【WALT】调度与负载计算(未更新完)
【WALT】调度与负载计算
代码版本:Linux4.9 android-msm-crosshatch-4.9-android12
注:本文中的任务主要指进程。
@
一、WALT 负载
0. top task load
该负载的计算在【WALT】top task 相关代码详解 中有描述,它本质上其实是根据 busytime 路径计算出来的任务负载得到的一个值,计算的方法也类似 demand 路径中用到的桶算法,我将它单列出来作为一种特殊负载。
1. 任务负载
在 WALT 算法中有两个路径计算任务的负载,分别是 update_task_demand() 和 update_cpu_busy_time()。我们简单称之为 demand 路径与 busytime 路径。
a. demand 路径
update_task_demand() 会统计任务在当前 WALT 窗口中的 runtime,通过 scale_exec_time() 对 runtime 进行归一化处理,称归一化后的 runtime 为负载,然后统计出任务在每个窗口内的负载,在窗口翻滚(rollover)时通过 update_hisroty() 保存进数组 sum_history 中。sum_history[RAVG_HIST_SIZE] 保存了历史 RAVG_HIST_SIZE 个窗口的负载。
p->ravg.demand:在 update_hisroty() 中根据数组 sum_history 中保存的历史窗口负载对下一个窗口的负载进行预测,预测结果为 demand。demand 主要用于 选核;p->ravg.pred_demand:在 predict_and_update_buckets() 中根据 桶算法 和数组 sum_history 中保存的历史窗口负载对下一个窗口的负载进行预测,预测结果为 pred_demand。同时,在 update_task_pred_demand() 中,如果任务在当前窗口中预测出来的 demand 值小于 curr_window(该值的描述在下方 busytime 路径中),则再次使用桶算法计算 pred_demand。pred_demand 主要用于 调频。
b. busytime 路径
update_cpu_busy_time() 会统计任务在当前 WALT 窗口中的 runtime,通过 scale_exec_time() 对 runtime 进行归一化处理,统计出任务在在每个窗口内的负载,更新到当前窗口的 curr_window 中以及前一窗口的 prev_window 中。更新指的是它并不会在窗口翻滚时才保存负载值,而是实时更新,在窗口翻滚时才会将 curr_window 的值赋给 prev_window,然后将 curr_window 的值置 0。
p->ravg.curr_window:表示任务在当前(尚未完成)窗口中的 CPU 需求(represents cpu demand of task in its most recently tracked window)p->ravg.prev_window:表示 curr_window 跟踪的窗口之前的窗口中任务的 CPU 需求(represents cpu demand of task in the window prior to the one being tracked by curr_window)
值得注意的是,update_task_demand() 和 update_cpu_busy_time() 两种路径的进入条件不同,统计出来的 runtime 也不同。
2. CPU 负载
CPU 负载也有两种路径,可以简单视作对两种路径的任务负载的累加。
a. busytime 路径
update_cpu_busy_time() 会统计任务在当前 WALT 窗口中的 runtime,并直接累加进 runnable_sum 中,窗口翻滚时才会将 curr_runnable_sum 赋给 prev_runnable_sum,并将 curr_runnable_sum 置 0。根据是否是当前窗口以及任务是否是新任务,将 runnable_sum 分为以下四种:
rq->curr_runnable_sum:从当前(尚未完成)窗口执行的所有任务的总需求(aggregate demand from all tasks which executed during the current (not yet completed) window)rq->prev_runnable_sum:最近完成的窗口期间执行的所有任务的聚合需求(aggregate demand from all tasks which executed during the most recent completed window)rq->nt_curr_runnable_sum:当前(尚未完成)窗口期间执行的所有“新”任务的总需求(aggregate demand from all 'new' tasks which executed during the current (not yet completed) window)rq->nt_prev_runnable_sum:最近完成的窗口期间执行的所有“新”任务的总需求(aggregate demand from all 'new' tasks which executed during the most recent completed window)
其中,“新”任务指的是:自 fork 以来活动窗口数量小于 SCHED_NEW_TASK_WINDOWS 的任务。活动窗口定义为观察到任务可运行的窗口。(A 'new' task is defined as a task whose number of active windows since fork is less than SCHED_NEW_TASK_WINDOWS. An active window is defined as a window where a task was observed to be runnable.)
如果任务属于相关线程组(related_thread_group),那么以上 runnable_sum 将会统计进 rq 的 grp_time 中(由 rq->xxx 变为 rq->grp_time.xxx)。
busytime 路径下的负载计算可以点击【WALT】update_cpu_busy_time() 代码详解 查看
b. demand 路径
demand 路径下的 CPU 负载较为复杂,以下篇幅将详细阐述三种负载的统计方式:
rq->cum_window_demand:rq->walt_stats.cumulative_runnable_avg:rq->walt_stats.pred_demands_sum:
二、demand 路径下 CPU 负载的统计方式
0. 基础信息
注:本文中的任务主要指进程。
a. TASK_RUNNING(任务状态之一)
