InfoTS: 具有信息感知增强的时间序列对比学习《Time Series Contrastive Learning with Information-Aware Augmentations》(对比学习、信息感知增强、高保真、多样性、信息论-信息瓶颈、元学习器)(没看懂,还需要再回顾)
现在是2024年5月23日,14:30,开始看论文。
论文:Time Series Contrastive Learning with Information-Aware Augmentations
或者是:Time series contrastive learning with information-aware augmentations
GitHub:https://github.com/chengw07/InfoTS
AAAI 2023的论文。
摘要
近年来,人们提出了各种对比学习方法,并取得了显著的实证成功。对比学习方法虽然有效且普遍,但对时间序列数据的探索却较少。对比学习的一个关键组成部分是选择适当的增强,施加一些先验来构建可行的正样本,这样就可以训练编码器学习稳健且具有鉴别力的表征。在图像和语言领域,"所需的 "增强样本可以在人类预制先验的指导下根据经验法则生成,而时间序列增强样本的临时人工选择则不同,它们的时间结构多种多样,人类无法识别。如何找到对特定对比学习任务和数据集有意义的所需时间序列数据增强,仍然是一个未决问题。在这项工作中,我们以信息论为基础,通过鼓励高保真和多样性来解决这个问题。通过理论分析,我们得出了选择可行数据增强的标准。在此基础上,我们提出了一种新的具有信息感知增强功能的对比学习方法--InfoTS,它能为时间序列表示学习自适应地选择最佳增强功能。在各种数据集上进行的实验表明,该方法的性能极具竞争力,与领先的基线方法相比,预测任务的 MSE 降低了 12.0%,分类任务的准确率相对提高了 3.7%。
引言
现实世界中的时间序列数据具有高维、非结构化和复杂等独特特性,给数据建模带来了挑战(Yang 和 Wu,2006 年)。此外,由于没有人类可识别的模式,在现实世界的应用中,对时间序列数据进行标注要比对图像和语言进行标注难得多。这些标注限制阻碍了深度学习方法在时间序列数据上的应用,而深度学习方法通常需要大量标注数据进行训练(时序上不需要标注,因为时序数据就是自己和自己)(Eldele 等人,2021 年)。表征学习从原始时间序列中学习固定维度的嵌入,以保持其固有特征。与原始时间序列数据相比,这些表征具有更好的转移性和泛化能力。为了解决标记的局限性,对比学习方法在视觉、语言和图结构数据等多个领域的表征学习中表现出色,被广泛采用(陈等人,2020;谢等人,2019;游等人,2020)。简而言之,对比学习方法通常是训练编码器,将实例映射到一个嵌入空间,在这个空间中,不同(负)实例与相似(正)实例很容易区分开来,并对预测进行建模,使其不受应用于输入实例或隐藏状态的微小噪声的影响。
尽管对比学习有效且普遍,但在时间序列领域的探索却较少(Eldele 等人,2021 年;Franceschi、Dieuleveut 和 Jaggi,2019 年;Fan、Zhang 和 Gao,2020 年;Tonekaboni、Eytan 和 Goldenberg,2021 年)。现有的对比学习方法通常采用特定的数据增强策略,在不改变标签的情况下创建新颖、逼真的训练数据,为任何输入样本构建正向替代数据。它们的成功依赖于在领域专业知识指导下精心设计的经验法则。用于对比学习的常规数据增强技术主要是针对图像和语言数据设计的,如颜色变形、翻转、单词替换和反向翻译(Chen 等,2020 年;Luo 等,2021 年)。这些增强技术一般不适用于时间序列数据。最近,一些研究人员提出了时间序列增强技术,以提高训练数据的大小和质量(Wen 等,2021 年)。例如,TS-TCC(Eldele 等人,2021 年)和 Self-Time(Fan、Zhang 和 Gao,2020 年)采用抖动、缩放和排列策略生成增强实例。Franceschi 等人提出提取子序列用于数据增强(Franceschi、Dieuleveut 和 Jaggi,2019 年)。尽管目前取得了进展,但现有方法仍有两大局限。首先,与具有人类可识别特征的图像不同,时间序列数据往往与无法解释的潜在模式相关联。强增强(如置换)可能会破坏这种模式(我同意,实际上本质就是找一种平衡,既能增强数据,又不会完全破坏数据的特性),因此,模型会将负面手工误认为正面手工。而抖动等弱增强方法可能会生成与原始输入过于相似的增强实例,从而无法为对比学习提供足够的信息。另一方面,来自不同领域的时间序列数据集可能具有不同的性质。针对所有数据集和任务采用一种通用的数据增强方法,如子序列(Xie 等人,2019 年),会导致性能达不到最优。其他研究则遵循经验规则,从昂贵的试错中选择合适的增强方法。与手工制作特征类似,从学习的角度来看,手工选择数据增强也是不可取的。现实生活中时间序列数据的多样性和异质性进一步阻碍了这些方法的广泛应用。
