K6 在 Nebula Graph 上的压测实践
背景
对于数据库来说,性能测试是一个非常频繁的事情。优化查询引擎的规则,调整存储引擎的参数等,都需要通过性能测试,查看系统在不同场景下的影响。
即便是同样的代码,同样的参数配置,在不同的机器资源配置,不同的业务场景下也有较大的区别,记录一下内部的压测实践过程,有一个参考。
本文中操作系统为 x86 架构 CentOS 7.8。
部署 nebula 的机器配置为 4C 16G 内存,SSD 磁盘,万兆网络。
工具
- nebula-ansible 用于部署 nebula 服务
- nebula-importer 用于导入数据到 nebula 集群中
- k6-plugin k6 压测工具,里面使用 go 客户端向 nebula 集群发起请求
- nebula-bench 整合了生成 LDBC 数据集,数据导入和压测。
- ldbc_snb_datagen_hadoop LDBC 数据生成工具
概述
数据使用 ldbc_snb_datagen 自动生成的 LDBC 数据集,整体流程如下图。
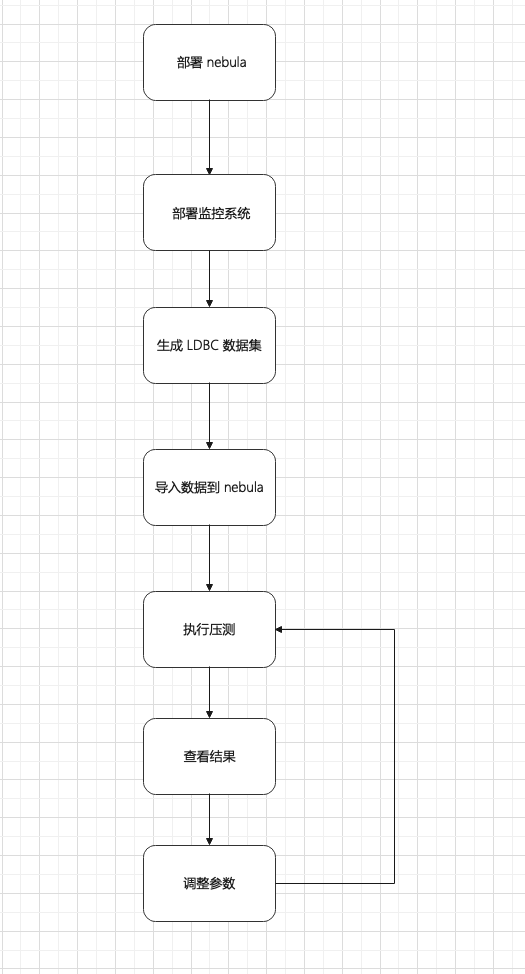
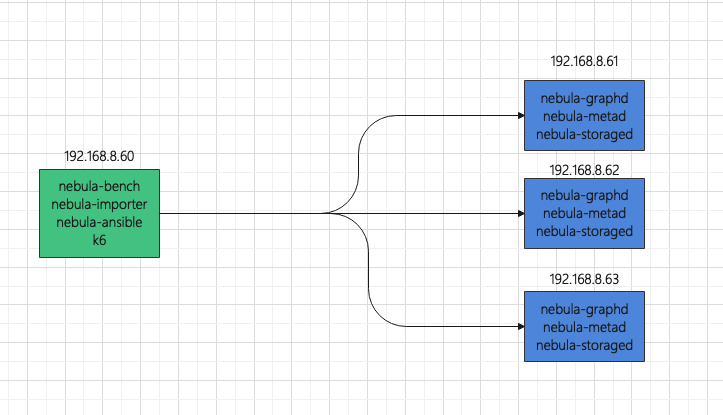
部署拓扑,使用 1 台机器作为压测负载机,3 台机器组成一个 nebula 集群
为了方便监控,压测负载机还部署了:
- Promethues
- Influxdb
- Grafana
- node-exporter
nebula 机器上还部署了:
- node-exporter
- process-exporter
具体步骤
使用 nebula-ansible 部署 nebula
- 先初始化用户,打通 ssh
- 分别登录 192.168.8.60,192.168.8.61,192.168.8.62,192.168.8.63,创建 vesoft 用户,加入 sudoer 中,并设置 NOPASSWD。
- 登录 192.168.8.60,打通 ssh
ssh-keygen
ssh-copy-id vesoft@192.168.8.61
ssh-copy-id vesoft@192.168.8.62
ssh-copy-id vesoft@192.168.8.63
- 下载 nebula-ansible,安装 ansible,修改 ansible 配置
sudo yum install ansible -y
git clone https://github.com/vesoft-inc/nebula-ansible
cd nebula-ansible/
# 因为默认是国际 cdn,改为国内的 cdn
sed -i 's/oss-cdn.nebula-graph.io/oss-cdn.nebula-graph.com.cn/g' group_vars/all.yml
inventory.ini 示例
[all:vars]
# GA or nightly
install_source_type = GA
nebula_version = 2.0.1
os_version = el7
arc = x86_64
pkg = rpm
packages_dir = {{ playbook_dir }}/packages
deploy_dir = /home/vesoft/nebula
data_dir = {{ deploy_dir }}/data
# ssh user
ansible_ssh_user = vesoft
force_download = False
[metad]
192.168.8.[61:63]
[graphd]
192.168.8.[61:63]
[storaged]
192.168.8.[61:63]
- 安装并启动 nebula
ansible-playbook install.yml
ansible-playbook start.yml
部署监控
