Python爬取跑男的评论,看看大家都在看谁吧
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于菜J学Python,作者: J哥
Python爬取爬取腾讯视频弹幕视频讲解
https://www.bilibili.com/video/BV1954y1r7pi/
![]()
前言
「《奔跑吧》第五季」已经播出两期了,节目以“黄河生态经济带”沿线地区为依托,通过创新游戏设置、直播带货扶贫等新形式,展现黄河流域的重要地位,描绘黄河生态经济带城市“文化之美”。
然而,网友貌似并不买账,邓超、郑凯等退出跑男后,「收视明显不如以前」,而吐槽貌似有所增加。为了了解吃瓜群众们对于跑男的看法,我爬了爬腾讯视频关于跑男的评论,并做了简单文本「可视化分析」。
数据获取
腾讯视频评论要点击「查看更多评论」才能加载更多数据,很明显是一个动态网页,评论内容使用了「Ajax动态加载技术」。因此,我们需要找到「真实URL」,然后再请求数据。通过真实URL获取到cursor=?和_=?这两个参数即可。核心代码如下:
def main():
#初始页面的_=?
page=1607948139253
#初始待刷新页面的cursor=?
lastId="0"
for i in range(1,1000):
time.sleep(1)
html = get_content(page,lastId)
#获取评论数据
commentlist=get_comment(html)
print("------第"+str(i)+"轮页面评论------")
k = 0
for j in range(1,len(commentlist)):
comment = commentlist[j]
k += 1
print('第%s条评论:%s'%(k,comment))
#获取下一轮刷新页ID
lastId=get_lastId(html)
page += 1
if __name__ == '__main__':
main()
![]()
数据处理
导入相关包
import jieba
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType
import stylecloud
from IPython.display import Image
![]()
导入评论数据
分别爬取了两期评论,因此需要分别读取并合并所有数据。
df1 = pd.read_csv('/腾讯评论/paonan.csv',names=['评论内容'])
df2 = pd.read_csv('/腾讯评论/paonan1.csv',names=['评论内容'])
df = pd.concat([df1,df2])
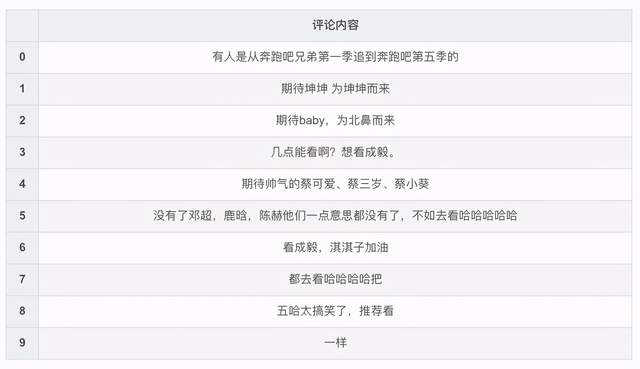
df.head(10)
![]()
![]()
数据预览
查看数据信息
print('共有评论数:',df.shape[0],'条')
![]()
共有评论数:21307 条
df.info()
df['评论内容'] = df['评论内容'].astype('str')
![]()
<class 'pandas.core.frame.DataFrame'>
Int64Index:21307 entries, 0 to 11833
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 评论内容 21199 non-null object
dtypes: object(1)
memory usage: 332.9+ KB
![]()
删除重复评论
df = df.drop_duplicates()
![]()
删除缺失数据
df = df.dropna()
![]()
增加评论类型
人为划分评论类型,20字以下为短评,20-50字为中评,50字以上为长评。
cut = lambda x : '短评'if len(x) <= 20else ('中评'if len(x) <=50else'长评')
df['评论类型'] = df['评论内容'].map(cut)
![]()
提取演员关键词
根据评论内容关键词,提取出人物提及字段。
tmp=[]
for i in df["评论内容"]:
if"黑牛"in i:
tmp.append("李晨")
elif"杨颖"in i:
tmp.append("杨颖")
elif"沙溢"in i:
tmp.append("沙溢")
elif"坤"in i:
tmp.append("蔡徐坤")
elif"毅"in i:
tmp.append("成毅")
elif"一桐"in i:
tmp.append("李一桐")
else:
tmp.append("其他")
df['人物提及'] = tmp
![]()
机械压缩去重
定义一个机械压缩函数:
def yasuo(st):
for i in range(1,int(len(st)/2)+1):
for j in range(len(st)):
if st[j:j+i] == st[j+i:j+2*i]:
k = j + i
while st[k:k+i] == st[k+i:k+2*i] and k<len(st):