为了应对这些挑战,我们首先介绍了在对比学习中选择良好数据增强的标准。数据增强通过将输入训练空间正确外推到更大的区域,有利于可泛化、可迁移和稳健的表征学习(Wilk 等人,2018 年)。正向实例包围着一个判别区域,在这个区域中,所有数据点都应与原始实例相似。对比性表征学习所需的数据增强应该同时具有高保真和高多样性。高保真鼓励增强数据保持语义特征,而语义特征对转换是不变的(Wilk 等人,2018 年)。例如,如果下游任务是分类,那么生成的输入增强数据就应该是保留类别的。同时,生成具有高多样性的增强样本可以提高泛化能力,从而有利于表征学习(Chen 等人,2020 年)。从动机出发,我们基于信息论从理论上分析了数据增强中的信息流,并推导出选择所需的时间序列增强的标准。由于实际时间序列数据的不可解释性,我们假定语义标识由下游任务中的目标呈现。因此,通过最大化下游标签和增强数据之间的互信息,可以实现高保真。在无监督设置中,当下游标签不可用时,会为每个实例分配一个一次性伪标签。这些伪标签促使不同实例的增强能够相互区分。我们证明,保留这些伪标签的数据增强可以在不降低保真度的情况下增加新信息。同时,我们最大限度地提高了增强数据在原始实例条件下的熵,从而增加了数据增强的多样性。(我有疑问!!!这种假设是基于下游任务的目标来推导的标签生成过程。因此,这并不是一种通用的方法,是一种针对特定下游任务的策略。这种方法依赖于下游任务的目标来生成和调整标签,也就是说,在应用这种方法之前,需要明确下游任务的具体目标,并基于此设计标签生成策略和数据增强方法。不是通用的标签生成方法。一般这种打标签的,多多少少都不是通用的吧。(个人理解,勿喷))
根据得出的标准,我们提出了一种自适应数据增强方法--InfoTS(如图 1 所示),以避免临时选择或艰苦的试错调整。具体来说,我们利用另一个神经网络(用元学习器表示)来学习增强先验和对比学习。元学习器会自动从候选增强中选择最佳增强,以生成可行的正样本。然后,将增强实例与随机抽样的负实例一起输入时间序列编码器,以对比方式学习表征。通过重新参数化技巧,元学习器可以根据建议的标准通过反向传播进行有效优化。因此,元学习器可以根据数据集和学习任务自动选择数据增强,而无需借助专家知识或繁琐的下游验证。我们的主要贡献包括:
- 我们提出了指导对比式时间序列表示学习选择数据增强的标准,而无需预制知识。
- 我们提出了一种针对不同时间序列数据集自动选择可行数据增强的方法,该方法可通过反向传播进行有效优化。
- 我们通过实证验证了所提出的标准在寻找最佳数据增强方面的有效性。广泛的实验证明,InfoTS 可以实现极具竞争力的性能,与领先的基线相比,预测任务的 MSE 降低了 12.0%,分类任务的准确率相对提高了 3.7%。
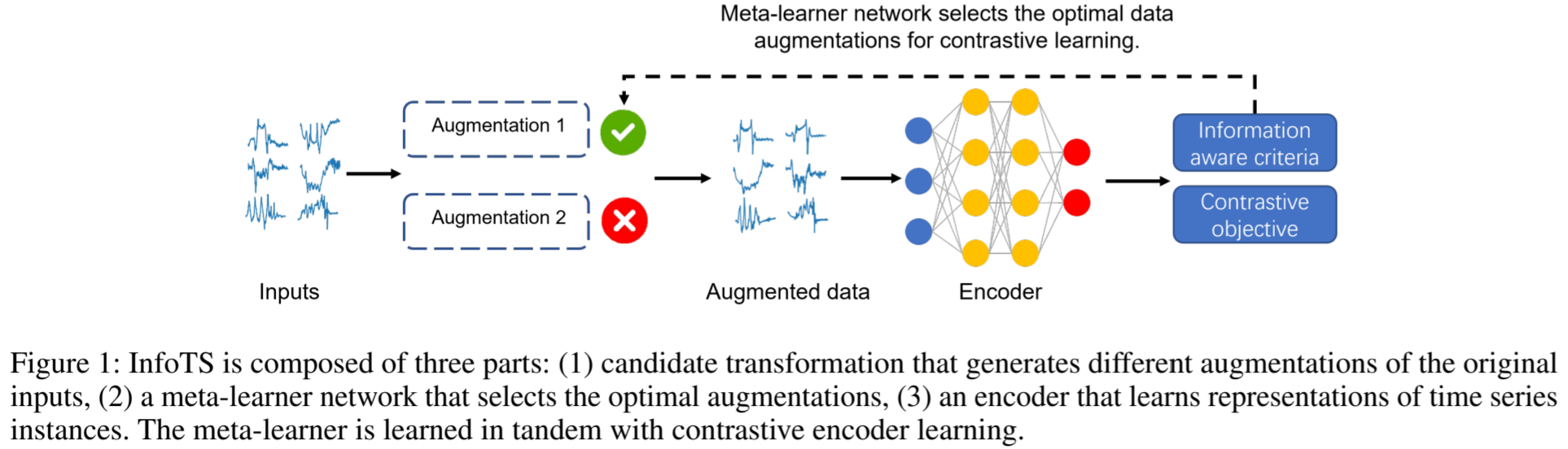
图 1:InfoTS 由三部分组成:(1) 候选变换,用于生成原始输入的不同增强;(2) 元学习器网络,用于选择最佳增强;(3) 编码器,用于学习时间序列实例的表征。元学习器的学习与对比编码器的学习同步进行。
方法论
术语和问题定义
时间序列实例 x 的维度为 T × F,其中 T 是序列长度,F 是特征维度。给定一组时间序列实例 X,我们的目标是学习一个编码器 f θ (x),将每个实例 x 映射到一个固定长度的向量 z∈R D,其中 θ 是编码器网络的可学习参数,D 是表示向量的维度。在半监督设置中,标签集 X L ⊆ X 中的每个实例 x 都与下游任务的标签 y 相关联。特别是,在完全监督设置中,X L = X 成立。在工作中,我们使用无衬线小写字母(如 x)表示随机时间序列变量,使用斜体小写字母(如 x)表示采样实例。
良好增强的信息感知标准
对比学习的数据增强目标是创建现实合理的实例,并通过不同的转换方法保持语义。与视觉和语言领域的实例不同,人类无法识别时间序列数据的基本语义,因此很难甚至不可能将人类知识纳入时间序列数据的数据增强。例如,旋转图像不会改变其内容或标签。而改变一个时间序列实例可能会破坏其信号模式,生成一个毫无意义的时间序列实例。此外,现实生活中的时间序列数据集具有极大的异质性,这进一步使得基于试验和错误的选择变得不切实际。虽然针对时间序列数据已经提出了多种数据增强方法,但对于什么是对特定学习任务和数据集有意义的好的增强方法,而没有预制人为先验的讨论较少。从我们的角度来看,用于对比表示的理想数据增强应该保持高保真度、多样性和对不同数据集的适应性。图 2 举例说明了这一点。
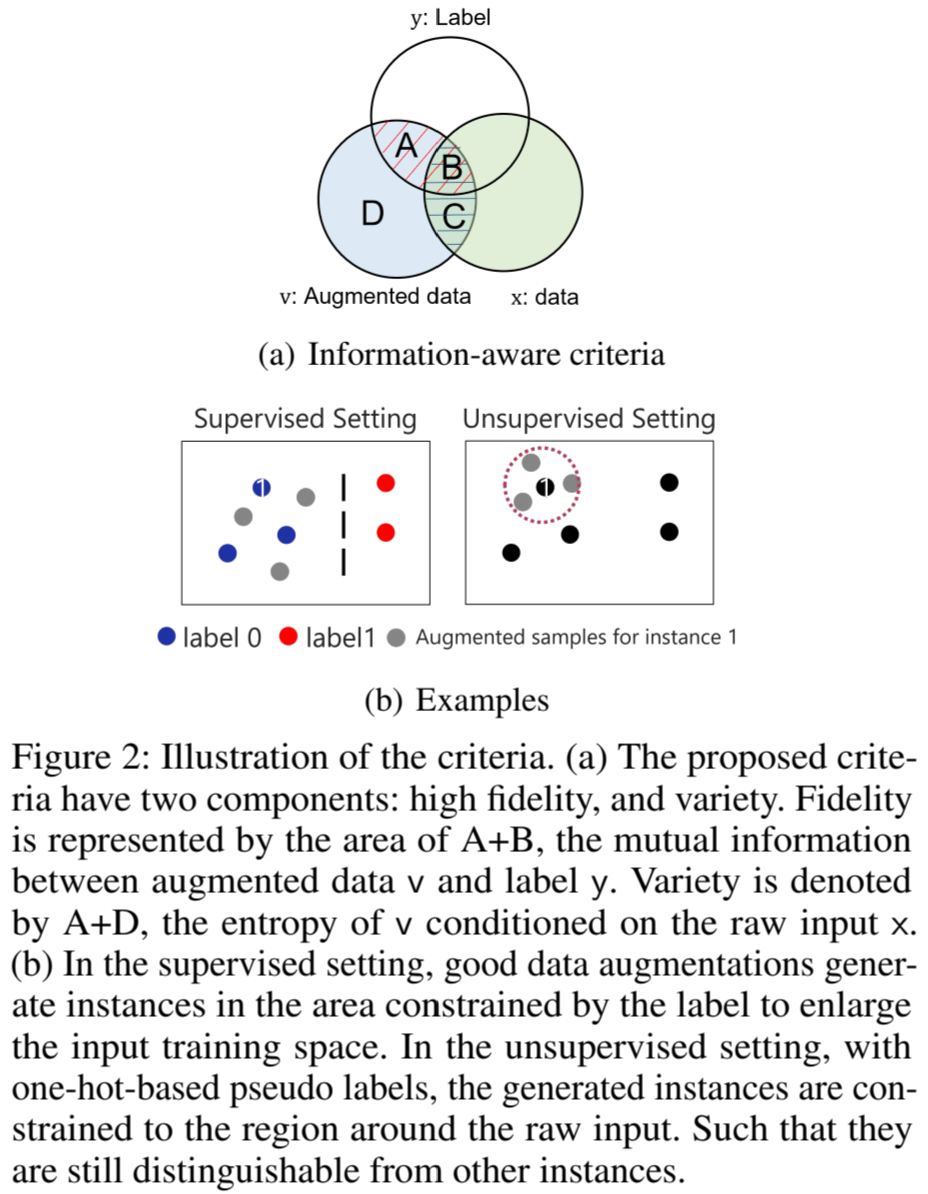
图 2:标准说明。(a) 提议的标准有两个组成部分:高保真和多样性。保真度用 A+B 表示,A+B 是增强数据 v 和标签 y 之间的互信息;多样性用 A+D 表示,A+D 是 v 在原始输入 x 条件下的熵。在无监督环境下,使用基于单次热处理的伪标签,生成的实例会被限制在原始输入周围的区域。这样,它们仍能与其他实例区分开来。
高保真。高保真的增强数据能保持语义的一致性,不受变换的影响。考虑到实际时间序列数据的不可解释性,直观检查增强的保真度是一项挑战。因此,我们假定时间序列实例的语义标识是由其在下游任务中的标签呈现的,而在训练期间,标签可能是可用的,也可能是不可用的。在此,我们从有监督的情况开始分析,稍后将扩展到无监督的情况。受信息瓶颈(Tishby、Pereira 和 Bialek,2000 年)的启发,我们将保持高保真的目标定义为增强 v 和标签 y 之间的大互信息(MI),即 MI(v; y)。