为了方便部署,使用 Docker-Compose 运行,需要先在机器上安装 Docker 和 Docker-Compose。
登录 192.168.8.60 压测机
git clone https://github.com/vesoft-inc/nebula-bench.git
cd nebula-bench
cp -r third/promethues ~/.
cp -r third/exporter ~/.
cd ~/exporter/ && docker-compose up -d
cd ~/promethues
# 修改监控节点的 exporter 的地址
# vi prometheus.yml
docker-compose up -d
# 复制 exporter 到 192.168.8.61,192.168.8.62,192.168.8.63,然后启动 docker-compse
配置 grafana 的数据源和 dashboard,具体见 https://github.com/vesoft-inc/nebula-bench/tree/master/third 。
生成 LDBC 数据集
cd nebula-bench
sudo yum install -y git \
make \
file \
libev \
libev-devel \
gcc \
wget \
python3 \
python3-devel \
java-1.8.0-openjdk \
maven
pip3 install --user -r requirements.txt
# 默认生成 sf1, 1G的数据,300w+点,1700w+边
python3 run.py data
# mv 生成好的数据
mv target/data/test_data/ ./sf1
导入数据
cd nebula-bench
# 修改 .evn
cp env .env
vi .env
以下是 .env 示例
DATA_FOLDER=sf1
NEBULA_SPACE=sf1
NEBULA_USER=root
NEBULA_PASSWORD=nebula
NEBULA_ADDRESS=192.168.8.61:9669,192.168.8.62:9669,192.168.8.63:9669
#NEBULA_MAX_CONNECTION=100
INFLUXDB_URL=http://192.168.8.60:8086/k6
# 编译 nebula-importer 和 k6
./scripts/setup.sh
# 导入数据
python3 run.py nebula importer
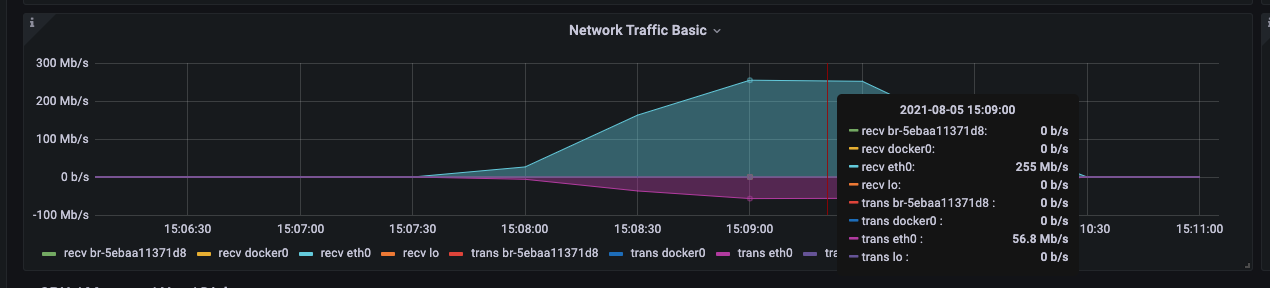
导入过程中,可以重点关注以下网络带宽和磁盘 io 写。
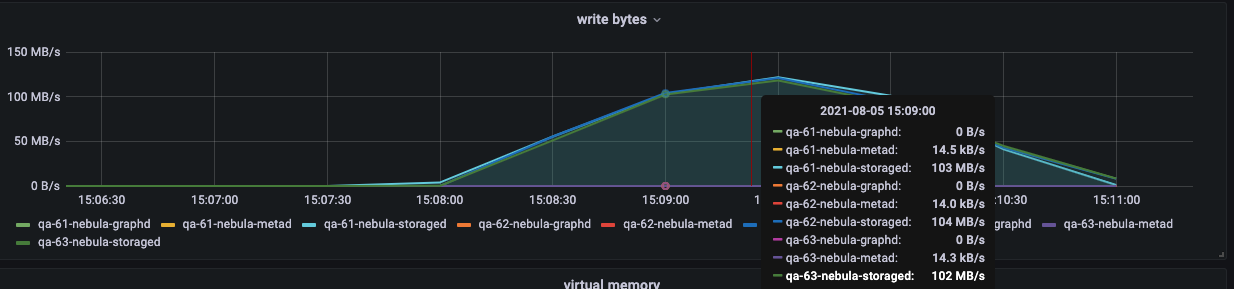
执行压测
python3 run.py stress run
会根据 scenarios 里的代码,自动渲染出 js 文件,然后使用 k6 压测所有场景。
执行后,js 文件和压测结果都在 output 文件夹中。
其中 latency 是服务端返回的 latency 时间, responseTime 是客户端从发起 execute 到接收的时间,单位 us。
[vesoft@qa-60 nebula-bench]$ more output/result_Go1Step.json
{
"metrics": {
"data_sent": {
"count": 0,
"rate": 0
},
"checks": {
"passes": 1667632,
"fails": 0,
"value": 1
},
"data_received": {
"count": 0,
"rate": 0
},
"iteration_duration": {
"min": 0.610039,
"avg": 3.589942336582023,
"med": 2.9560145,
