OCR文字检测与识别系统:融合文字检测、文字识别和方向分类器的综合解决方案
1. OCR文字检测与识别系统:融合文字检测、文字识别和方向分类器的综合解决方案
前两章主要介绍了DBNet文字检测算法以及CRNN文字识别算法。然而对于我们实际场景中的一张图像,想要单独基于文字检测或者识别模型,是无法同时获取文字位置与文字内容的,因此,我们将文字检测算法以及文字识别算法进行串联,构建了PP-OCR文字检测与识别系统。在实际使用过程中,检测出的文字方向可能不是我们期望的方向,最终导致文字识别错误,因此我们在PP-OCR系统中也引入了方向分类器。
本章主要介绍PP-OCR文字检测与识别系统以及该系统中涉及到的优化策略。通过本节课的学习,您可以获得:
- PaddleOCR策略调优技巧
- 文本检测、识别、方向分类器模型的优化技巧和优化方法
PP-OCR系统共经历了2次优化,下面对PP-OCR系统和这2次优化进行简单介绍。
1.1 PP-OCR系统与优化策略简介
PP-OCR中,对于一张图像,如果希望提取其中的文字信息,需要完成以下几个步骤:
- 使用文本检测的方法,获取文本区域多边形信息(PP-OCR中文本检测使用的是DBNet,因此获取的是四点信息)。
- 对上述文本多边形区域进行裁剪与透视变换校正,将文本区域转化成矩形框,再使用方向分类器对方向进行校正。
- 基于包含文字区域的矩形框进行文本识别,得到最终识别结果。
上面便完成了对于一张图像的文本检测与识别过程。
PP-OCR的系统框图如下所示。
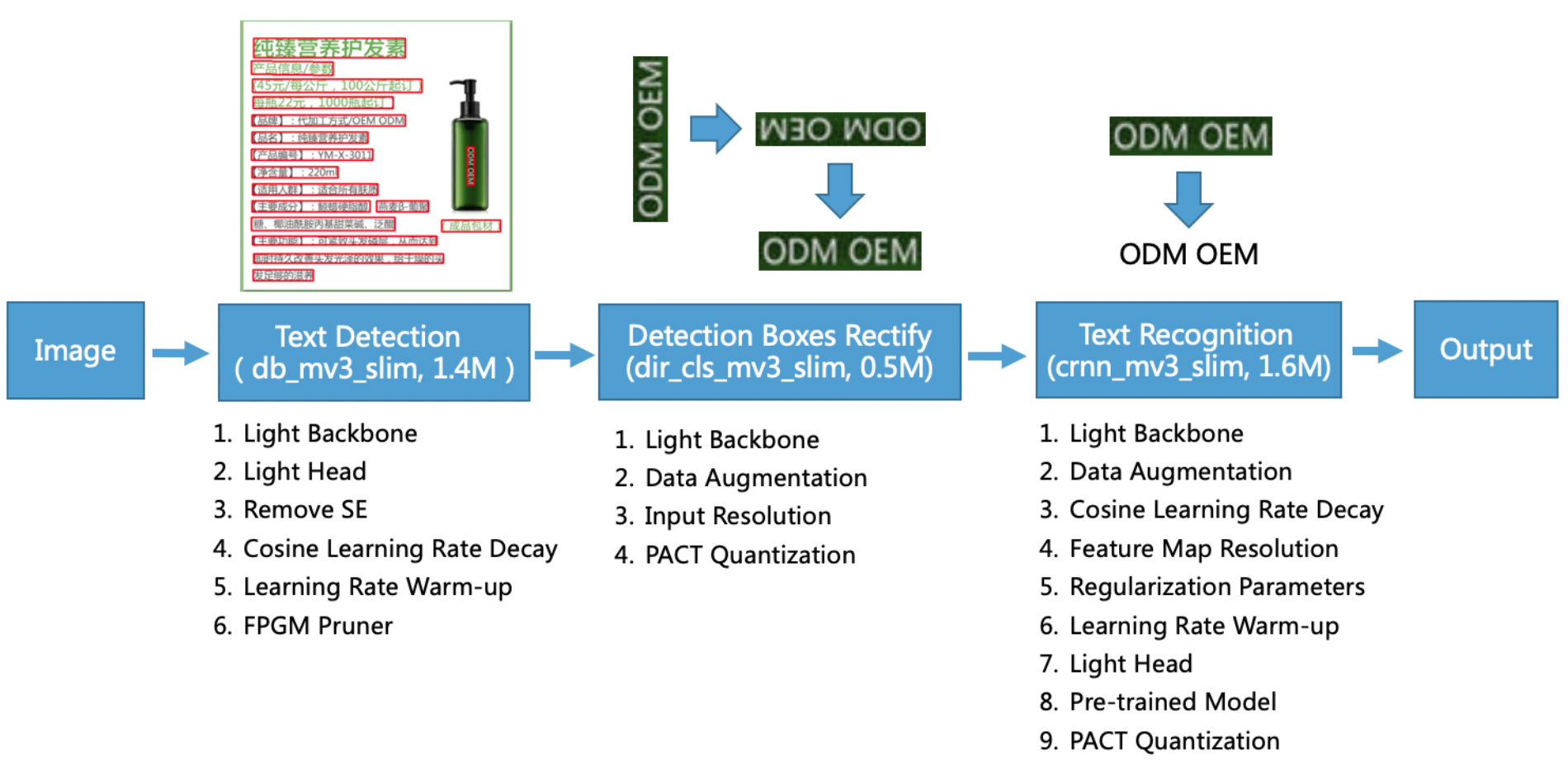
PP-OCR系统框图
文本检测基于后处理方案比较简单的DBNet,文字区域校正主要使用几何变换以及方向分类器,文本识别使用了基于融合了卷积特征与序列特征的CRNN模型,使用CTC loss解决预测结果与标签不一致的问题。
PP-OCR从骨干网络、学习率策略、数据增广、模型裁剪量化等方面,共使用了19个策略,对模型进行优化瘦身,最终打造了面向服务器端的PP-OCR server系统以及面向移动端的PP-OCR mobile系统。
1.2 PP-OCRv2系统与优化策略简介
相比于PP-OCR, PP-OCRv2 在骨干网络、数据增广、损失函数这三个方面进行进一步优化,解决端侧预测效率较差、背景复杂以及相似字符的误识等问题,同时引入了知识蒸馏训练策略,进一步提升模型精度。具体地:
- 检测模型优化: (1) 采用 CML 协同互学习知识蒸馏策略;(2) CopyPaste 数据增广策略;
- 识别模型优化: (1) PP-LCNet 轻量级骨干网络;(2) U-DML 改进知识蒸馏策略; (3) Enhanced CTC loss 损失函数改进。
从效果上看,主要有三个方面提升:
- 在模型效果上,相对于 PP-OCR mobile 版本提升超7%;
- 在速度上,相对于 PP-OCR server 版本提升超过220%;
- 在模型大小上,11.6M 的总大小,服务器端和移动端都可以轻松部署。
PP-OCRv2 模型与之前 PP-OCR 系列模型的精度、预测耗时、模型大小对比图如下所示。
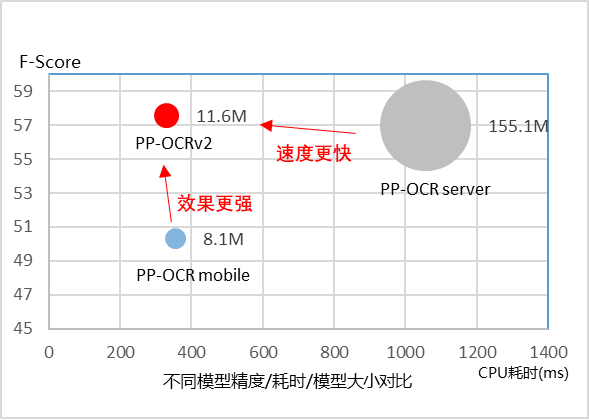
PP-OCRv2与PP-OCR的速度、精度、模型大小对比
PP-OCRv2的系统框图如下所示。
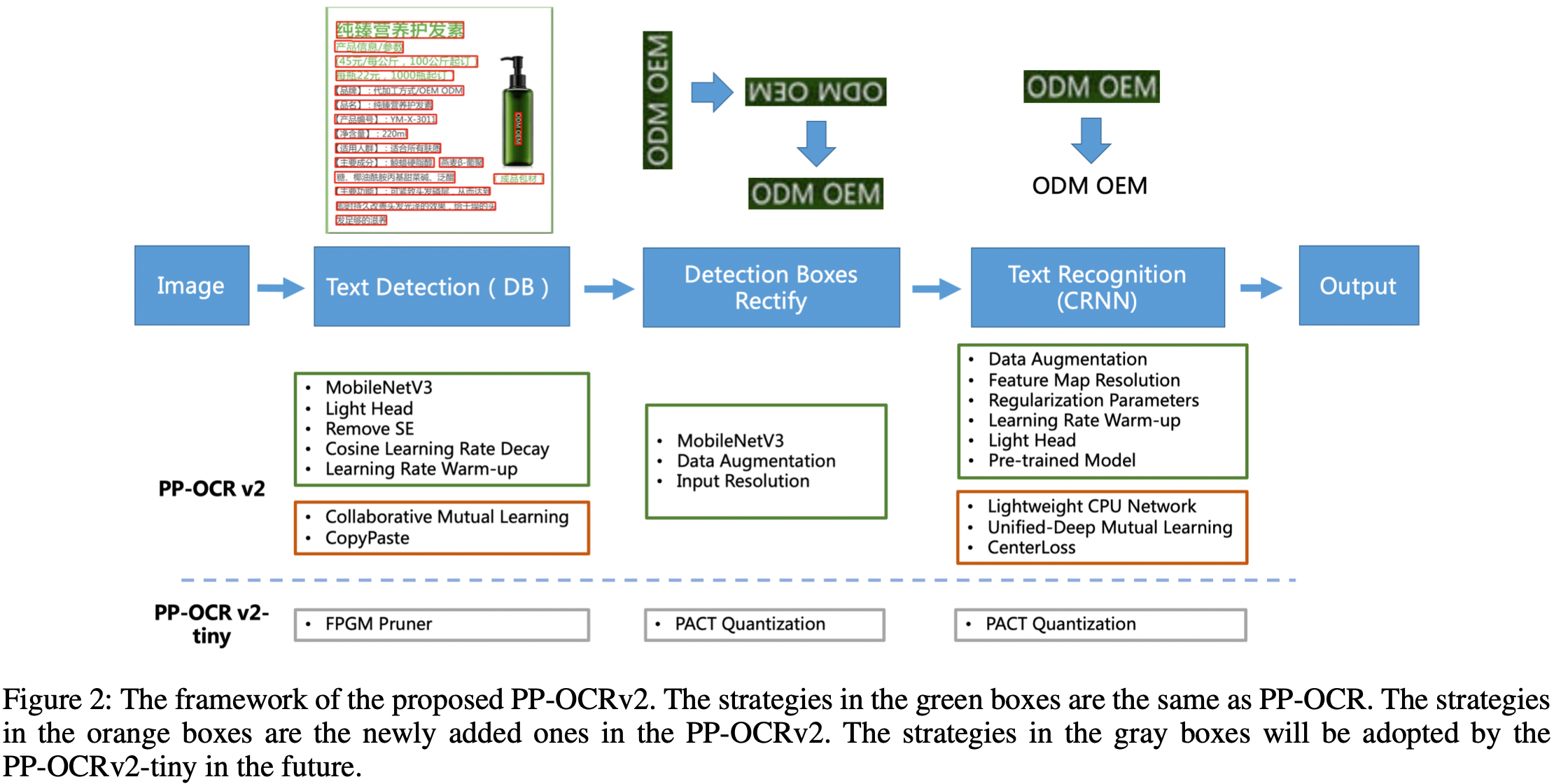
PP-OCRv2系统框图
2. PP-OCR 优化策略
PP-OCR系统包括文本检测器、方向分类器以及文本识别器。本节针对这三个方向的模型优化策略进行详细介绍。
2.1 文本检测
PP-OCR中的文本检测基于DBNet (Differentiable Binarization)模型,它基于分割方案,后处理简单。DBNet的具体模型结构如下图。
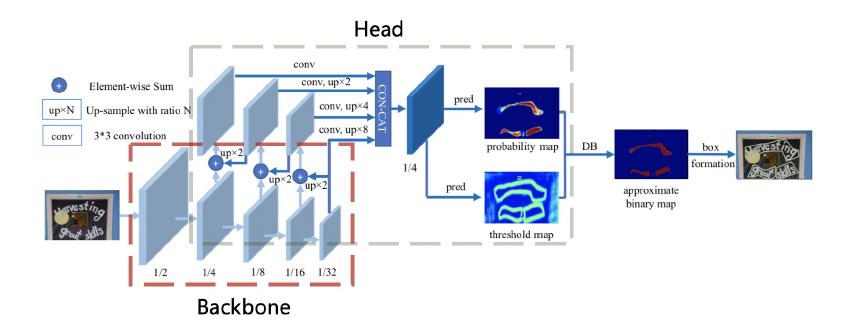
DBNet框图
DBNet通过骨干网络(backbone)提取特征,使用DBFPN的结构(neck)对各阶段的特征进行融合,得到融合后的特征。融合后的特征经过卷积等操作(head)进行解码,生成概率图和阈值图,二者融合后计算得到一个近似的二值图。计算损失函数时,对这三个特征图均计算损失函数,这里把二值化的监督也也加入训练过程,从而让模型学习到更准确的边界。
DBNet中使用了6种优化策略用于提升模型精度与速度,包括骨干网络、特征金字塔网络、头部结构、学习率策略、模型裁剪等策略。在验证集上,不同模块的消融实验结论如下所示。
DBNet消融实验
下面进行详细说明。
2.1.1 轻量级骨干网络
骨干网络的大小对文本检测器的模型大小有重要影响。因此,在构建超轻量检测模型时,应选择轻量的骨干网络。随着图像分类技术的发展,MobileNetV1、MobileNetV2、MobileNetV3和ShuffleNetV2系列常用作轻量骨干网络。每个系列都有不同的模型大小和性能表现。PaddeClas提供了20多种轻量级骨干网络。他们在ARM上的精度-速度曲线如下图所示。
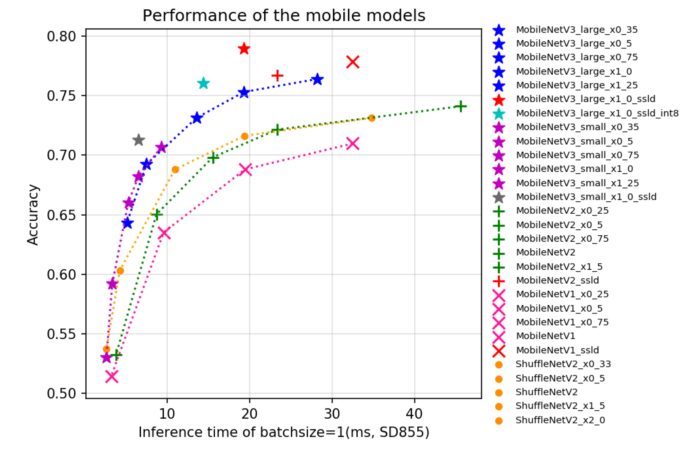
PaddleClas中骨干网络的"速度-精度"曲线
在预测时间相同的情况下,MobileNetV3系列可以实现更高的精度。作者在设计的时候为了覆盖尽可能多的场景,使用scale这个参数来调整特征图通道数,标准为1x,如果是0.5x,则表示该网络中部分特征图通道数为1x对应网络的0.5倍。为了进一步平衡准确率和效率,在V3的尺寸选择上,我们采用了MobileNetV3_large 0.5x的结构。
下面打印出DBNet中MobileNetV3各个阶段的特征图尺寸。
2.1.2 轻量级特征金字塔网络DBFPN结构
文本检测器的特征融合(neck)部分DBFPN与目标检测任务中的FPN结构类似,融合不同尺度的特征图,以提升不同尺度的文本区域检测效果。
