强化学习、分布式计算方向的phd毕业后去企业的要求
实验室慕师弟马上要phd毕业了,虽然我是遥遥无期,但是看到身边同学可以上岸还是提师弟高兴。由于师弟准备去企业工作,于是乎我也不免好奇起来phd毕业后去公司会有什么样的要求,于是网上找了找招聘信息,挑了几个不错的招聘岗位,这里mark下。
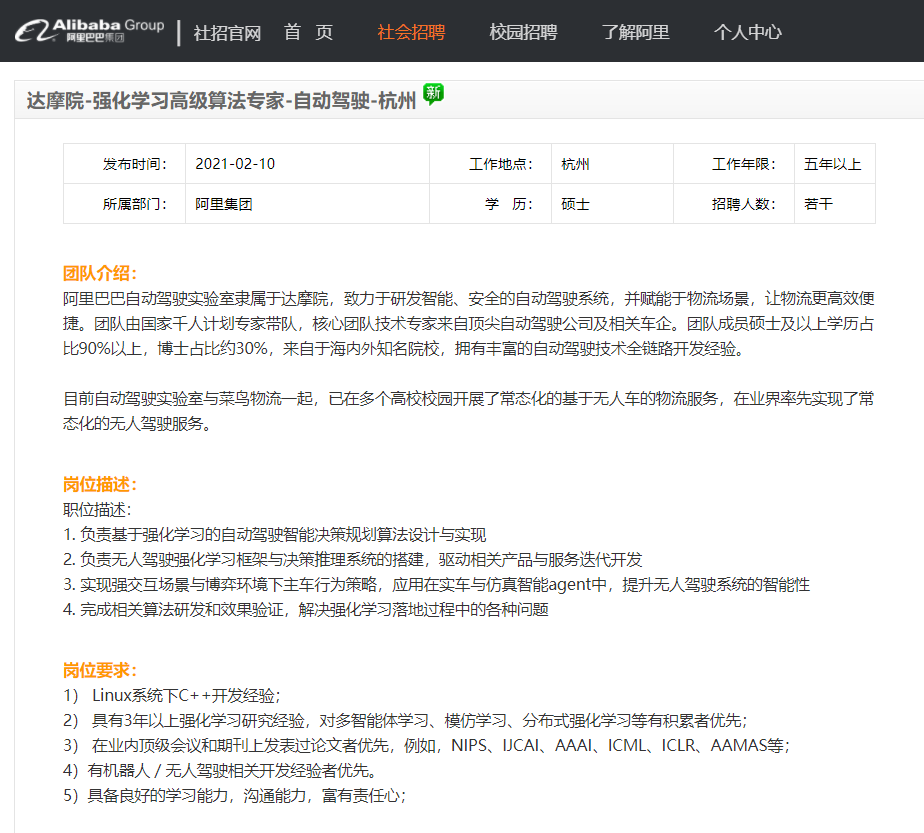
1. 强化学习方向的(自动驾驶)
虽然要求硕士学历就可以,不过看到其中的顶会论文要求便知道这个岗位也是不容易get到的。
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP705939
======================================================
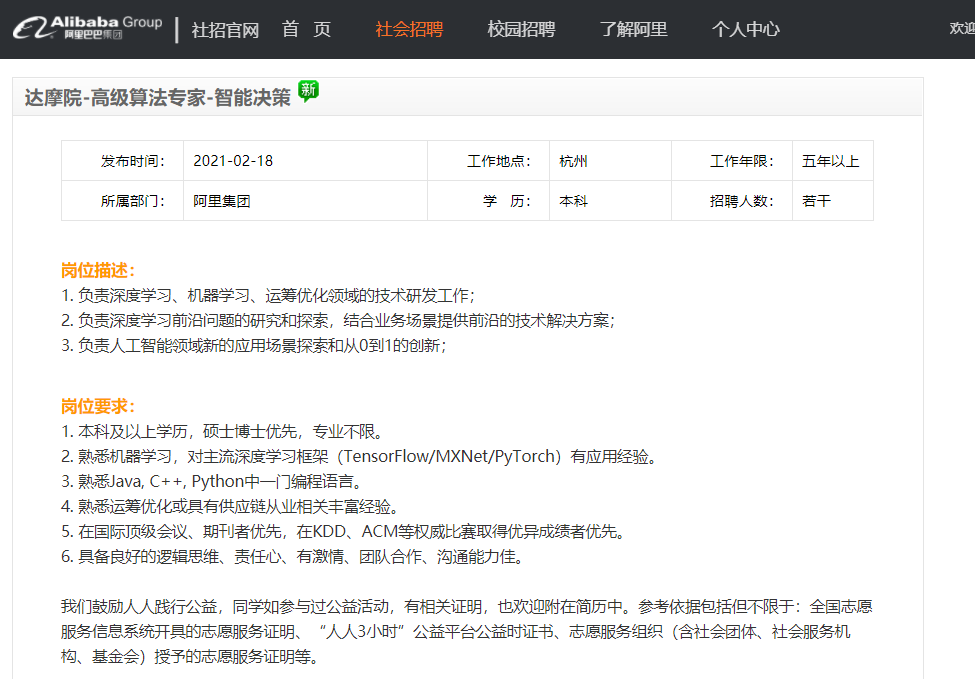
2. 智能决策方向
要求论文或比赛经历,要求比第一个貌似低些。