| |<----- runnable ------>|<---------- running ---------->|<-- runnable ->|
|-----------|-----------------------|-------------------------------|---------------|
wakeup enqueue start_exec end_exec dequeue
任务从睡眠状态被唤醒时,任务的状态会被设置为 TASK_RUNNING,随后任务入队。
TASK_RUNNING 包含两种状态:
- running:任务正在占用 CPU ;
- runnable(ready):任务刚进入队列还未上 CPU 的状态,或是任务在 running 时时间片耗尽或者主动让出 CPU、或者被更高优先级进程抢占后,在队列中等待的状态。
处于 TASK_RUNNING 状态的进程要么正在 CPU 上运行,要么随时都可以投入运行,只不过CPU资源有限,调度器暂时没有选中他们。
处于 TASK_RUNNING 状态的进程是调度器的调度对象。在 Linux 中,每个 CPU 都有自己的运行队列。如果是实时进程(rt),则根据优先级的情况落在相应的优先级的队列上;如果是普通进程(cfs),则根据虚拟运行时间,落在红黑树相应位置上。
Linux 通过 __schedule() 函数进行任务的调度,该函数调用 pick_netx_task() 选出下一个要上 CPU 的任务,通过 context_switch() 进行上下文切换,让选出的任务上 CPU 执行。
b. 调度相关
1) 调度策略
进程在 sched.h 中的数据结构如下:
struct task_struct {
……
int on_rq;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_SCHED_WALT
struct ravg ravg;
#endif
struct sched_dl_entity dl;
unsigned int policy;
};
policy:进程的调度策略,一共分为 6 中调度策略:
/*
* Scheduling policies
*/
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
#define SCHED_DEADLINE 6
- SCHED_DEADLINE:基于EDF(earliest deadline first),针对突发型计算,并且对延迟和完成时间敏感的进程使用,调度优先级最高的用户进程,选择 deadline 调度器;
- SCHED_RR:时间片轮转,进程用完时间片后加入优先级对应运行队列的尾部,把 CPU 让给同优先级的其他进程,选择 realtime 调度器;
- SCHED_FIFO:先进先出调度,没有时间片,在没有更高优先级的情况下, 只能等待主动让出 CPU,选择 realtime 调度器;
- SCHED_NORMAL:普通的分时进程,被用于绝大多数用户进程,选择 CFS 调度器;
- SCHED_BATCH:是SCHED_NORMAL的分化版本。适用于没有用户交互行为的后台进程,用户对该类进程的响应时间要求不高,但对吞吐量要求较高,因此调度器会在完成所有 SCHED_NORMAL 的进程之后让该类进程不受打扰地跑上一段时间,这样能够最大限度地利用缓存,适合成批处理的工作,选择 CFS 调度器;
- SCHED_IDLE:优先级最低,在系统空闲时运行,给 0 号进程(swapper)使用,选择 idle 调度器;
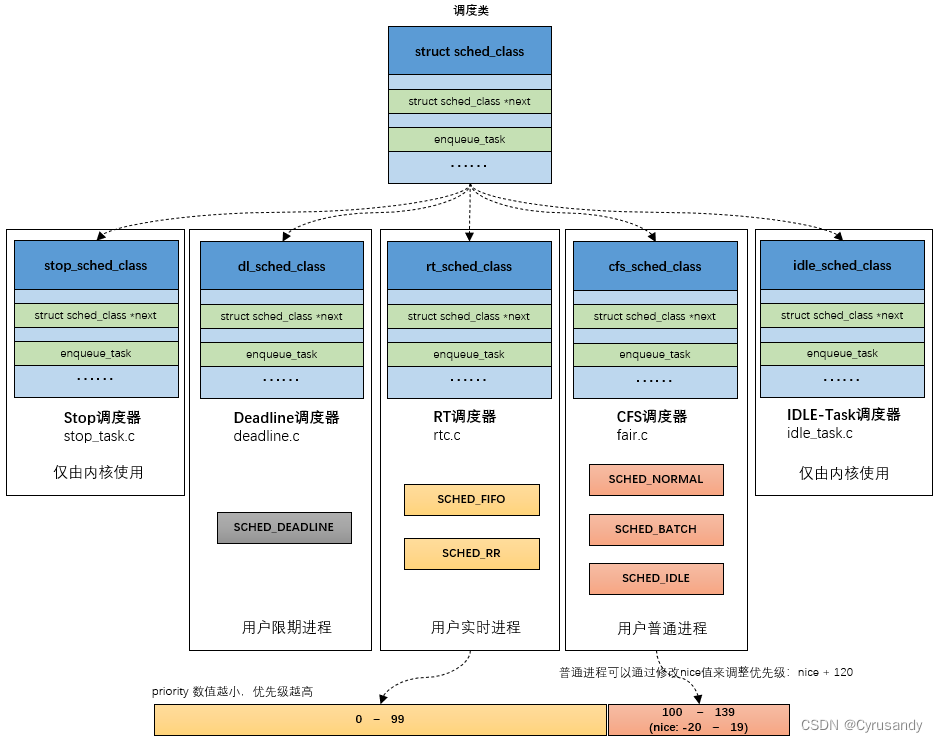
2) 调度类
sched_class:对调度器进行抽象,一共分为 5 类调度类,按照优先级有高到底排序依次为:
- stop_sched_class:优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占;
- dl_sched_class:使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行;
- rt_sched_class:为每个优先级维护一个队列;
- fair_sched_class:采用完全公平调度算法,引入虚拟运行时间概念;
- idle_sched_class:每个CPU都会有一个idle线程,当没有其他进程可以调度时,调度运行idle线程;
不同的调度类绑定了不同的方法,如下所示:
rt任务:
const struct sched_class rt_sched_class = {
……
.enqueue_task = enqueue_task_rt,
.dequeue_task = dequeue_task_rt,
#ifdef CONFIG_SCHED_WALT
.fixup_walt_sched_stats = fixup_walt_sched_stats_common,
#endif
}
dl任务:
const struct sched_class dl_sched_class = {
……
.enqueue_task = enqueue_task_dl,
.dequeue_task = dequeue_task_dl,
#ifdef CONFIG_SCHED_WALT
.fixup_walt_sched_stats = fixup_walt_sched_stats_common,
#endif
}
stop任务:
const struct sched_class stop_sched_class = {
……
.enqueue_task = enqueue_task_stop,
.dequeue_task = dequeue_task_stop,
#ifdef CONFIG_SCHED_WALT
.fixup_walt_sched_stats = fixup_walt_sched_stats_common,
#endif
}
cfs任务:
const struct sched_class fair_sched_class = {
……
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
#ifdef CONFIG_SCHED_WALT
.fixup_walt_sched_stats = walt_fixup_sched_stats_fair,
#endif
以上部分资料与下图来自 吐血整理 | 肝翻 Linux 进程调度所有知识点:
3) 调度实体
struct sched_entity se:采用 CFS 算法调度的普通非实时进程的调度实体。
cfs 调度实体在 sched.h 中的数据结构如下:struct sched_entity {
……
struct rb_node run_node;
unsigned int on_rq;
u64 vruntime;
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
#endif
};