为了方便合并不同通道的特征图,这里使用1×1的卷积将特征图减少到相同数量的通道。
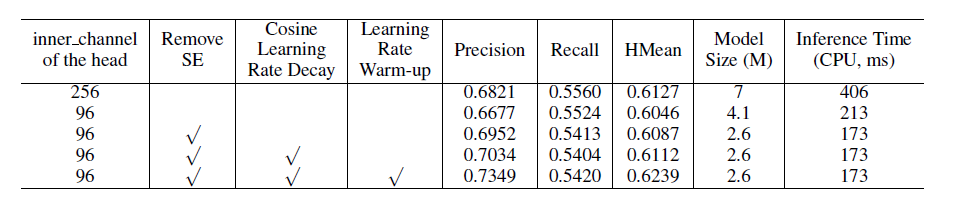
概率图和阈值图是由卷积融合的特征图生成的,卷积也与inner_channels相关联。因此,inner_channels对模型尺寸有很大的影响。当inner_channels由256减小到96时,模型尺寸由7M减小到4.1M,速度提升48%,但精度只是略有下降。
下面打印DBFPN的结构以及对于骨干网络特征图的融合结果。
2.1.3 骨干网络中SE模块分析
SE是squeeze-and-excitation的缩写(Hu, Shen, and Sun 2018)。如图所示
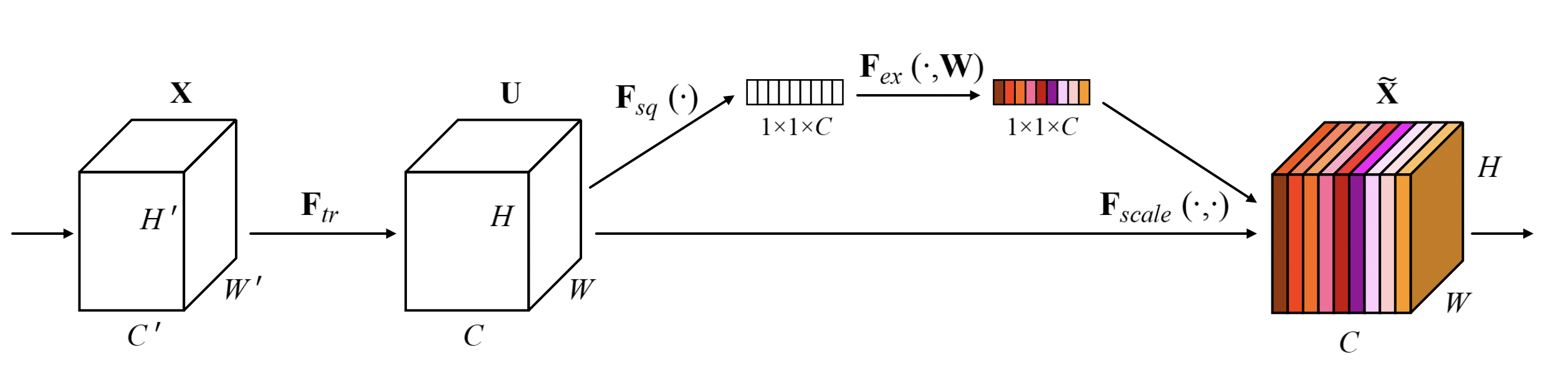
SE模块示意图
SE块显式地建模通道之间的相互依赖关系,并自适应地重新校准通道特征响应。在网络中使用SE块可以明显提高视觉任务的准确性,因此MobileNetV3的搜索空间包含了SE模块,最终MobileNetV3中也包含很多个SE模块。然而,当输入分辨率较大时,例如640×640,使用SE模块较难估计通道的特征响应,精度提高有限,但SE模块的时间成本非常高。在DBNet中,我们将SE模块从骨干网络中移除,模型大小从4.1M降到2.6M,但精度没有影响。
PaddleOCR中可以通过设置disable_se=True来移除骨干网络中的SE模块,使用方法如下所示。
2.1.4 学习率策略优化
- Cosine 学习率下降策略
梯度下降算法需要我们设置一个值,用来控制权重更新幅度,我们将其称之为学习率。它是控制模型学习速度的超参数。学习率越小,loss的变化越慢。虽然使用较低的学习速率可以确保不会错过任何局部极小值,但这也意味着模型收敛速度较慢。
因此,在训练前期,权重处于随机初始化状态,我们可以设置一个相对较大的学习速率以加快收敛速度。在训练后期,权重接近最优值,使用相对较小的学习率可以防止模型在收敛的过程中发生震荡。
Cosine学习率策略也就应运而生,Cosine学习率策略指的是学习率在训练的过程中,按照余弦的曲线变化。在整个训练过程中,Cosine学习率衰减策略使得在网络在训练初期保持了较大的学习速率,在后期学习率会逐渐衰减至0,其收敛速度相对较慢,但最终收敛精度较好。下图比较了两种不同的学习率衰减策略piecewise decay和cosine decay。
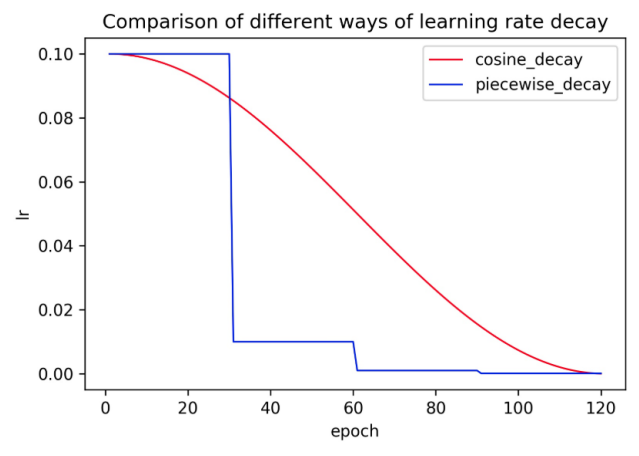
Cosine与Piecewise学习率下降策略
- 学习率预热策略
模型刚开始训练时,模型权重是随机初始化的,此时若选择一个较大的学习率,可能造成模型训练不稳定的问题,因此学习率预热的概念被提出,用于解决模型训练初期不收敛的问题。
学习率预热指的是将学习率从一个很小的值开始,逐步增加到初始较大的学习率。它可以保证模型在训练初期的稳定性。使用学习率预热策略有助于提高图像分类任务的准确性。在DBNet中,实验表明该策略也是有效的。学习率预热策略与Cosine学习率结合时,学习率的变化趋势如下代码演示。
2.1.5 模型裁剪策略-FPGM
深度学习模型中一般有比较多的参数冗余,我们可以使用一些方法,去除模型中比较冗余的地方,从而提升模型推理效率。
模型裁剪指的是通过去除网络中冗余的通道(channel)、滤波器(filter)、神经元(neuron)等,来得到一个更轻量的网络,同时尽可能保证模型精度。
相比于裁剪通道或者特征图的方法,裁剪滤波器的方法可以得到更加规则的模型,因此减少内存消耗,加速模型推理过程。
之前的裁剪滤波器的方法大多基于范数进行裁剪,即,认为范数较小的滤波器重要程度较小,但是这种方法要求存在的滤波器的最小范数应该趋近于0,否则我们难以去除。
针对上面的问题,基于几何中心点的裁剪算法(Filter Pruning via Geometric Median, FPGM)被提出。FPGM将卷积层中的每个滤波器都作为欧几里德空间中的一个点,它引入了几何中位数这样一个概念,即与所有采样点距离之和最小的点。如果一个滤波器的接近这个几何中位数,那我们可以认为这个滤波器的信息和其他滤波器重合,可以去掉。
FPGM与基于范数的裁剪算法的对比如下图所示。
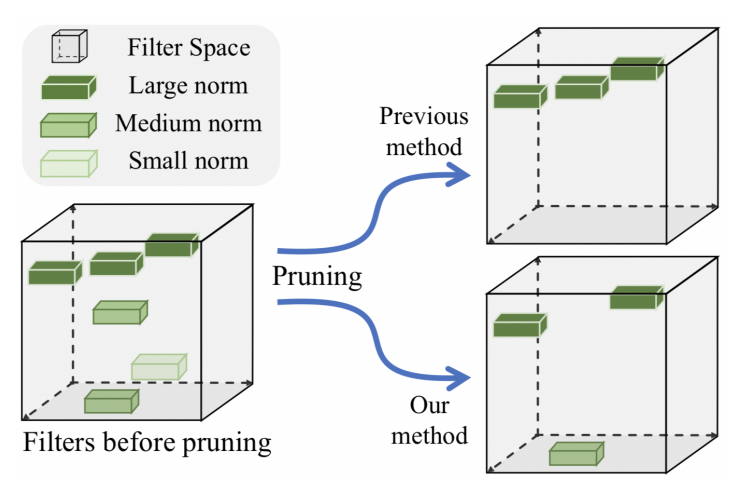
FPGM裁剪示意图
在PP-OCR中,我们使用FPGM对检测模型进行剪枝,最终DBNet的模型精度只有轻微下降,但是模型大小减小46%,预测速度加速19%。
关于FPGM模型裁剪实现的更多细节可以参考PaddleSlim。
注意:
- 模型裁剪需要重新训练模型,可以参考PaddleOCR剪枝教程。
- 裁剪代码是根据DBNet进行适配,如果您需要对自己的模型进行剪枝,需要重新分析模型结构、参数的敏感度,我们通常情况下只建议裁剪相对敏感度低的参数,而跳过敏感度高的参数。
- 每个卷积层的剪枝率对于裁剪后模型的性能也很重要,用完全相同的裁剪率去进行模型裁剪通常会导致显着的性能下降。
- 模型裁剪不是一蹴而就的,需要进行反复的实验,才能得到符合要求的模型。
2.1.6 文本检测配置说明
下面给出DBNet的训练配置简要说明,完整的配置文件可以参考:ch_det_mv3_db_v2.0.yml。
Architecture: # 模型结构定义
model_type: det
algorithm: DB
Transform:
Backbone:
name: MobileNetV3 # 配置骨干网络
scale: 0.5
model_name: large
disable_se: True # 去除SE模块
Neck:
name: DBFPN # 配置DBFPN
out_channels: 96 # 配置 inner_channels
