go-zero 是如何追踪你的请求链路的
go-zero 是如何追踪你的请求链路
微服务架构中,调用链可能很漫长,从 http 到 rpc ,又从 rpc 到 http 。而开发者想了解每个环节的调用情况及性能,最佳方案就是 全链路跟踪。
追踪的方法就是在一个请求开始时生成一个自己的 spanID ,随着整个请求链路传下去。我们则通过这个 spanID 查看整个链路的情况和性能问题。
下面来看看 go-zero 的链路实现。
代码结构
- spancontext:保存链路的上下文信息「traceid,spanid,或者是其他想要传递的内容」
- span:链路中的一个操作,存储时间和某些信息
- propagator:
trace传播下游的操作「抽取,注入」 - noop:实现了空的
tracer实现
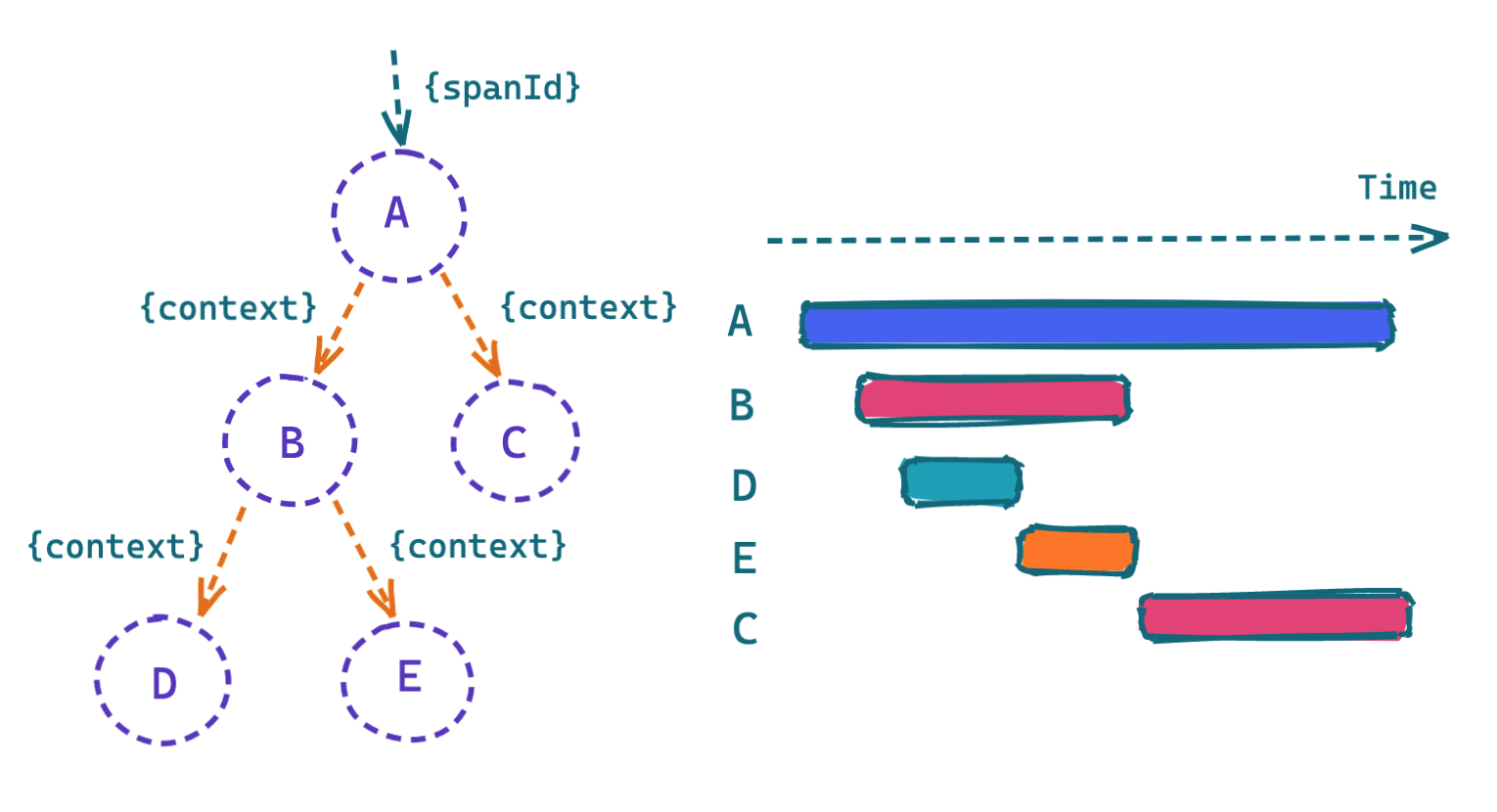
概念
SpanContext
在介绍 span 之前,先引入 context 。SpanContext 保存了分布式追踪的上下文信息,包括 Trace id,Span id 以及其它需要传递到下游的内容。OpenTracing 的实现需要将 SpanContext 通过某种协议 进行传递,以将不同进程中的 Span 关联到同一个 Trace 上。对于 HTTP 请求来说,SpanContext 一般是采用 HTTP header 进行传递的。
下面是 go-zero 默认实现的 spanContext
type spanContext struct {
traceId string // TraceID 表示tracer的全局唯一ID
spanId string // SpanId 标示单个trace中某一个span的唯一ID,在trace中唯一
}
同时开发者也可以实现 SpanContext 提供的接口方法,实现自己的上下文信息传递:
type SpanContext interface {
TraceId() string // get TraceId
SpanId() string // get SpanId
Visit(fn func(key, val string) bool) // 自定义操作TraceId,SpanId
}
Span
一个 REST 调用或者数据库操作等,都可以作为一个 span 。 span 是分布式追踪的最小跟踪单位,一个 Trace 由多段 Span 组成。追踪信息包含如下信息:
type Span struct {
ctx spanContext // 传递的上下文
serviceName string // 服务名
operationName string // 操作
startTime time.Time // 开始时间戳
flag string // 标记开启trace是 server 还是 client
children int // 本 span fork出来的 childsnums
}
从 span 的定义结构来看:在微服务中, 这就是一个完整的子调用过程,有调用开始 startTime ,有标记自己唯一属性的上下文结构 spanContext 以及 fork 的子节点数。
实例应用
在 go-zero 中http,rpc中已经作为内置中间件集成。我们以 http,rpc 中,看看 tracing 是怎么使用的:
HTTP
func TracingHandler(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// **1**
carrier, err := trace.Extract(trace.HttpFormat, r.Header)
