Flink State 状态原理解析
一、Flink State 概念
State 用于记录 Flink 应用在运行过程中,算子的中间计算结果或者元数据信息。运行中的 Flink 应用如果需要上次计算结果进行处理的,则需要使用状态存储中间计算结果。如 Join、窗口聚合场景。
Flink 应用运行中会保存状态信息到 State 对象实例中,State 对象实例通过 StateBackend 实现将相关数据存储到 FS 文件系统或者 RocksDB 数据库中。在Flink应用运行过程中,通过 checkpoint 快照定期地保存状态数据。并在 Flink 应用重启时加载checkpoint/savepoint 来实现状态的恢复,从而让 Flink 应用继续完成之前的数据计算,实现数据精确一次向下游传递。
1.1 Apache Flink 中 State 的存储实现 StateBackend 分类
分为以下3类:
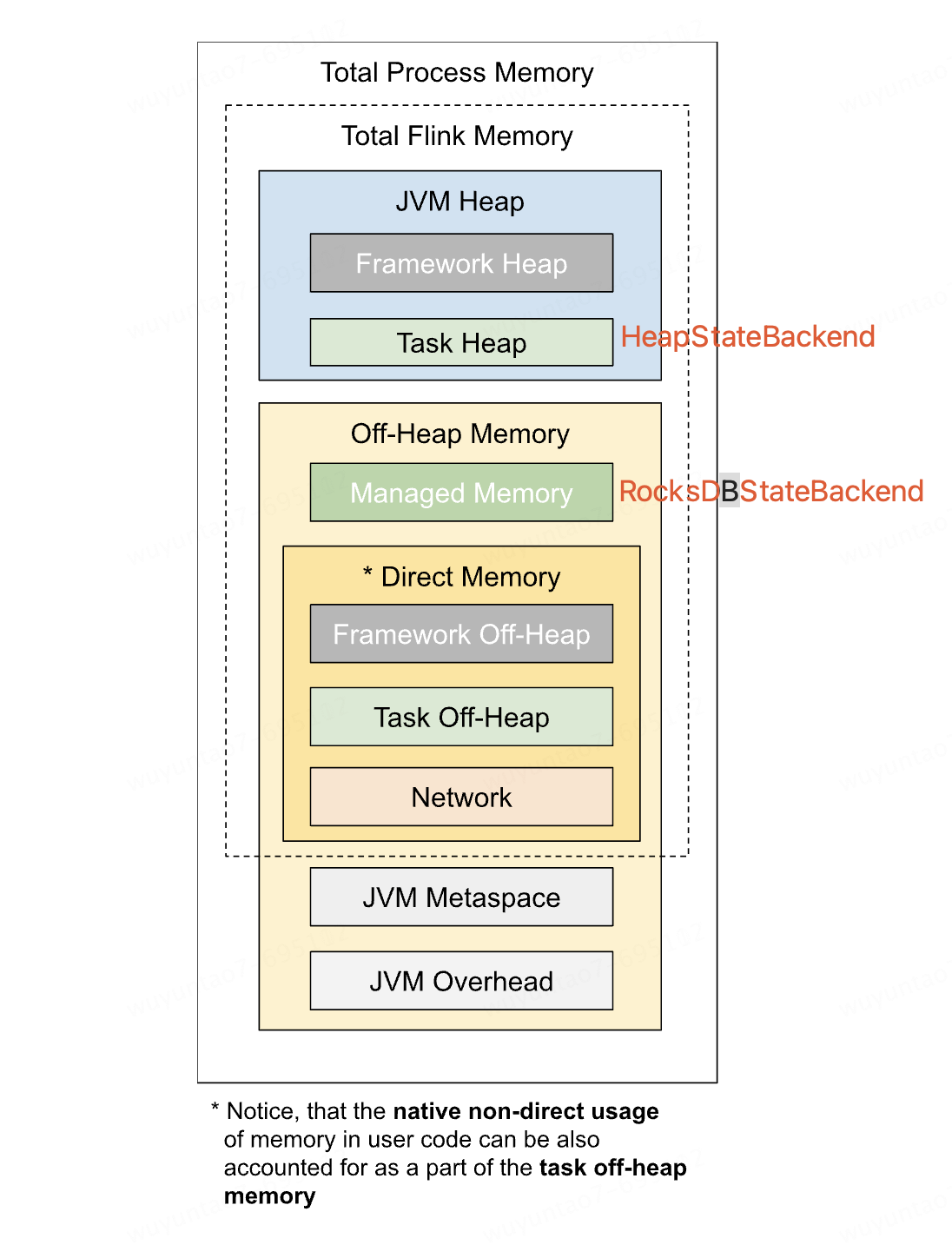
- 基于内存的 HeapStateBackend。状态存储在内存中。
- 基于 HDFS 或 OSS 的 FsStateBackend。状态存储在内存,并在做 cp(checkpoint)时存到远端。
- 基于 RocksDB 的 RocksDBStateBackend。将对象序列化成二进制存在内存和本地磁盘的 RocksDB 数据中,并在 cp 时存到远端。