k = k + i
st = st[:j] + st[k:]
return st
yasuo(st="123")
![]()
调用函数,对评论内容进行机械压缩去重:
df["评论内容"] = df["评论内容"].apply(yasuo)
![]()
特殊字符处理
用正则表达式提取出中文:
df['评论内容'] = df['评论内容'].str.extract(r"([\u4e00-\u9fa5]+)")
df = df.dropna() #纯表情弹幕直接删除
![]()
过滤掉评论字数少于四个字的评论:
df = df[df["评论内容"].apply(len)>=4]
df = df.dropna()
![]()
数据可视化
整体评论情况
# 绘制词云图
text1 = get_cut_words(content_series=df['评论内容'])
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=1000,
collocations=False,
font_path='演示悠然小楷.ttf',
icon_name='fas fa-video',
size=653,
#palette='matplotlib.Inferno_9',
output_name='./评论.png')
Image(filename='./评论.png')
![]()

![]()
通过对所有评论进行词云图绘制,我们发现「成毅」提及最多,对于最新跑男的看法,大家表现出非一致的看法。有人说「好看、喜欢」,有人说「没意思」。另外,评论中还多次提到往期节目中的嘉宾,如「陈赫、郑凯、郭麒麟」等,没有比较就没有伤害,很多人还是更喜欢往期的跑男的。
评论类型分布
df2 = df.groupby('评论类型')['评论内容'].count()
df2 = df2.sort_values(ascending=False)
regions = df2.index.to_list()
values = df2.to_list()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
.add("", zip(regions,values),radius=["40%", "70%"])
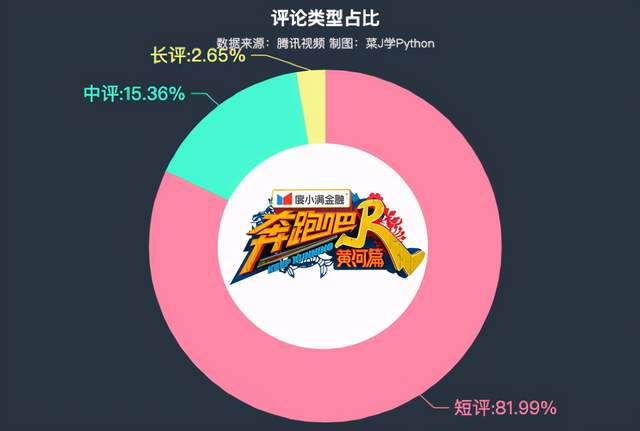
.set_global_opts(title_opts=opts.TitleOpts(title="评论类型占比",subtitle="数据来源:腾讯视频",pos_top="2%",pos_left = 'center'))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18))
)
c.render_notebook()
![]()
![]()
短评占据「81.99%」,仅有2.65%的观众给出了50字以上的评论。
演员角色提及
df8 = df["人物提及"].value_counts(ascending=True)[:6]
print(df8.index.to_list())
print(df8.to_list())
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
.add_xaxis(df8.index.to_list())
.add_yaxis("",df8.to_list()).reversal_axis()
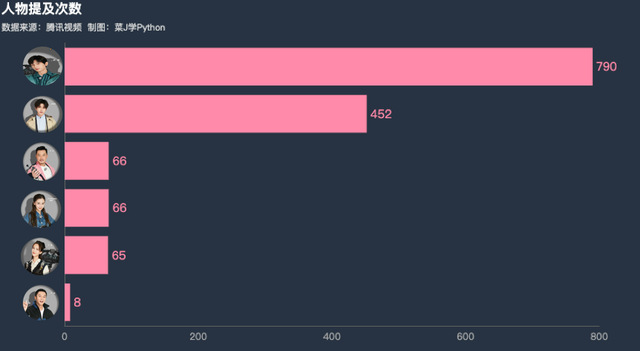
.set_global_opts(title_opts=opts.TitleOpts(title="人物提及次数",subtitle="数据来源:腾讯视频 ",pos_left = 'top'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()
![]()
![]()
image
新成员「成毅」被观众提及次数最多,达到790次,其次是「蔡徐坤」,被提及452次。李晨被提及次数最少。
成毅评论词云
cy = df[df["人物提及"]=="成毅"]
text = get_cut_words(content_series=cy['评论内容'])
stylecloud.gen_stylecloud(text=' '.join(text), max_words=500,
collocations=False,
font_path='演示悠然小楷.ttf',
icon_name='fas fa-comments',
#palette='matplotlib.Inferno_9',
size=653,
output_name='./dinghui.png')
Image(filename='./dinghui.png')
![]()

![]()
成毅在新一季跑男的表现被网友广泛议论,认可他的观众「喜欢、期待、可爱」他的表现。也有相当多的观众觉得他「智商」有问题,是个「游戏黑洞」,而且很「搞笑」。
想要获取更多Python学习资料可以加
QQ:2955637827私聊
或加Q群630390733
大家一起来学习讨论吧!