每个就绪态的调度实体包含插入红黑树中使用的节点 run_node,同时 vruntime 成员记录已经运行的虚拟时间。
同时,on_rq 表明是否处于 CFS 运行队列中,这部分将在下文详细描述。
struct sched_rt_entity rt:采用 Roound-Robin 或者 FIFO 算法调度的实时调度实体。struct sched_rt_entity {
……
unsigned short on_rq;
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity *parent;
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq;
#endif
};
struct sched_dl_entity dl:采用 EDF 算法调度的实时调度实体。
值得注意的是:每一个进程的 task_struct 中都嵌入了 sched_entity 对象,所以进程是可调度的实体,但是可调度的实体不一定是进程,也可能是进程组。
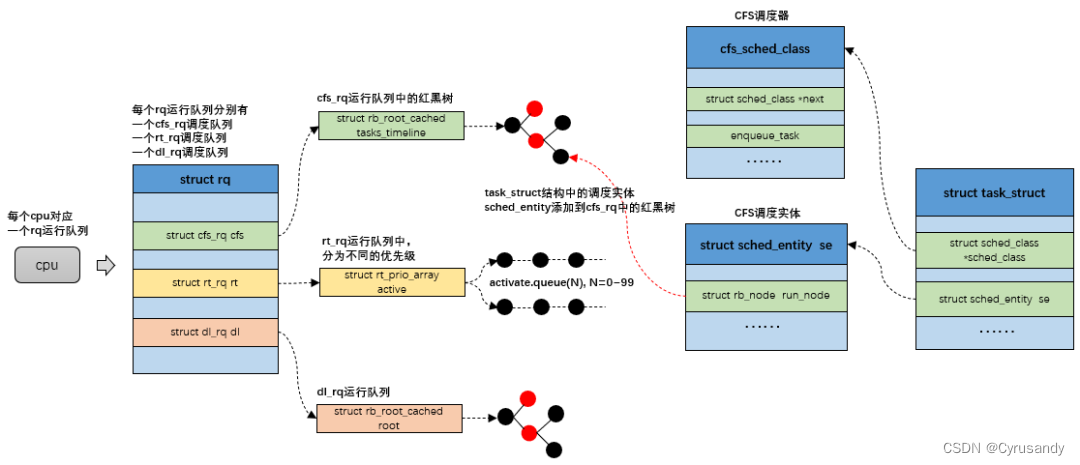
4) 运行队列
调度器的核心工作就是把可运行的任务放到 CPU 上运行,Linux 内核使用一个运行队列(runqueue)来存放可运行的任务,是本 CPU 上所有可运行进程的队列集合。运行队列在 sched.h 中的数据结构如下:
struct rq {
……
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
};
每个 CPU 都有一个运行队列,每个运行队列中有三个调度队列,task 作为调度实体加入到各自的调度队列中。
以上部分资料与下图来自 吐血整理 | 肝翻 Linux 进程调度所有知识点:
5) on_rq 标志位
任务入队时,它的 on_rq 为 1,任务对应的 cfs 调度实体的 on_rq 同样也 1。
p->on_rq:在 sched.h 中设置了两种 on_rq 的状态:
/* task_struct::on_rq states: */
#define TASK_ON_RQ_QUEUED 1
#define TASK_ON_RQ_MIGRATING 2
- on_rq == 0 时意味着任务不在运行队列中;
- on_rq == 1 时意味着任务在运行队列中;
- on_rq == 2 时意味着任务在运行队列中,但正在迁移到另一个运行队列。
cfs 调度实体中也设置了 on_rq,但它只等于 0 或 1。它表明了 cfs 调度实体是否在 cfs 运行队列之中。
cfs_rq:跟踪就绪队列信息以及管理就绪态调度实体,并维护一棵按照虚拟时间排序的红黑树。
struct cfs_rq {
...
struct rb_root_cached tasks_timeline
};
tasks_timeline->rb_root 是红黑树的根,tasks_timeline->rb_leftmost 指向红黑树中最左边的调度实体,即虚拟时间最小的调度实体。上文说到,每个就绪态的调度实体包含插入红黑树中使用的节点 run_node,同时 vruntime 成员记录已经运行的虚拟时间。因此可以整理出下图。
以上部分资料与下图来自 吐血整理 | 肝翻 Linux 进程调度所有知识点:
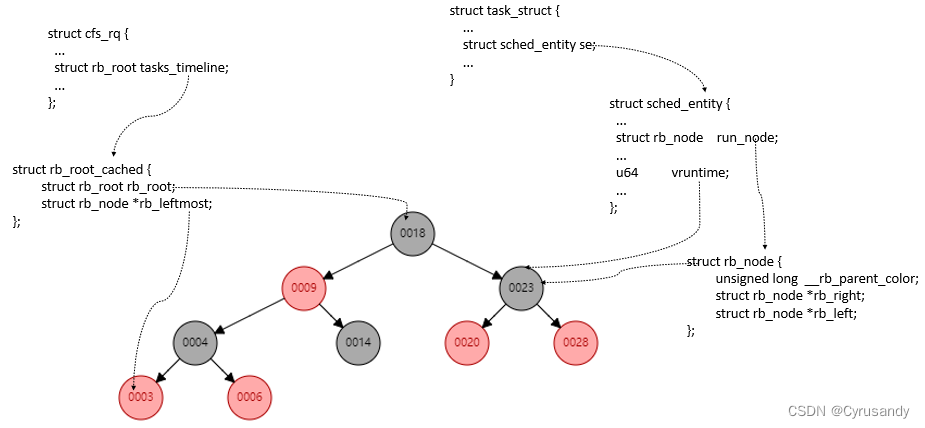
值得注意的是:
- cfs 运行队列里面包含有一个红黑树,但这个红黑树并不是 cfs 运行队列的全部,因为红黑树仅仅是用于选择出下一个调度程序的算法。当一个进程由就绪态切换到运行态时,该进程会被从红黑树中移除,但是还是处于 cfs 运行队列中,因此其 on_rq 为 1。只有准备退出、即将睡眠等待和转为实时进程的进程,其 cfs 运行队列的 on_rq 为 0。
- 尽管 cfs 运行队列使用红黑树对所有调度实体进行管理,但这并不是 cfs 运行队列的全部,还包括相应数据结构以及标志位的更新,进程加入就绪队列并不仅仅是将调度实体的 run_node 节点添加到红黑树中,还涉及到一系列的操作,包括更新 vruntime、更新负载信息、更新 on_rq 标志位等等。
c. 组调度
上文提到,进程是可调度的实体,但是可调度的实体不一定是进程,也可能是进程组。sched_entity 结构体中判断一个调度实体是否是进程组的字段是 my_q。如果该字段为 NULL,则表示该调度实体一个任务,否则就是一个进程组组。
my_q 同样是结构体 cfs_rq,也就是说同一个 CPU 上隶属于同一个进程组的进程又通过另一个 cfs_rq —— my_q 组织了起来,放在另一棵红黑树中。
进程组在 sched.h 中的数据结构如下:
/* task group related information */
struct task_group {
……
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each cpu */
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
struct cfs_rq **cfs_rq;
unsigned long shares;
……
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
……
struct cfs_bandwidth cfs_bandwidth;
};
以下图片来自 CFS调度器(3)-组调度,组调度详细知识可以点击链接查看:
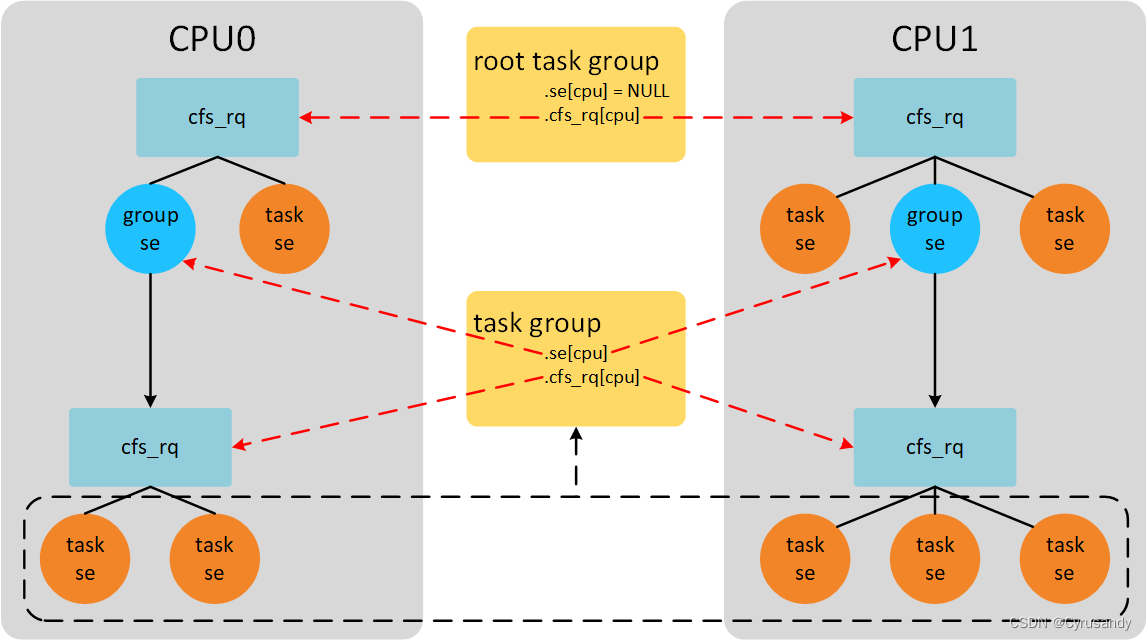
隶属于同一个调度组的调度实体不一定都在同一个 cfs_rq 中,可以分布在多个 CPU 的 cfs_rq 中,如上图底部的五个调度实体。
假设 CPU1 的调度组(group se)中的一个调度实体(例如右下角的调度实体)在执行,在上层 cfs_rq 看来,调度组就是正在执行的调度实体,但事实上真正执行的是调度组内部的 cfs_rq 上的一个调度实体。这个时候,调度实体的 on_rq 为 1,调度组的 on_rq 也为 1。
假设 CPU1 中的调度组 A 中有一个调度实体 B 已经在队列中(下方的 cfs_rq),那么调度组 A 同样也在队列中(上方的 cfs_rq)。此时 B->on_rq 和 A->on_rq 都为 1。如果调度组 A 中有另一个调度实体 C 要入队,直接将其添加到 A->cfs_rq(下方的 cfs_rq)就行。
但是如果调度实体 B 不在队列中,那么调度组 A 也不在队列中。如果调度实体 C 要入队,这时候就需要通过递归(enqueue_task_fair(),下文将会介绍)将 C 和 A 都进行入队操作。
d. cfs 带宽控制
带宽控制是通过设置两个变量 quota 和 period 来限制一个进程组的最大使用 CPU 带宽。
