python-scrapy框架初探
内置支持 selecting and extracting 使用扩展的CSS选择器和XPath表达式从HTML/XML源中获取数据,并使用正则表达式提取助手方法。
interactive shell console (ipython-aware)用于尝试使用css和xpath表达式来获取数据,在编写或调试spider时非常有用。
内置支持 generating feed exports 以多种格式(json、csv、xml)存储在多个后端(ftp、s3、本地文件系统)
强大的编码支持和自动检测,用于处理外部、非标准和中断的编码声明。
Strong extensibility support ,允许您使用 signals 以及定义良好的API(中间件, extensions 和 pipelines )
广泛的内置扩展和用于处理的中间产品:
cookie和会话处理
HTTP功能,如压缩、身份验证、缓存
用户代理欺骗
robots.txt
爬行深度限制
更多
A Telnet console 用于挂接到运行在Scrapy进程中的Python控制台,以便内省和调试爬虫程序
还有其他的好东西,比如可重复使用的蜘蛛 Sitemaps 和XML/CSV源,这是 automatically downloading images (或任何其他媒体)与抓取的项目、缓存DNS解析程序等相关!
拿一个官方例子来看
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
start_urls = [
'http://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.xpath('span/small/text()').get(),
}
next_page = response.css('li.next a::attr("href")').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
这里内置了scrapy.Spider,name就是每个的名字,这个start_urls是我们开启这个项目他就会第一个发起请求的列表,他就会自动交给parse函数处理,而且我们不能改parse这个名字,这里面的response就是返回的源代码
首先是我们创建一个项目
scrapy startproject tutorial
tutorial就是我们的项目名
F:\python post\code\ScrapyT>scrapy startproject tutorial
New Scrapy project 'tutorial', using template directory 'g:\python3.8\lib\site-packages\scrapy\templates\project', created in:
F:\python post\code\ScrapyT\tutorial
You can start your first spider with:
cd tutorial
scrapy genspider example example.com
F:\python post\code\ScrapyT>