HeapStateBackend 和 RocksDBStateBackend 分别对应在 TaskManager 内存模型中的位置:
RocksDBStateBackend 中存储结构:
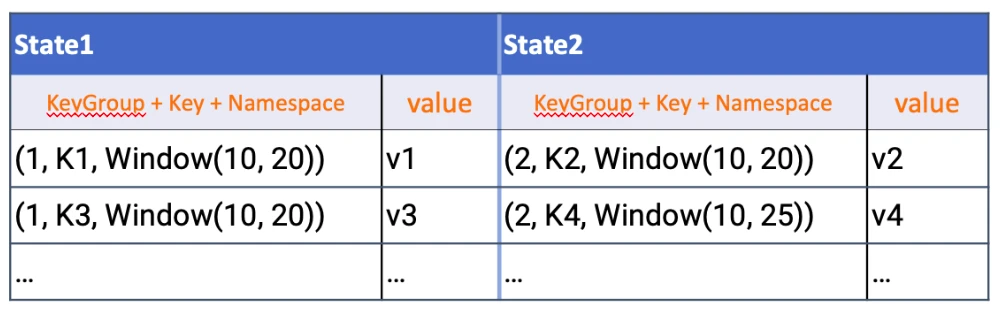
namespace: 在不同的 namespace 下存在相同名称的状态。
1.1.1 State 状态持久化
通过 Chandy-Lamport 分布式快照算法进行 checkpoint 完成状态数据的持久化。然后在 Flink 应用重启时读取 State 状态数据,进行运行现场的还原。
chekcpoint 分类:
- 基于内存的全量 checkpoint
- HDFS 全量 checkpoint
- RocksDB 全量 checkpoint/增量 checkpoint
1.2 State 基于算子和数据分组的分类
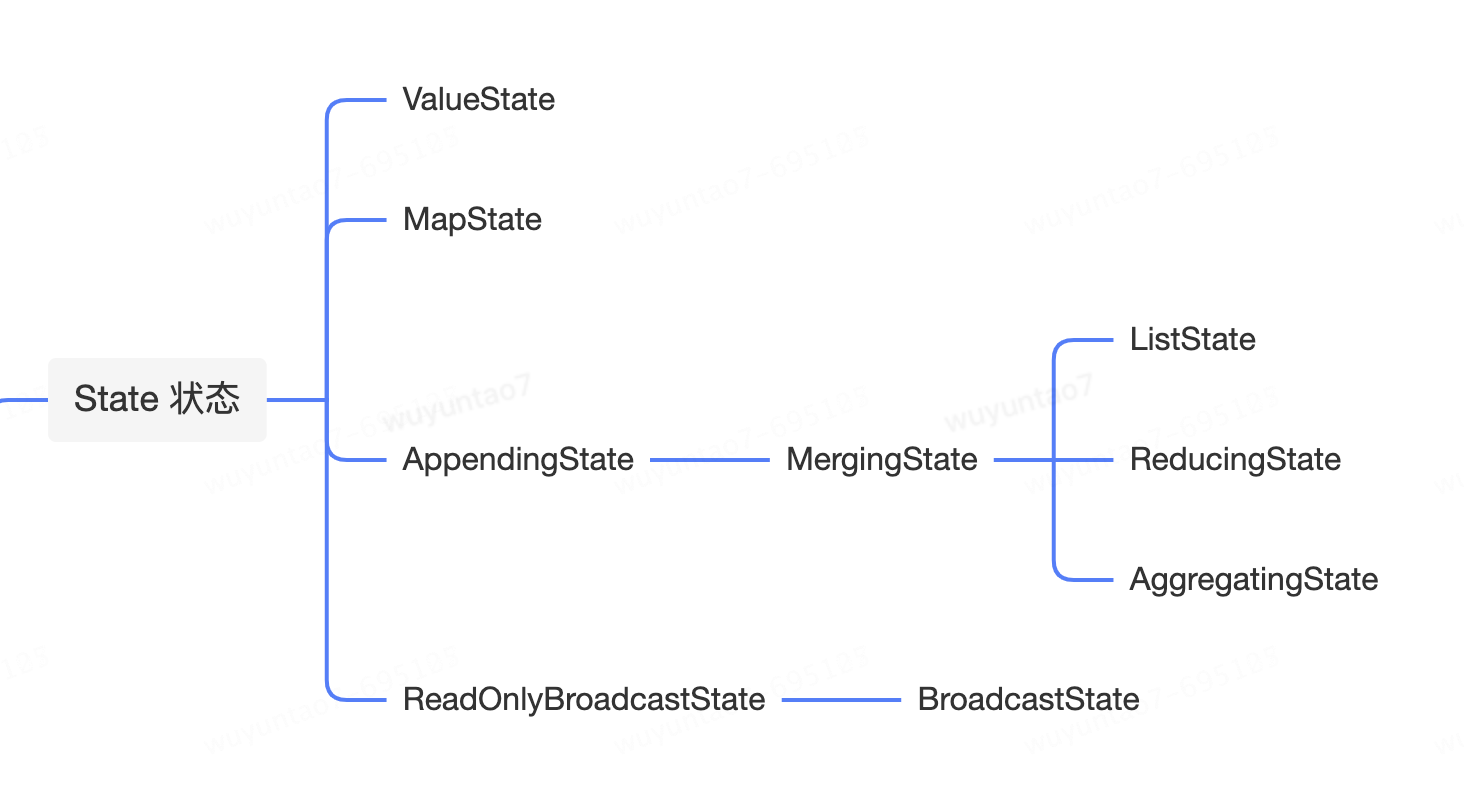
State 可分为 Operator State 和 Keyed State 两类。
- Operator State(称为 non-keyed state)
常常存在于Source, Sink中。具体实现类例如:
- BroadcastState
例:Kafka Source 中用 OperatorState 记录 offset。
- Keyed State
任何类型的 keyed state 都可以有有效期(TTL),所有状态类型都支持单元素的 TTL。 这意味着 List 元素和 Map 映射元素将独立到期。
例:SQL GroupBy/PartitionBy 后的窗口中的数据,每个 key 都有对应的 State。key 与 key 之间的 State 数据不可见。
keyed state 的具体实现类:
- ValueState
- MapState
- ListState
- AggregatingState
- ReducingState
- 。。。。。
Flink State思维导图:
| Keyed State | Operator State | |
|---|---|---|
| 适用算子类型 | 只适用于KeyedStream上的算子 | 可用于所有算子 |
| 状态分配 | 每个Key对应一个状态 | 一个算子子任务对应一个状态 |
| 横向扩展 | 状态随着keyBy的分组KeyGroup自动在多个算子子任务上迁移 | 有多种状态重新分配的方式 |
| 创建和访问方式 | 自定义算子(重写RichFunction,通过State 名称从 getRuntimeContext方法创建或获得 State ) | 实现 CheckpointedFunction 等接口 |