// ErrInvalidCarrier means no trace id was set in http header
if err != nil && err != trace.ErrInvalidCarrier {
logx.Error(err)
}
// **2**
ctx, span := trace.StartServerSpan(r.Context(), carrier, sysx.Hostname(), r.RequestURI)
defer span.Finish()
// **5**
r = r.WithContext(ctx)
next.ServeHTTP(w, r)
})
}
func StartServerSpan(ctx context.Context, carrier Carrier, serviceName, operationName string) (
context.Context, tracespec.Trace) {
span := newServerSpan(carrier, serviceName, operationName)
// **4**
return context.WithValue(ctx, tracespec.TracingKey, span), span
}
func newServerSpan(carrier Carrier, serviceName, operationName string) tracespec.Trace {
// **3**
traceId := stringx.TakeWithPriority(func() string {
if carrier != nil {
return carrier.Get(traceIdKey)
}
return ""
}, func() string {
return stringx.RandId()
})
spanId := stringx.TakeWithPriority(func() string {
if carrier != nil {
return carrier.Get(spanIdKey)
}
return ""
}, func() string {
return initSpanId
})
return &Span{
ctx: spanContext{
traceId: traceId,
spanId: spanId,
},
serviceName: serviceName,
operationName: operationName,
startTime: timex.Time(),
// 标记为server
flag: serverFlag,
}
}
将 header -> carrier,获取 header 中的traceId等信息
开启一个新的 span,并把「traceId,spanId」封装在context中
从上述的 carrier「也就是header」获取traceId,spanId。
- 看header中是否设置
- 如果没有设置,则随机生成返回
从
request中产生新的ctx,并将相应的信息封装在 ctx 中,返回从上述的 context,拷贝一份到当前的
request
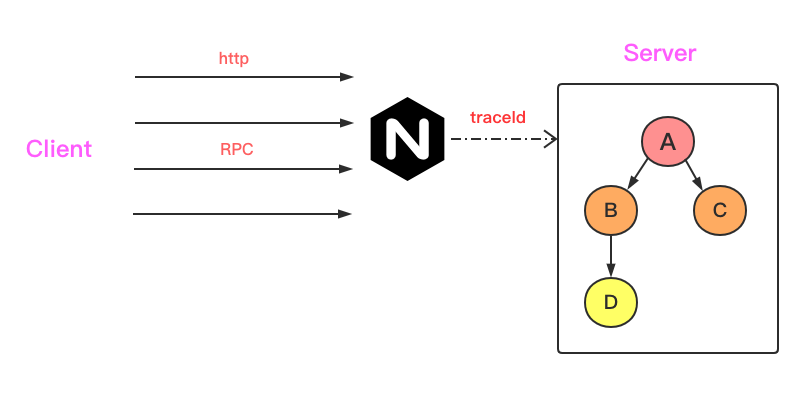
这样就实现了 span 的信息随着 request 传递到下游服务。
RPC
在 rpc 中存在 client, server ,所以从 tracing 上也有 clientTracing, serverTracing 。 serveTracing 的逻辑基本与 http 的一致,来看看 clientTracing 是怎么使用的?