period 是指一段周期时间;quota 是指在 period 周期时间内,一个进程组组可以使用的 CPU 时间限额。当进程组进程的运行时间超过 quota 后,找个进程组就会被限制运行,这个动作被称作 throttle。直到下一个 period 周期开始,这个进程组会被重新调度,这个过程称作 unthrottle。
quota 和 period 的值存储在 cfs_bandwidth 结构体中,该结构体嵌在 task_group 中,cfs_bandwidth 结构体还包含 runtime 成员记录剩余限额时间。带宽控制在 sched.h 中的数据结构如下:
struct cfs_bandwidth {
#ifdef CONFIG_CFS_BANDWIDTH
……
ktime_t period;
u64 quota, runtime;
s64 hierarchical_quota;
u64 runtime_expires;
int idle, period_active;
struct hrtimer period_timer, slack_timer;
struct list_head throttled_cfs_rq;
/* statistics */
int nr_periods, nr_throttled;
u64 throttled_time;
bool distribute_running;
#endif
};
每当进程组中的进程运行一段时间时,对应的 runtime 时间也在减少。系统会启动一个高精度定时器,周期时间是 period,在定时器时间到达后重置剩余限额时间 runtime 为 quota,开始下一个轮时间跟踪。所有的进程组进程运行的时间累加在一起,保证总的运行时间小于quota。
限制一个进程组中的进程可以简单的将进程组管理的调度实体从对应的就绪队列上删除,然后标记调度实体对应的 group cfs_rq 的标志位。每个用户组会管理CPU个数的就绪队列group cfs_rq。每个group cfs_rq中也有限额时间,该限额时间是从全局用户组quota中申请。例如,周期period值100ms,限额quota值50ms,2个CPU系统。CPU0上group cfs_rq首先从全局限额时间中申请5ms时间(此实runtime值为45),然后运行进程。当5ms时间消耗完时,继续从全局时间限额quota中申请5ms(此实runtime值为40)。CPU1上的情况也同样如此,先以就绪队列cfs_rq的身份从quota中申请一个时间片,然后供进程运行消耗。当全局quota剩余时间不足以满足CPU0或者CPU1申请时,就需要throttle对应的cfs_rq。在定时器时间到达后,unthrottle所有已经throttle的cfs_rq。
总结一下就是,cfs_bandwidth就像是一个全局时间池(时间池管理时间,类比内存池管理内存)。每个group cfs_rq如果想让其管理的红黑树上的调度实体调度,必须首先向全局时间池中申请固定的时间片,然后供其进程消耗。当时间片消耗完,继续从全局时间池中申请时间片。终有一刻,时间池中已经没有时间可供申请。此时就是throttle cfs_rq的大好时机。
e. DL 调度器
deadline 任务有三个重要的属性:运行时间 runtime,周期 period,截止期限 deadline。
举个例子:
curr_time
| | ↓ | |
|---------------|-------------------·---|-----------|-------------------|
wakeup start_exec | absolute deadline
|<------ runtime ------>|
|<----------------- deadline ------------------>|
|<---------------------------- period ----------------------------->|
runtime 是完成任务工作需要的 CPU 执行时间,即在一个周期中,需要 CPU 参与运算的时间值。runtime在设定的时候必须考虑最坏情况下的执行时间,且调度器需要确保任务在每个 period 时间窗口内得到 runtime 这么多的 CPU 时间,并且必须在 deadline 这个时间点之前得到。
deadline 定义了处理完成的结果必须被交付的最后期限。当产生一个调度点的时候,DL 调度器总是选择其 deadline 距离当前时间点最近的那个任务并调度它执行。
f. 主要函数(walt_fixup_cum_window_demand() 和 fixup_cumulative_runnable_avg())
我们先介绍两个函数,这两个函数是 demand 路径下 CPU 负载统计时必要的函数,分别是 walt_fixup_cum_window_demand() 和 fixup_cumulative_runnable_avg()。
static inline void walt_fixup_cum_window_demand(struct rq *rq, s64 delta)
{
rq->cum_window_demand += delta;
if (unlikely((s64)rq->cum_window_demand < 0))
rq->cum_window_demand = 0;
}
将 delta 累加进任务所在的 CPU 的运行队列的 cum_window_demand 中。
static inline void
fixup_cumulative_runnable_avg(struct walt_sched_stats *stats,
s64 task_load_delta, s64 pred_demand_delta)
{
// 是否禁用 CPU 的窗口统计
if (sched_disable_window_stats)
return;
stats->cumulative_runnable_avg += task_load_delta;
BUG_ON((s64)stats->cumulative_runnable_avg < 0);
stats->pred_demands_sum += pred_demand_delta;
BUG_ON((s64)stats->pred_demands_sum < 0);
}
将 task_load_delta 累加进任务所在的 CPU 的运行队列的 cumulative_runnable_avg 中,将 pred_demand_delta 累加进任务所在的 CPU 的运行队列的 pred_demands_sum 中。
1. 初始化
在 walt.c 中的 walt_sched_init() 中,会将 cum_window_demand、cumulative_runnable_avg 和 pred_demands_sum 初始化为 0。
void walt_sched_init(struct rq *rq) {
……
rq->walt_stats.cumulative_runnable_avg = 0;
rq->walt_stats.pred_demands_sum = 0;