Head:
name: DBHead
k: 50
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine # 配置cosine学习率下降策略
learning_rate: 0.001 # 初始学习率
warmup_epoch: 2 # 配置学习率预热策略
regularizer:
name: 'L2' # 配置L2正则
factor: 0 # 正则项的权重
2.1.7 PP-OCR 检测优化总结
上面给大家介绍了PP-OCR中文字检测算法的优化策略,这里再给大家回顾一下不同优化策略对应的消融实验与结论。
DBNet消融实验
通过轻量级骨干网络、轻量级neck结构、SE模块的分析和去除、学习率调整及优化、模型裁剪等策略,DBNet的模型大小从7M减少至1.5M。通过学习率策略优化等训练策略优化,DBNet的模型精度提升超过1%。
PP-OCR中,超轻量DBNet检测效果如下所示:

下面展示快速使用文字检测模型的预测效果。

2.2 方向分类器
方向分类器的任务是用于分类出文本检测出的文本实例的方向,将文本旋转到0度之后,再送入后续的文本识别器中。PP-OCR中,我们考虑了0度和180度2个方向。下面详细介绍针对方向分类器的速度、精度优化策略。

方向分类器消融实验
2.2.1 轻量级骨干网络
与文本检测器相同,我们仍然采用MobileNetV3作为方向分类器的骨干网络。因为方向分类的任务相对简单,我们使用MobileNetV3 small 0.35x来平衡模型精度与预测效率。实验表明,即使当使用更大的骨干时,精度不会有进一步的提升。
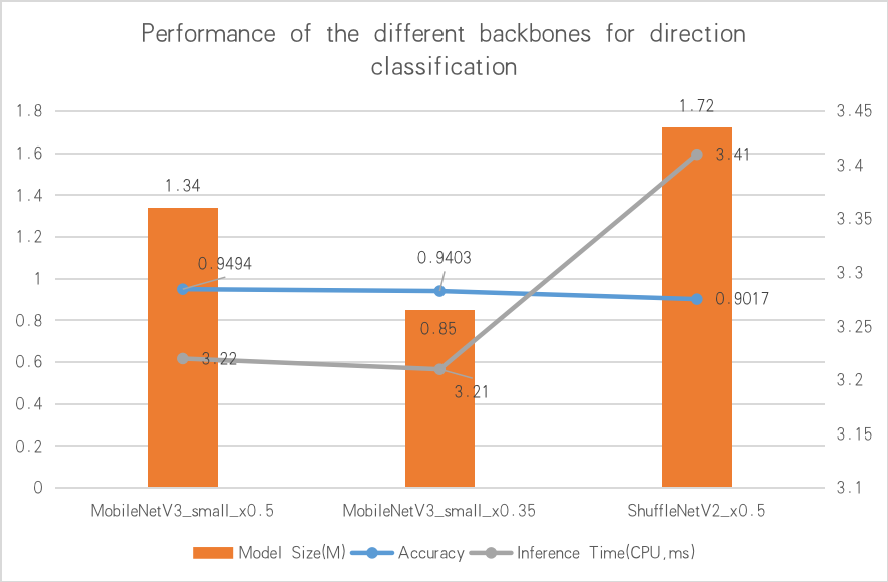
不同骨干网络下的方向分类器精度对比
2.2.2 数据增强
数据增强指的是对图像变换,送入网络进行训练,它可以提升网络的泛化性能。常用的数据增强包括旋转、透视失真变换、运动模糊变换和高斯噪声变换等,PP-OCR中,我们统称这些数据增强方法为BDA(Base Data Augmentation)。结果表明,BDA可以明显提升方向分类器的精度。
下面展示一些BDA数据增广方法的效果

BDA数据增广效果
除了BDA外,我们还加入了一些更高阶的数据增强操作来提高分类的效果,例如 AutoAugment (Cubuk et al. 2019), RandAugment (Cubuk et al. 2020), CutOut (DeVries and Taylor 2017), RandErasing (Zhong et al. 2020), HideAndSeek (Singh and Lee 2017), GridMask (Chen 2020), Mixup (Zhang et al. 2017) 和 Cutmix (Yun et al. 2019)。
这些数据增广大体分为3个类别:
(1)图像变换类:AutoAugment、RandAugment
(2)图像裁剪类:CutOut、RandErasing、HideAndSeek、GridMask
(3)图像混叠类:Mixup、Cutmix
下面给出不同高阶数据增广的可视化对比结果。

高阶数据增广可视化效果
但是实验表明,除了RandAugment 和 RandErasing 外,大多数方法都不适用于方向分类器。下图也给出了在不同数据增强策略下,模型精度的变化。
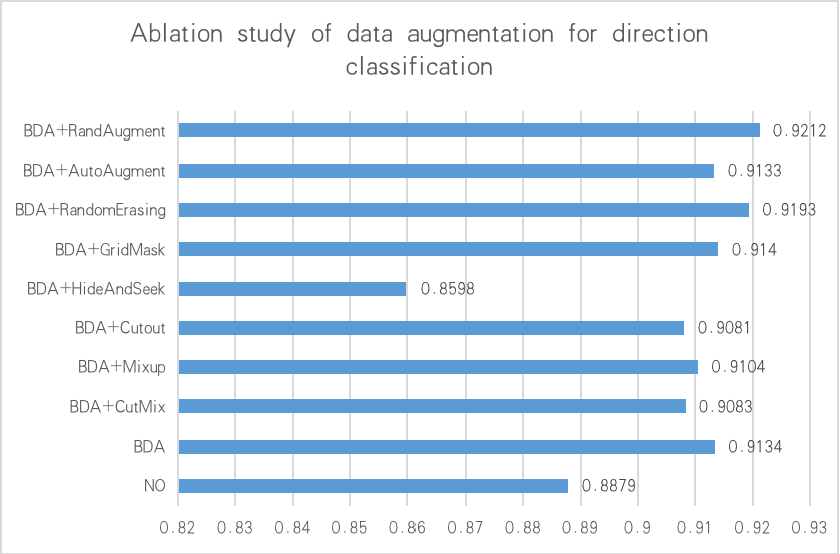
最终,我们在训练时结合BDA和RandAugment,作为方向分类器的数据增强策略。
- RandAugment代码演示
2.2.3 输入分辨率优化
一般来说,当图像的输入分辨率提高时,精度也会提高。由于方向分类器的骨干网络参数量很小,即使提高了分辨率也不会导致推理时间的明显增加。我们将方向分类器的输入图像尺度从3x32x100增加到3x48x192,方向分类器的精度从92.1%提升至94.0%,但是预测耗时仅仅从3.19ms提升至3.21ms。
下面给出两种尺度下的图像大小对比。

32x100和48x192尺度下的图像大小对比
2.2.4 模型量化策略-PACT
模型量化是一种将浮点计算转成低比特定点计算的技术,可以使神经网络模型具有更低的延迟、更小的体积以及更低的计算功耗。
模型量化主要分为离线量化和在线量化。其中,离线量化是指一种利用KL散度等方法来确定量化参数的定点量化方法,量化后不需要再次训练;在线量化是指在训练过程中确定量化参数,相比离线量化模式,它的精度损失更小。
PACT(PArameterized Clipping acTivation)是一种新的在线量化方法,可以提前从激活层中去除一些极端值。在去除极端值后,模型可以学习更合适的量化参数。普通PACT方法的激活值的预处理是基于RELU函数的,公式如下:
$$
y=P A C T(x)=0.5(|x|-|x-\alpha|+\alpha)=\left{\begin{array}{cc}
0 & x \in(-\infty, 0) \
x & x \in[0, \alpha) \
\alpha & x \in[\alpha,+\infty)
\end{array}\right.
$$
所有大于特定阈值的激活值都会被重置为一个常数。然而,MobileNetV3中的激活函数不仅是ReLU,还包括hardswish。因此使用普通的PACT量化会导致更高的精度损失。因此,为了减少量化损失,我们将激活函数的公式修改为:
$$
y=P A C T(x)=\left{\begin{array}{rl}
-\alpha & x \in(-\infty,-\alpha) \
x & x \in[-\alpha, \alpha) \
\alpha & x \in[\alpha,+\infty)
\end{array}\right.