然后就是cd tutorial和scrapy genspider example example.com这里的example就是我们的要获取的网址,这里就默认
F:\python post\code\ScrapyT>cd tutorial
F:\python post\code\ScrapyT\tutorial>scrapy genspider example example.com
Created spider 'example' using template 'basic' in module:
tutorial.spiders.example
F:\python post\code\ScrapyT\tutorial>
然后我们就可以看到目录下生成了这个py文件
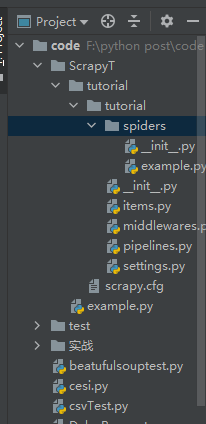
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['example.com']
start_urls = ['http://example.com/']
def parse(self, response):
pass
我们使用时候在这里修改就行了
然后我们可以看到这里生成了很多文件,首先在使用了scrapy startproject tutorial后就生成了
tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
这些内容,这个spiders文件夹是存放我们的爬虫代码的,items是用来写爬虫代码的,middlewares是一些钩子,pipelines是中间件就下载一些东西要储存在这里改,settings是一些设置一些线程多开缓存啥啥的,scrapy.cfg是如果要部署在网页上需要设置的
这里第一只蜘蛛
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
运行scrapy crawl quotes
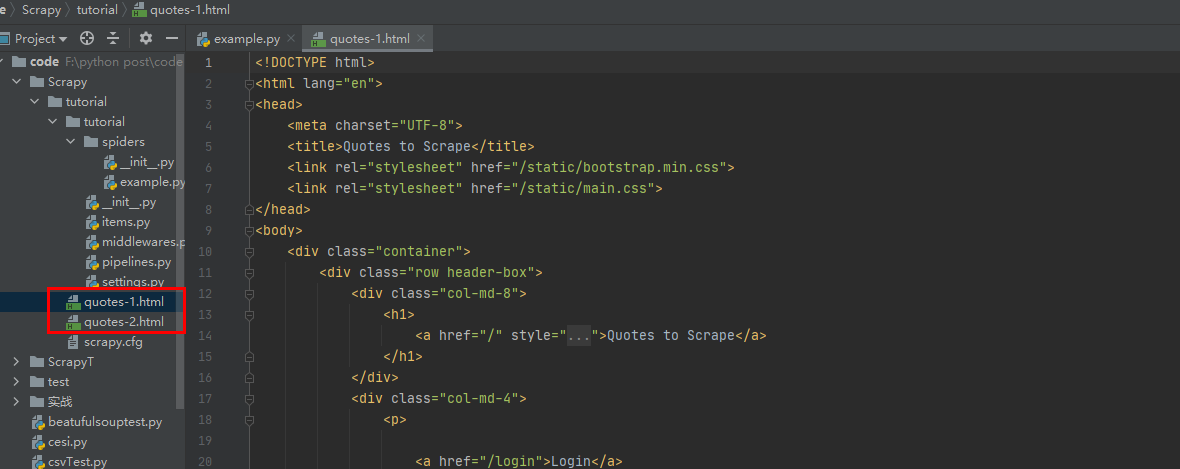
然后看下第二个
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
先看看div.quote其实就是每个div
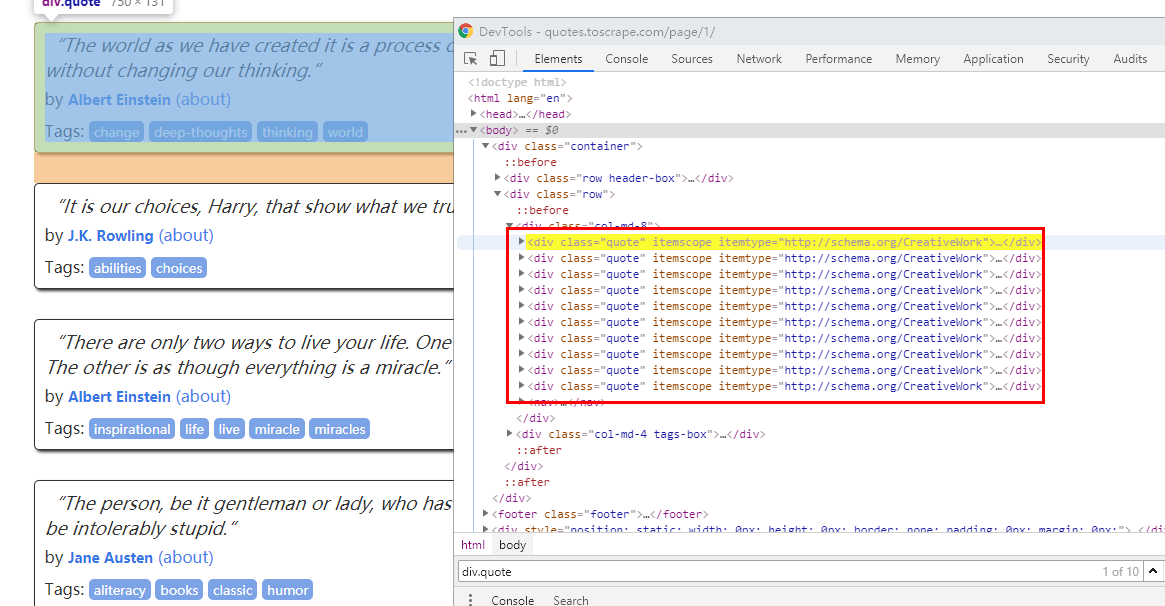
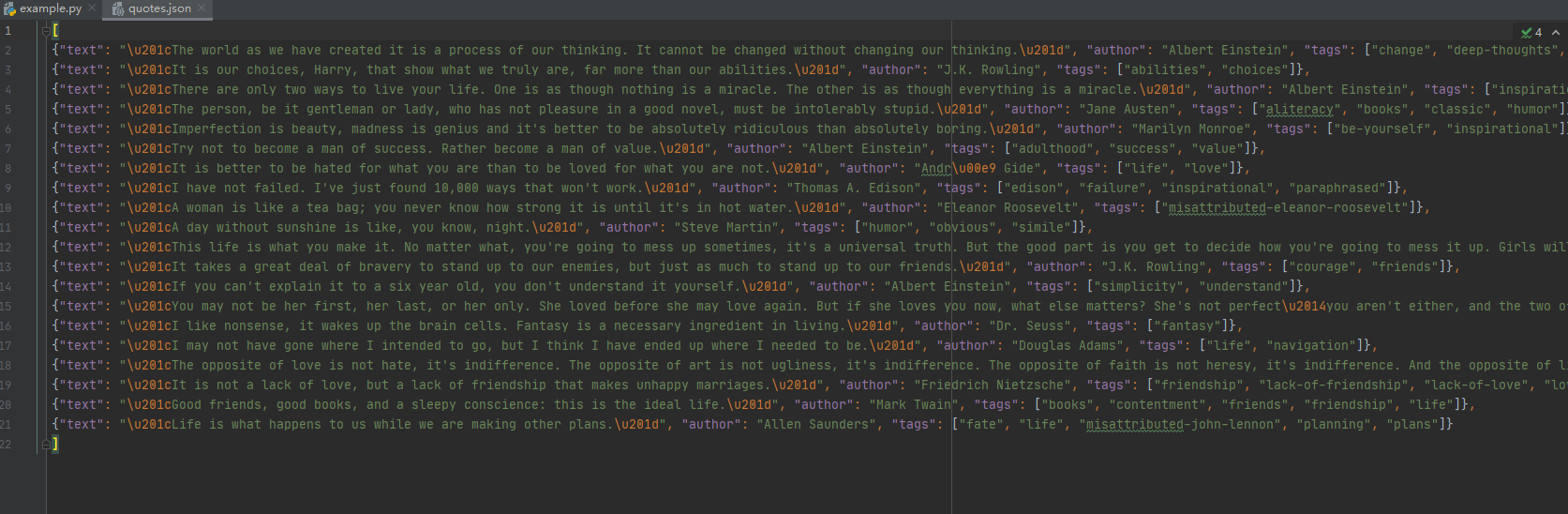
这里text 和author用get tags用getall就是因为前两个只有一个 后者有多个,如果要存储就-o就行了
scrapy crawl quotes -o quotes.json
python-scrapy框架初探的更多相关文章
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- [Python][Scrapy 框架] Python3 Scrapy的安装
1.方法(只介绍 pip 方式安装) PS.不清楚 pip(easy_install) 可以百度或留言. cmd命令: (直接可以 pip,而不用跳转到 pip.exe目录下,是因为把所在目录加入 P ...