rq->cum_window_demand = 0;
}
2. 任务入队与出队
入队相关代码
任务入队时,会调用 enqueue_task() 函数:
static inline void enqueue_task(struct rq *rq, struct task_struct *p, int flags) {
……
p->sched_class->enqueue_task(rq, p, flags);
}
通过判断任务所在的调度类,就能直接调用对应的方法:
rt任务:
static void
enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags) {
……
walt_inc_cumulative_runnable_avg(rq, p);
}
--------------------------------------------------------------------------------
dl任务:
static void enqueue_task_dl(struct rq *rq, struct task_struct *p, int flags) {
……
enqueue_dl_entity(&p->dl, pi_se, flags);
}
static void enqueue_dl_entity(struct sched_dl_entity *dl_se,
struct sched_dl_entity *pi_se, int flags) {
……
__enqueue_dl_entity(dl_se);
}
static void __enqueue_dl_entity(struct sched_dl_entity *dl_se) {
……
inc_dl_tasks(dl_se, dl_rq);
}
static inline
void inc_dl_tasks(struct sched_dl_entity *dl_se, struct dl_rq *dl_rq) {
……
walt_inc_cumulative_runnable_avg(rq_of_dl_rq(dl_rq), dl_task_of(dl_se));
}
--------------------------------------------------------------------------------
stop任务:
static void
enqueue_task_stop(struct rq *rq, struct task_struct *p, int flags) {
……
walt_inc_cumulative_runnable_avg(rq, p);
}
--------------------------------------------------------------------------------
cfs任务:' 细节可以查看【二、0. b. 5) 组调度】相关介绍 '
static void
enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
……
/* #define for_each_sched_entity(se) \
/* for (; se; se = se->parent) */
' 为了递归向上将没有添加到就绪队列的 '
' se 以及 se->parent 添加到就绪队列 '
for_each_sched_entity(se) {
if (se->on_rq)
break;
cfs_rq = cfs_rq_of(se);
enqueue_entity(cfs_rq, se, flags);
if (cfs_rq_throttled(cfs_rq))
break;
cfs_rq->h_nr_running++;
walt_inc_cfs_rq_stats(cfs_rq, p);
flags = ENQUEUE_WAKEUP;
}
' 更新已经存在于就绪队列中的 '
' parent 节点中的相关信息 '
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
cfs_rq->h_nr_running++;
walt_inc_cfs_rq_stats(cfs_rq, p);
if (cfs_rq_throttled(cfs_rq))
break;
update_load_avg(se, UPDATE_TG);
update_cfs_shares(se);
}
if (!se) {
add_nr_running(rq, 1);
inc_rq_walt_stats(rq, p);
}
……
}
static void walt_inc_cfs_rq_stats(struct cfs_rq *cfs_rq, struct task_struct *p) {
……
fixup_cumulative_runnable_avg(&cfs_rq->walt_stats, p->ravg.demand,
p->ravg.pred_demand);
}
void inc_rq_walt_stats(struct rq *rq, struct task_struct *p) {
……
walt_inc_cumulative_runnable_avg(rq, p);
}
在 fair 调度类的这一段代码中,进入 walt_inc_cfs_rq_stats() 执行 fixup_cumulative_runnable_avg() 时是让 cfs_rq 的 cumulative_runnable_avg 和 pred_demands_sum 加上任务的 demand 和 pred_demand;
而进入 inc_rq_walt_stats() 执行 walt_inc_cumulative_runnable_avg() 时是让 rq 的 cumulative_runnable_avg 和 pred_demands_sum 加上任务的 demand 和 pred_demand。
几乎所有的任务入队的最后都会进入 walt_inc_cumulative_runnable_avg():
static inline void
walt_inc_cumulative_runnable_avg(struct rq *rq, struct task_struct *p) {
// 是否禁用 CPU 的窗口统计
if (sched_disable_window_stats)
return;
fixup_cumulative_runnable_avg(&rq->walt_stats, p->ravg.demand,
p->ravg.pred_demand);
/*
* Add a task's contribution to the cumulative window demand when
*
* (1) task is enqueued with on_rq = 1 i.e migration, prio/cgroup/class change.