我们将增强 v 视为 x 的概率函数和随机变量,即 v = g(x;)。根据互信息的定义,我们有 MI(v; y) = H(y) - H(y|v),其中 H(y) 是 y 的(香农)熵,H(y|v) 是以增强 v 为条件的 y 的熵。由于 H(y) 与数据增强无关,因此目标等同于最小化条件熵 H(y|v)。考虑到高效优化,我们按照(Ying 等人,2019 年)和(Luo 等人,2020 年)的方法,用 y 和 ˆy 之间的交叉熵来近似它,其中 ˆy 是以增强 v 为输入的预测,计算方法是
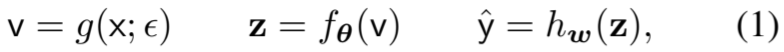
其中,z 是表示,h w (-) 是以 w 为参数的预测投影器。那么,有监督或半监督情况下的高保真目标就是最小化
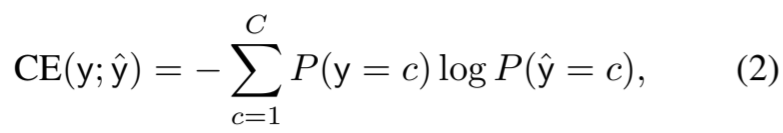
其中 C 是标签的数量。
在 y 不可用的无监督设置中,利用单点编码 y s∈R |X|作为伪标签来替代公式 (2) 中的 y。这样做的动机是,增强后的实例仍然可以通过分类器与其他实例区分开来。我们从理论上证明,保留伪标签的增强具有以下特性。
特性 1(保真)。如果增强 v 保留了单次编码伪标签,那么 v 与下游任务标签 y(虽然训练时看不到)之间的互信息等同于原始输入 x 与 y 之间的互信息,即 MI(v; y) = MI(x; y)。
特性 2(添加新信息)。通过保留单次编码伪标签,与原始输入 x 相比,增量 v 包含新信息,即 H(v) ≥ H(x)。
详细证明见附录。这些特性表明,在无监督环境下,保留单次编码伪标签可以保证生成的增强不会降低保真度,而不管增强中固有的下游任务和差异如何。同时,它还能为对比学习引入新的信息。
由于在无监督情况下,标签数等于数据集 X 中的实例数,直接优化公式 (2) 既低效又不可扩展。因此,我们进一步放宽限制,用批量单热编码 y B 来近似 y,从而将标签数 C 从数据集大小减小到批量大小。
高多样性。增量的充分差异可提高对比学习模型的泛化能力。在信息论中,随机变量可能结果中固有的不确定性由其熵来描述。考虑到增强实例是根据原始输入 x 生成的,我们要最大化 v 在 x 条件下的熵 H(v|x),以保持增强的多样性。根据条件熵的定义,我们可以得出
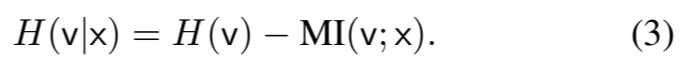
我们不考虑第一部分,因为 v 的无约束熵可能被无意义的噪声所支配。考虑到 v 和 x 的连续性,我们通过最小化留空上限(L1Out)来最小化 v 和 x 之间的互信息(Poole 等人,2019 年)。其他互信息上限,如互信息的对比对比率上限(Cheng 等,2020 年),也可以方便地成为我们框架中的即插即用组件。那么,鼓励高多样性的目标就是最小化 v 和 x 之间的 L1Out:
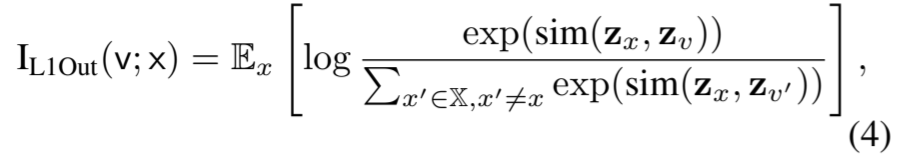
其中v是输入实例x的扩充实例。zx、zv和zv分别是实例x、v和v的表示。sim(z1,z2)=zT1z2是向量z1和z2的内积。
标准。结合高保真度和多样性的信息感知定义,我们提出了在没有先验知识的情况下选择良好增强的标准,
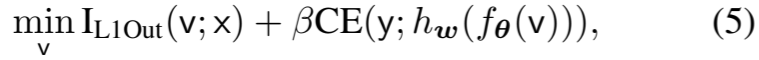
其中,β 是一个超参数,用于权衡保真度和多样性。请注意,在无监督设置中,y 被单次编码伪标签所取代。
与信息瓶颈的关系。虽然形成过程与数据压缩中的信息瓶颈(min p(e|x) MI(x; e) - βMI(e;y))类似,但我们的标准在以下几个方面有所不同。首先,信息瓶颈中的 e 代表输入 x,而公式(5)中的 v 代表增强实例。其次,信息瓶颈的目的是为数据压缩保留最少且足够的信息,而我们的标准是为对比学习中的数据增强而设计的。第三,在信息瓶颈中,压缩后的表示 e 是输入 x 的一个确定性函数,不存在方差。MI(e; y) 和 MI(e; x) 受 MI(x; y) 和 H(x) 约束,即 MI(e; y) ≤ MI(x; y) 和 MI(e; x) = H(e),其中 H(e) 是 e 的熵。在我们的标准中,v 是输入 x 的概率函数,因此,在信息瓶颈中,v 的方差使得增强空间远大于压缩表示空间。
与 InfoMin 的关系。 InfoMin 是基于信息瓶颈设计的,即好的视图应从原始输入中保留最少且足够的信息(Tian 等,2020 年)。与信息瓶颈类似,InfoMin 假设增强视图是输入的函数,这就在很大程度上限制了数据增强的方差。此外,高保真特性在无监督设置中也被否定了。由于人类知识的可用性,它适用于图像数据集。但是,它可能无法为时间序列数据生成合理的增强。此外,他们还采用了对抗学习,即最小化 MI 的下限,以增加增强的多样性。而为了最小化统计依赖性,我们更倾向于使用上限,如 L1Out,而不是下限。
(以上内容没看懂,...)
