NLP复习之N元文法
N元文法的统计
二元概率方程:
\]
三元概率估计方程:
\]
例题1
给出以下一个小型语料库,在最大似然一元模型和二元模型之间使用加一平滑法进行平滑, 请计算P(Sam|am)。注意要将tokens 和与其他单词一样看待。
<s> I am Sam </s>
<s> Sam I am </s>
<s> I am Sam </s>
<s> I do not like green eggs and Sam </s>
解
\(P(Sam|am) = \frac{C(am;Sam)}{C(am)} = \frac{2}{3}\)
\(P_{Laplace}(Sam|am) = \frac{C(am;Sam)+1}{C(am)+|V|} = \frac{2+1}{3+11} = \frac{3}{14}\)
注意:V是不同单词的种类!!是词汇表的大小
例题2
在1的条件下,请使用线性插值法,其中假设 λ1 = 1/2, λ2 =1/2,请计算P(Sam|am)。注意要将tokens 和与其他单词一样看待。
解
\(P(Sam) = \frac{C(Sam)}{S} =\frac{4}{25}\)
注意:S是单词出现的总次数!!
\(P(am) = \frac{3}{25}\)
统计\(bigram\)数量,\(P(Sam|am) = \frac{2}{3}\)
根据线性插值法,
P(Sam|am) &= \lambda_2 \times P(Sam|am) + \lambda_1 \times P(Sam)\\
&= 0.5 \times \frac{2}{3} + 0.5 \times \frac{3}{25} \\
&= \frac{31}{75}
\end{aligned}
\]
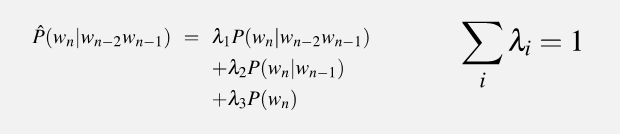
例题3
给定一个包含 100 个数字的训练集,其中包含 91 个0和 1-9 其他数字中的每个数字。 有以下的测试集:0 0 0 0 0 3 0 0 0 0。计算该问题的一元困惑度 unigram perplexity。
困惑度
\]
困惑度越小,概率越大。
解
\(P(0) = 91 / 100 = 0.91;\)
\(P(1;9) = 1 / 100 = 0.01;\)
\(PP(W) = (P(0)p(0)p(0)p(0)p(0)p(3)p(0)p(0)p(0)p(0))^{-0.1} = 1.725\)
NLP复习之N元文法的更多相关文章
- 【转】统计模型-n元文法
在谈N-Gram模型之前,我们先来看一下Mrkove假设: 1.一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词: 2.一个词出现的概率条件地依赖于前N-1个词的词类. 定义 N-Gram是大词 ...
- 算法复习——高斯消元(ssoi)
题目: 题目描述 Tom 是个品学兼优的好学生,但由于智商问题,算术学得不是很好,尤其是在解方程这个方面.虽然他解决 2x=2 这样的方程游刃有余,但是对于下面这样的方程组就束手无策了.x+y=3x- ...
- DeepNLP的核心关键/NLP词的表示方法类型/NLP语言模型 /词的分布式表示/word embedding/word2vec
DeepNLP的核心关键/NLP语言模型 /word embedding/word2vec Indexing: 〇.序 一.DeepNLP的核心关键:语言表示(Representation) 二.NL ...
- NLP十大里程碑
NLP十大里程碑 2.1 里程碑一:1985复杂特征集 复杂特征集(complex feature set)又叫做多重属性(multiple features)描写.语言学里,这种描写方法最早出现在语 ...
- NLP之语言模型
参考: https://mp.weixin.qq.com/s/NvwB9H71JUivFyL_Or_ENA http://yangminz.coding.me/blog/post/MinkolovRN ...
- 【NLP】中文分词:原理及分词算法
一.中文分词 词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键. ...
- 实战HMM-Viterbi角色标注地名识别
http://www.hankcs.com/nlp/ner/place-names-to-identify-actual-hmm-viterbi-role-labeling.html 命名实体识别(N ...
- word2vec原理浅析
1.word2vec简介 word2vec,即词向量,就是一个词用一个向量来表示.是2013年Google提出的.word2vec工具主要包含两个模型:跳字模型(skip-gram)和连续词袋模型( ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- Nature重磅:Hinton、LeCun、Bengio三巨头权威科普深度学习
http://wallstreetcn.com/node/248376 借助深度学习,多处理层组成的计算模型可通过多层抽象来学习数据表征( representations).这些方法显著推动了语音识别 ...
随机推荐
- HDU 1171 0-1背包
最近感觉DP已经完全忘了..各种爆炸,打算好好复习一发,0-1背包开始 Big Event in HDU Problem Description Nowadays, we all know that ...
- 小知识:调整OCI实例的时区
之前在随笔中<Linux (RHEL)修改时区> 介绍了时区修改方法. 默认OCI实例中,时区是GMT,在国内用看着这个时区就是很别扭的事情,于是修改时区,实测无需配置 /etc/sysc ...
- C++算法之旅、08 基础篇 | 质数、约数
质数 在>1的整数中,如果只包含1和本身这两个约数,就被称为质数(素数) 866 试除法判定 866. 试除法判定质数 - AcWing题库 \(O(n)\) bool isprime(int ...
- Bridge 桥接模式简介与 C# 示例【结构型2】【设计模式来了_7】
〇.简介 1.什么是桥接模式? 一句话解释: 通过一个类的抽象,与另一个类的抽象关联起来,当做桥.此后不管两个抽象类的实现有多少种,均可以通过这个桥来将两个对象联系起来. 桥接,顾名思义就是用桥来 ...
- 实验四报告: 熟悉Python字典、集合、字符串的使用
实验目标 本实验的主要目标是熟悉Python中字典.集合.字符串的创建和操作,包括字典的创建.访问.修改和合并,集合的创建.访问以及各种集合运算,以及字符串的创建.格式化和常用操作. 实验要求 通过编 ...
- 从零用VitePress搭建博客教程(2) –VitePress默认首页和头部导航、左侧导航配置
2. 从零用VitePress搭建博客教程(2) –VitePress默认首页和头部导航.左侧导航配置 接上一节: 从零用VitePress搭建博客教程(1) – VitePress的安装和运行 四. ...
- vscode/sublime 语法高亮定义和代码段的区别
vscode插件数据格式基于json,sublime插件数据格式基于xml.sublime插件的官方文档说的不清楚,相关教程也很难找,遇到的一些坑记录一下 语法定义文件对比 同样使用TextMate定 ...
- 该如何选择ClickHouse的表引擎
该如何选择ClickHouse的表引擎 本文将介绍ClickHouse中一个非常重要的概念-表引擎(table engine).如果对MySQL熟悉的话,或许你应该听说过InnoDB和MyISAM存储 ...
- 持续集成指南:GitHubAction 自动构建+部署AspNetCore项目
前言 之前研究了使用 GitHub Action 自动构建和发布 nuget 包:开发现代化的.NetCore控制台程序:(4)使用GithubAction自动构建以及发布nuget包 现在更进一步, ...
- Qt中QTabWidget添加控件(按钮,label等)以及使用方法
今天遇到了一个问题,已经在QTabWidget每一行添加了一个按钮,我有一个需求就是,点击每一行的按钮都有各自的响应 首先说一下添加控件代码: 添加文字可以用setItem,添加控件就得用setCel ...