"max": 1004.232905,
"p(90)": 6.351617299999998,
"p(95)": 7.997563949999995,
"p(99)": 12.121579809999997
},
"latency": {
"min": 308,
"avg": 2266.528722763775,
"med": 1867,
"p(90)": 3980,
"p(95)": 5060,
"p(99)": 7999
},
"responseTime": {
"max": 94030,
"p(90)": 6177,
"p(95)": 7778,
"p(99)": 11616,
"min": 502,
"avg": 3437.376111156418,
"med": 2831
},
"iterations": {
"count": 1667632,
"rate": 27331.94978169588
},
"vus": {
"max": 100,
"value": 100,
"min": 0
[vesoft@qa-60 nebula-bench]$ head -300 output/output_Go1Step.csv | grep -v USE
timestamp,nGQL,latency,responseTime,isSucceed,rows,errorMsg
1628147822,GO 1 STEP FROM 4398046516514 OVER KNOWS,1217,1536,true,1,
1628147822,GO 1 STEP FROM 2199023262994 OVER KNOWS,1388,1829,true,94,
1628147822,GO 1 STEP FROM 1129 OVER KNOWS,1488,2875,true,14,
1628147822,GO 1 STEP FROM 6597069771578 OVER KNOWS,1139,1647,true,30,
1628147822,GO 1 STEP FROM 2199023261211 OVER KNOWS,1399,2096,true,6,
1628147822,GO 1 STEP FROM 2199023256684 OVER KNOWS,1377,2202,true,4,
1628147822,GO 1 STEP FROM 4398046515995 OVER KNOWS,1487,2017,true,39,
1628147822,GO 1 STEP FROM 10995116278700 OVER KNOWS,837,1381,true,3,
1628147822,GO 1 STEP FROM 933 OVER KNOWS,1130,3422,true,5,
1628147822,GO 1 STEP FROM 6597069771971 OVER KNOWS,1022,2292,true,60,
1628147822,GO 1 STEP FROM 10995116279952 OVER KNOWS,1221,1758,true,3,
1628147822,GO 1 STEP FROM 8796093031179 OVER KNOWS,1252,1811,true,13,
1628147822,GO 1 STEP FROM 10995116279792 OVER KNOWS,1115,1858,true,6,
1628147822,GO 1 STEP FROM 6597069777326 OVER KNOWS,1223,2016,true,4,
1628147822,GO 1 STEP FROM 8796093028089 OVER KNOWS,1361,2054,true,13,
1628147822,GO 1 STEP FROM 6597069777454 OVER KNOWS,1219,2116,true,2,
1628147822,GO 1 STEP FROM 13194139536109 OVER KNOWS,1027,1604,true,2,