时间序列元对比学习
我们的目标是设计一种可学习的增强选择器,学会以数据驱动的方式选择可行的增强。有了这种自适应数据增强,对比损失就可以用来训练编码器,从而从原始时间序列中学习表征。
架构 采用的编码器 f θ (x) : R T×F → R D 由两部分组成:一个全连接层和一个 10 层扩张 CNN 模块(Franceschi、Dieuleveut 和 Jaggi,2019 年;Yue 等,2021 年)。为了探索时间序列的内在结构,我们在对比学习框架中加入了全局损失(实例级)和局部损失(子序列级)来训练编码器。
全局对比损失旨在捕捉时间序列数据集中的实例级关系。形式上,给定一批时间序列实例 X B ⊆ X,对于每个实例 x ∈ X B,我们用自适应选择的变换生成一个增强实例 v,这将在后面介绍。(x, v) 被视为正对,而其他 (B-1) 组合 {(x, v )}(其中 v' 是 x' 的增强实例且 x' /= x)被视为负对。按照(Chen 等人,2020 年;You 等人,2020 年),我们基于 InfoNCE(Hjelm 等人,2018 年)设计了全局对比损失。batch-size实例级对比损失为
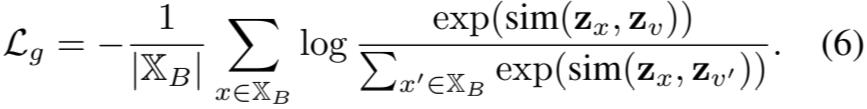 局部对比损失提出的目的是探索时间序列中的时间内关系。对于时间序列实例 x 的增强实例 v,我们首先将其拆分为一组子序列 S,每个子序列的长度为 L。对于每个子序列 s∈ S,我们按照(Tonekaboni、Eytan 和 Goldenberg,2021 年)的方法,通过选择与之相近的另一个子序列来生成一个正对(s,p)。我们采用非相邻样本 ¯ N s 来生成负数对。详细说明见附录。那么,实例 x 的局部对比损失为:
局部对比损失提出的目的是探索时间序列中的时间内关系。对于时间序列实例 x 的增强实例 v,我们首先将其拆分为一组子序列 S,每个子序列的长度为 L。对于每个子序列 s∈ S,我们按照(Tonekaboni、Eytan 和 Goldenberg,2021 年)的方法,通过选择与之相近的另一个子序列来生成一个正对(s,p)。我们采用非相邻样本 ¯ N s 来生成负数对。详细说明见附录。那么,实例 x 的局部对比损失为:
(现在是2024年5月24日下午17:33,继续看,最近事情比较多.)
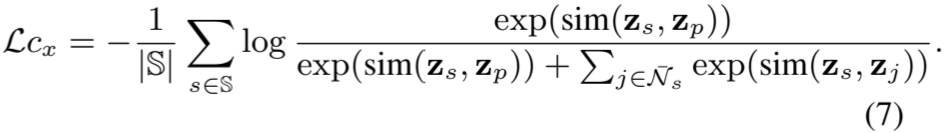
在一个批次的所有实例中,我们有
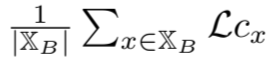 。最终的对比目标是:
。最终的对比目标是:

其中,α 是一个超参数,用于权衡全局和局部对比度损失。
元学习器网络 以往的时间序列对比学习方法(Franceschi、Dieuleveut 和 Jaggi,2019 年;Fan、Zhang 和 Gao,2020 年;Eldele 等,2021 年;Tonekaboni、Eytan 和 Goldenberg,2021 年)都是通过预制人类先验指导下的经验法则或乏味的尝试和错误来生成增强,这些方法都是针对特定数据集和学习任务而设计的。在本部分中,我们将讨论如何基于所提出的信息感知标准,利用元学习者网络自适应地选择最佳增强。我们可以将最优增强的选择视为一种先验选择。我们首先选择一组候选变换 T,如抖动和时间扭曲。每个候选变换 t i∈ T 都与权重 p i∈ (0, 1) 相关联,推断出选择变换 t i 的概率。对于一个实例 x,通过变换 t i 得到的增强实例 v i 可以通过以下方式计算:
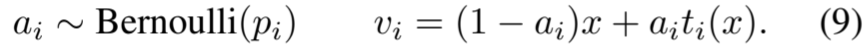
考虑到多重变换,我们将所有 v i 置为相同长度。然后,通过组合候选实例,就能得到自适应增强实例,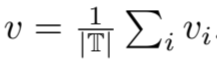 。
。
为了使用基于梯度的方法进行高效优化,我们用二元具体分布来近似离散伯努利过程(Maddison、Mnih 和 Teh,2016 年)。具体来说,我们将公式 (9) 中的 a i 近似为
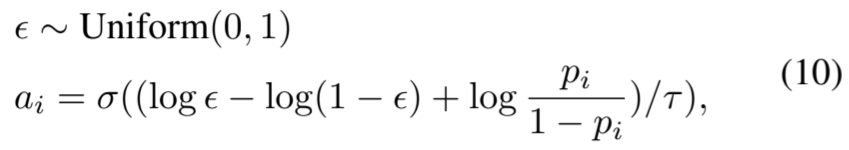
其中,σ(-) 是 sigmoid 函数,τ 是控制近似值的温度。这种近似的合理性见附录。此外,当温度 τ > 0 时,梯度 ∂v/∂p i 是明确定义的。因此,我们的元网络是端到端可微分的。详细算法见附录。
(Sorry,最近在休息摸鱼,今天是2024年5月29日,10:58,继续看这个论文.)