$$
PaddleOCR中提供了适用于PP-OCR套件的量化脚本。具体链接可以参考PaddleOCR模型量化教程。
2.2.5 方向分类器配置说明
训练方向分类器时,配置文件中的部分关键字段和说明如下所示。完整配置文件可以参考cls_mv3.yml。
Architecture:
model_type: cls
algorithm: CLS
Transform:
Backbone:
name: MobileNetV3 # 配置分类模型为MobileNetV3
scale: 0.35
model_name: small
Neck:
Head:
name: ClsHead
class_dim: 2
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/cls
label_file_list:
- ./train_data/cls/train.txt
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- ClsLabelEncode: # Class handling label
- RecAug:
use_tia: False # 配置BDA数据增强,不使用TIA数据增强
- RandAugment: # 配置随机增强数据增强方法
- ClsResizeImg:
image_shape: [3, 48, 192] # 这里将[3, 32, 100]修改为[3, 48, 192],进行输入分辨率优化
- KeepKeys:
keep_keys: ['image', 'label'] # dataloader will return list in this order
loader:
shuffle: True
batch_size_per_card: 512
drop_last: True
num_workers: 8
2.2.5 方向分类器实验总结
在方向分类器模型优化中,我们使用轻量化骨干网络以及模型量化,最终将模型从0.85M降低到了0.46M,使用组合数据增广、高分辨率等特征,最终将模型精度提升了超过2%。消融实验对比如下所示。
方向分类器消融实验
2.3 文本识别
PP-OCR中,文本识别器使用的是CRNN模型。训练的时候使用CTC loss去解决不定长文本的预测问题。
CRNN模型结构如下所示。
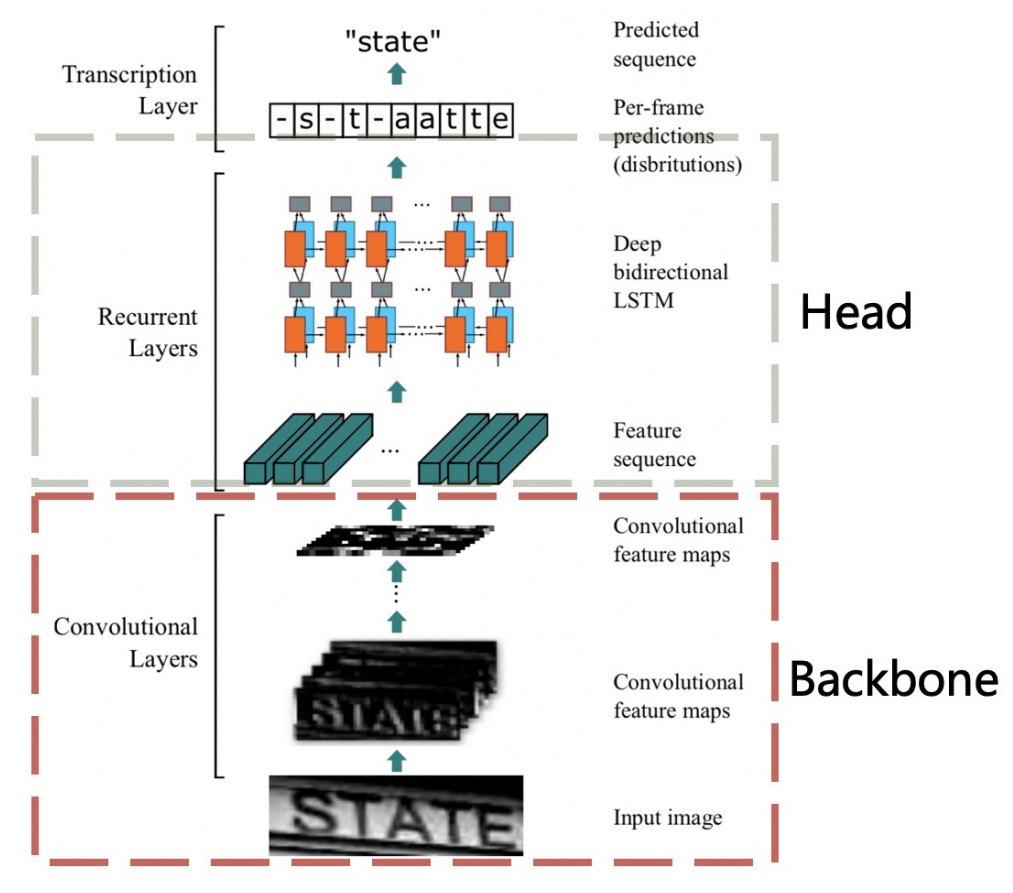
CRNN结构图
PP-OCR针对文本识别器,从骨干网络、头部结构优化、数据增强、正则化策略、特征图下采样策略、量化等多个角度进行模型优化,具体消融实验如下所示。

CRNN识别模型消融实验
下面详细介绍文本识别模型的具体优化策略。
2.3.1 轻量级骨干网络和头部结构
- 轻量级骨干网络
在文本识别中,仍然采用了与文本检测相同的MobileNetV3作为backbone。选自MobileNetV3_small_x0.5进一步地平衡精度和效率。如果不要求模型大小的话,可以选择MobileNetV3_small_x1,模型大小仅增加5M,精度明显提高。
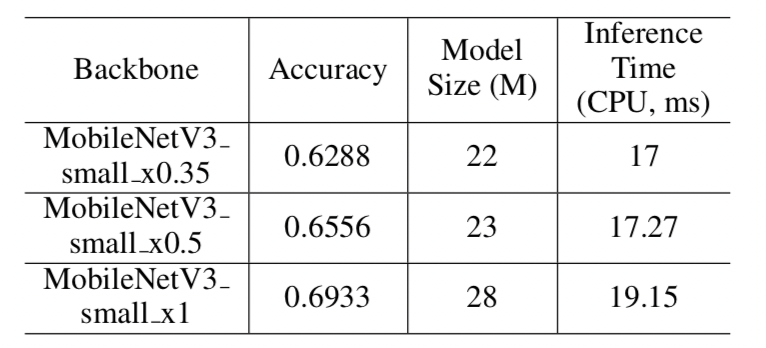
不同骨干网络下的识别模型精度对比
- 轻量级头部结构
CRNN中,用于解码的轻量级头(head)是一个全连接层,用于将序列特征解码为普通的预测字符。序列特征的维数对文本识别器的模型大小影响非常大,特别是对于6000多个字符的中文识别场景(序列特征维度若设置为256,则仅仅是head部分的模型大小就为6.7M)。在PP-OCR中,我们针对序列特征的维度展开实验,最终将其设置为48,平衡了精度与效率。部分消融实验结论如下。
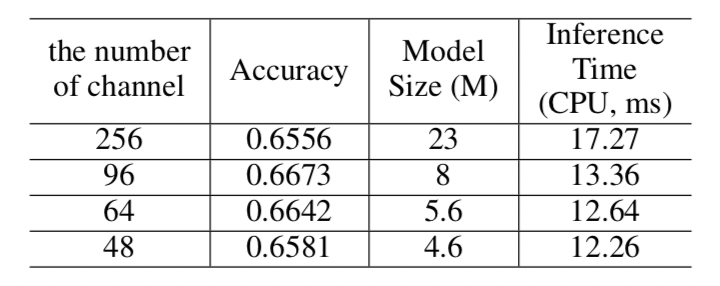
不同序列特征维度的精度对比
2.3.2 数据增强
除了前面提到的经常用于文本识别的BDA(基本数据增强),TIA(Luo等人,2020)也是一种有效的文本识别数据增强方法。TIA是一种针对场景文字的数据增强方法,它在图像中设置了多个基准点,然后随机移动点,通过几何变换生成新图像,这样大大提升了数据的多样性以及模型的泛化能力。TIA的基本流程图如图所示:
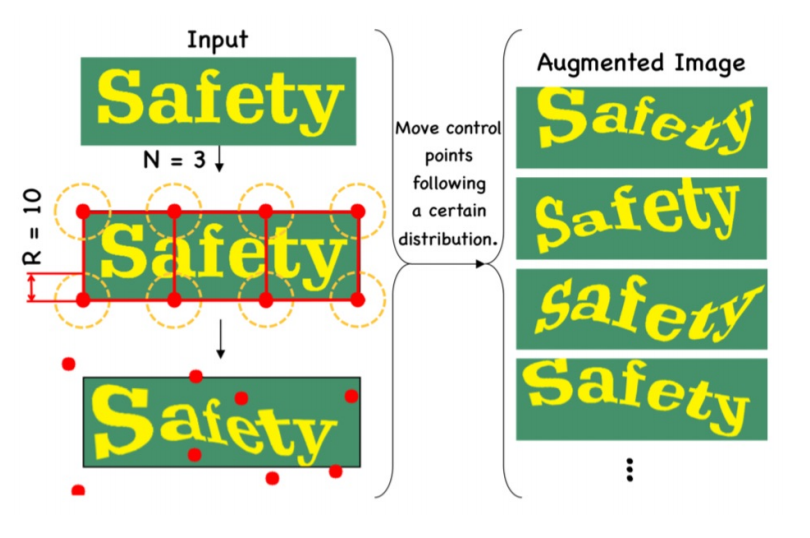
实验证明,使用TIA数据增广,可以帮助文本识别模型的精度在一个极高的baseline上面进一步提升0.9%。
下面是TIA中三种涉及到的数据增广的可视化效果图。
2.3.3 学习率策略和正则化
在识别模型训练中,学习率下降策略与文本检测相同,也使用了Cosine+Warmup的学习率策略。
正则化是一种广泛使用的避免过度拟合的方法,一般包含L1正则化和L2正则化。在大多数使用场景中,我们都使用L2正则化。它主要的原理就是计算网络中权重的L2范数,添加到损失函数中。在L2正则化的帮助下,网络的权重趋向于选择一个较小的值,最终整个网络中的参数趋向于0,从而缓解模型的过拟合问题,提高了模型的泛化性能。
我们实验发现,对于文本识别,L2正则化对识别准确率有很大的影响。
CRNN识别模型消融实验
2.3.4 特征图降采样策略
我们在做检测、分割、OCR等下游视觉任务时,骨干网络一般都是使用的图像分类任务中的骨干网络,它的输入分辨率一般设置为224x224,降采样时,一般宽度和高度会同时降采样。
但是对于文本识别任务来说,由于输入图像一般是32x100,长宽比非常不平衡,此时对宽度和高度同时降采样,会导致特征损失严重,因此图像分类任务中的骨干网络应用到文本识别任务中需要进行特征图降采样方面的适配(如果大家自己换骨干网络的话,这里也需要注意一下)。
在PaddleOCR中,CRNN中文文本识别模型设置的输入图像的高度和宽度设置为32和320。原始MobileNetV3来自分类模型,如前文所述,需要调整降采样的步长,适配文本图像输入分辨率。具体地,为了保留更多的水平信息,我们将下采样特征图的步长从 (2,2) 修改为 (2,1) ,第一次下采样除外。最终如下图所示。
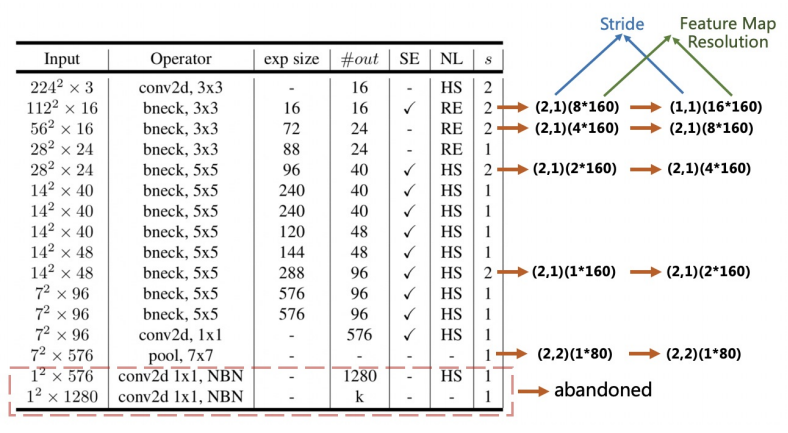
降采样步长策略优化可视化
为了保留更多的垂直信息,我们进一步将第二次下采样特征图的步长从 (2,1) 修改为 (1,1)。因此,第二个下采样特征图的步长s2会显著影响整个特征图的分辨率和文本识别器的准确性。在PP-OCR中,s2被设置为(1,1),可以获得更好的性能。同时,由于水平的分辨率增加,CPU的推理时间从11.84ms 增加到 12.96ms。
下面给出了stride优化前后的特征图尺度对比。虽然最终输出特征图尺度相同,但是stride从(2,1)修改为(1,1)之后,特征信息在编码的过程中被保留得更为完整。
2.3.5 PACT 在线量化策略
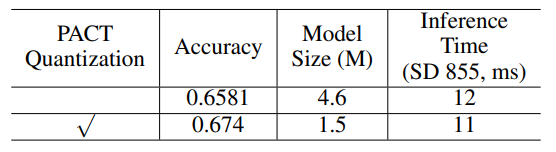
我们采用与方向分类器量化类似的方案来减小文本识别器的模型大小。由于LSTM量化的复杂性,PP-OCR中没有对LSTM进行量化。使用该量化策略之后,模型大小减小67.4%、预测速度加速8%、准确率提升1.6%,量化可以减少模型冗余,增强模型的表达能力。
模型量化消融实验
2.3.6 文字识别预训练模型
使用合适的预训练模型可以加快模型的收敛速度。在真实场景中,用于文本识别的数据通常是有限的。PP-OCR中,我们合成了千万级别的数据,对模型进行训练,之后再基于该模型,在真实数据上微调,最终识别准确率从从65.81%提升到69%。
2.3.7 文本识别配置说明
下面给出CRNN的训练配置简要说明,完整的配置文件可以参考:rec_chinese_lite_train_v2.0.yml。
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine # 配置Cosine 学习率下降策略
learning_rate: 0.001
warmup_epoch: 5 # 配置预热学习率
regularizer:
name: 'L2' # 配置L2正则
factor: 0.00001
Architecture:
model_type: rec
algorithm: CRNN
Transform:
Backbone:
name: MobileNetV3 # 配置Backbone
scale: 0.5
model_name: small
small_stride: [1, 2, 2, 2] # 配置下采样的stride
Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 48 # 配置最后一层全连接层的维度
Head:
name: CTCHead
fc_decay: 0.00001
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/
label_file_list: ["./train_data/train_list.txt"]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- RecAug: # 配置数据增强BDA和TIA,TIA默认使用
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 320]
- KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: True
batch_size_per_card: 256
drop_last: True
num_workers: 8
2.3.8 识别优化小结