1628147822,GO 1 STEP FROM 10027 OVER KNOWS,2212,3016,true,83,
1628147822,GO 1 STEP FROM 13194139544176 OVER KNOWS,855,1478,true,29,
1628147822,GO 1 STEP FROM 10995116280047 OVER KNOWS,1874,2211,true,12,
1628147822,GO 1 STEP FROM 15393162797860 OVER KNOWS,714,1684,true,5,
1628147822,GO 1 STEP FROM 6597069770517 OVER KNOWS,2295,3056,true,7,
1628147822,GO 1 STEP FROM 17592186050570 OVER KNOWS,768,1630,true,26,
1628147822,GO 1 STEP FROM 8853 OVER KNOWS,2773,3509,true,14,
1628147822,GO 1 STEP FROM 19791209307908 OVER KNOWS,1022,1556,true,6,
1628147822,GO 1 STEP FROM 13194139544258 OVER KNOWS,1542,2309,true,91,
1628147822,GO 1 STEP FROM 10995116285325 OVER KNOWS,1901,2556,true,0,
1628147822,GO 1 STEP FROM 6597069774931 OVER KNOWS,2040,3291,true,152,
1628147822,GO 1 STEP FROM 8796093025056 OVER KNOWS,2007,2728,true,29,
1628147822,GO 1 STEP FROM 21990232560726 OVER KNOWS,1639,2364,true,9,
1628147822,GO 1 STEP FROM 8796093030318 OVER KNOWS,2145,2851,true,6,
1628147822,GO 1 STEP FROM 21990232556027 OVER KNOWS,1784,2554,true,5,
1628147822,GO 1 STEP FROM 15393162796879 OVER KNOWS,2621,3184,true,71,
1628147822,GO 1 STEP FROM 17592186051113 OVER KNOWS,2052,2990,true,5,
也可以对单个场景压测,不断调整配置参数,来进行对比。
并发读
# 执行 go 2 跳,50 并发,持续 300 秒
python3 run.py stress run -scenario go.Go2Step -vu 50 -d 300
INFO[0302] 2021/08/06 03:55:27 [INFO] finish init the pool
✓ IsSucceed
█ setup
█ teardown
checks...............: 100.00% ✓ 1559930 ✗ 0
data_received........: 0 B 0 B/s
data_sent............: 0 B 0 B/s
iteration_duration...: min=687.47µs avg=9.6ms med=8.04ms max=1.03s p(90)=18.41ms p(95)=22.58ms p(99)=31.87ms
iterations...........: 1559930 5181.432199/s
latency..............: min=398 avg=6847.850345 med=5736 max=222542 p(90)=13046 p(95)=16217 p(99)=23448