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP635511
=============================================
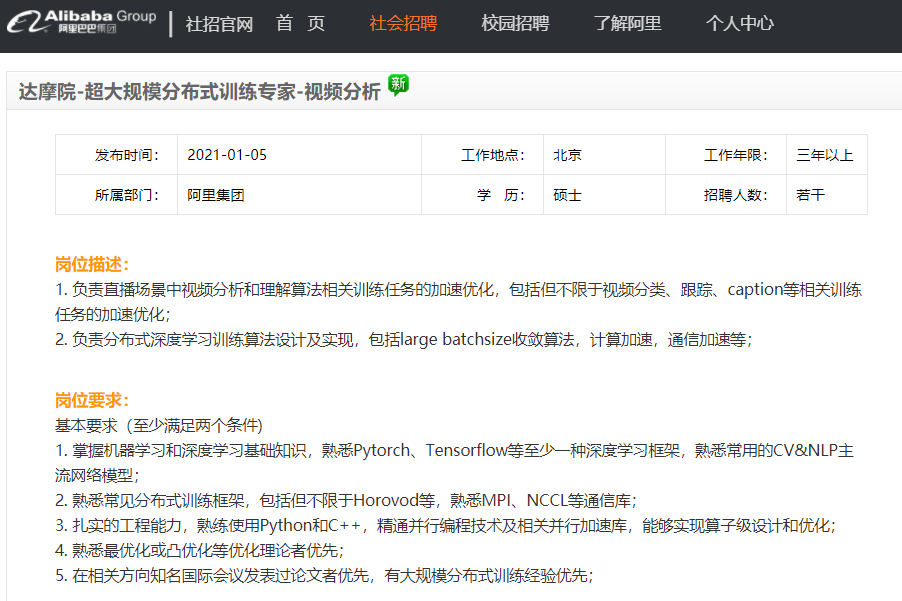
3. 分布式人工智能算法工程师
在对论文等有要求外还希望有较好的相关编程经验(分布式:MPI,NCCL等)
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP630418
============================================
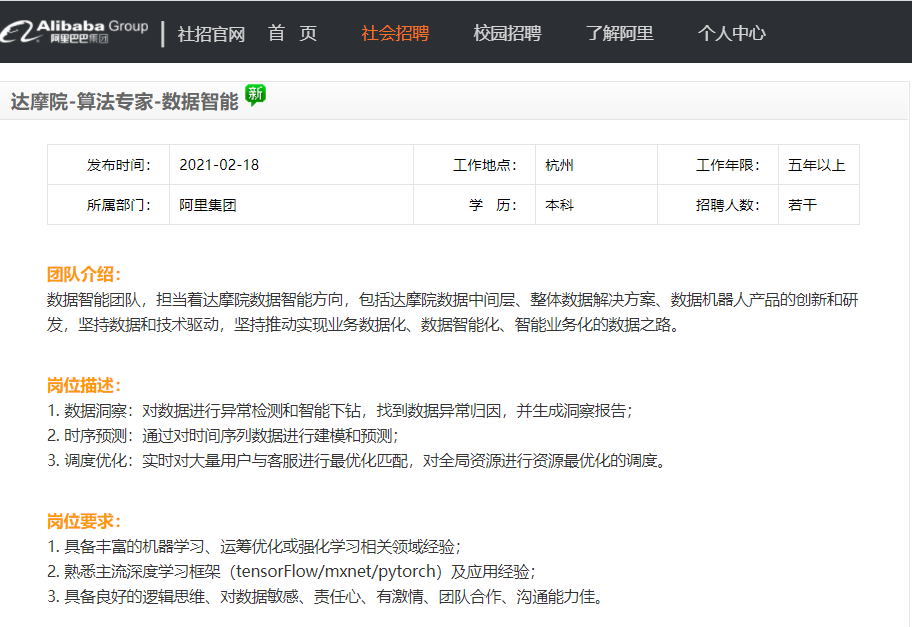
4. 数据智能
要求较低。
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP626894
===============================================
