【一】MADDPG-单智能体|多智能体总结(理论、算法)
相关文章:
【二】MADDPG--单智能体|多智能体总结算法实现--【追逐游戏】
1.单智能体
连续动作(赛车游戏中方向盘的角度,油门,刹车控制信息,通信中功率控制,可由policy gradient、DDPG、A3C、PPO算法做决策)和离散动作(围棋、贪吃蛇游戏,Alpha Go,可通过算法Q-Learning、DQN、A3C及PPO算法做决策)。
算法分类:
强化学习中有很多算法来寻找最优策略。另外,算法有很多分类。
1、按照有无模型分:有模型(事先知道转移概率P,并且作为输入,算法为动态规划)、无模型(试错,事先不知道转移概率P,算法为:蒙特卡罗算法、Q-Learning、Sarsa、Policy Gradients);
2、基于策略(输出下一步所采取的各种动作的概率,根据概率来采取动作:Policy Gradients)和基于价值(输出所有动作的价值,根据最高价值来选动作,不适用于连续动作:Q-Learning,Sarsa等)(由于基于策略和价值的算法都各有优缺点,由此集合在一起就有了Actor-Critic算法,其中Actor可以基于概率做出动作,而Critic会对做出的动作做出动作的价值,这就在前述的policy gradients上加速了学习过程);
3、单步更新(游戏中每一步都在更新,可以边玩边学习:QLearning、Sarsa、升级版的policy
gradients)和回合更新(游戏开始后,等游戏结束,再总结所有转折点,在更新行为准则:基础版的policy gradients、Monte-carlo learning);
4、在线学习(必须我本人在场,边玩边学:一般只有一个策略,最常见的是e-贪婪,即SARSA算法)、离线学习(从过往的经验里,但是过往的经验没必要是自己的:一般有两个策略,常见的是e-贪婪来选择新的动作,另一个贪婪法更新价值函数,即,常见的Q-Learning)。
5、千万注意,一定要明确不同的强化学习算法的优缺点以便于求解不同类型的问题。比如:Q-Learning适合解决低纬度且离散动作及状态空间,DQN适合解决低纬度动作和高纬度状态空间、DDPG适合求解高纬度(连续)动作空间及状态空间。
产生问题:
1–传统的多智能体RL算法中,每个智能体走势在不断学习且改进其策略。由此,从每个智能体的角度来看,环境是不稳定的,不利于收敛。而传统的单智能体强化学习,需要稳定的环境
2–由于环境的不稳定,无法通过仅改变智能体本身的策略来适应动态不稳定的环境。
3–由于环境的不稳定,无法直接使用经验回放等DQN技巧。
4–因为大量智能体的交互会导致不可避免的反馈开销。更重要的是,生成的马尔可夫过程通常很难处理。用于MDP的数值求解技术遭受所谓的“维数诅咒”,这使它们在计算上不可行。
2.多智能体
 (转)
(转)
1-如图所示,多智能体系统中至少有两个智能体。另外,智能体之间存在着一定的关系,如合作关系,竞争关系,或者同时存在竞争与合作的关系。每个智能体最终所获得的回报不仅仅与自身的动作有关系,还跟对方的动作有关系。
2-多智能体强化学习的描述:马尔可夫博弈。状态转换符合马尔可夫过程,关系符合博弈。可以表示为<N,S,A,Ri,T>,其中,N表示的是智能体的集合,S表示的是环境的状态空间、Ai表示的是智能体i的动作空间,A=A1A2…An表示为联合动作,R表示智能体i的奖励,T为状态转换函数。
3-一般来说,在马尔可夫博弈中,每个智能体的目标为找到最优策略来使它在任意状态下获得最大的长期累积奖励。
2.1 Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
论文下载:【https://download.csdn.net/download/sinat_39620217/16203960】

- Multi-Agent:多智能体
- Deep:与DQN类似,使用目标网络+经验回放
- Deterministic:直接输出确定性的动作
- Policy Gradient: 基于策略Policy来做梯度下降从而优化模型
1.不过传统的RL方法,比如Q-Learning或者policy gradient都不适用于多智能体环境。主要的问题是,在训练过程中,每个智能体的策略都在变化,因此从每个智能体的角度来看,环境变得十分不稳定(其他智能体的行动带来环境变化)。对DQN来说,经验重放的方法变的不再适用(如果不知道其他智能体的状态,那么不同情况下自身的状态转移会不同),而对PG的方法来说,环境的不断变化导致了学习的方差进一步增大。