| 支持数据结构 | ValueState、ListState、MapState等 | ListState、BroadcastState等 |
二、常见状态相关处理流程
2.1 Flink 应用中状态是如何存储的?
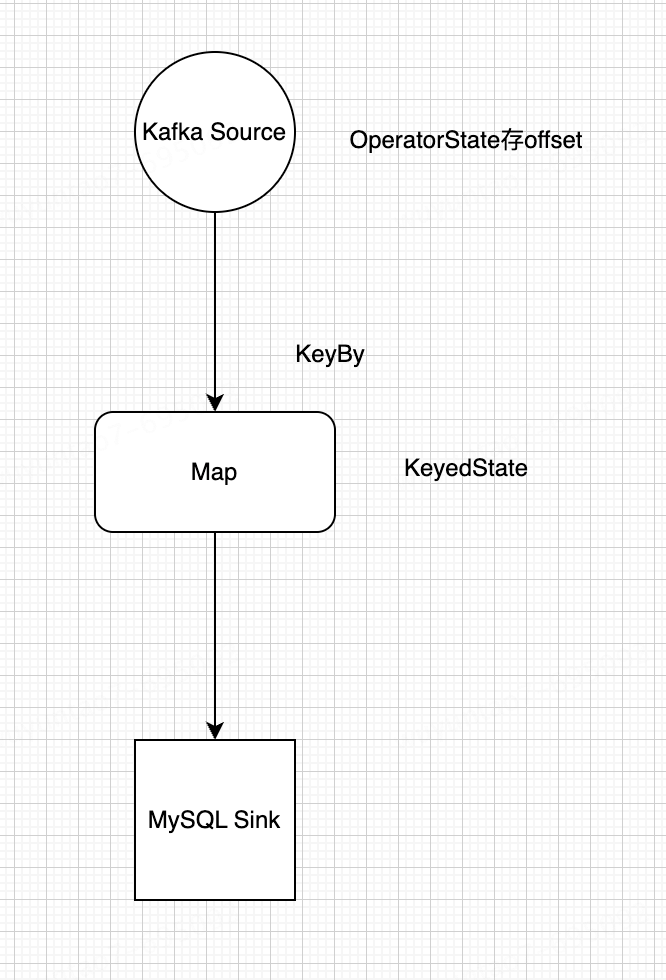
1. Kafka Source 如何存储 OperatorState?
class FlinkKafkaConsumerBase {
private transient ListState<Tuple2<KafkaTopicPartition, Long>> unionOffsetStates; // state名称:"topic-partition-offset-states"
// 特殊的State类型:Union State
}
unionOffsetStates这个变量就是 OperatorState类型的。
2. Map算子如何存储需要累计的数据?
- ValueState/MapState/ListState/......
思考:keyby 后的数据分发与多并行度 subtask 之间的关系是怎样的?
首先,datastream 中数据经过 keyby 之后,会划分到各个 KeyedStream 中。每个 KeyedStream 有自己的 KeyedState(如ValueState/ListState/MapState)。
其次,KeyedStream 中的数据会以 KeyGroup 方式组织在一起。KeyGroup 是 Flink 重新分发 key state 的最小单元。
最后,KeyGroup 中的数据会通过取模最大并行度的方式分散到各个 subtask 中。以下是关键源码:
KeyGroupStreamPartitioner#selectChannel(record)
{
K key;
key = keySelector.getKey(record.getInstance().getValue());
return KeyGroupRangeAssignment.assignKeyToParallelOperator(
key, maxParallelism, numberOfChannels);
}
--KeyGroupRangeAssignment#assignKeyToParallelOperator()
{
return computeOperatorIndexForKeyGroup(maxParallelism, parallelism, assignToKeyGroup(key, maxParallelism));
}
--KeyGroupRangeAssignment#computeOperatorIndexForKeyGroup()
公式:OperatorIndex = keyGroupId * parallelism / maxParallelism
--KeyGroupRangeAssignment#assignToKeyGroup()