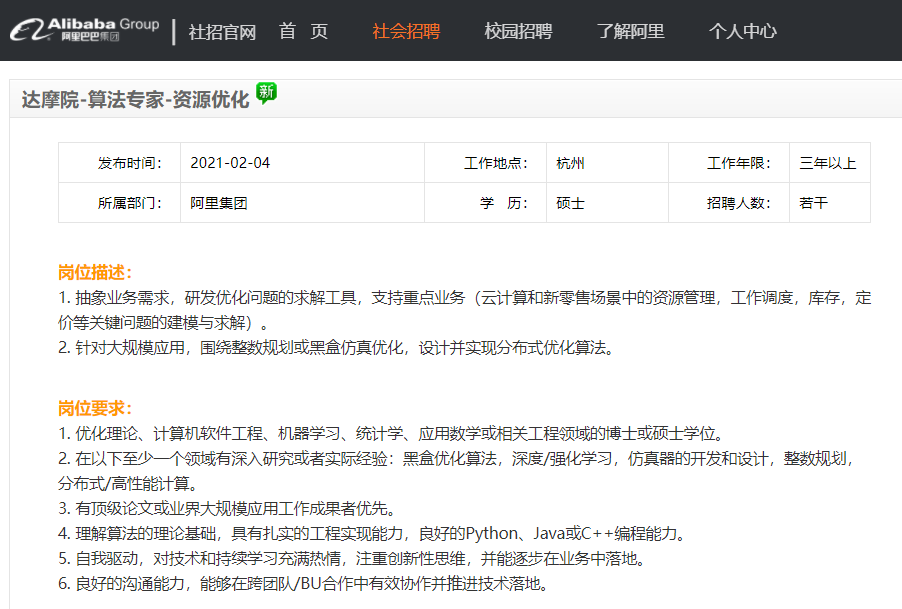
5. 资源优化( 算法工程师 )
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP634344
==============================================
强化学习、分布式计算方向的phd毕业后去企业的要求的更多相关文章
- 强化学习 1 --- 马尔科夫决策过程详解(MDP)
强化学习 --- 马尔科夫决策过程(MDP) 1.强化学习介绍 强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境 ...
- 强化学习(二)马尔科夫决策过程(MDP)
在强化学习(一)模型基础中,我们讲到了强化学习模型的8个基本要素.但是仅凭这些要素还是无法使用强化学习来帮助我们解决问题的, 在讲到模型训练前,模型的简化也很重要,这一篇主要就是讲如何利用马尔科夫决策 ...
