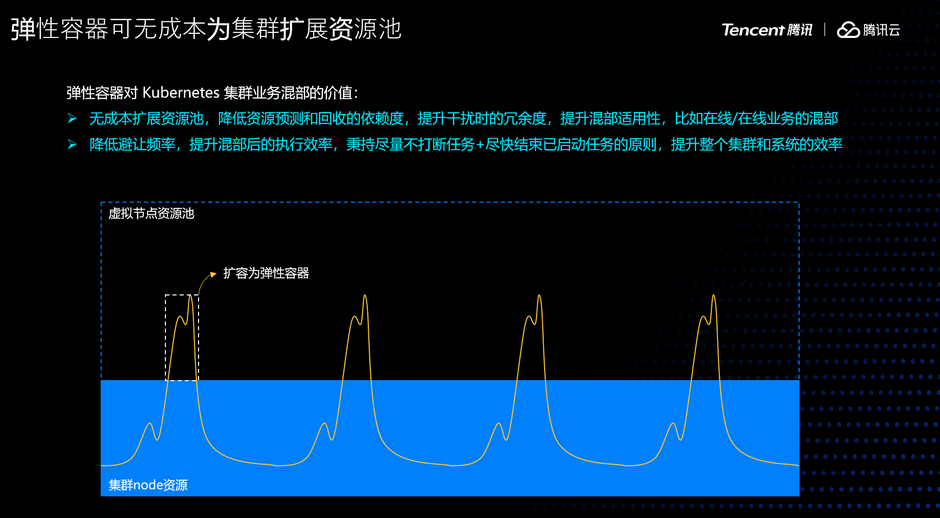
这个能力对混部的核心价值在于:它无成本的扩展了集群资源池,降低了资源冲突的风险,提升了混部集群的冗余度和适用性。另外,在检测到资源不足之类的冲突时,在很多场景可以不中止次优先级任务,而是视情况扩容或再调度,在弹性容器上继续运行任务,秉持尽量不打断已启动任务的原则,提升整个系统的效率。

这类混部集群的几个典型场景:
1、低负载时进行任务填充,运行更多任务,提升集群资源利用率。
2、万一发生了在线服务干扰,封锁相关节点,驱逐次优先级任务到虚拟节点,让其继续运行。
3、发生集群资源紧张时,封锁相关节点,视情况,如果是可压缩资源紧张,比如 CPU、IO 等,则压制次优先级任务;如果是不可压缩资源紧张,如内存、存储等,则驱逐次优先级任务到虚拟节点;在此情况下所有新增 Pod 均调度到虚拟节点,不再对集群固定资源增加任何压力,避免发生雪崩。
这3个例子还不能覆盖所有的混部场景,但已经提升了原生 K8s 集群混部的适用范围。我们也在持续探索其他的路径来做到更好。也欢迎有想法的朋友下来一起探讨和分享。
最后,混部是一个持续优化的过程。各家大厂都对混部投入了相当长的时间研究,才开始放量铺开。随着技术的发展,K8s 混部的效果会越来越好,适用的场景也会越来越多。谢谢大家!
Kubernetes 混部与弹性容器(本文) PPT 下载方式,请在公众号腾讯云原生后台回复关键字“EKS”获取。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

Serverless 如何应对 K8s 在离线场景下的资源供给诉求的更多相关文章
- 难道主键除了自增就是GUID?支持k8s等分布式场景下的id生成器了解下
背景 主键(Primary Key),用于唯一标识表中的每一条数据.所以,一个合格的主键的最基本要求应该是唯一性. 那怎么保证唯一呢?相信绝大部分开发者在刚入行的时候选择的都是数据库的自增id,因为这 ...
- 超大规模商用 K8s 场景下,阿里巴巴如何动态解决容器资源的按需分配问题?
作者 | 张晓宇(衷源) 阿里云容器平台技术专家 关注『阿里巴巴云原生』公众号,回复关键词"1010",可获取本文 PPT. 导读:资源利用率一直是很多平台管理和研发人员关心的话 ...
- 从零入门 Serverless | SAE 场景下,应用流量的负载均衡及路由策略配置实践
作者 | 落语 阿里云云原生技术团队 本文整理自<Serverless 技术公开课>,关注"Serverless"公众号,回复"入门",即可获取 S ...
