MapReduce之自定义OutputFormat
@
OutputFormat接口实现类
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了OutputFormat接口。下面介绍几种常见的OutputFormat实现类。
文本输出
TextoutputFormat
默认的输出格式是TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把它们转换为字符串。SequenceFileOutputFormat
将SecquenceFileOutputFormat输出作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。自定义OutputFormat
根据用户需求,自定义实现输出。
自定义OutputFormat使用场景及步骤
使用场景
- 为了实现控制最终文件的输出路径和输出格式,可以自定义OutputFormat。
例如:要在一个MapReduce程序中根据数据的不同输出两类结果到不同目录,这类灵活的输出需求可以通过自定义OutputFormat来实现。 - 自定义OutputFormat步骤
(1)自定义一个类继承FileOutputFormat。
(2)改写RecordWriter,具体改写输出数据的方法write()。
自定义OutputFormat 案例实操
需求
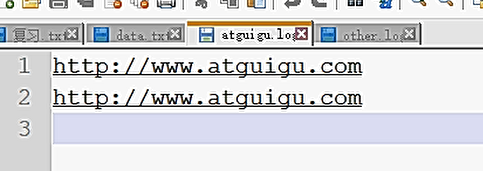
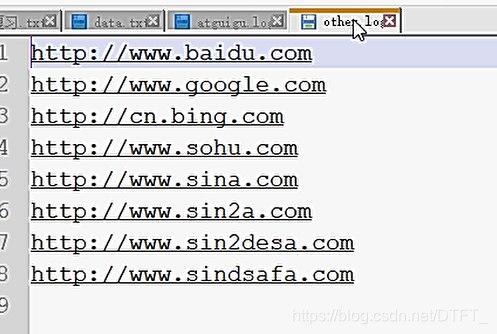
过滤输入的log日志,包含atguigu的网站输出到e:/atguigu.log,不包含atguigu的网站输出到e:/other.log。
输入数据

什么时候需要Reduce
①合并
②需要对数据排序
所以本案例不需要Reduce阶段,key-value不需要实现序列化
CustomOFMapper.java
public class CustomOFMapper extends Mapper<LongWritable, Text, String, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, String, NullWritable>.Context context) throws IOException, InterruptedException {
String content = value.toString();
//value不需要,但是不能用Null这个关键字,要使用NullWritable对象
context.write(content+"\r\n", NullWritable.get());
}
}
MyOutPutFormat.java
public class MyOutPutFormat extends FileOutputFormat<String, NullWritable>{
@Override
public RecordWriter<String, NullWritable> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException {
return new MyRecordWriter(job);//传递job对象,才能在RecordWriter中获取配置
}
}
MyRecordWriter.java
public class MyRecordWriter extends RecordWriter<String, NullWritable> {
private Path atguiguPath=new Path("e:/atguigu.log");
private Path otherPath=new Path("e:/other.log");
private FSDataOutputStream atguguOS ;
private FSDataOutputStream otherOS ;
private FileSystem fs;
private TaskAttemptContext context;
public MyRecordWriter(TaskAttemptContext job) throws IOException {
context=job;
Configuration conf = job.getConfiguration();
fs=FileSystem.get(conf);
atguiguOS = fs.create(atguiguPath);
otherOS = fs.create(otherPath);
}
// 将key-value写出到文件
@Override
public void write(String key, NullWritable value) throws IOException, InterruptedException {
if (key.contains("atguigu")) {
atguguOS.write(key.getBytes());//写到atguigu.log
//统计输出的含有atguigu字符串的key-value个数
context.getCounter("MyCounter", "atguiguCounter").increment(1);
}else {
otherOS.write(key.getBytes());//写到other.log
context.getCounter("MyCounter", "otherCounter").increment(1);
}
}
// 关闭流
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
if (atguguOS != null) {
IOUtils.closeStream(atguguOS);
}
if (otherOS != null) {
IOUtils.closeStream(otherOS);
}
if (fs != null) {
fs.close();
}
}
}
CustomOFDriver.java
public class CustomOFDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("e:/mrinput/outputformat");
Path outputPath=new Path("e:/mroutput/outputformat");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
//重点,设置为自定义的输出格式
job.setJarByClass(CustomOFDriver.class);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(CustomOFMapper.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置输入和输出格式
job.setOutputFormatClass(MyOutPutFormat.class);
// 取消reduce阶段。设置为0,默认为1
job.setNumReduceTasks(0);
// ③运行Job
job.waitForCompletion(true);
}
}
输出文件:
MapReduce之自定义OutputFormat的更多相关文章
- 第3节 mapreduce高级:7、自定义outputformat实现输出到不同的文件夹下面
2.1 需求 现在有一些订单的评论数据,需求,将订单的好评与差评进行区分开来,将最终的数据分开到不同的文件夹下面去,数据内容参见资料文件夹,其中数据第九个字段表示好评,中评,差评.0:好评,1:中评, ...