- 强化学习 CartPole实验的一些启发 有没有可能设计一个新的实验呢?(杆子可以向360度方向倾倒,可行吗?)
最近在看强化学习方面的东西,突然想到了这么一个事情,那就是经典的CartPole游戏我们改变一下,或者说升级一下,那么使用强化学习是否能得到不错的效果呢? 原始游戏如图: 一点个人的想法: ===== ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习(十三) 策略梯度(Policy Gradient)
在前面讲到的DQN系列强化学习算法中,我们主要对价值函数进行了近似表示,基于价值来学习.这种Value Based强化学习方法在很多领域都得到比较好的应用,但是Value Based强化学习方法也有很 ...
- 强化学习(八)价值函数的近似表示与Deep Q-Learning
在强化学习系列的前七篇里,我们主要讨论的都是规模比较小的强化学习问题求解算法.今天开始我们步入深度强化学习.这一篇关注于价值函数的近似表示和Deep Q-Learning算法. Deep Q-Lear ...
- 强化学习(六)时序差分在线控制算法SARSA
在强化学习(五)用时序差分法(TD)求解中,我们讨论了用时序差分来求解强化学习预测问题的方法,但是对控制算法的求解过程没有深入,本文我们就对时序差分的在线控制算法SARSA做详细的讨论. SARSA这 ...
- 强化学习(三)用动态规划(DP)求解
在强化学习(二)马尔科夫决策过程(MDP)中,我们讨论了用马尔科夫假设来简化强化学习模型的复杂度,这一篇我们在马尔科夫假设和贝尔曼方程的基础上讨论使用动态规划(Dynamic Programming, ...
随机推荐
- C#.NET Rsa私钥加密公钥解密
在C#中,RSA私钥只能签名,不能加密,如果要加密,要借助BouncyCastle库. nuget 中引用 Portable.BouncyCastle. 工具类: RsaEncryptUtil usi ...
- python根据文件目录批量过滤空行
import shutil import os path = "E:\\in\\" #文件夹操作目录 path2 = "E:\\out\\" #文件夹输出目录 ...
- OpenCompass 作业
Smiling & Weeping ---- 愿我们都做生活的高手 -- 昭阳&乐瑶
- iOS开发之弹窗管理
前言 "千淘万漉虽辛苦,吹尽狂沙始到金."在这快速变化的互联网行业,身边的朋友有的选择了勇敢创业,有的则在技术的海洋中默默耕耘.时常在深夜反思,作为一个开发者,我们的价值何在?答案 ...
- onreadystatechange 属性
onreadystatechange 属性是 XMLHttpRequest 对象的一个事件处理器,用于在 XMLHttpRequest 对象的 readyState 属性发生变化时触发.这个属性通常用 ...
- 使用getevent在Android中调试输入子系统
# Android getevent用法详解 背景 在调试安卓设备按键,想使用hexdump,但是发现没有找到,反而找到了这个更好用的工具. 以下是我的调试片段 # getevent -l /dev/ ...
- W5100 硬件协议栈 调试经验
--- title: W5100 硬件协议栈 调试经验 date: 2020-06-21 11:22:33 categories: tags: - debug - tcpip - w5100 - su ...
- 设备树DTS 学习: 4-uboot 传递 dtb 给 内核
背景 得到 dtb 文件以后,我们需要想办法下载到 板子中,并给 Linux 内核使用. (高级版本的 uboot也有了 自己使用设备树支持,我们这里不讨论 uboot 使用的设备树) Linux 内 ...
- T3/A40i升级,推荐全志T507-H的5个理由!
作为能源电力.工业自动化领域的国产中坚力量,全志T3/A40i处理器国产平台一直深受广大客户的喜爱,甚有"国产工业鼻祖处理器"之称.自创龙科技推出T3/A40i全国产工业核心板(S ...
- map端join和reduce端join的区别
MapReduce Join MapJoin和ReduceJoin区别及优化 maptask处理后写到本地,如果再到reduce,又涉及到网络的拷贝. map端join最大优势,可以提前过滤不需要的数 ...