- 从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
本文来自火山引擎公众号,原文发布于2021-09-06. 近日,字节跳动旗下的企业级技术服务平台火山引擎正式对外发布「ByteHouse」,作为 ClickHouse 企业版,解决开源技术上手难 &a ...
- 浅谈Vue不同场景下组件间的数据交流
浅谈Vue不同场景下组件间的数据“交流” Vue的官方文档可以说是很详细了.在我看来,它和react等其他框架文档一样,讲述的方式的更多的是“方法论”,而不是“场景论”,这也就导致了:我们在阅读完 ...
- 亿级流量场景下,大型架构设计实现【2】---storm篇
承接之前的博:亿级流量场景下,大型缓存架构设计实现 续写本博客: ****************** start: 接下来,我们是要讲解商品详情页缓存架构,缓存预热和解决方案,缓存预热可能导致整个系 ...
- Entity Framework入门教程(9)---离线场景附加实体图集到上下文
附加离线实体图集到上下文 这节主要内容是通过不同的方法将离线实体附加到上下文中. 在离线场景中,保存一个实体要略微困难一些.当我们保存一个离线的实体图集或一个单独的离线实体时,我们需要做两件事.首先, ...
- 【Vue】浅谈Vue不同场景下组件间的数据交流
浅谈Vue不同场景下组件间的数据“交流” Vue的官方文档可以说是很详细了.在我看来,它和react等其他框架文档一样,讲述的方式的更多的是“方法论”,而不是“场景论”,这也就导致了:我们在阅读完 ...
- 美团在O2O场景下的广告营销
美团作为中国最大的在线本地生活服务平台,覆盖了餐饮.酒店.旅行.休闲娱乐.外卖配送等方方面面生活场景,连接了数亿用户和数百万商户.如何帮助本地商户开展在线营销,使得他们能快速有效地触达目标用户群体提升 ...
随机推荐
- 人社部新职业,Panda Global发现区块链新职业榜上有名!
近日,为了助力新冠肺炎疫情的防控,扎实做好"六稳"工作,全面落实"六保"任务,促就业拓岗位,人力资源社会保障部联合市场监管总局.国家统计局近日正式向社会发布一批 ...
- ACM里的期望和概率问题 从入门到精通
起因:在2020年一场HDU多校赛上.有这么一题没做出来. 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6829 题目大意:有三个人,他们分别有X,Y ...
- git clone 速度太慢解决方法
本来想下载一个翻墙软件,实在是忍受不了每秒十几K的龟速,查阅各种资料,终于找到了失传已久的秘籍 先附图,实测有效,这速度简直要上天了啊啊啊啊啊(只支持HTTPS方式,SSH无效) 方案:使用githu ...
- 有了Git这个功能,再也不需要依赖IDE了!
大家好,今天给大家介绍一个隐藏的功能--搜索. 我们在写代码的时候经常遇到的一种情况就是,我们想要知道某一个函数是怎么定义的,这样我们才能知道该如何调用它.如果代码少的话我们当然可以自己人肉查找,但是 ...
- Tokyo 五年 IT 生活
今天阳光甚好,在家中小屋,闲来无事,回顾一下这五年的历程.我想从来东京的缘由.东京的环境.生活.IT这四个方面介绍一下. 首先,说一下为什么我会来到东京. 电子信息专业毕业,大学实验室学习IT,毕业后 ...
- Scala中的IO操作及ArrayBuffer线程安全问题
通过Scala对文件进行读写操作在实际业务中应用也比较多,这里介绍几种常用的方式,直接上代码: 1. 从文件中读取内容 object Main { def loadData(): Array[Stri ...
- Struts2-059 漏洞复现
0x00 漏洞简介 Apache Struts框架, 会对某些特定的标签的属性值,比如id属性进行二次解析,所以攻击者可以传递将在呈现标签属性时再次解析的OGNL表达式,造成OGNL表达式注入.从而可 ...
- C# 数组 ArrayList List<T>区别
System.Collenctions和System.Collenctions.Generic 中提供了很多列表.集合和数组.例如:List<T>集合,数组Int[],String[] . ...
- C# 如何查询字符串前面有几个0
有几个0 string t = "0001203"; int tLen = t.Length - t.TrimStart('0').Length; charAt方法 using S ...
- 让vs2013自带的IISExpress支持apk文件下载
使用vs2013作为android的服务器端开发时,总是会碰到需要自动更新的功能,VS2013自带IIS Express,想要下载apk文件,就需要添加MIME映射.没有图形界面,只能命令行.进入C: ...