2. 本文提出的方法框架是集中训练,分散执行的。我们先回顾一下DDPG的方式,DDPG本质上是一个AC方法。训练时,Actor根据当前的state选择一个action,然后Critic可以根据state-action计算一个Q值,作为对Actor动作的反馈。Critic根据估计的Q值和实际的Q值来进行训练,Actor根据Critic的反馈来更新策略。测试时,我们只需要Actor就可以完成,此时不需要Critic的反馈。因此,在训练时,我们可以在Critic阶段加上一些额外的信息来得到更准确的Q值,比如其他智能体的状态和动作等,这也就是集中训练的意思,即每个智能体不仅仅根据自身的情况,还根据其他智能体的行为来评估当前动作的价值。分散执行指的是,当每个Agent都训练充分之后,每个Actor就可以自己根据状态采取合适的动作,此时是不需要其他智能体的状态或者动作的。DQN不适合这么做,因为DQN训练和预测是同一个网络,二者的输入信息必须保持一致,我们不能只在训练阶段加入其他智能体的信息。
3. DDPG它是Actor-Critic 和 DQN 算法的结合体。
我们首先来看Deep,正如Q-learning加上一个Deep就变成了DQN一样,这里的Deep即同样使用DQN中的经验池和双网络结构来促进神经网络能够有效学习。
再来看Deterministic,即我们的Actor不再输出每个动作的概率,而是一个具体的动作,这更有助于我们连续动作空间中进行学习。
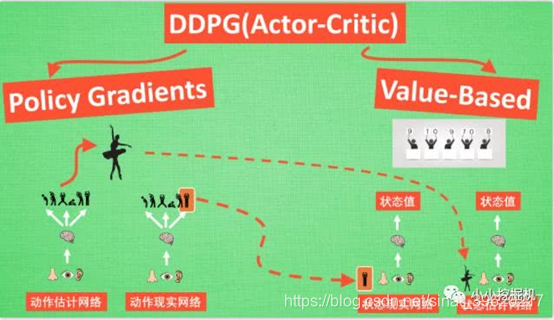
采用了类似DQN的双网络结构,而且Actor和Critic都有target-net和eval-net。我们需要强调一点的事,我们只需要训练动作估计网络和状态估计网络的参数,而动作现实网络和状态现实网络的参数是由前面两个网络每隔一定的时间复制过去的。
我们先来说说Critic这边,Critic这边的学习过程跟DQN类似,我们都知道DQN根据下面的损失函数来进行网络学习,即现实的Q值和估计的Q值的平方损失:

上面式子中Q(S,A)是根据状态估计网络得到的,A是动作估计网络传过来的动作。而前面部分R + gamma * maxQ(S',A')是现实的Q值,这里不一样的是,我们计算现实的Q值,不在使用贪心算法,来选择动作A',而是动作现实网络得到这里的A'。总的来说,Critic的状态估计网络的训练还是基于现实的Q值和估计的Q值的平方损失,估计的Q值根据当前的状态S和动作估计网络输出的动作A输入状态估计网络得到,而现实的Q值根据现实的奖励R,以及将下一时刻的状态S'和动作现实网络得到的动作A' 输入到状态现实网络 而得到的Q值的折现值加和得到(这里运用的是贝尔曼方程)。
 (DDPG)
(DDPG)
传统的DQN采用target-net网络参数更新,即每隔一定的步数就将eval-net中的网络参数赋值过去,而在DDPG中,采用的target-net网络参数更新,即每一步都对target-net网络中的参数更新一点点,这种参数更新方式经过试验表明可以大大的提高学习的稳定性。

每个Agent的训练同单个DDPG算法的训练过程类似,不同的地方主要体现在Critic的输入上:在单个Agent的DDPG算法中,Critic的输入是一个state-action对信息,但是在MADDPG中,每个Agent的Critic输入除自身的state-action信息外,还可以有额外的信息,比如其他Agent的动作。
【一】MADDPG-单智能体|多智能体总结(理论、算法)的更多相关文章
- [译]基于GPU的体渲染高级技术之raycasting算法
[译]基于GPU的体渲染高级技术之raycasting算法 PS:我决定翻译一下<Advanced Illumination Techniques for GPU-Based Volume Ra ...
- C/C++中结构体总结笔记
结构体的定义方式 在C/C++中结构体的定义方式有很多种,做个简单的总结. 定义方式1: struct st{ int a; }; 定义方式2: struct _st{ int a; } st; 定义 ...