func TracingInterceptor(ctx context.Context, method string, req, reply interface{},
cc *grpc.ClientConn, invoker grpc.UnaryInvoker, opts ...grpc.CallOption) error {
// open clientSpan
ctx, span := trace.StartClientSpan(ctx, cc.Target(), method)
defer span.Finish()
var pairs []string
span.Visit(func(key, val string) bool {
pairs = append(pairs, key, val)
return true
})
// **3** 将 pair 中的data以map的形式加入 ctx
ctx = metadata.AppendToOutgoingContext(ctx, pairs...)
return invoker(ctx, method, req, reply, cc, opts...)
}
func StartClientSpan(ctx context.Context, serviceName, operationName string) (context.Context, tracespec.Trace) {
// **1**
if span, ok := ctx.Value(tracespec.TracingKey).(*Span); ok {
// **2**
return span.Fork(ctx, serviceName, operationName)
}
return ctx, emptyNoopSpan
}
- 获取上游带下来的 span 上下文信息
- 从获取的 span 中创建新的 ctx,span「继承父span的traceId」
- 将生成 span 的data加入ctx,传递到下一个中间件,流至下游
总结
go-zero 通过拦截请求获取链路traceID,然后在中间件函数入口会分配一个根Span,然后在后续操作中会分裂出子Span,每个span都有自己的具体的标识,Finsh之后就会汇集在链路追踪系统中。
开发者可以通过 ELK 工具追踪 traceID ,看到整个调用链。同时 go-zero 并没有提供整套 trace 链路方案,开发者可以封装 go-zero 已有的 span 结构,做自己的上报系统,接入 jaeger, zipkin 等链路追踪工具。
参考
go-zero 是如何追踪你的请求链路的的更多相关文章
- SpringCloud(八)Sleuth 分布式请求链路跟踪
SpringCloud Sleuth 分布式请求链路跟踪 概述 为什么会出现这个技术?需要解决哪些问题? 在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后 ...
- 【应用程序见解 Application Insights】Application Insights 使用 Application Maps 构建请求链路视图
Applicaotn Insigths 使用 Application Maps 构建请求链路视图 构建系统时,请求的逻辑操作大多数情况下都需要在不同的服务,或接口中完成整个请求链路.一个请求可以经历 ...
- SpringCloud微服务(07):Zipkin组件,实现请求链路追踪
本文源码:GitHub·点这里 || GitEE·点这里 一.链路追踪简介 1.Sleuth组件简介 Sleuth是SpringCloud微服务系统中的一个组件,实现了链路追踪解决方案.可以定位一个请 ...