- Hadoop案例(五)过滤日志及自定义日志输出路径(自定义OutputFormat)
过滤日志及自定义日志输出路径(自定义OutputFormat) 1.需求分析 过滤输入的log日志中是否包含xyg (1)包含xyg的网站输出到e:/xyg.log (2)不包含xyg的网站输出到e: ...
- Hadoop_27_MapReduce_运营商原始日志增强(自定义OutputFormat)
1.需求: 现有一些原始日志需要做增强解析处理,流程: 1. 从原始日志文件中读取数据(日志文件:https://pan.baidu.com/s/12hbDvP7jMu9yE-oLZXvM_g) 2. ...
- hadoop 自定义OutputFormat
1.继承FileOutputFormat,复写getRecordWriter方法 /** * @Description:自定义outputFormat,输出数据到不同的文件 */ public cla ...
- 关于spark写入文件至文件系统并制定文件名之自定义outputFormat
引言: spark项目中通常我们需要将我们处理之后数据保存到文件中,比如将处理之后的RDD保存到hdfs上指定的目录中,亦或是保存在本地 spark保存文件: 1.rdd.saveAsTextFile ...
- 关于MapReduce中自定义分区类(四)
MapTask类 在MapTask类中找到run函数 if(useNewApi){ runNewMapper(job, splitMetaInfo, umbilical, reporter ...
- 关于MapReduce中自定义分组类(三)
Job类 /** * Define the comparator that controls which keys are grouped together * for a single ...
- 关于MapReduce中自定义带比较key类、比较器类(二)——初学者从源码查看其原理
Job类 /** * Define the comparator that controls * how the keys are sorted before they * are pa ...
- 关于MapReduce中自定义Combine类(一)
MRJobConfig public static fina COMBINE_CLASS_ATTR 属性COMBINE_CLASS_ATTR = "mapreduce.j ...
随机推荐
- 数据结构之二叉搜索树(BST)--JavaScript实现
原理: 叉排序树的查找过程和次优二叉树类似,通常采取二叉链表作为二叉排序树的存储结构.中序遍历二叉排序树可得到一个关键字的有序序列,一个无序序列可以通过构造一棵二叉排序树变成一个有序序列,构造树的过程 ...
- Redis安装与运行讲解
第一步:安装Redis 打开网址:https://github.com/MicrosoftArchive/redis/releases 因为版本比较多,最新版已经是3.2.100,我们选择3.0.50 ...
- scala 数据结构(二):数组
1 数组-定长数组(声明泛型) 第一种方式定义数组 这里的数组等同于Java中的数组,中括号的类型就是数组的类型 val arr1 = new Array[Int](10) //赋值,集合元素采用小括 ...
- scrapy 基础组件专题(六):自定义命令
写好自己的爬虫项目之后,可以自己定制爬虫运行的命令. 一.单爬虫 在项目的根目录下新建一个py文件,如命名为start.py,写入如下代码: from scrapy.cmdline import ex ...
- Python并发编程01 /操作系统发展史、多进程理论
Python并发编程01 /操作系统发展史.多进程理论 目录 Python并发编程01 /操作系统发展史.多进程理论 1. 操作系统 2. 进程理论 1. 操作系统 定义:管理控制协调计算机中硬件与软 ...
- 响应式布局rem、rem方法封装、移动端响应式布局
相信大家在做移动端的时候都会做各个手机的适配这种适配就是响应式布局在之前做网站的响应式从pc到手机用的是媒体查询 @media screen and (max-width: 300px){} 最大宽度 ...
- VMWare WorkStation中MacOS虛擬機無法啓動的問題
關於MacOS虛擬機,在有VMWare重裝,升級以及MacOS更新時,都可能會造成破解補丁失效,因此儅Mac虛擬機無法啓動時,可以嘗試以下操作: 重新運行unlocker208中的win-instal ...
- Cyber Security - Palo Alto Security Policies(1)
Security policies: Enforcing network traffic by configuring rules of what is allowed or denied to co ...
- xss利用
xss盗取cookie 什么是cookie cookie是曲奇饼,啊开个玩笑,cookie是每个用户登录唯一id和账号密码一样可以登录到网站,是的你没有听错cookie可以直接登录,至于服务器怎么设置 ...
- 7.CSMA协议
载波监听多路访问协议CSMA CS:载波侦听/监听,每一个站在发送数据之前要检测一下总线上是否有其他计算机在发送数据. MA:多点接入,表示许多计算机以多点接入的方式连接在一根总线上 协议思想:发送帧 ...