* (2) task is waking for the first time in this window.
*/
if (p->on_rq || (p->last_sleep_ts < rq->window_start))
walt_fixup_cum_window_demand(rq, p->ravg.demand);
}
出队相关代码
任务入队时,会调用 dequeue_task() 函数:
static inline void dequeue_task(struct rq *rq, struct task_struct *p, int flags) {
……
p->sched_class->dequeue_task(rq, p, flags);
}
通过判断任务所在的调度类,就能直接调用对应的方法:
rt任务:
static void dequeue_task_rt(struct rq *rq, struct task_struct *p, int flags) {
……
walt_dec_cumulative_runnable_avg(rq, p);
}
--------------------------------------------------------------------------------
dl任务:
static void dequeue_task_dl(struct rq *rq, struct task_struct *p, int flags) {
……
__dequeue_task_dl(rq, p, flags);
}
static void __dequeue_task_dl(struct rq *rq, struct task_struct *p, int flags) {
dequeue_dl_entity(&p->dl);
……
}
static void dequeue_dl_entity(struct sched_dl_entity *dl_se) {
__dequeue_dl_entity(dl_se);
}
static void __dequeue_dl_entity(struct sched_dl_entity *dl_se) {
……
dec_dl_tasks(dl_se, dl_rq);
}
static inline
void dec_dl_tasks(struct sched_dl_entity *dl_se, struct dl_rq *dl_rq) {
……
walt_dec_cumulative_runnable_avg(rq_of_dl_rq(dl_rq), dl_task_of(dl_se));
}
--------------------------------------------------------------------------------
stop任务:
static void
dequeue_task_stop(struct rq *rq, struct task_struct *p, int flags) {
……
walt_dec_cumulative_runnable_avg(rq, p);
}
--------------------------------------------------------------------------------
cfs任务:' cfs任务出队和入队的逻辑相近 '
static void dequeue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
int task_sleep = flags & DEQUEUE_SLEEP;
' 如果当前 se 存在 parent,且该 parent 下'
' 不存在其它子 se 在就绪队列上,parent 同时出队; '
' 如果 parent 下还存在其它 se 在就绪队列上, '
' parent 不需要出队 '
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
dequeue_entity(cfs_rq, se, flags);
if (cfs_rq_throttled(cfs_rq))
break;
cfs_rq->h_nr_running--;
walt_dec_cfs_rq_stats(cfs_rq, p);
/* Don't dequeue parent if it has other entities besides us */
if (cfs_rq->load.weight) {
se = parent_entity(se);
if (task_sleep && se && !throttled_hierarchy(cfs_rq))
set_next_buddy(se);
break;
}
flags |= DEQUEUE_SLEEP;
}
' 更新已经存在于就绪队列中的 '
' parent 节点中的相关信息 '
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
cfs_rq->h_nr_running--;
walt_dec_cfs_rq_stats(cfs_rq, p);
if (cfs_rq_throttled(cfs_rq))
break;
update_load_avg(se, UPDATE_TG);
update_cfs_shares(se);
}
if (!se) {
sub_nr_running(rq, 1);
dec_rq_walt_stats(rq, p);
}
……
}
static void walt_dec_cfs_rq_stats(struct cfs_rq *cfs_rq, struct task_struct *p) {
……
fixup_cumulative_runnable_avg(&cfs_rq->walt_stats, -(s64)p->ravg.demand,
-(s64)p->ravg.pred_demand);
}
void dec_rq_walt_stats(struct rq *rq, struct task_struct *p) {
……
walt_dec_cumulative_runnable_avg(rq, p);
}
在 fair 调度类的这一段代码中,进入 walt_dec_cfs_rq_stats() 执行 fixup_cumulative_runnable_avg() 时是让 cfs_rq 的 cumulative_runnable_avg 和 pred_demands_sum 减去任务的 demand 和 pred_demand;
而进入 dec_rq_walt_stats() 执行 walt_dec_cumulative_runnable_avg() 时是让 rq 的 cumulative_runnable_avg 和 pred_demands_sum 减去任务的 demand 和 pred_demand。
几乎所有的任务出队的最后都会进入 walt_dec_cumulative_runnable_avg():
static inline void
walt_dec_cumulative_runnable_avg(struct rq *rq, struct task_struct *p) {
if (sched_disable_window_stats)
return;
fixup_cumulative_runnable_avg(&rq->walt_stats, -(s64)p->ravg.demand,
-(s64)p->ravg.pred_demand);
/*
* on_rq will be 1 for sleeping tasks. So check if the task is migrating or dequeuing in RUNNING state to change the prio/cgroup/class.
*/
if (task_on_rq_migrating(p) || p->state == TASK_RUNNING)
walt_fixup_cum_window_demand(rq, -(s64)p->ravg.demand);
}
任务入队与出队总结
入队
任务入队的时候,无论哪一种调度类,最终都会执行
fixup_cumulative_runnable_avg(),进行 rq->walt_stats.cumulative_runnable_avg += demand 和 rq->walt_stats.pred_demands_sum += pred_demand。同时,任务对应调度实体及其父节点入队时也都会进行一次 cfs_rq->walt_stats.cumulative_runnable_avg += demand 和 cfs_rq->walt_stats.pred_demands_sum += pred_demand。
除此之外,会根据以下条件之一是否满足执行
walt_fixup_cum_window_demand():- 任务正在运行队列中时(p->on_rq == 1 == TASK_ON_RQ_QUEUED);
- 任务在此窗口中首次唤醒(p->last_sleep_ts < rq->window_start)。
这两条条件其中之一满足的时候,cum_window_demand += demand。
出队
任务出队的时候,无论哪一种调度类,最终都会执行
fixup_cumulative_runnable_avg(),进行 rq->walt_stats.cumulative_runnable_avg -= demand 和 rq->walt_stats.pred_demands_sum -= pred_demand。同时,任务对应调度实体及其父节点出队时也都会进行一次 cfs_rq->walt_stats.cumulative_runnable_avg -= demand 和 cfs_rq->walt_stats.pred_demands_sum -= pred_demand。
除此之外,会根据以下条件之一是否满足执行
walt_fixup_cum_window_demand():(代码中的注释说:对于休眠任务,on_rq 将为 1。是这样的吗?)