在模型体积方面,PP-OCR使用轻量级骨干网络、序列维度裁剪、模型量化的策略,将模型大小从4.5M减小至1.6M。在精度方面,使用TIA数据增强、Cosine-warmup学习率策略、L2正则、特征图分辨率改进、预训练模型等优化策略,最终在验证集上提升15.4%。
PP-OCR中部分识别效果如下所示。

文本识别模型的代码演示如下。
3. PP-OCRv2优化策略解读
第2节的内容主要是对PP-OCR以及它的19个优化策略进行了详细介绍。
相比于PP-OCR, PP-OCRv2 在骨干网络、数据增广、损失函数这三个方面进行进一步优化,解决端侧预测效率较差、背景复杂以及相似字符的误识等问题,同时引入了知识蒸馏训练策略,进一步提升模型精度。具体地:
- 检测模型优化: (1) 采用 CML 协同互学习知识蒸馏策略;(2) CopyPaste 数据增广策略;
- 识别模型优化: (1) PP-LCNet 轻量级骨干网络;(2) U-DML 改进知识蒸馏策略; (3) Enhanced CTC loss 损失函数改进。
本节主要基于文字检测和识别模型的优化过程,去解读PP-OCRv2的优化策略。
3.1 文字检测模型优化详解
文字检测模型优化过程中,采用 CML 协同互学习知识蒸馏以及 CopyPaste 数据增广策略;最终将文字检测模型在大小不变的情况下,Hmean从 0.759 提升至 0.795,具体消融实验如下所示。
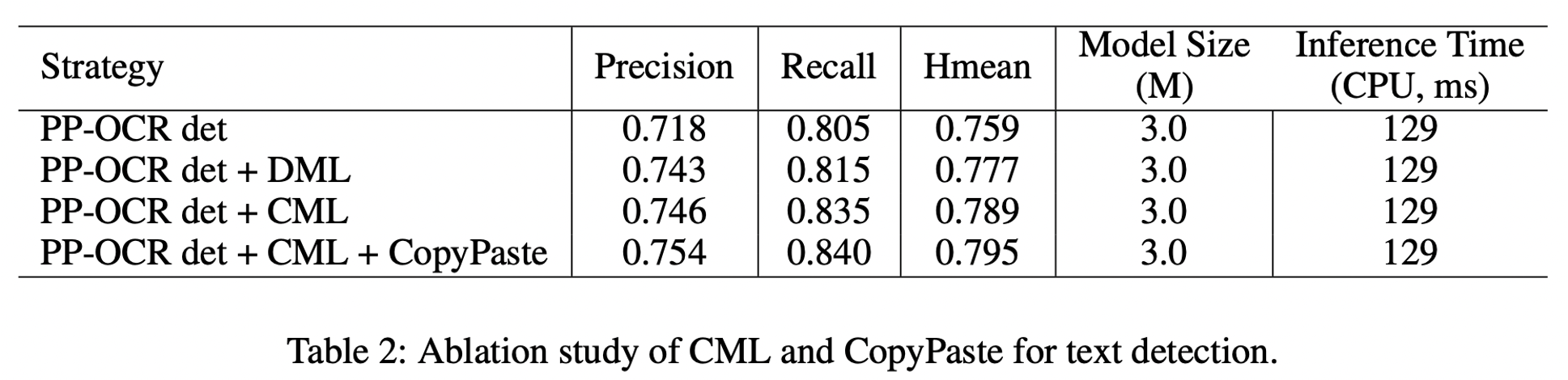
PP-OCRv2检测模型消融实验
3.1.1 CML知识蒸馏策略
知识蒸馏的方法在部署中非常常用,通过使用大模型指导小模型学习的方式,在通常情况下可以使得小模型在预测耗时不变的情况下,精度得到进一步的提升,从而进一步提升实际部署的体验。
标准的蒸馏方法是通过一个大模型作为 Teacher 模型来指导 Student 模型提升效果,而后来又发展出 DML 互学习蒸馏方法,即通过两个结构相同的模型互相学习,相比于前者,DML 脱离了对大的 Teacher 模型的依赖,蒸馏训练的流程更加简单,模型产出效率也要更高一些。
PP-OCRv2 文字检测模型中使用的是三个模型之间的 CML (Collaborative Mutual Learning) 协同互蒸馏方法,既包含两个相同结构的 Student 模型之间互学习,同时还引入了较大模型结构的 Teacher 模型。CML与其他蒸馏算法的对比如下所示。
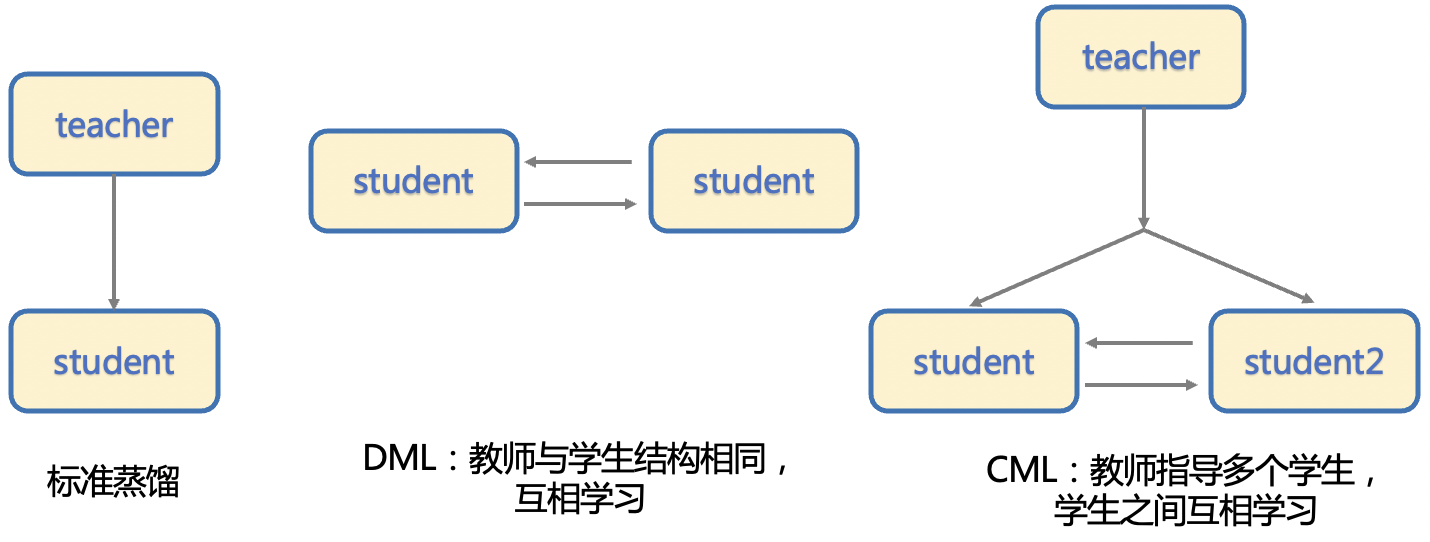
CML与其他知识蒸馏算法的对比
具体地,文本检测任务中,CML的结构框图如下所示。这里的 response maps 指的就是DBNet最后一层的概率图输出 (Probability map) 。在整个训练过程中,总共包含3个损失函数。
- GT loss
- DML loss
- Distill loss
这里的 Teacher 模型的骨干网络为 ResNet18_vd,2 个 Student 模型的骨干网络为 MobileNetV3。
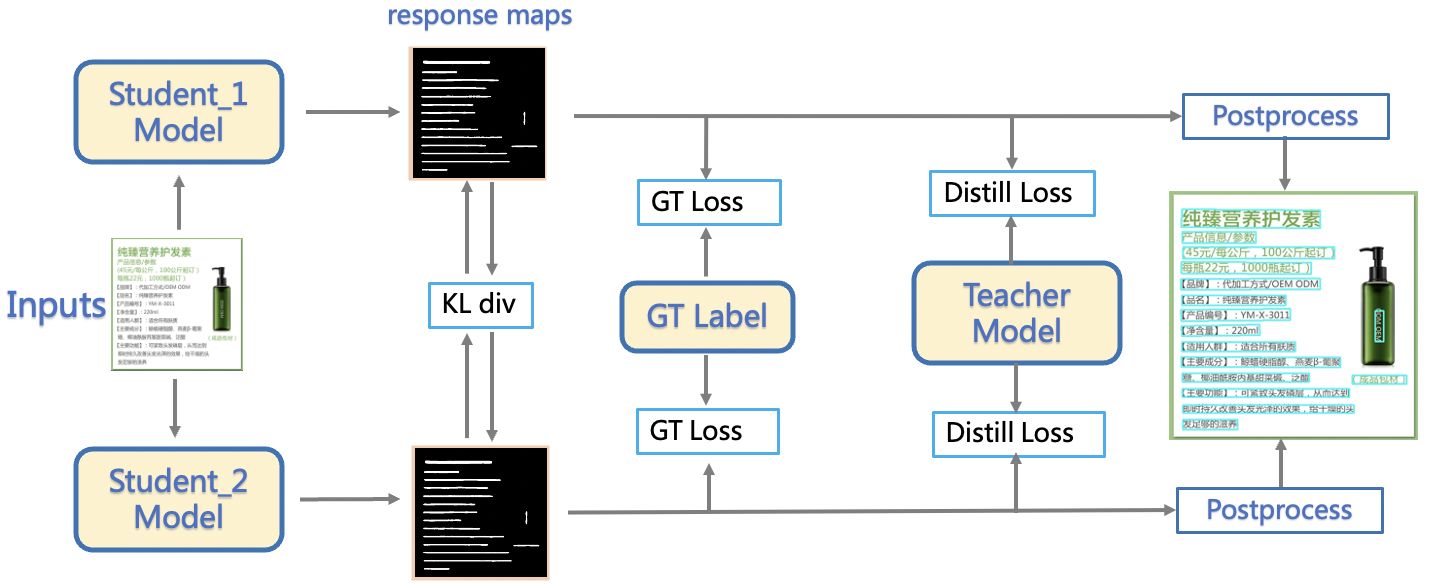
CML结构框图
- GT loss
两个 Student 模型中大部分的参数都是从头初始化的,因此它们在训练的过程中需要受到 groundtruth (GT) 信息 的监督。DBNet 训练任务的 pipeline 如下所示。其输出主要包含 3 种 feature map,具体如下所示。
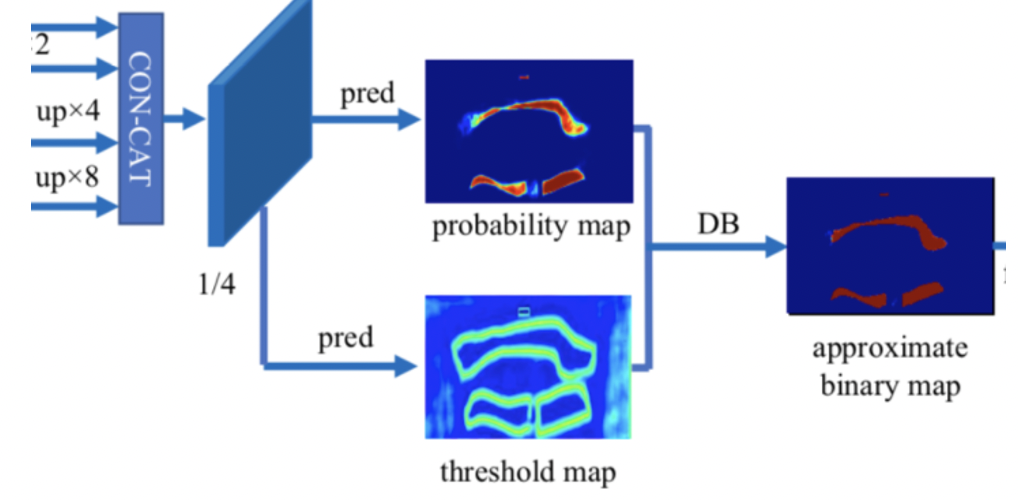
DBNet头部结构
对这 3 种 feature map 使用不同的 loss function 进行监督,具体如下表所示。
| Feature map | Loss function | weight |
|---|---|---|
| Probability map | Binary cross-entropy loss | 1.0 |
| Binary map | Dice loss | $\alpha$ |
| Threshold map | L1 loss | $\beta$ |
最终GT loss可以表示为如下所示。
$$ Loss_{gt}(T_{out}, gt) = l_{p}(S_{out}, gt) + \alpha l_{b}(S_{out}, gt) + \beta l_{t}(S_{out}, gt) $$
- DML loss
对于 2 个完全相同的 Student 模型来说,因为它们的结构完全相同,因此对于相同的输入,应该具有相同的输出,DBNet 最终输出的是概率图 (response maps),因此基于 KL 散度,计算 2 个 Student 模型的 DML loss,具体计算方式如下。
$$ Loss_{dml} = \frac{KL(S1_{pout} || S2_{pout}) + KL(S2_{pout} || S1_{pout})}{2} $$
其中 KL(·|·)是 KL 散度的计算公式,最终这种形式的 DML loss 具有对称性。
- Distill loss
CML 中,引入了 Teacher 模型,来同时监督 2 个 Student 模型。PP-OCRv2 中只对特征 Probability map 进行蒸馏的监督。具体地,对于其中一个 Student 模型,计算方法如下所示, lp(·) 和 lb(·) 分别表示 Binary cross-entropy loss 和 Dice loss。另一个 Student 模型的 loss 计算过程完全相同。
$$ Loss_{distill} = \gamma l_{p}(S_{out}, f_{dila}(T_{out})) + l_{b}(S_{out}, f_{dila}(T_{out})) $$
最终,将上述三个 loss 相加,就得到了用于 CML 训练的损失函数。
检测配置文件为ch_PP-OCRv2_det_cml.yml,蒸馏结构部分的配置和部分解释如下。
Architecture:
name: DistillationModel # 模型名称,这是通用的蒸馏模型表示。
algorithm: Distillation # 算法名称,
Models: # 模型,包含子网络的配置信息
Teacher: # Teacher子网络,包含`pretrained`与`freeze_params`信息以及其他用于构建子网络的参数
freeze_params: true # 是否固定Teacher网络的参数
pretrained: ./pretrain_models/ch_ppocr_server_v2.0_det_train/best_accuracy # 预训练模型
return_all_feats: false # 是否返回所有的特征,为True时,会将backbone、neck、head等模块的输出都返回
model_type: det # 模型类别
algorithm: DB # Teacher网络的算法名称
Transform:
Backbone:
name: ResNet
layers: 18
Neck:
name: DBFPN
out_channels: 256
Head:
name: DBHead
k: 50
Student: # Student子网络
freeze_params: false
pretrained: ./pretrain_models/MobileNetV3_large_x0_5_pretrained
return_all_feats: false
model_type: det
algorithm: DB
Backbone:
name: MobileNetV3
scale: 0.5
model_name: large
disable_se: True
Neck:
name: DBFPN
out_channels: 96
Head:
name: DBHead
k: 50
Student2: # Student2子网络
freeze_params: false
pretrained: ./pretrain_models/MobileNetV3_large_x0_5_pretrained
return_all_feats: false
model_type: det
algorithm: DB
Transform:
Backbone:
name: MobileNetV3
scale: 0.5
model_name: large
disable_se: True
Neck:
name: DBFPN
out_channels: 96
Head:
name: DBHead
k: 50
DistillationModel类的实现在distillation_model.py文件中,DistillationModel类的实现与部分讲解如下。
class DistillationModel(nn.Layer):
def __init__(self, config):
"""
the module for OCR distillation.
args:
config (dict): the super parameters for module.
"""
super().__init__()
self.model_list = []
self.model_name_list = []
# 根据Models中的每个字段,抽取出子网络的名称以及对应的配置
for key in config["Models"]:
model_config = config["Models"][key]
freeze_params = False