responseTime.........: min=603 avg=9460.857877 med=7904 max=226992 p(90)=18262 p(95)=22429 p(99)=31726.71
vus..................: 50 min=0 max=50
vus_max..............: 50 min=50 max=50
同时可以观察监控的各个指标。
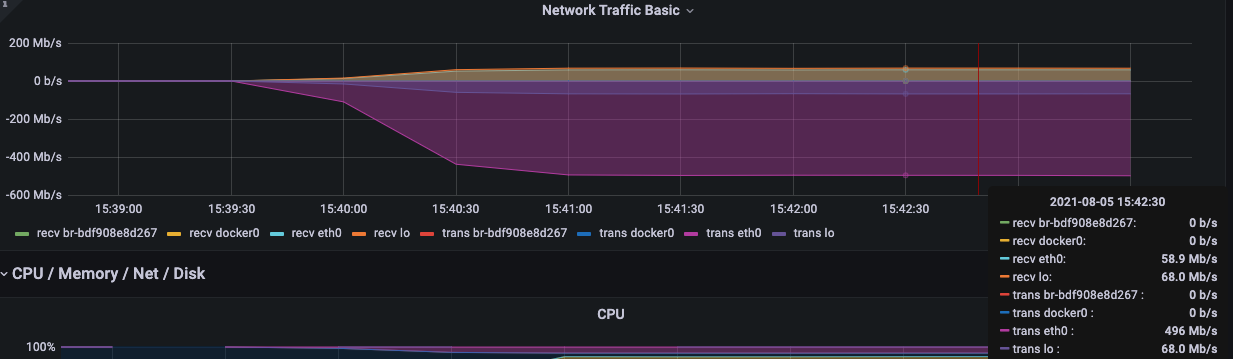
checks 是校验请求是否执行成功,如果执行失败,会在 csv 中保存失败的错误消息。
awk -F ',' '{print $NF}' output/output_Go2Step.csv|sort |uniq -c
# 执行 go 2 跳,200 并发,持续 300 秒
python3 run.py stress run -scenario go.Go2Step -vu 200 -d 300
INFO[0302] 2021/08/06 04:02:34 [INFO] finish init the pool
✓ IsSucceed
█ setup
█ teardown
checks...............: 100.00% ✓ 1866850 ✗ 0
data_received........: 0 B 0 B/s
data_sent............: 0 B 0 B/s
iteration_duration...: min=724.77µs avg=32.12ms med=25.56ms max=1.03s p(90)=63.07ms p(95)=84.52ms p(99)=123.92ms
iterations...........: 1866850 6200.23481/s
latency..............: min=395 avg=25280.893558 med=20411 max=312781 p(90)=48673 p(95)=64758 p(99)=97993.53
responseTime.........: min=627 avg=31970.234329 med=25400 max=340299 p(90)=62907 p(95)=84361.55 p(99)=123750
vus..................: 200 min=0 max=200
vus_max..............: 200 min=200 max=200
grafana 上 k6 的监控数据
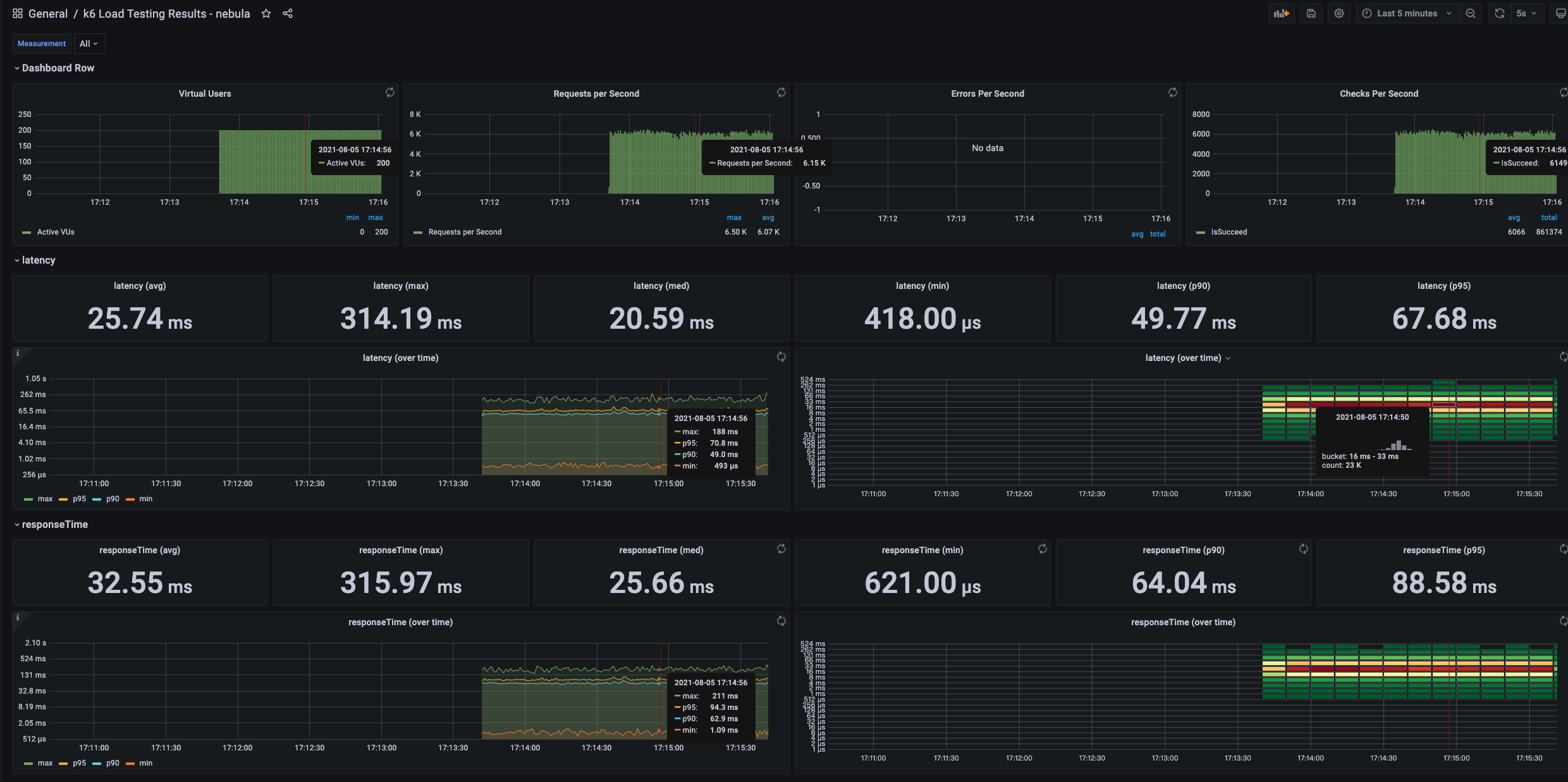
并发写
# 执行 insert,200 并发,持续 300 秒,默认 batchSize 100
python3 run.py stress run -scenario go.Go2Step -vu 200 -d 300
可以手动修改一下 js 文件,调整 batchSize
sed -i 's/batchSize = 100/batchSize = 300/g' output/InsertPersonScenario.js
# 手动运行 k6
scripts/k6 run output/InsertPersonScenario.js -u 400 -d 30s --summary-trend-stats "min,avg,med,max,p(90),p(95),p(99)" --summary-export output/result_InsertPersonScenario.json --out influxdb=http://192.168.8.60:8086/k6
当 batchSize 为 300,并发为 400 的时候,就会错误产生。
INFO[0032] 2021/08/06 04:03:49 [INFO] finish init the pool