- 任务处于迁移过程中,可能不在就绪队列中(p->on_rq == 2 == TASK_ON_RQ_MIGRATING);
- 任务处于 TASK_RUNNING 状态下迁移或出队(p->state == TASK_RUNNING)。
这两条条件其中之一满足的时候,cum_window_demand -= demand。
总而言之,在任务入队的时候会直接将其之前得到的 demand 和 pred_demand 放入 CPU 负载之中,在出队时再去掉这部分。
3. WALT 窗口翻滚
在 【WALT】update_history() 代码详解 中我们介绍了 WALT 在窗口翻滚的时候是如何计算 demand 的,以及是如何通过 【WALT】predict_and_update_buckets() 代码详解 计算 pred_demand 的。
窗口翻滚相关代码
我们在 update_history() 中的这部分代码中可以知道,在计算完任务的 demand 和 pred_demand 之后,WALT 将他们更新到 CPU 负载中去了:
static void update_history(struct rq *rq, struct task_struct *p,
u32 runtime, int samples, int event)
{
……
// ⑸ 将 demand 与 pred_demand 更新到 rq 中
if (!task_has_dl_policy(p) || !p->dl.dl_throttled) {
if (task_on_rq_queued(p))
p->sched_class->fixup_walt_sched_stats(rq, p, demand,
pred_demand);
else if (rq->curr == p)
walt_fixup_cum_window_demand(rq, demand);
}
……
}
首先先判断两个条件:
!task_has_dl_policy(struct task_struct *p):这句话等同于policy != SCHED_DEADLINE,也就是该任务的调度策略并非 dl 策略;!p->dl.dl_throttled:即任务没有耗尽调度器设置的运行时间,解释如下:内核中这么描述 dl_throttled:@dl_throttled 告诉我们是否耗尽了运行时间。如果是这样,任务必须等待下次触发 dl_timer 时执行补充。(@dl_throttled tells if we exhausted the runtime. If so, the task has to wait for a replenishment to be performed at the next firing of dl_timer.)
在【二、0. c. DL 调度器】中简单描述了 runtime、deadline 和 period 之间的关系。耗尽了运行时间是指任务在当前 period 之中的运行时间大于等于调度器设置的任务能够运行的最长时间 runtime。
如果任务的调度策略不是 deadline,或 DL 任务并没有耗尽运行时间,还需要进行两次条件判断:
如果
task_on_rq_queued(p)为真,即 p->on_rq == 1 == TASK_ON_RQ_QUEUED 时(猜测:任务此时处于 runnable 状态,否则条件一囊括了条件二):执行不同调度类的
fixup_walt_sched_stats(rq, p, demand, pred_demand)p->sched_class->fixup_walt_sched_stats(rq, p, p->ravg.demand, p->ravg.pred_demand);
从【二、0. b. 2) 调度类】中我们可以知道,除了 cfs 任务对应的方法是
walt_fixup_sched_stats_fair(),其他的任务对应的方法都是fixup_walt_sched_stats_common()。先来看看
walt_fixup_sched_stats_fair()方法:#ifdef CONFIG_CFS_BANDWIDTH
static void walt_fixup_sched_stats_fair(struct rq *rq, struct task_struct *p,
u32 new_task_load, u32 new_pred_demand)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
// new_demand - p->ravg.demand
s64 task_load_delta = (s64)new_task_load - task_load(p);
// new_pred_demand - p->ravg.pred_demand
s64 pred_demand_delta = PRED_DEMAND_DELTA; for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se); fixup_cumulative_runnable_avg(&cfs_rq->walt_stats,
task_load_delta,
pred_demand_delta);
if (cfs_rq_throttled(cfs_rq))
break;
} /* Fix up rq->walt_stats only if we didn't find any throttled cfs_rq */
if (!se) {
fixup_cumulative_runnable_avg(&rq->walt_stats,
task_load_delta,
pred_demand_delta);
walt_fixup_cum_window_demand(rq, task_load_delta);
}
}
#else /* CONFIG_CFS_BANDWIDTH */
static void walt_fixup_sched_stats_fair(struct rq *rq, struct task_struct *p,
u32 new_task_load, u32 new_pred_demand)
{
fixup_walt_sched_stats_common(rq, p, new_task_load, new_pred_demand);
}
#endif /* CONFIG_CFS_BANDWIDTH */
在 CONFIG_CFS_BANDWIDTH 打开的时候:
task_load_delta 是用新计算出来的 demand 减去上一次的 demand 得到的,pred_demand_delta 是用新计算出来的 pred_demand 减去上一次的 pred_demand 得到的;
遍历 se 及其 parent,通过
fixup_cumulative_runnable_avg()将任务的 task_load_delta 和 pred_demand_delta 加进 cfs_rq 的 cumulative_runnable_avg 和 pred_demands_sum 中;最后通过
fixup_cumulative_runnable_avg()和walt_fixup_cum_window_demand()将任务的 task_load_delta 加进 rq 的 cumulative_runnable_avg 和 cum_window_demand,将任务的 pred_demand_delta 加进 rq 的 pred_demands_sum 中。在 CONFIG_CFS_BANDWIDTH 没有打开的时候其实也执行的是
fixup_walt_sched_stats_common()。
void fixup_walt_sched_stats_common(struct rq *rq, struct task_struct *p,
u32 new_task_load, u32 new_pred_demand)
{
s64 task_load_delta = (s64)new_task_load - task_load(p);
s64 pred_demand_delta = PRED_DEMAND_DELTA; fixup_cumulative_runnable_avg(&rq->walt_stats, task_load_delta,
pred_demand_delta); walt_fixup_cum_window_demand(rq, task_load_delta);
}
也就是说,窗口翻滚的时候,如果当前任务处于 runnable 状态,直接通过
fixup_cumulative_runnable_avg()将任务的 task_load_delta 加进 rq 的 cumulative_runnable_avg,将任务的 pred_demand_delta 加进 rq 的 pred_demands_sum 中;
也会通过walt_fixup_cum_window_demand()将任务的 task_load_delta 加进 rq 的 cum_window_demand。如果任务就是运行队列中的当前任务,即
rq->curr == p时:
直接执行walt_fixup_cum_window_demand(rq, demand), 将任务的 demand 加进 rq 的 cum_window_demand。也就是说,窗口翻滚的时候,如果当前任务处于 running 状态,就会将本次计算的 demand 累加进任务所在 CPU 的运行队列的 cum_window_demand 中,但是不会将差值累加。
4. 带宽控制
参考资料:
- 吐血整理 | 肝翻 Linux 进程调度所有知识点
- 「知识分享源码分析」linux内核调度详解
- linux调度子系统7 - se 的 enqueue 和 dequeue
- linux 中进程的状态
- CFS调度器(5)-带宽控制
- 郭健: deadline调度器之(一):原理
- 郭健: Deadline调度器之(二):细节和使用方法
【WALT】调度与负载计算(未更新完)的更多相关文章
- Java多线程笔记[未更新完]
最近课上可摸鱼时间较多,因此并发开坑学习 本篇学习自Java多线程编程实战指南 目前进展:刚开坑,处于理解概念阶段 本篇学习自Java多线程编程实战指南 Q.进程和线程的区别 进程Process是程序 ...