相关工作
对比时间序列表征学习
对比学习已被广泛应用于表征学习,并在多个领域取得了卓越的表现(Chen 等人,2020;Xie 等人,2019;You 等人,2020)。最近,有人致力于将对比学习应用到时间序列领域(Oord、Li 和 Vinyals 2018;Franceschi、Dieuleveut 和 Jaggi 2019;Fan、Zhang 和 Gao 2020;Eldele 等人 2021;Tonekaboni、Eytan 和 Goldenberg 2021;Yue 等人 2021)。时间对比学习(Time Contrastive Learning)利用多项式逻辑回归分类器训练特征提取器,以区分时间序列中的所有片段(Hyvarinen 和 Morioka,2016 年)。在(Franceschi、Dieuleveut 和 Jaggi 2019)中,Franceschi 等人根据子序列生成正负对。TNC 采用去偏对比目标,以确保在表示空间中,本地邻域中的信号可与非邻域信号区分开来(Tonekaboni、Eytan 和 Goldenberg,2021 年)。SelfTime 通过探索样本间和样本内的关系,采用多种手工制作的增强方法进行无监督时间序列对比学习(Fan、Zhang 和 Gao,2020 年)。TS2Vec 为每个时间戳学习一个表示,并以分层方式进行对比学习(Yue 等,2021 年)。然而,这些方法中的数据增强要么是通用的,要么是通过误差轨迹选择的,这阻碍了它们在复杂的现实生活数据集中的广泛应用。
时间序列预测
预测是时间序列分析中的一项重要任务。文献中使用的深度学习架构包括循环神经网络(RNNs)(Salinas 等人,2020 年;Oreshkin 等人,2019 年)、卷积神经网络(CNNs)(Bai、Kolter 和 Koltun,2018 年)、Transformer(Li 等人,2019 年;Zhou 等人,2021 年)和图神经网络(GNNs)(Cao 等人,2021 年)。N-BEATS 深度堆叠了具有后向和前向残差链接的全连接层,用于单变量时间序列预测(Oreshkin 等人,2019 年)。TCN 利用具有扩张因果卷积的深度 CNN 架构(Bai、Kolter 和 Koltun,2018 年)。考虑到多变量时间序列中的长期依赖性和短期趋势,LSTnet 将 CNN 和 RNNS 结合到一个统一的模型中(Lai 等人,2018 年)。LogTrans 将 Transformer 模型引入时间序列预测,并在其注意机制中加入因果卷积(Li 等人,2019 年)。Informer 进一步提出了一种稀疏自注意机制,以降低时间复杂性和内存使用量(Zhou 等,2021 年)。StemGNN 是一种基于 GNN 的模型,它同时考虑了时内和序列间的相关性(Cao 等,2021 年)。与这些研究不同的是,我们的目标是学习时间序列数据的一般表征,这种表征不仅可用于预测,还可用于分类等其他任务。此外,我们提出的框架还兼容各种编码器架构。
自适应数据增强
数据增强是对比学习的重要组成部分。现有研究表明,最佳增强的选择取决于下游任务和数据集(Chen 等,2020 年;Fan、Zhang 和 Gao,2020 年)。一些研究人员探索了视觉领域对比学习中最优增强的自适应选择。AutoAugment 通过强化学习方法自动搜索翻译策略组合(Cubuk 等人,2019 年)。Faster-AA 利用可微分策略网络改进了数据增强的搜索管道(Hataya 等人,2020 年)。DADA 进一步引入了无偏梯度估计器,以实现高效的单程优化策略(Li 等人,2020 年)。在对比学习框架内,Tian 等人应用了信息瓶颈理论,即最佳视图应共享最少且足够的信息,以指导视觉领域对比学习中良好视图的选择(Tian 等人,2020 年)。考虑到时间序列数据的不可解释性,直接应用 InfoMin 框架可能会在增强过程中保留不充分的信息。与(Tian 等人,2020 年)不同的是,我们专注于时间序列领域,并提出了一种端到端的可微分方法,以自动选择每个数据集的最优增强。