✗ IsSucceed
↳ 96% — ✓ 31257 / ✗ 1103
█ setup
█ teardown
checks...............: 96.59% ✓ 31257 ✗ 1103
data_received........: 0 B 0 B/s
data_sent............: 0 B 0 B/s
iteration_duration...: min=12.56ms avg=360.11ms med=319.12ms max=2.07s p(90)=590.31ms p(95)=696.69ms p(99)=958.32ms
iterations...........: 32360 1028.339207/s
latency..............: min=4642 avg=206931.543016 med=206162 max=915671 p(90)=320397.4 p(95)=355798.7 p(99)=459521.39
responseTime.........: min=6272 avg=250383.122188 med=239297.5 max=1497159 p(90)=384190.5 p(95)=443439.6 p(99)=631460.92
vus..................: 400 min=0 max=400
vus_max..............: 400 min=400 max=400
awk -F ',' '{print $NF}' output/output_InsertPersonScenario.csv|sort |uniq -c
31660
1103 error: E_CONSENSUS_ERROR(-16)."
1 errorMsg
发现是 E_CONSENSUS_ERROR,应该是并发大的时候,raft 的 appendlog buffer overflow 了,可以调整相关的参数。
总结
- 使用 LDBC 作为标准数据集,数据特征会标准一些,可以生成更多的数据比如 10 亿点,而数据结构是一样的。
- 使用 k6 作为压测负载工具,二进制相比 Jmeter 更方便,而且因为 k6 底层使用 Golang 的 goroutine,相比 Jmeter 使用更少的资源。
- 通过工具,模拟各种场景或者调整 nebula 的参数,可以更好的使用到服务器资源。
《开源分布式图数据库Nebula Graph完全指南》,又名:Nebula 小书,里面详细记录了图数据库以及图数据库 Nebula Graph 的知识点以及具体的用法,阅读传送门:https://docs.nebula-graph.com.cn/site/pdf/NebulaGraph-book.pdf
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
K6 在 Nebula Graph 上的压测实践的更多相关文章
- 【原创】MySQL Replay线上流量压测工具
一. 背景 去年做过一次mysql trace 重放的测试,由于performance schema本身采集样本的长度等限制,实际回放的成功率比较低. 最近找到一款开源的工具,基于TCPCopy实现了 ...
- JMeter在linux上分布式压测步骤(二)
哈喽,我又来了~ 前提:三台linux虚拟机,一台作为master,另外两台作为slave. 一.server端 1.修改1099端口,client和server通信的端口,可以不修改,默认就是109 ...
- 在Mac上利用压测工具Jmeter-Suite进行一次压测实践的保姆级详细步骤(参考腾讯云文章)
参考的文章 压测工具Jmeter-Suite详细操作步骤 写此文的目的 由于我是刚开始接触kubernetes和jmeter,所以在学习过程中遇到了很多很多问题,同时我很烦恼为什么网上没有文章是从真正 ...