- JSP配置即报错以及解决办法(未更新完)
JSP: JAVA Server Page 使用JAVA语言编写的一种在服务器运行的动态页面 JSP = JAVA + HTML JSP 的执行过程 1: 翻译阶段 把JSP源文件翻译成 java ...
- Linux系列(25) - 常用快捷键(未更新完)
快捷键 说明 Ctrl+L 清屏 tab tab按一次自动补全目录文件名称/tab按二次将目录下带有补全前面字段的所有文件目录展示出来,例子: cd / tab键按两次将根目录下所有文件展示出来 ...
- HDU 4640 状态压缩DP 未写完
原题链接:http://acm.hdu.edu.cn/showproblem.php?pid=4640 解题思路: 首先用一个简单的2^n*n的dp可以求出一个人访问一个给定状态的最小花费,因为这i个 ...
- 会话标识未更新(AppScan扫描结果)
最近工作要求解决下web的项目的漏洞问题,扫描漏洞是用的AppScan工具,其中此篇文章是关于会话标识未更新问题的.下面就把这块东西分享出来. 原创文章,转载请注明 ----------------- ...
- java或者jsp中修复会话标识未更新漏洞
AppScan会扫描“登录行为”前后的Cookie,其中会对其中的JSESSIONOID(或者别的cookie id依应用而定)进行记录.在登录行为发生后,如果cookie中这个值没有发生变化,则判定 ...
- virtualbox更新完之后重启不成功
前几天更新完virtualbox,一直没用,今天想用,可是提示can't not access the kernel drivers,百度完之后按照别人博客所教方法弄好了,特地来转载他人文章,表达对博 ...
- flock防止crontab脚本周期内未执行完重复执行(转)
如果某脚本要运行30分钟,可以在Crontab里把脚本间隔设为至少一小时来避免冲突.而比较糟的情况是可能该脚本在执行周期内没有完成,接着第二个脚本又开始运行了.如何确保只有一个脚本实例运行呢?一个好用 ...
- 缓存服务,还未创建完缓存时, 需要更改图层名称、服务名称、数据源位置、mxd名称等
缓存服务,还未创建完缓存时, 需要更改图层名称.服务名称.数据源位置.mxd名称等.已经创建好的缓存还可以再用吗? 测试后可以, 注意:新服务相对旧服务,符号样式没有改变,切片方案没有变化. 测试步骤 ...
- React Native (0.57)开发环境搭建(注意:Node不要随便更新到最新版,更新完后莫名其妙的问题一大堆)
搭建开发环境 一.安装依赖 必须安装的依赖有:Node.Watchman 和 React Native 命令行工具以及 Xcode. 1.首先安装 Homebrew 2.安装 Node, Watchm ...
随机推荐
- Python 有趣的模块之pynupt——通过pynput控制鼠标和键盘
写在前面 Python中有许多有趣和强大的模块,其中一个非常有趣的模块就是pynupt.pynupt是基于pynput模块的一个封装,用于控制鼠标和键盘.它可以实现自动化操作和游戏外挂等功能. 本文将 ...
- 在线问诊 Python、FastAPI、Neo4j — 创建 节点关系
目录 关系:症状-检查 关系:疾病-症状 代码重构 relationship_data.csv 症状,检查,疾病,药品,宜吃,忌吃 "上下楼梯疼,不能久站,感觉有点肿"," ...
- div 让a内容居中方法
<div>标签是HTML中的一个重要标签,它代表了一个文档中的一个分割区块或一个部分.在<div>标签中,我们可以放置各种内容,包括文本.图像.链接等等.有时候,我们需要将其中 ...
- Django框架项目之支付功能——支付宝支付
文章目录 支付宝支付 入门 支付流程 aliapy二次封装包 GitHub开源框架 依赖 结构 alipay_public_key.pem app_private_key.pem setting.py ...
- daffodil
import java.util.ArrayList; public class Daffodil { /** * 打印出100-999之间所有的"水仙花数",所谓"水仙 ...
- Stable Diffusion
Stable Diffusion ...using diffusers Stable Diffusion is a text-to-image latent diffusion model cre ...
- MyBatis foreach循环批量修改数据时报错
报错如下 org.springframework.jdbc.BadSqlGrammarException: ### Error updating database. Cause: java.sql.S ...
- 如何去掉桌面快捷方式左下角的小箭头(Win11)
在对系统重命名之后,在快捷方式的左下角莫名的出现了小图标 如果想要去掉这个小图标 (1)首先在桌面上创建一个txt文件 (2)打开后输入指令 reg add "HKEY_LOCAL_MACH ...
- flask 三方模块
flask 三方插件 Flask-AppBuilder - Simple and rapid Application builder, includes detailed security, auto ...
- VLAN通信之单臂路由与三层交换
VLAN之间通信 再次提及,vlan是虚拟局域网,用于分隔广播域,解决广播风暴.但是vlan之间无法直接通信.所有我们要用三层交换.单臂路由来实现vlan之间的通信. 单臂路由 使用场景:规划错误,只 ...