(去吃了个饭,现在14:27,继续.)
实验
在本节中,我们将在时间序列预测和分类任务中对 InfoTS 和 SOTA 基线进行比较。我们还进行了案例研究,以展示对所提出的标准和元学习器网络的见解。详细的实验设置见附录。完整的实验结果和额外的实验(如参数敏感性研究)见附录。
时间序列预测
时间序列预测的目的是利用最后 L x 个观测值预测未来 L y 个时间戳。我们按照(Yue 等人,2021 年)的方法,训练一个用 L2 准则惩罚正则化的线性模型来进行预测。在单变量情况下,输出维度为 L y;在多变量情况下,输出维度为 L y × F,其中 F 为特征维度。
数据集和基准。采用了四个时间序列预测基准数据集,包括 ETTh1、ETTh2、ETTm1(Zhou 等,2021 年)和电力数据集(Dua 和 Graff,2017 年)。这些数据集用于单变量和多变量设置。我们将无监督 InfoTS 与 SOTA 基线进行了比较,包括 TS2Vec(Yue 等,2021 年)、Informer(Zhou 等,2021 年)、StemGNN(Cao 等,2021 年)、TCN(Bai、Kolter 和 Koltun,2018 年)、LogTrans(Li 等,2019 年)、LSTnet(Lai 等,2018 年)和 N-BEATS(Oreshkin 等,2019 年)。在这些方法中,N-BEATS 仅针对单变量设计,而 StemGNN 仅针对多变量设计。我们参考(Yue 等人,2021 年)建立了公平比较的基线。我们使用回归问题的标准指标、平均平方误差(MSE)和平均绝对误差(MAE)进行评估。单变量时间序列预测的评估结果如表 1 所示,而多变量预测结果因篇幅所限在附录中报告。
性能。如表 1 和表 4 所示,在单变量和多变量设置下的比较结果表明,InfoTS 的性能始终与领先基线相当或更胜一筹。由于内存不足问题,StemGNN 的部分结果无法提供(Yue 等,2021 年)。具体来说,我们有以下观察结果。TS2Vec 是另一种具有数据增强功能的对比学习方法,它在大多数情况下都取得了第二好的性能。TS2Vec 相对于其他基线的持续改进表明了对比学习在时间序列表征学习中的有效性。不过,这种通用数据增强可能不是生成正对的最有信息量的数据。与 TS2Vec 相比,InfoTS 在单变量环境下的平均 MSE 降低了 12.0%,平均 MAE 降低了 9.0%。在多变量设置中,MSE 和 MAE 分别降低了 5.5% 和 2.3%。究其原因,InfoTS 可以以数据驱动的方式自适应地选择最合适的增强因子,而且种类繁多、保真度高。使用这种信息增强方法训练的编码器可以学习到更高质量的表征。
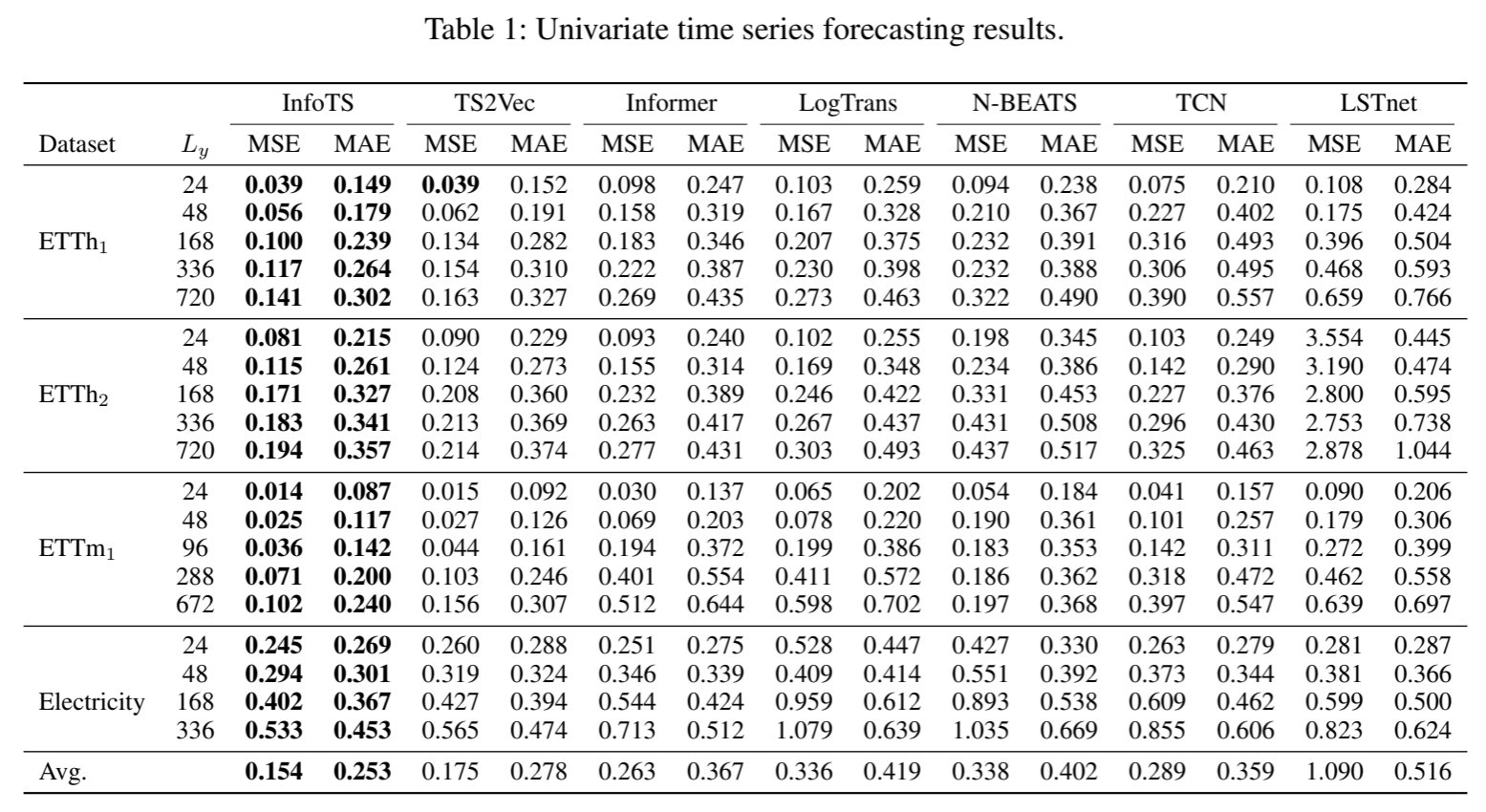
表 1:单变量时间序列预测结果。
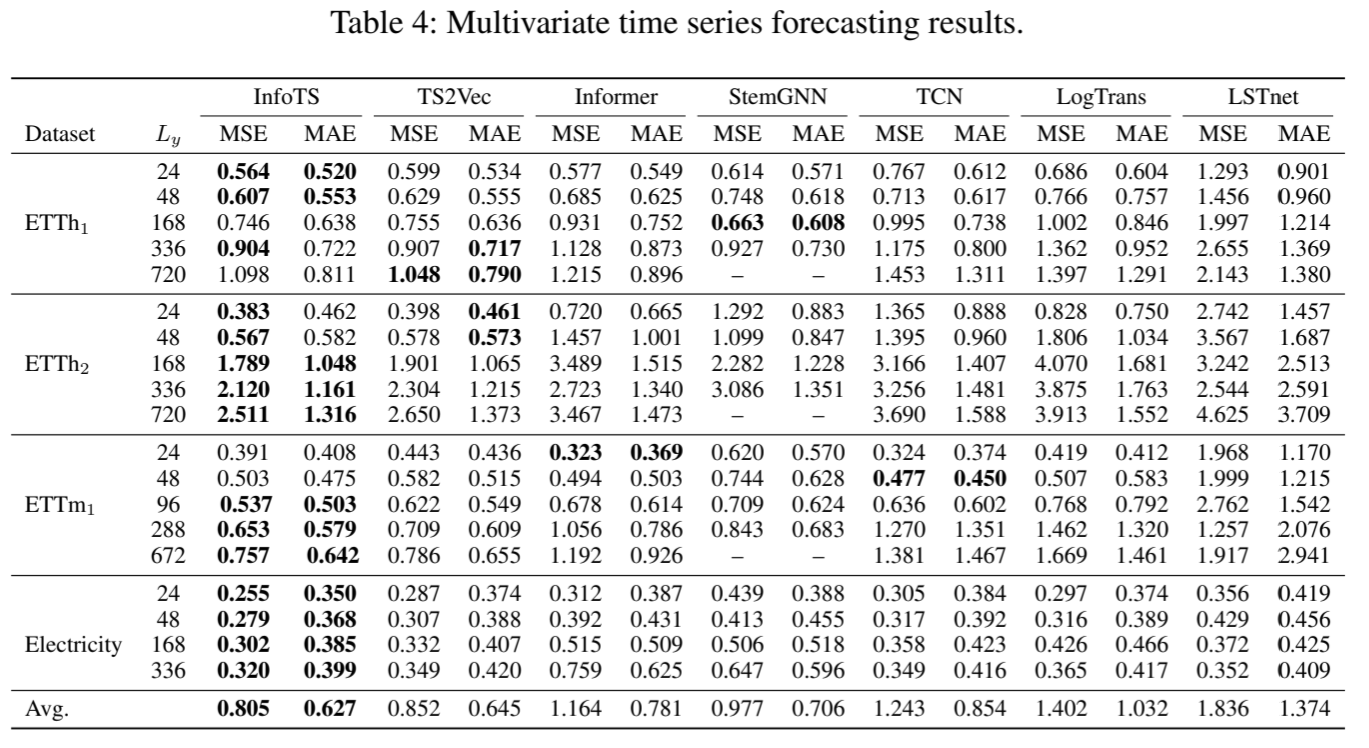
表 4:多元时间序列预测结果。
时间序列分类
按照前面的设置,我们以标准监督方式评估时间序列分类的表征质量(Franceschi、Dieuleveut 和 Jaggi,2019 年;Yue 等,2021 年)。我们在训练分割的表征基础上训练一个具有径向基函数核的 SVM 分类器,然后比较测试集的预测结果。
数据集和基准。我们使用两种基准数据集进行评估。UCR 档案(Dau 等人,2019 年)包含 128 个单变量时间序列数据集,UEA 档案(Bredin,2017 年)包含 30 个多变量数据集。我们将 InfoTS 与 TS2Vec(Yue 等人,2021 年)、T-Loss(Franceschi、Dieuleveut 和 Jaggi,2019 年)、TS-TCC(Eldele 等人,2021 年)、TST(Zerveas 等人,2021 年)和 DTW(Franceschi、Dieuleveut 和 Jaggi,2019 年)等基线进行了比较。对于我们的方法,InfoTS s ,训练标签仅用于训练元学习器网络,以选择合适的增强,InfoTS 是在纯粹无监督的情况下进行表征学习的。