- jmeter压测实践
技巧一:命令行执行 命令执行:指定参数,报告的存储位置 jmeter -n -t baidu_requests_results.jmx -r -l baidu_requests_results.jtl ...
- ClickHouse与Elasticsearch压测实践
1 需求分析 1.1 分析压测对象 1)什么是ClickHouse 和Elasticsearch ClickHouse 是一个真正的列式数据库管理系统(DBMS).在 ClickHouse 中,数据始 ...
- JMeter在linux上分布式压测环境配置(一)
环境配置 一.在Linux服务器先安装SDK 1.先从官网下载jdk1.8.0_131.tar.gz,l(linux版本,32位,64位根据系统来判断) 2.在/usr/目录下创建java文件夹,(当 ...
- 使用tcpcopy拷贝线上流量压测测试环境
tcpcopy项目地址:https://github.com/session-replay-tools/tcpcopy 作者地址:http://blog.csdn.net/wangbin579 1:环 ...
- Jmeter在Windows上分布式压测遇到的坑
1.五星坑:远程启动测试,响应数据为空. controller运行jmeter脚本后,GUI无性能数据返回. agent的jmeter server显示连接后立即结束.看似执行实则响应数据为空. 出现 ...
- JMeter在linux上分布式压测遇到的坑(三)
master和slave机要在同一网段内,才能做分布式(Jmeter要配环境变量,这样不用手动起server) 分布式不成功,解决方案: 1.master端和slave端要ping通 2.ping通后 ...
- 性能压测诡异的Requests/second 响应刺尖问题
最近一段时间都在忙着转java项目最后的冲刺,前期的coding翻代码.debug.fixbug都逐渐收尾,进入上线前的性能压测. 虽然不是大促前的性能压测要求,但是为了安全起见,需要摸个底心里有个数 ...
随机推荐
- 说透IO多路复用模型
作者:京东零售 石朝阳 在说IO多路复用模型之前,我们先来大致了解下Linux文件系统.在Linux系统中,不论是你的鼠标,键盘,还是打印机,甚至于连接到本机的socket client端,都是以文件 ...
- echarts设置单位的偏移
echarts 可以设置的echarts单位的偏移位置吗? 之前是知道echarts的X和Y是可以设置单位的. 但是设置单位的位置一直不好调整. 现在有时间,我们会回答一下上面标题的问题? echar ...
- flask session 伪造
flask session 伪造 一.session的作用 由于http协议是一个无状态的协议,也就是说同一个用户第一次请求和第二次请求是完全没有关系的,但是现在的网站基本上有登录使用的功能,这就要求 ...
- Ubuntu编译Xilinx的u-boot
博主这里的是Ubuntu20.04LTS+Vivado2017.4+ZedBoard 注意:本文使用的环境变量导入方法是临时的,只要退出当前终端或者使用其他终端就会失效,出现异常问题,请随时expor ...
- IDM全版本激活工具
前往IDM官网下载IDM IDM官网 下载破解工具 IDM激活工具.zip 解压打开激活工具选择1 然后回车耐心等待激活完成即可
- Unity2019使用Android Studio 4出安卓包
前言 在我所经历的项目组中有这几种方法来生成APK 直接在Unity生成APK,可以接入SDK 使用Unity导出Android Studio工程手动生成APK 使用Unity导出Android St ...
- TienChin 活动管理-准备工作
配置权限 INSERT INTO `sys_menu` VALUES (2014, '添加活动', 2003, 1, '', NULL, NULL, 1, 0, 'F', '0', '0', 'tie ...
- JQ模糊查询插件
//构造函数写法 ;(function($,window,document,undefined){//注意这里的分号必须加 //插件的全部代码 var FazzSearch = function (e ...
- zblog文章采集发布插件-免费下载
推荐一款可以自动采集网页文章,并发布到zblog系统网站的zblog采集发布插件,支持简数采集器,火车头数据采集器,八爪鱼文章采集器,后羿采集器等...... zblog采集发布插件使用教程如下: 1 ...
- CF1515F Phoenix and Earthquake 题解
题目链接:CF 或者 洛谷 首先基于一个事实,答案一定是生成树,显然,每次我们都需要连边,每次都会 \(-x\),那么一共会减少 \((n-1)\times x\),很显然的一个必要条件为: \[\s ...