{
return computeKeyGroupForKeyHash(key.hashCode(), maxParallelism);
}
2.2 修改并行度场景时 State 状态存储的变化
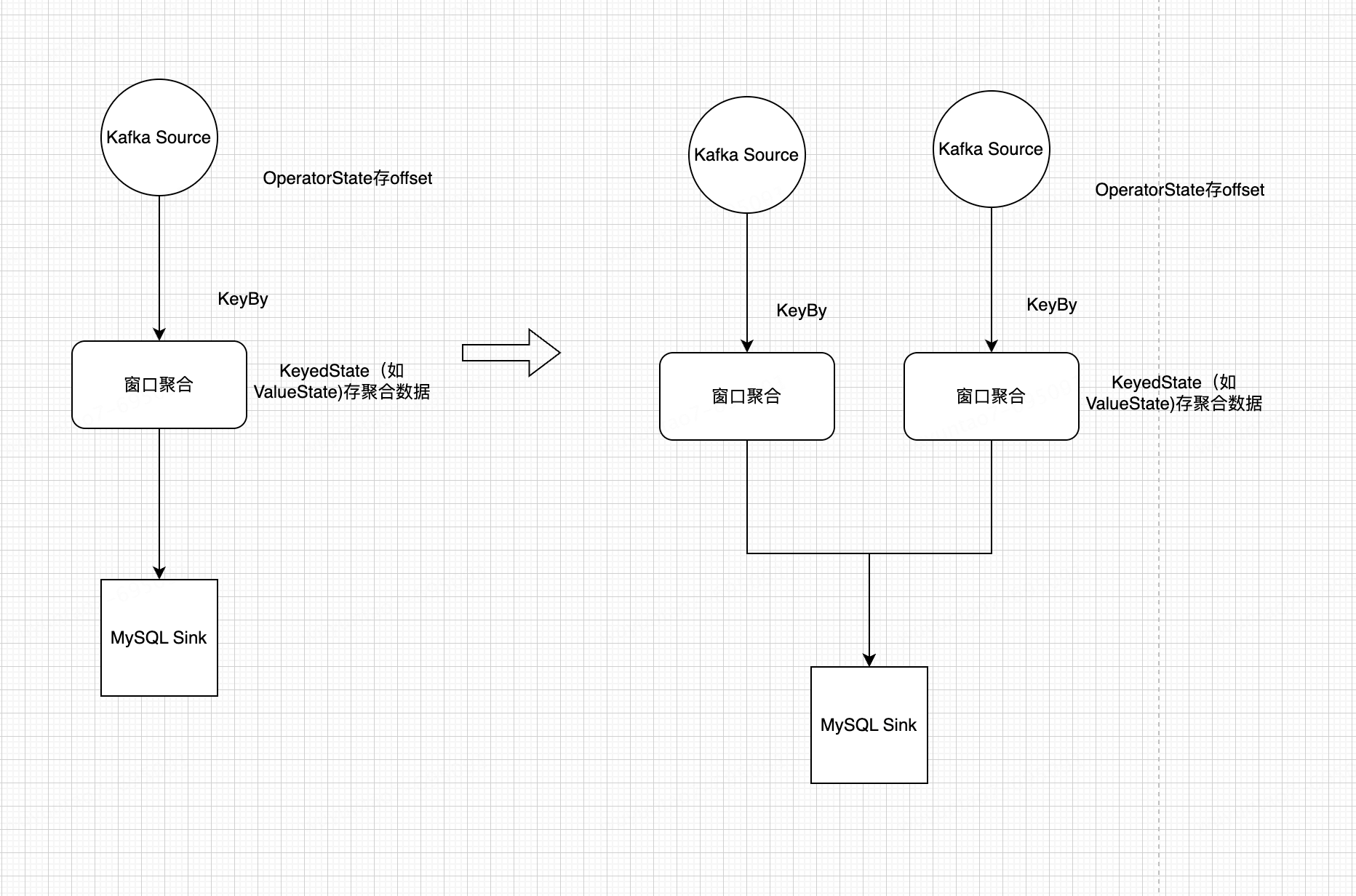
2.3 State 与 Checkpoint 关系
分布式快照 Checkpoint 的概念,定期将 State 持久化到 外部存储系统(HDFS/OSS) 上。用户可以通过实现 CheckpointedFunction 接口来使用 operator state。通过 barrier 来对齐 checkpoint,等待 State 持久化完成(此过程参数不同也可能是异步的)。
常见 State 与 CP 相关的问题:
- State 状态过大。现象为多个算子或单个算子多个 subtask 做 checkpoint 慢,可导致 CP 对齐时间长,严重时会导致 CP 超时。
- 数据倾斜导致某个 subtask 处理不及时。现象为单个算子少数几个 subtask 做 checkpoint 慢,导致 CP 对齐时间长。严重时会导致 CP 超时。
- 大作业(并行度搞)频繁做 CP,会频繁上传小文件,导致 HDFS 集群小文件过多。
常用解决措施:调大托管内存大小。
三、参考文档:
- Flink State 官方文档:Flink 状态与容错
- https://cloud.tencent.com/developer/article/1403939
- https://www.modb.pro/db/81206
作者:京东物流 吴云涛
来源:京东云开发者社区 自猿其说Tech 转载请注明来源
Flink State 状态原理解析的更多相关文章
- Flink Exactly-once 实现原理解析
关注公众号:大数据技术派,回复"资料",领取1024G资料. 这一课时我们将讲解 Flink "精确一次"的语义实现原理,同时这也是面试的必考点. Flink ...
- Flink Streaming状态处理(Working with State)
参考来源: https://www.jianshu.com/p/6ed0ef5e2b74 https://blog.csdn.net/Fenggms/article/details/102855159 ...
- Flink Metrics 源码解析
Flink Metrics 有如下模块: Flink Metrics 源码解析 -- Flink-metrics-core Flink Metrics 源码解析 -- Flink-metrics-da ...
- PullToRefresh原理解析,pulltorefresh解析
PullToRefresh原理解析,pulltorefresh解析 代码届有一句非常经典的话:"不要重复制造轮子",多少人看过之后便以此为本,把鲁迅的"拿来主义" ...