- 部署Zipkin分布式性能追踪日志系统的操作记录
Zipkin是Twitter的一个开源项目,是一个致力于收集Twitter所有服务的监控数据的分布式跟踪系统,它提供了收集数据,和查询数据两大接口服务. 部署Zipkin环境的操作记录:部署Zipki ...
- PHP中使用CURL实现GET和POST请求
转自:http://www.smsyun.com/home-index-page-id-284.html 一.什么是CURL? cURL 是一个利用URL语法规定来传输文件和数据的工具,支持很多协议, ...
- SpringCloud(7)服务链路追踪Spring Cloud Sleuth
1.简介 Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案,并且兼容支持了 zipkin,你只需要在pom文件中引入相应的依赖即可.本文主要讲述服务追踪组件zipki ...
- (转)python爬虫:http请求头部(header)详解
本文根据RFC2616(HTTP/1.1规范),参考 http://www.w3.org/Protocols/rfc2068/rfc2068 http://www.w3.org/Protocols/r ...
- curl get请求添加header头信息
function get($url) { $ch = curl_init(); curl_setopt($ch, CURLOPT_HTTPGET, true); curl_setopt($ch, CU ...
- PHP的curl查看header信息的功能(包括查看返回header和请求header)
PHP的curl功能十分强大,简单点说,就是一个PHP实现浏览器的基础. 最常用的可能就是抓取远程数据或者向远程POST数据.但是在这个过程中,调试时,可能会有查看header的必要. 如下: ech ...
随机推荐
- git push 提交时出错 the remote end hung up unexpectedly
错误原因 与远程服务的连接中断,但是检查发现origin还在,可能是文件太大,缓存不够,增加缓存大小 解决方案 专案目录 >.git >config 在末尾增加如下代码 [http] po ...
- 使用VS2015从TFS获取项目后编译报错
把VS2015关闭后,打开C:\Windows\Temp,把里面的文件清空后,重新打开VS即可.
- [Vue warn]: Error in render: "TypeError: Cannot read property 'matched' of undefined" found in <App> at src/App.vue
当用Vue模块化开发时,输入 http://localhost:8080 页面没有显示,首先按F12,检查是否有如下错误 话不多说,直接看下面: 解决方法1 如果是上面出的问题,以后就要注意了哦, ...
- matlab中num2str 将数字转换为字符数组
参考:https://ww2.mathworks.cn/help/matlab/ref/num2str.html?searchHighlight=num2str&s_tid=doc_srcht ...
- OpenCV图像加载与保存
OpenCV中的图像加载与保存 头文件是包含的库,在GitHub上下载的 imread("图片路径",图片加载方式) 图片加载方式: IMREAD_GRAYSCALE 灰度图像 I ...
- Springboot集成logback,控制台日志打印两次,并且是不同的线程打印的
背景 在搭建一个新项目的时候,从公司别的项目搞了个logback-spring.xml的配置过来,修改一下启动项目的时候发现 所有的日志都输出了两次 并且来自于不同的线程,猜测是配置重复了,但是仔细检 ...
- Consul 快速入门
Consul是什么 Consul是一个服务网格(微服务间的 TCP/IP,负责服务之间的网络调用.限流.熔断和监控)解决方案,它是一个一个分布式的,高度可用的系统,而且开发使用都很简便.它提供了一个功 ...
- JVM 第六篇:极致优化 IDEA 启动速度
本文内容过于硬核,建议有 Java 相关经验人士阅读. 1. 引言 相信做 Java 开发的同学,对 IDEA 这个工具应该都不陌生,即使不使用 IDEA 做开发,那么对 Eclipse 这个工具应该 ...
- MeteoInfoLab脚本示例:Maskout图形
Maskout通常有两种类型:Maskout图形和Maskout数据.这里是Maskout图形的示例.需要用shaperead读取地图数据形成图层作为Maskout图层(这里是中国的行政区域china ...
- day49 Pyhton 数据库Mysql 06
多表查询 连表查询 要进行连接,那一定涉及两个表,两个表中要有关联条件才能进行连接 内连接 只有表一和表二中的连接条件都满足的时候才能显示出来 inner join on /where 条件 sele ...