Python爬取跑男的评论,看看大家都在看谁吧的更多相关文章
- 一篇文章教会你用Python爬取淘宝评论数据(写在记事本)
[一.项目简介] 本文主要目标是采集淘宝的评价,找出客户所需要的功能.统计客户评价上面夸哪个功能多,比如防水,容量大,好看等等. 很多人学习python,不知道从何学起.很多人学习python,掌握了 ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- 【Python爬虫案例学习】Python爬取天涯论坛评论
用到的包有requests - BeautSoup 我爬的是天涯论坛的财经论坛:'http://bbs.tianya.cn/list.jsp?item=develop' 它里面的其中的一个帖子的URL ...
- python爬取知乎评论
点击评论,出现异步加载的请求 import json import requests from lxml import etree from time import sleep url = " ...
- python 爬取简书评论
import json import requests from lxml import etree from time import sleep url = "https://www.ji ...
- python制作爬虫爬取京东商品评论教程
作者:蓝鲸 类型:转载 本文是继前2篇Python爬虫系列文章的后续篇,给大家介绍的是如何使用Python爬取京东商品评论信息的方法,并根据数据绘制成各种统计图表,非常的细致,有需要的小伙伴可以参考下 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- Python爬取淘宝店铺和评论
1 安装开发需要的一些库 (1) 安装mysql 的驱动:在Windows上按win+r输入cmd打开命令行,输入命令pip install pymysql,回车即可. (2) 安装自动化测试的驱动s ...
- Python学习-使用Python爬取陈奕迅新歌《我们》网易云热门评论
<后来的我们>上映也有好几天了,一直没有去看,前几天还爆出退票的事件,电影的主题曲由陈奕迅所唱,特地找了主题曲<我们>的MV看了一遍,还是那个感觉.那天偶然间看到Python中 ...
随机推荐
- 学习django笔记一:在urls.py中导入sign应用views文件的问题
>python-admin startproject guest #创建guest项目 >python3 manage.py startapp sign #在guest项目中创建 ...
- 从执行上下文角度重新理解.NET(Core)的多线程编程[2]:同步上下文
一般情况下,我们可以将某项操作分发给任意线程来执行,但有的操作确实对于执行的线程是有要求的,最为典型的场景就是:GUI针对UI元素的操作必须在UI主线程中执行.将指定的操作分发给指定线程进行执行的需求 ...
- Windows启用SSH命令
前言 直接通过windows自带的CMD终端远程连接服务器,需要先安装好OpenSSH客户端. 安装 使用浏览器打开官网: https://www.mls-software.com/opensshd. ...
- selenium调用JS实现自动化
webdriver自带的api使用起来有局限性,比如下拉滚动条文本框输入,以及一些弹出框的操作,使用JS直接操作方便又灵活. 一:示例 from selenium import webdriver f ...
- 【AcWing 99】激光炸弹——二维前缀和
(题面来自AcWing) 一种新型的激光炸弹,可以摧毁一个边长为 R 的正方形内的所有的目标. 现在地图上有 N 个目标,用整数Xi,Yi表示目标在地图上的位置,每个目标都有一个价值Wi. 激光炸弹的 ...
- 【原创】视频+文字:详解VBA解决数独问题
[说在前面]: 之前,我在微信朋友圈看到一个同事发了一个状态,说的是她在家辅导孩子做作业,一个数独的题目,好像没有做出来.我看了下,我也做不出来,后来仔细想了下,花了两个多小时时间,用Python编了 ...
- 干货分享:盘点那些最常用的Linux命令,需熟记!
- C语言常用的一些转换工具函数!
1.字符串转十六进制 代码实现: 2.十六进制转字符串 代码实现: 或者 效果:十六进制:0x13 0xAA 0x02转为字符串:"13AAA2" 3.字符串转十进制 代码实现: ...
- 「刷题笔记」哈希,kmp,trie
Bovine Genomics 暴力 str hash+dp 设\(dp[i][j]\)为前\(i\)组匹配到第\(j\)位的方案数,则转移方程 \[dp[i][j+l]+=dp[i-1][j] \] ...
- 微软发布 Pylance:改善 VS Code 中的 Python 体验
原标题:微软发布 Pylance:改善 VS Code 中的 Python 体验 来源:开源中国 微软宣布推出一种新的 Python 语言服务器,名为 Pylance,其可利用语言服务器协议与 VS ...