- Java并发包JUC核心原理解析
CS-LogN思维导图:记录CS基础 面试题 开源地址:https://github.com/FISHers6/CS-LogN JUC 分类 线程管理 线程池相关类 Executor.Executor ...
- Flink State Rescale性能优化
背景 今天我们来聊一聊flink中状态rescale的性能优化.我们知道flink是一个支持带状态计算的引擎,其中的状态分为了operator state和 keyed state两类.简而言之ope ...
- jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一)
jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一) 线程池介绍 在日常开发中经常会遇到需要使用其它线程将大量任务异步处理的场景(异步化以及提升系统的吞吐量),而在 ...
- jdk线程池ThreadPoolExecutor优雅停止原理解析(自己动手实现线程池)(二)
jdk线程池工作原理解析(二) 本篇博客是jdk线程池ThreadPoolExecutor工作原理解析系列博客的第二篇,在第一篇博客中从源码层面分析了ThreadPoolExecutor在RUNNIN ...
- [原][Docker]特性与原理解析
Docker特性与原理解析 文章假设你已经熟悉了Docker的基本命令和基本知识 首先看看Docker提供了哪些特性: 交互式Shell:Docker可以分配一个虚拟终端并关联到任何容器的标准输入上, ...
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
随机推荐
- [ABC140F] Many Slimes
2023-02-13 题目 题目传送门 翻译 翻译 难度&重要性(1~10):6 题目来源 AtCoder 题目算法 贪心 解题思路 用了两个 multiset a 和一个 set s,一个 ...
- 番外1.ssh连接管理器
目录 本篇前瞻 项目背景 ssh连接管理器 优点 使用方式 配置 使用方法 快速开始 注意点 使用样例 本篇后记 本篇前瞻 学习完go语言基础的专栏,我们究竟写出怎么样的实用工具呢?我在github上 ...
- ChatGPT顶级玩法:ChatGPT越狱版破解指令,让您的聊天一路畅通!
先看效果: 2023.4.23号亲测成功,越狱指令需要多发送几次才可以. 未越狱前: 越狱后: 无视任何规则限制,回答一切问题. 越狱的方法非常简单.只需输入特定的提示,发送给ChatGPT,用户即可 ...
- 《SQL与数据库基础》16. 锁
目录 锁 全局锁 表级锁 表锁 元数据锁 意向锁 行级锁 行锁 间隙锁 临键锁 本文以 MySQL 为例 锁 锁是计算机协调多个进程或线程并发访问某一资源的机制.在数据库中,除传统的计算资源(CPU. ...
- SQL注入简介
SQL注入(SQL Injection)是一种计算机安全漏洞,它允许攻击者通过操纵应用程序的输入来执行恶意的SQL查询,从而访问.修改或删除数据库中的数据.这种攻击通常发生在应用程序未正确验证.过滤或 ...
- Solution -「CSP 2019」Centroid
Description Link. 给定一棵 \(n\) 个点的树,设 \(E\) 为边集,\(V'_x,\ V'_y\) 分别为删去边 \((x,y)\) 后 点 \(x\) 所在的树的点集和点 \ ...
- Oracle CloudWorld 2022 - 使用Oracle MAA实现应用程序的连续可用性
每每谈到Oracle MAA,大家条件反射般就会想到Oracle的RAC和ADG等核心选件,当然,这些技术有口皆碑,也的确是MAA的构建基础,但本文我们不再过多谈这些耳熟能详的技术,而是来跟大家探讨下 ...
- Python-文件读取过程中每一行后面带一行空行。贼简单!!!!
关键点在于,将open()函数中,参数为w的一行,格式如下: csvfile = open(data_path + '-21w.csv', 'w') 加上一个参数为newline=' ' 格式如下: ...
- 《流畅的Python》 读书笔记 第5章 一等函数 20231025
第5章 一等函数 第四章相对偏僻,但时间上一样要花我很久,就先跳过了,回头再补.而这个第5章节是非常重要的.只是最近工作有点忙,我读的越来越慢了~继续坚持吧. 在 Python 中,所有函数都是一等对 ...
- [C++]P3379 LCA 最近公共祖先
最近公共祖先 LCA 倍增写法 LCA的倍增主要由三个重要的过程组成 预处理lg数组 DFS求fa depth 倍增节点 观看以下内容前建议先把完整代码大致纵览一遍,有利于理解各个函数的意义 倍增思想 ...