- Scrapy框架初探
Scrapy 貌似是 Python 最出名的爬虫框架 0. 文档 中文文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.ht ...
- python scrapy框架爬虫遇到301
1.什么是状态码301 301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一.如果可能,拥有链接编 ...
- Python scrapy框架
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- Python - Scrapy 框架
Scrapy 是采用Python 开发的一个快速可扩展的抓取WEB 站点内容的爬虫框架.Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构 ...
- 我的第一篇博文,Python+scrapy框架安装。
自己用Python脚本写爬虫有一段时日了,也抓了不少网页,有的网页信息两多,一个脚本用exe跑了两个多月,数据还在进行中.但是总觉得这样抓效率有点低,问题也是多多的,很早就知道了这个框架好用,今天终于 ...
- 利用python scrapy 框架抓取豆瓣小组数据
因为最近在找房子在豆瓣小组-上海租房上找,发现搜索困难,于是想利用爬虫将数据抓取. 顺便熟悉一下Python. 这边有scrapy 入门教程出处:http://www.cnblogs.com/txw1 ...
- (19)python scrapy框架
安装scrapy pycharm 建个纯python工程 settings里 环境变量设置 C:\Python27;C:\Python27\Scripts; 下载win32api https://so ...
随机推荐
- Java不可重入锁和可重入锁的简单理解
基础知识 Java多线程的wait()方法和notify()方法 这两个方法是成对出现和使用的,要执行这两个方法,有一个前提就是,当前线程必须获其对象的monitor(俗称“锁”),否则会抛出Ille ...
- 【踩坑笔记】layui之单选和复选框不显示
直接上代码,下面前端页面代码,使用layui框架: <div class="layui-form-item"> <div class="lay ...
- 修改vsftpd的默认根目录/var/ftp/pub到另一个目录
修改ftp的根目录只要修改/etc/vsftpd/vsftpd.conf文件即可: 加入如下几行: local_root=/var/www/html chroot_local_user=YES ano ...
- OpenStack虚拟机virtaulinterfance 网络设备在libvirt的代码梳理
nova创建虚机网卡实际设备的代码调用流程为 _create_domain_and_network---->plug_vifs-->LibvirtGenericVIFDriver.plug ...
- 数据分析-RFM模型用户分析
RFM模型 根据美国数据库营销研究所Arthur Hughes的研究,客户数据库中有3个神奇的要素,这3个要素构成了数据分析最好的指标: 最近一次消费 (Recency) 消费频率 (Frequenc ...
- Gradle Wrapper
Gradle Wrapper 当把本地一个项目放入到远程版本库的时候,如果这个项目是以gradle构建的,那么其他人从远程仓库拉取代码之后如果本地没有安装过gradle会无法编译运行,如果对gradl ...
- [SCOI2013]摩托车交易 题解
思路分析 为了让交易额尽量大,显然我们需要尽量多地买入.对于每个城市,到达这个城市时携带的黄金受到几个条件的影响:之前卖出的黄金,之前能买入的最多的黄金,前一个城市到当前城市的路径上的最小边权.既然不 ...
- Git使用感悟
前言 分支介绍 我们现在开发的分支一般是这样的(基于上面那张图片的): master:上线用的 dev:开发用的 featature_xxx:开发用的 test:测试用的 hotfix:修复bug的 ...
- 8点了解Java服务端单元测试
一. 前言 单元测试并不只是为了验证你当前所写的代码是否存在问题,更为重要的是它可以很大程度的保障日后因业务变更.修复Bug或重构等引起的代码变更而导致(或新增)的风险. 同时将单元测试提前到编写正式 ...
- 快速幂 (C++)
typedef long long LL; using namespace std; //求a^b%m,递归写法 LL binaryPow(LL a,LL b,LL m){ if(b==){ //如果 ...