pretrained = None
if "freeze_params" in model_config:
freeze_params = model_config.pop("freeze_params")
if "pretrained" in model_config:
pretrained = model_config.pop("pretrained")
# 根据每个子网络的配置,基于BaseModel生成子网络
model = BaseModel(model_config)
# 判断是否加载预训练模型
if pretrained is not None:
load_pretrained_params(model, pretrained)
# 判断是否需要固定该子网络的模型参数
if freeze_params:
for param in model.parameters():
param.trainable = False
self.model_list.append(self.add_sublayer(key, model))
self.model_name_list.append(key)
def forward(self, x):
result_dict = dict()
for idx, model_name in enumerate(self.model_name_list):
result_dict[model_name] = self.model_list[idx](x)
return result_dict
使用下面的命令,可以快速完成蒸馏模型的初始化过程。
3.1.2 数据增广
数据增广是提升模型泛化能力重要的手段之一,CopyPaste 是一种新颖的数据增强技巧,已经在目标检测和实例分割任务中验证了有效性。利用 CopyPaste,可以合成文本实例来平衡训练图像中的正负样本之间的比例。相比而言,传统图像旋转、随机翻转和随机裁剪是无法做到的。
CopyPaste 主要步骤包括:
- 随机选择两幅训练图像;
- 随机尺度抖动缩放;
- 随机水平翻转;
- 随机选择一幅图像中的目标子集;
- 粘贴在另一幅图像中随机的位置。
这样就比较好地提升了样本丰富度,同时也增加了模型对环境的鲁棒性。如下图所示,通过在左下角的图中裁剪出来的文本,随机旋转缩放之后粘贴到左上角的图像中,进一步丰富了该文本在不同背景下的多样性。

如果希望在模型训练中使用CopyPaste,只需在Train.transforms配置字段中添加CopyPaste即可,如下所示。
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/icdar2015/text_localization/
label_file_list:
- ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
ratio_list: [1.0]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- DetLabelEncode: # Class handling label
- CopyPaste: # 添加CopyPaste
- IaaAugment:
augmenter_args:
- { 'type': Fliplr, 'args': { 'p': 0.5 } }
- { 'type': Affine, 'args': { 'rotate': [-10, 10] } }
- { 'type': Resize, 'args': { 'size': [0.5, 3] } }
- EastRandomCropData:
size: [960, 960]
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
- MakeShrinkMap:
shrink_ratio: 0.4
min_text_size: 8
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask'] # the order of the dataloader list
loader:
shuffle: True
drop_last: False
batch_size_per_card: 8
num_workers: 4
CopyPaste的具体实现可以参考copy_paste.py。
下面基于icdar2015检测数据集,演示CopyPaste的实际运行过程。

3.1.3 文字检测优化小结
PP-OCRv2中,对文字检测模型采用使用知识蒸馏方案以及数据增广策略,增加模型的泛化性能。最终文字检测模型在大小不变的情况下,Hmean从 0.759 提升至 0.795,具体消融实验如下所示。
PP-OCRv2检测模型消融实验
PP-OCRv2中检测效果如下所示。

3.2 文本识别模型优化详解
PP-OCRv2文字识别模型优化过程中,采用骨干网络优化、UDML知识蒸馏策略、CTC loss改进等技巧,最终将识别精度从 66.7% 提升至 74.8%,具体消融实验如下所示。
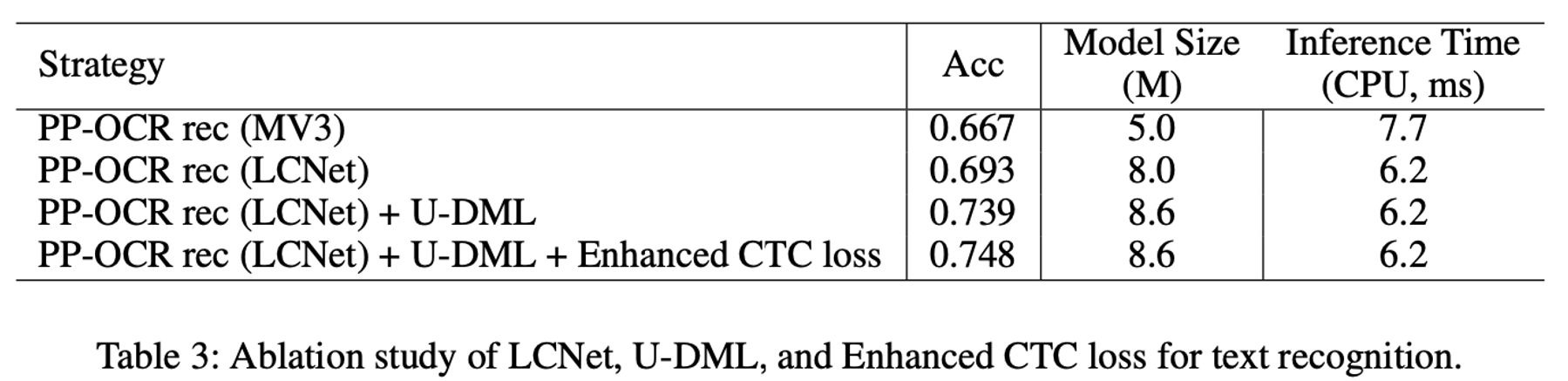
PP-OCRv2识别模型消融实验
3.2.1 PP-LCNet轻量级骨干网络
百度提出了一种基于 MKLDNN 加速策略的轻量级 CPU 网络,即 PP-LCNet,大幅提高了轻量级模型在图像分类任务上的性能,对于计算机视觉的下游任务,如文本识别、目标检测、语义分割等,有很好的表现。这里需要注意的是,PP-LCNet是针对CPU+MKLDNN这个场景进行定制优化,在分类任务上的速度和精度都远远优于其他模型,因此大家如果有这个使用场景的模型需求的话,也推荐大家去使用。
PP-LCNet 论文地址:PP-LCNet: A Lightweight CPU Convolutional Neural Network
PP-LCNet基于MobileNetV1改进得到,其结构图如下所示。
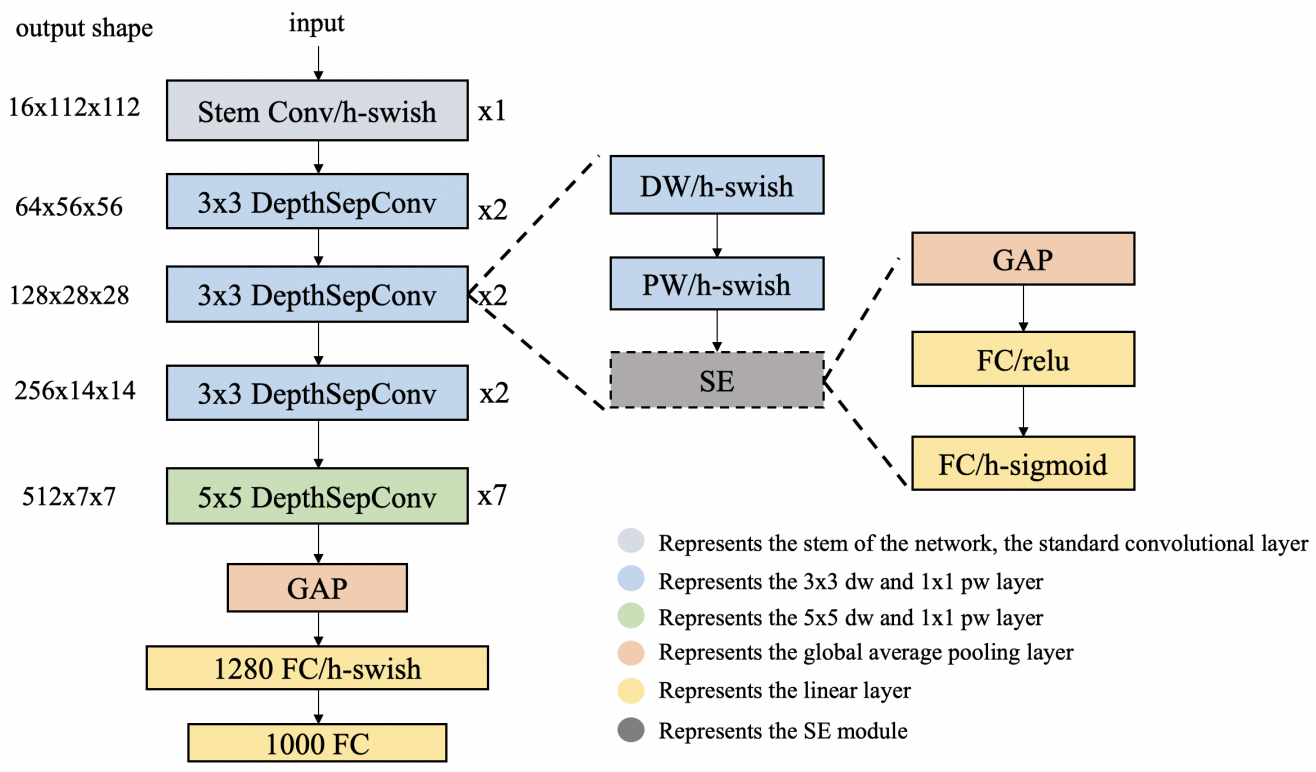
相比于MobileNetV1,PP-LCNet中融合了MobileNetV3结构中激活函数、头部结构、SE模块等策略优化技巧,同时分析了最后阶段卷积层的卷积核大小,最终该模型在保证速度优势的基础上,精度大幅超越MobileNet、GhostNet等轻量级模型。
具体地,PP-LCNet中共涉及到下面4个优化点。
- 除了 SE 模块,网络中所有的 relu 激活函数替换为 h-swish,精度提升1%-2%
- PP-LCNet 第五阶段,DW 的 kernel size 变为5x5,精度提升0.5%-1%
- PP-LCNet 第五阶段的最后两个 DepthSepConv block 添加 SE 模块, 精度提升0.5%-1%
- GAP 后添加 1280 维的 FC 层,增加特征表达能力,精度提升2%-3%
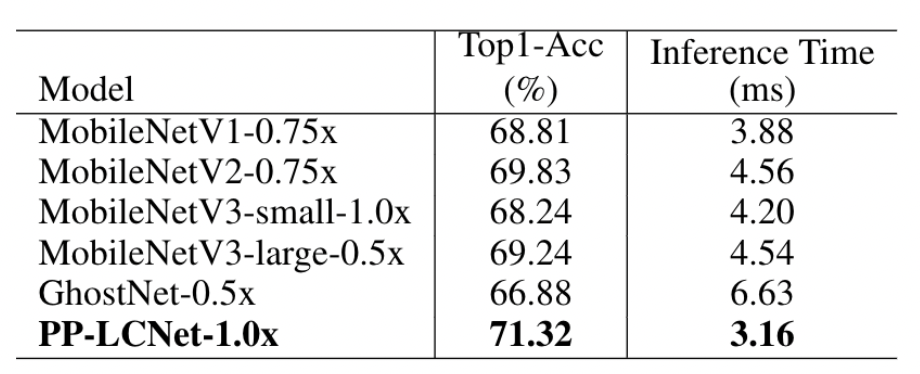
在ImageNet1k数据集上,PP-LCNet相比于其他目前比较常用的轻量级分类模型,Top1-Acc 与预测耗时如下图所示。可以看出,预测耗时和精度都是要更优的。
通过下面这种方式,便可以快速完成PP-LCNet识别模型的定义。
3.2.2 U-DML 知识蒸馏策略
对于标准的 DML 策略,蒸馏的损失函数仅包括最后输出层监督,然而对于 2 个结构完全相同的模型来说,对于完全相同的输入,它们的中间特征输出期望也完全相同,因此在最后输出层监督的监督上,可以进一步添加中间输出的特征图的监督信号,作为损失函数,即 PP-OCRv2 中的 U-DML (Unified-Deep Mutual Learning) 知识蒸馏方法。
U-DML 知识蒸馏的算法流程图如下所示。 Teacher 模型与 Student 模型的网络结构完全相同,初始化参数不同,此外,在新增在标准的 DML 知识蒸馏的基础上,新增引入了对于 Feature Map 的监督机制,新增 Feature Loss。

在训练的过程中,总共包含 3 种 loss: GT loss,DML loss,Feature loss。
- GT loss
文本识别任务使用的模型结构是 CRNN,因此使用 CTC loss 作为 GT loss, GT loss 计算方法如下所示。
$$ Loss_{ctc} = CTC(S_{hout}, gt) + CTC(T_{hout}, gt) $$
- DML loss
DML loss 计算方法如下,这里 Teacher 模型与 Student 模型互相计算 KL 散度,最终 DML loss具有对称性。
$$ Loss_{dml} = \frac{KL(S_{pout} || T_{pout}) + KL(T_{pout} || S_{pout})}{2} $$
- Feature loss
Feature loss 使用的是 L2 loss,具体计算方法如下所示。
$$ Loss_{feat} = L2(S_{bout}, T_{bout}) $$
最终,训练过程中的 loss function 计算方法如下所示。
$$ Loss_{total} = Loss_{ctc} + Loss_{dml} + Loss_{feat} $$
此外,在训练过程中通过增加迭代次数,在 Head 部分添加 FC 层等 trick,平衡模型的特征编码与解码的能力,进一步提升了模型效果。
配置文件在ch_PP-OCRv2_rec_distillation.yml。
Architecture:
model_type: &model_type "rec" # 模型类别,rec、det等,每个子网络的的模型类别都与
name: DistillationModel # 结构名称,蒸馏任务中,为DistillationModel,用于构建对应的结构
algorithm: Distillation # 算法名称
Models: # 模型,包含子网络的配置信息
Teacher: # 子网络名称,至少需要包含`pretrained`与`freeze_params`信息,其他的参数为子网络的构造参数
pretrained: # 该子网络是否需要加载预训练模型
freeze_params: false # 是否需要固定参数
return_all_feats: true # 子网络的参数,表示是否需要返回所有的features,如果为False,则只返回最后的输出
model_type: *model_type # 模型类别
algorithm: CRNN # 子网络的算法名称,该子网络剩余参与均为构造参数,与普通的模型训练配置一致
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 64
Head:
name: CTCHead
mid_channels: 96 # Head解码过程中穿插一层
fc_decay: 0.00002
Student: # 另外一个子网络,这里给的是DML的蒸馏示例,两个子网络结构相同,均需要学习参数
pretrained: # 下面的组网参数同上
freeze_params: false
return_all_feats: true
model_type: *model_type
algorithm: CRNN
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 64
Head:
name: CTCHead
mid_channels: 96
fc_decay: 0.00002
当然,这里如果希望添加更多的子网络进行训练,也可以按照Student与Teacher的添加方式,在配置文件中添加相应的字段。比如说如果希望有3个模型互相监督,共同训练,那么Architecture可以写为如下格式。
Architecture:
model_type: &model_type "rec"
name: DistillationModel
algorithm: Distillation
Models:
Teacher:
pretrained:
freeze_params: false
return_all_feats: true
model_type: *model_type
algorithm: CRNN
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 64
Head:
name: CTCHead
mid_channels: 96
fc_decay: 0.00002
Student:
pretrained:
freeze_params: false
return_all_feats: true
model_type: *model_type
algorithm: CRNN
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 64
Head:
name: CTCHead
mid_channels: 96
fc_decay: 0.00002
Student2: # 知识蒸馏任务中引入的新的子网络,其他部分与上述配置相同
pretrained:
freeze_params: false
return_all_feats: true
model_type: *model_type
algorithm: CRNN
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 64
Head:
name: CTCHead
mid_channels: 96
fc_decay: 0.00002
最终该模型训练时,包含3个子网络:Teacher, Student, Student2。
蒸馏模型DistillationModel类的具体实现代码可以参考distillation_model.py。
最终模型forward输出为一个字典,key为所有的子网络名称,例如这里为Student与Teacher,value为对应子网络的输出,可以为Tensor(只返回该网络的最后一层)和dict(也返回了中间的特征信息)。
在识别任务中,为了添加更多损失函数,保证蒸馏方法的可扩展性,将每个子网络的输出保存为dict,其中包含子模块输出。以该识别模型为例,每个子网络的输出结果均为dict,key包含backbone_out,neck_out, head_out,value为对应模块的tensor,最终对于上述配置文件,DistillationModel的输出格式如下。
{
"Teacher": {
"backbone_out": tensor,
"neck_out": tensor,
"head_out": tensor,
},
"Student": {
"backbone_out": tensor,
"neck_out": tensor,
"head_out": tensor,
}
}
知识蒸馏任务中,损失函数配置如下所示。
Loss:
name: CombinedLoss # 损失函数名称,基于改名称,构建用于损失函数的类
loss_config_list: # 损失函数配置文件列表,为CombinedLoss的必备函数
- DistillationCTCLoss: # 基于蒸馏的CTC损失函数,继承自标准的CTC loss
weight: 1.0 # 损失函数的权重,loss_config_list中,每个损失函数的配置都必须包含该字段
model_name_list: ["Student", "Teacher"] # 对于蒸馏模型的预测结果,提取这两个子网络的输出,与gt计算CTC loss
key: head_out # 取子网络输出dict中,该key对应的tensor
- DistillationDMLLoss: # 蒸馏的DML损失函数,继承自标准的DMLLoss
weight: 1.0 # 权重
act: "softmax" # 激活函数,对输入使用激活函数处理,可以为softmax, sigmoid或者为None,默认为None
model_name_pairs: # 用于计算DML loss的子网络名称对,如果希望计算其他子网络的DML loss,可以在列表下面继续填充
- ["Student", "Teacher"]
key: head_out # 取子网络输出dict中,该key对应的tensor
- DistillationDistanceLoss: # 蒸馏的距离损失函数
weight: 1.0 # 权重
mode: "l2" # 距离计算方法,目前支持l1, l2, smooth_l1
model_name_pairs: # 用于计算distance loss的子网络名称对
- ["Student", "Teacher"]
key: backbone_out # 取子网络输出dict中,该key对应的tensor
上述损失函数中,所有的蒸馏损失函数均继承自标准的损失函数类,主要功能为: 对蒸馏模型的输出进行解析,找到用于计算损失的中间节点(tensor),再使用标准的损失函数类去计算。
以上述配置为例,最终蒸馏训练的损失函数包含下面3个部分。
Student和Teacher的最终输出(head_out)与gt的CTC loss,权重为1。在这里因为2个子网络都需要更新参数,因此2者都需要计算与gt的loss。Student和Teacher的最终输出(head_out)之间的DML loss,权重为1。Student和Teacher的骨干网络输出(backbone_out)之间的l2 loss,权重为1。
CombinedLoss类实现如下。
class CombinedLoss(nn.Layer):
"""
CombinedLoss:
a combionation of loss function
"""
def __init__(self, loss_config_list=None):
super().__init__()
self.loss_func = []
self.loss_weight = []
assert isinstance(loss_config_list, list), (
'operator config should be a list')
for config in loss_config_list:
assert isinstance(config,
dict) and len(config) == 1, "yaml format error"
name = list(config)[0]
param = config[name]
assert "weight" in param, "weight must be in param, but param just contains {}".format(
param.keys())
self.loss_weight.append(param.pop("weight"))
self.loss_func.append(eval(name)(**param))
def forward(self, input, batch, **kargs):
loss_dict = {}
loss_all = 0.