性能。表 2 总结了 UEA 数据集的结果。全部结果见附录。有了ground-truth标签对元学习网络的指导,InfoTS s 的表现大大优于其他基线。平均而言,它比最佳基线 TS2Vec 的分类准确率提高了 3.7%,在所有 30 个 UEA 数据集上的平均排名值为 1.967。在纯粹的无监督设置下,InfoTS 采用独热编码作为伪标签,从而保持了保真度。在表 2 中,InfoTS 的平均性能排名第二,平均排名值为 2.633。128 个 UCR 数据集的性能见附录中的表 8。这些数据集都是单变量数据,具有易于识别的模式,数据增强的效果微乎其微,甚至是负面的(Yue 等人,2021 年)。然而,根据我们的标准对每个数据集进行自适应选择增强后,InfoTS s 和 InfoTS 仍然优于同行。

表 2:30 个 UEA 数据集的多变量时间序列分类。
消融研究
为深入介绍所提出的方法,我们对 "电力 "数据集进行了多次消融研究,以实证验证所提出的信息感知标准和框架在自适应选择合适增强因子方面的有效性。我们使用 MSE 进行评估。
评估标准。在本节中,我们提出了时间序列数据增强的信息感知标准,即好的增强应该具有高多样性和高保真性。利用 L1Out 和交叉熵作为近似值,我们得到了公式 (5) 中的标准。为了验证所提标准的有效性,我们采用了两组增强,即不同长度的子序列增强和不同标准偏差的抖动增强。子序列增强在时间维度上起作用,而抖动增强在特征维度上起作用。对于子序列增强,我们将子序列比率 r 的范围设定为 [0.01, 0.99]。比率为 r 的子序列增强用 Sub r 表示,如 Sub 0.01。抖动增强的标准偏差范围为 [0.01,3.0]。标准偏差为 std 的抖动增强用 Jitter std 表示,如 Jitter 0.01。
直观地说,随着 r 的增加,Sub r 生成的增强实例种类更少,保真度更高。例如,当 r = 0.01 时,Sub r 生成的子序列只保留了原始输入的 1%时间戳,这就导致了高多样性和极低的保真度。同样,对于抖动增强,随着 std 的增加,Jitter std 生成的增强实例种类更多,但保真度却更低。
图 3 显示了预测性能与我们提出的标准之间的关系。一般来说,在 MAE 和 MSE 设置中,性能与所提出的标准呈正相关,这验证了将标准作为元学习器网络训练目标的正确性。
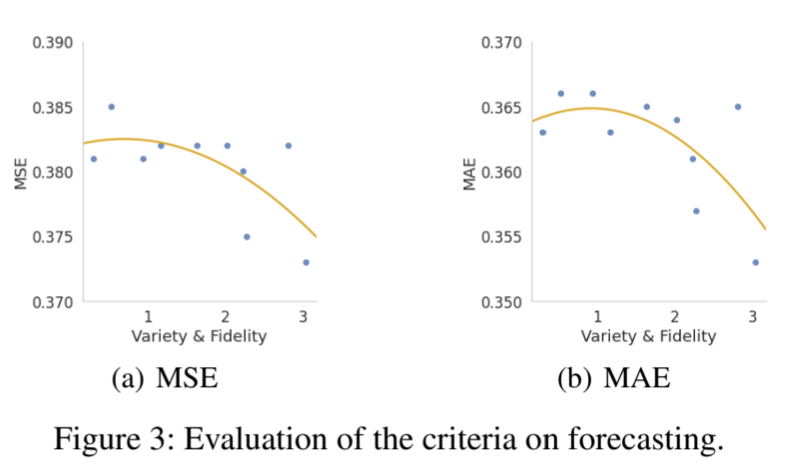
图 3:预测标准评估。
元学习网络的评估。在这一部分中,我们通过实证分析表明了所开发的元学习器网络在学习最优增强方面的优势。结果如表 3 所示。我们将 InfoTS 与变体 "随机 "和 "全部 "进行了比较。"随机 "每次从候选变换函数中随机选择一个增强,而 "全部 "则按顺序应用变换来生成增强实例。它们的性能受到低质量候选增强的严重影响,这验证了自适应选择在我们方法中的关键作用。2) 为了展示元学习网络训练中多样性和保真度目标的影响,我们加入了 "w/o Fidelity "和 "w/o Variety "两个变体,它们分别取消了保真度或多样性目标。通过对 InfoTS 和这两个变体的比较,我们从经验上证实了多样性和保真度对于对比学习中的数据增强都很重要。
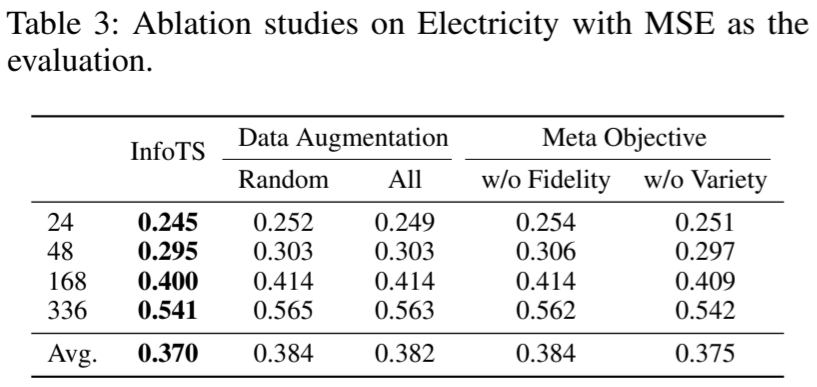
表 3:以 MSE 作为评估指标的电力消融研究。
结论
我们为时间序列数据提出了一种信息感知的数据增强标准,即好的增强应保持高多样性和高保真性。我们用互信息神经估计和交叉熵估计来近似该标准。在近似标准的基础上,我们采用元学习者网络来自适应地选择最佳增强,以进行对比性表征学习。综合实验表明,用我们的方法生成的表示具有很高的质量,而且易于用于各种下游任务,如时间序列预测和分类,具有最先进的性能。
(现在17:42,看完了,今天乱七八糟的事情比较多,而且还摸鱼.)