- 【VS开发】【智能语音处理】DTW算法(语音识别)
DTW主要是应用在孤立词识别的算法,用来识别一些特定的指令比较好用,这个算法是基于DP(动态规划)的算法基础上发展而来的.这里介绍语音识别就先介绍下语音识别的框架,首先我们要有一个比对的模版声音,然后 ...
- TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- DRL 教程 | 如何保持运动小车上的旗杆屹立不倒?TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- 3D打印:三维智能数字化创造(全彩)
3D打印:三维智能数字化创造(全彩)(全球第一本系统阐述3D打印与3D智能数字化的专业著作) 吴怀宇 编 ISBN 978-7-121-22063-0 2014年1月出版 定价:99.00元 42 ...
- iOS开发——C篇&结构体与枚举
一:结构体与枚举的介绍: 结构体与枚举:是一种存储复杂的数据结构体:是用户自定义的一种类型,不同类型的集合,而数组是相同类型变量的集合. 二:结构体的创建 struct user { char ...
- C学习之结构体
结构体(struct) 结构体是由基本数据类型构成的.并用一个标识符来命名的各种变量的组合,结构体中可以使用不同的数据类型. 1. 结构体说明和结构体变量定义 在Turbo C中, 结构体也是一种数据 ...
- 数据库顶会VLDB论文解读:阿里数据库智能参数优化的创新与实践
前言 一年一度的数据库领域顶级会议VLDB 2019于美国当地时间8月26日-8月30日在洛杉矶召开.在本届大会上,阿里云数据库产品团队多篇论文入选Research Track和Industrial ...
- 奇点云 x 阿里云 | 联合发布综合体数字化转型与数据创新解决方案
2019年7月25日下午,在阿里云峰会上海站,奇点云入选阿里云首批联合解决方案合作伙伴,并联合发布了“综合体数字化转型与数据创新解决方案”,共同探索综合体的智能服务. 关于综合体的数字化转型,奇点云联 ...
随机推荐
- 发布会回放|Gradio 4.0 正式发布!
Gradio 的目标是使机器学习模型的演示更容易定制和访问,以满足不同用户的需求.在 4.0 正式版的发布活动上,Hugging Face 的 Gradio 团队介绍了自己为了提高机器学习模型的可访问 ...
- -bash: /home/advert/bin/vim: No such file or directory
今天advert用户使用vim时,突然报错 -bash: /home/advert/bin/vim: No such file or directory 之前还好好的,且其他用户都能用vim,查看也是 ...
- 【Cpp】RTTI 机制原理解析
References Baidu Wiki C++中的RTTI机制详解 RTTI 推荐阅读: RTTI 原理 推荐阅读:C++中的RTTI机制 什么是RTTI机制? RTTI 是"Runti ...
- 通过 Homebrew 在 Mac OS X 上安装和配置 Redis
通过使用 Homebrew,可以大大降低在 Mac OS X 上设置和配置开发环境的成本. 让我们安装 Redis. $ brew install redis 安装后,我们将看到一些有关配置注意事项的 ...
- AtCoder Beginner Contest 204 (AB水题,C题DFS,D题位运算DP,E题BFS好题)
补题链接:Here A - Rock-paper-scissors 石头剪刀布,两方是一样的则输出该值,否则输出该值 int s[4] = {0, 1, 2}; void solve() { int ...
- Redis 中bitMap使用及实现访问量
1. Bitmap 是什么 Bitmap(也称为位数组或者位向量等)是一种实现对位的操作的'数据结构',在数据结构加引号主要因为: Bitmap 本身不是一种数据结构,底层实际上是字符串,可以借助字符 ...
- Redis 使用 hyperLogLog 实现请求ip去重的浏览量
本文为博主原创,转载请注明出处: 未完,待续....
- JMS微服务项目模板
项目模板下载地址 vs2022模板:JMS.MicroServiceProjectTemplate2022.zip vs2019模板:JMS.MicroServiceHost.zip 说明 把压缩包解 ...
- PG数据库存储验证
PG数据库存储验证 背景 最近学习了SQLServer数据库的varchar和nvarchar的存储 想到PG数据库其实没让选择字符集,也没有nvarchar 所以想学习一下nvarchar的使用情况 ...
- [转帖]Windows自带MD5 SHA1 SHA256命令行工具
https://www.cnblogs.com/huangrt/p/13961399.html 检验工具http://www.zdfans.com/html/4346.html HashMyFiles ...