for idx, loss_func in enumerate(self.loss_func):
loss = loss_func(input, batch, **kargs)
if isinstance(loss, paddle.Tensor):
loss = {"loss_{}_{}".format(str(loss), idx): loss}
weight = self.loss_weight[idx]
loss = {key: loss[key] * weight for key in loss}
if "loss" in loss:
loss_all += loss["loss"]
else:
loss_all += paddle.add_n(list(loss.values()))
loss_dict.update(loss)
loss_dict["loss"] = loss_all
return loss_dict
关于CombinedLoss更加具体的实现可以参考: combined_loss.py。关于DistillationCTCLoss等蒸馏损失函数更加具体的实现可以参考distillation_loss.py。
对于上面3个模型的蒸馏,Loss字段也需要相应修改,同时考虑3个子网络之间的损失,如下所示。
Loss:
name: CombinedLoss # 损失函数名称,基于改名称,构建用于损失函数的类
loss_config_list: # 损失函数配置文件列表,为CombinedLoss的必备函数
- DistillationCTCLoss: # 基于蒸馏的CTC损失函数,继承自标准的CTC loss
weight: 1.0 # 损失函数的权重,loss_config_list中,每个损失函数的配置都必须包含该字段
model_name_list: ["Student", "Student2", "Teacher"] # 对于蒸馏模型的预测结果,提取这三个子网络的输出,与gt计算CTC loss
key: head_out # 取子网络输出dict中,该key对应的tensor
- DistillationDMLLoss: # 蒸馏的DML损失函数,继承自标准的DMLLoss
weight: 1.0 # 权重
act: "softmax" # 激活函数,对输入使用激活函数处理,可以为softmax, sigmoid或者为None,默认为None
model_name_pairs: # 用于计算DML loss的子网络名称对,如果希望计算其他子网络的DML loss,可以在列表下面继续填充
- ["Student", "Teacher"]
- ["Student2", "Teacher"]
- ["Student", "Student2"]
key: head_out # 取子网络输出dict中,该key对应的tensor
- DistillationDistanceLoss: # 蒸馏的距离损失函数
weight: 1.0 # 权重
mode: "l2" # 距离计算方法,目前支持l1, l2, smooth_l1
model_name_pairs: # 用于计算distance loss的子网络名称对
- ["Student", "Teacher"]
- ["Student2", "Teacher"]
- ["Student", "Student2"]
key: backbone_out # 取子网络输出dict中,该key对应的tensor
3.2.3 Enhanced CTC loss 改进
中文 OCR 任务经常遇到的识别难点是相似字符数太多,容易误识。借鉴 Metric Learning 中的想法,引入 Center loss,进一步增大类间距离,核心公式如下所示。
$$ L = L_{ctc} + \lambda * L_{center} $$
$$ L_{center} =\sum_{t=1}^T||x_{t} - c_{y_{t}}||_{2}^{2} $$
这里 $x_t$ 表示时间步长 $t$ 处的标签,$c_{y_{t}}$ 表示标签 $y_t$ 对应的 center。
Enhance CTC 中,center 的初始化对结果也有较大影响,在 PP-OCRv2 中,center 初始化的具体步骤如下所示。
- 基于标准的 CTC loss,训练一个网络;
- 提取出训练集合中识别正确的图像集合,记为 G ;
- 将 G 中的图片依次输入网络, 提取head输出时序特征的 $x_t$ 和 $y_t$ 的对应关系,其中 $y_t$ 计算方式如下:
$$ y_{t} = argmax(W * x_{t}) $$
- 将相同 $y_t$ 对应的 $x_t$ 聚合在一起,取其平均值,作为初始 center。
首先需要基于configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml训练一个基础网络
更多关于Center loss的训练步骤可以参考:Enhanced CTC Loss使用文档
最后,使用configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_enhanced_ctc_loss.yml进行训练,命令如下所示。
python tools/train.py -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_enhanced_ctc_loss.yml
主要改进点为Loss字段,相比于标准的CTCLoss,添加了CenterLoss。配置类别数、特征维度、center路径即可。
Loss:
name: CombinedLoss
loss_config_list:
- CTCLoss:
use_focal_loss: false
weight: 1.0
- CenterLoss:
weight: 0.05
num_classes: 6625
feat_dim: 96
center_file_path: "./train_center.pkl"
3.2.4 文本识别优化小结
PP-OCRv2文字识别模型优化过程中,对模型从骨干网络、损失函数等角度进行改进,并引入知识蒸馏的训练方法,最终将识别精度从 66.7% 提升至 74.8%,具体消融实验如下所示。
PP-OCRv2识别模型消融实验
在PP-OCRv2文字检测的基础上,识别模型的实验效果如下所示。

4. 总结
本章主要介绍PP-OCR以及PP-OCRv2的优化策略。
PP-OCR从骨干网络、学习率策略、数据增广、模型裁剪量化等方面,共使用了19个对策略,对模型进行优化瘦身,最终打造了面向服务器端的PP-OCR server系统以及面向移动端的PP-OCR mobile系统。
相比于PP-OCR, PP-OCRv2 在骨干网络、数据增广、损失函数这三个方面进行进一步优化,解决端侧预测效率较差、背景复杂以及相似字符的误识等问题,同时引入了知识蒸馏训练策略,进一步提升模型精度,最终打造了精度、速度远超PP-OCR的文字检测与识别系统。
参考链接
https://aistudio.baidu.com/education/group/info/25207
https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.7
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
OCR文字检测与识别系统:融合文字检测、文字识别和方向分类器的综合解决方案的更多相关文章
- 人脸识别系统 —— 基于python的人工智能识别核心
起因 自打用python+django写了一个点菜系统,就一直沉迷python编程.正好前几天公司boss要我研究一下人脸识别,于是我先用python编写了一个人脸识别系统的核心,用于之后的整个系统. ...
- Android名片扫描识别系统SDK
Android名片扫描识别系统SDK 一.Android名片扫描识别系统应用背景 这些年,随着移动互联的发展,APP应用成爆发式的增长,在很多APP中都涉及到对名片信息的录入,如移动CRM.移动端OA ...
- 基于opencv的车牌识别系统
前言 学习了很长一段时间了,需要沉淀下,而最好的办法就是做一个东西来应用学习的东西,同时也是一个学习的过程. 概述 OpenCV的全称是:Open Source Computer Vision ...
- 【OCR技术系列之四】基于深度学习的文字识别(3755个汉字)
上一篇提到文字数据集的合成,现在我们手头上已经得到了3755个汉字(一级字库)的印刷体图像数据集,我们可以利用它们进行接下来的3755个汉字的识别系统的搭建.用深度学习做文字识别,用的网络当然是CNN ...
- 【OCR技术系列之四】基于深度学习的文字识别
上一篇提到文字数据集的合成,现在我们手头上已经得到了3755个汉字(一级字库)的印刷体图像数据集,我们可以利用它们进行接下来的3755个汉字的识别系统的搭建.用深度学习做文字识别,用的网络当然是CNN ...
- javacpp-opencv图像处理系列:国内车辆牌照检测识别系统(万份测试车牌识别准确率99.7%以上,单次平均耗时39ms)
javaCV图像处理系列: 一.javaCV图像处理之1:实时视频添加文字水印并截取视频图像保存成图片,实现文字水印的字体.位置.大小.粗度.翻转.平滑等操作 二.javaCV图像处理之2:实时视频添 ...
- tesseract-ocr识别英文和中文图片文字以及扫描图片实例讲解
本文来源:http://blog.csdn.net/wanghui2008123/article/details/37694307 本文参考http://blog.sina.com.cn/s/blog ...
- 基于OpenCv的人脸检测、识别系统学习制作笔记之三
1.在windows下编写人脸检测.识别系统.目前已完成:可利用摄像头提取图像,并将人脸检测出来,未进行识别. 2.在linux下进行编译在windows环境下已经能运行的代码. 为此进行了linux ...
- 基于深度学习的鸟类检测识别系统(含UI界面,Python代码)
摘要:鸟类识别是深度学习和机器视觉领域的一个热门应用,本文详细介绍基于YOLOv5的鸟类检测识别系统,在介绍算法原理的同时,给出Python的实现代码以及PyQt的UI界面.在界面中可以选择各种鸟类图 ...
- 【OCR技术系列之五】自然场景文本检测技术综述(CTPN, SegLink, EAST)
文字识别分为两个具体步骤:文字的检测和文字的识别,两者缺一不可,尤其是文字检测,是识别的前提条件,若文字都找不到,那何谈文字识别.今天我们首先来谈一下当今流行的文字检测技术有哪些. 文本检测不是一件简 ...
随机推荐
- MongoDB 占用CPU资源过高
情况如下 db.currentOp() 发现有全表扫描 将 Collscan 对应的 Collection 建索引 db.Table1.createIndex({"DataTime" ...
- 电子签章Java后端与前端交互签名位置计算
电子签章过程中存在着在网页上对签署文件进行预览.指定签署位置.文件签署等操作,由于图片在浏览器上的兼容性和友好性优于PDF文件,所以一般在网页上进行电子签章时,会先将PDF文件转换成图片,展示给用户. ...
- c#-微软2
练习-编写第一个代码: 在第一次练习中你将使用c#将神圣的程序员用语打印到控制台的标准输出 编写第一行代码: 在软件开发者中,有这么一个传统,那就是将"Hello World!"这 ...
- Codeforces Round #658 (Div. 2)
A.Common Subsequence 题意 给你两组数,问你有没有相同 的书,有的话,输出最短的那组(大家都知道,1是最小的) AC #include<bits/stdc++.h> ...
- Windows环境下,解决无法使用ping命令
众所周知,ping命令是个非常实用的网络命令:有时,我们会发现在电脑中无法使用ping命令,一般来说,是由于电脑的环境变量出了问题,本文将介绍如何解决这个问题. 1.一般出现ping命令无法使用的情况 ...
- 你有一份Rx编程秘籍请签收
一.背景 在学习Rx编程的过程中,理解Observable这个概念至关重要,常规学习过程中,通常需要进行多次"碰壁"才能逐渐"开悟".这个有点像小时候学骑自行车 ...
- 2023陕西省大学生信息安全竞赛web writeup
前言 早写好了,忘发了,题目质量还行,够我坐大牢 ezpop 简单的反序列化,exp如下 <?php class night { public $night; } class day { pub ...
- 操作系统OS学习总结
操作系统OS笔记 操作系统概述 操作系统定义 操作系统,是计算机系统中最基本.最重要的系统软件,是其它软件的支撑.控制和管理计算机系统的硬件和软件资源,合理的组织计算机工作流程,并为用户使用计算机提供 ...
- shell 编程中 awk ,wc ,$0,$1 等 命令的使用总结
本文为博主原创,转载请注明出处: 1. awk 的常用场景总结 2. wc 常用场景总结 3. $0,$1,$# 的使用总结 4. seq 的使用总结 5. 获取用户输入 read 使用 1. awk ...
- Python追踪内存占用
技术背景 当我们需要对python代码所占用的内存进行管理时,首先就需要有一个工具可以对当前的内存占用情况进行一个追踪.虽然在Top界面或者一些异步的工具中也能够看到实时的内存变化,还有一些工具可以统 ...