准备再找一篇最新的相关的论文看,然后再串论文总结,加油,GOGOGO.
(俺的代码,还没看完,我老是想着,呜呜呜呜呜呜,快干活.)
InfoTS: 具有信息感知增强的时间序列对比学习《Time Series Contrastive Learning with Information-Aware Augmentations》(对比学习、信息感知增强、高保真、多样性、信息论-信息瓶颈、元学习器)(没看懂,还需要再回顾)的更多相关文章
- 【Luogu】P2765魔术球问题(没看懂的乱搞)
题目链接 这题……讲道理我没看懂. 不过我看懂题解的代码是在干嘛了qwq 题解是zhaoyifan的题解 然后……我来讲讲这个题解好了. 题解把值为i的球拆成了两个,一个编号是i*2,一个编号是i*2 ...
- PAT 甲级 1031 Hello World for U (20 分)(一开始没看懂题意)
1031 Hello World for U (20 分) Given any string of N (≥) characters, you are asked to form the char ...
- 那些年,很多人没看懂的Python内置函数
Python之所以特别的简单就是因为有很多的内置函数是在你的程序"运行之前"就已经帮你运行好了,所以,可以用这个的特性简化很多的步骤.这也是让Python语言变得特别的简单的原因之 ...
- QT插件开发方式(没看懂)
创建一个QT的库项目,删除自动生成的.h和.cpp文件,添加一个接口定义.h文件和一个接口实现类(一个.h一个.cpp).代码如下: 1.接口文件源码 #ifndef PLUGININTERFACE_ ...
- 面试之加分项vue(没看懂,。。。。)
对大部分人来说,掌握Vue.js基本的几个API后就已经能够正常地开发前端网站.但如果你想更加高效地使用Vue来开发,成为Vue.js大师,那下面我要传授的这五招你一定得认真学习一下了.在面试过程很多 ...
- ccf201403-3 记录一个神tmwa了的代码 莫非我没看懂题。。。
#include <string.h> #include<cstdio> #include<stdio.h> #include <iostream> # ...
- 闯缸鱼:看懂python如何实现整数加和,再决定是否自学编程
玩鱼缸的新手都知道有一种鱼叫"闯缸鱼",皮实好养,帮助新手判断鱼缸环境是否准备好.这篇笔记,最初用来解答一个编程新手的疑问,后来我发现,整理一下也可当做有兴趣自学python 编程 ...
- 一个例子看懂所有nodejs的官方网络demo
今天看群里有人用AI技术写了个五子棋,正好用的socket.io,本身我自己很久没看nodejs了,再加上Tcp/IP的知识一直很弱,我就去官网看了下net.socket 发现之前以为懂的一个官方例子 ...
- 小白都能看懂的tcp三次握手
众所周知,TCP在建立连接时需要经过三次握手.许多初学者经常对这个过程感到混乱:SYN是干什么的,怎么一会儿是1一会儿是0?怎么既有大写的ACK又有小写的ack?为什么ACK在第二次握手才开始出现?初 ...
- 一文看懂JVM内存区域分布与作用
那么我们在开始介绍Java内存区域之前,我们先放一张内存区域的图,方便我们后面介绍的时候可以对照着看. 须知,本文是根据JDK8来介绍的. 程序计数器 首先它是线程私有的,它也称为代码的行号指示器,字 ...
随机推荐
- UE Spline 样条网格体组件添加碰撞
最近做的一个功能是通过Spline 生成管道模型. 如下图所示: 遇到的一个问题是需要给生成的管路加上碰撞.其中需要两个重要的步骤: 设置SplineMeshComponent的碰撞预设 找到&quo ...
- django 信号第一个 raise ValidationError出现后,还会继续下一个if吗
在你提供的代码片段中,如果第一个 raise ValidationError 触发,会抛出异常并停止执行当前函数或代码块.这是因为异常(Exception)会中断正常的代码流程,将控制权传递给调用堆栈 ...
- 手写数字识别-使用TensorFlow构建和训练一个简单的神经网络
下面是一个具体的Python代码示例,展示如何使用TensorFlow实现一个简单的神经网络来解决手写数字识别问题(使用MNIST数据集).以下是一个完整的Python代码示例,展示如何使用Tenso ...
- iOS开发基础143-性能优化
我们可以先构建一个详细的大纲,然后在每个部分详细阐述.下面是一个针对iOS性能优化的详细大纲: 一. App启动时间优化 A. 启动分类 冷启动 热启动 B. 冷启动优化 减少启动时的动态库加载 尽可 ...
- 手把手教你集成GraphRag.Net:打造智能图谱搜索系统
在人工智能和大数据发展的背景下,我们常常需要在项目中实现知识图谱的应用,以便快速.准确地检索和使用信息. 今天,我将向大家详细介绍如何在一个新的.NET项目中集成GraphRag.Net,这是一个参考 ...
- 【Mybatis-Plus】制作逆向工具
官方文档可参考: https://baomidou.com/pages/779a6e/#快速入门 工具需要的依赖 <?xml version="1.0"?> <p ...
- 【转载】 Mobaxterm 中文输入Backspace按键问题
版权声明:本文为CSDN博主「Flynnsin」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明.原文链接:https://blog.csdn.net/qq_45830 ...
- Sentry For Vue 完整接入详解(2021 Sentry v21.8.x)前方高能预警!三万字,慎入!
内容源于:https://docs.sentry.io/platforms/javascript/guides/vue/ 系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创 ...
- 7月新特性 | 软件开发生产线CodeArts发布多项新特性等你体验!
华为云软件开发生产线CodeArts是一站式.全流程.安全可信的云原生DevSecOps平台,覆盖需求.开发.测试.部署.运维等软件交付全生命周期环节,为开发者打造全云化研发体验.2024年7月,Co ...
- 【题解】ABC365(A~E)
前四题30min切,然后T5死磕70min+几发小唐错,距离比赛结束还有16s交最后一发,AC了. 目录 A. Leap Year 题目描述 思路 代码 B. Second Best 题目描述 思路 ...